






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
FPGA因其灵灵活性、高并行性和可定制性,在卷积神经网络的加速中表现出良好的性能。实践中通常会将卷积的乘加运算交付给FPGA的DSP块,因此DSP的使用效率会直接影响加速器的性能。将两个乘法操作封装到一个DSP块可以同时提高DSP资源的利用率和卷积运算的速度。基于
双乘法器的卷积算子可以使运算的吞吐量和 DSP资源的利用率同时提高一倍。
一、FPGA中的DSP
目前FPGA中的DSP资源支持最多25bits×18bits的有符号乘法运算,同时拥有25bits的预加器和48bits的累加器。DSP块是FPGA中承担卷积运算的主要运算硬件单元。
在使用FPGA做卷积神经网络的硬件加速器设计时,由于其硬件特性,无法高效实现大量浮点运算,因此一般采取定点量化的方式。相关实验表明,量化位宽在8bit及以上时,各网络的损失基本在1%以内。因此,FPGA神经网络加速器往往使用8bit的量化方式来进行卷积运算。这样位宽为我们设计双乘法器提供了可能。
二、双乘法器
DSP块是FPGA中承担卷积运算的主要运算硬件单元。但是经过定点量化的卷积运算通常只需要进行8bits×8bits的有符号乘法运算,这无疑会带来很大的位宽浪费。
Nguyen提出了双乘法封装的方法[3],即将两个有相同乘数的乘法拼接在一起交给 DSP模块进行运算。如图a所示的两个乘法 A×C和 B×C,其中 A、B、C都为nbits无符号数,将 A和B进行拼接,由于nbits×nbits的结果为2nbits,故需要在拼接数中间插入(n+1)bits的0以保证A×C和B×C互不影响。
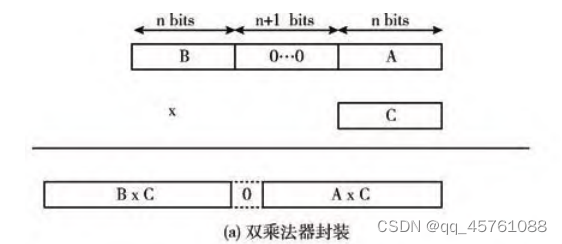
2.1双乘法器(无符号数)
对于无符号的双乘法器十分简单,不需要考虑符号问题,只是数据的简单拼接。
下图以 100 * 101 (4*5)为例 :

注意上图乘数的位数 100:3bit ;101: 3bit ;组合后 100_0_000_101; 110 : 3bit
计算结束后,按照位数对结果进行数据分割 将后位6bit拿出,之后拿掉间隔的一个0位,剩下的前面几位为 100 * 110的值。
2.2双乘法器(有符号数)
当处理有符号数时,需要考虑符号位的影响。经过位拼接后,会将低位乘数的符号位误作为运
算位进行处理,这种情况下会产生误差导致运算结果错误。
计算如下图所示:

有符号数被当成无符号数进行计算 并且最终输出错误结果,这就是我们需要解决的问题。
2.2.1有符号乘法解决方案
对于一个有符号数nbits有符号数A=anan-2…a1a0,对于其补码表示存在如下公式:

对此公式进行化简:

因此,我们可以把n位有符号的乘数看作是其补码所对应的n位无符号数以及这位有符号乘数最高位对应2的n次方的差。
对应的我们可以把有符号的乘法进行变换

这里的C为有符号数。这样就化为了一个 无符号数*有符号数 之后做差的运算。
因此, -5*-6 = 1011 * 1010 ==>
1011 ×1010 - 1010 0000 (此时1010不是-5 而是11)
= (11×-6)10-1010 0000 = (-66)10 - 1010 0000
=1011 1110 - 1010 0000 = 0001 1110 = (30)10
3双乘法器设计
首先对输入的3个数据 A、B、C进行预处理。通过比较器对数据C的符号进行判断,产生选择器的控制信号,之后3个二选一选择器使用该信号分别完成对数据 A 与-A、B与-B、C与-C的选择处理,得到预处理值 ~A、 ~B和 ~C。然后将 ~A、 ~B与(n+1)bits 0 进行位拼接,将该值与 ~C输入到DSP单元完成乘法运算。最后使用移位器将 ~C左移n位,再将该值与乘法运算结果一同输入到减法器中,得到最终的校验结果。其中,高2nbits为B×C的准确值,低2nbits为 A×C的准确值。

1代码设计
代码如下(示例):
module mult2(
input sys_clk ,
input rst_n ,
input [7:0] data_A,
input [7:0] data_B,//-7-7
input signed [7:0] data_C,
//8+8+1 ,
output reg [15:0] outA ,
output reg [15:0] outB
);
//填入dsp预处理数据
reg [7:0] A_r,B_r;
reg signed [7:0] C_r;
reg [24:0] in_r;
//reg [24:0] in_r_1;
reg [32:0]out,out_r,out_r_1;
reg [32:0] C_x; //做差分使用
//其各自的相反数
wire [7:0] A_n ;
wire [7:0] B_n ;
wire signed [7:0] C_n ;
assign A_n = ~data_A + 1'b1;
assign B_n = ~data_B + 1'b1;
assign C_n = ~data_C + 1'd1;
//预选择参数
always @(*)begin
if(!rst_n)begin
A_r = 8'd0;
B_r = 8'd0;
C_r = 8'd0;
end
else if(data_C[7]==1)begin
A_r = A_n;
B_r = B_n;
C_r = C_n;
end
else if(data_C[7] == 0)begin
A_r = data_A;
B_r = data_B;
C_r = data_C;
end
end
//组合预选参数
always@(*)begin
if(!rst_n)begin
in_r = 25'd0;
end
else
in_r = {A_r,{9{1'b0}},B_r};
end
//参数计算
always@(*)begin
if(!rst_n)begin
out_r = 33'd0;
out_r_1 = 33'd0;
end
else begin
out_r = $signed({in_r}) * C_r;
out_r_1 = $signed(in_r[24:0]) * C_r;
end
end
//相减处理
always@(*)begin
if(!rst_n)begin
C_x = 33'd0;
out = 33'd0;
end
else begin
if(B_r[7] == 1&& A_r[7] ==0 )begin
outA = out_r[32:17] ;
outB = out_r[15:0] - {C_r,{8{1'b0}}};
end
else if(B_r[7] == 0&& A_r[7] ==1 )begin
outA = out_r[32:17] ;
outB = out_r[15:0] ;
end
else if(B_r[7] == 1&& A_r[7] ==1 )begin
outA = out_r[32:17] ;
outB = out_r[15:0] - {C_r,{8{1'b0}}};
end
else if(B_r[7] ==0 && A_r[7]==0)begin
outA = out_r[32:17] ;
outB = out_r[ 15:0] ;
end
end
end
endmodule
2.激励文件
代码如下(示例):
module mult2_tb();
reg sys_clk;
reg rst_n;
reg [7:0]data_A ;
reg [7:0]data_B ;
reg signed [7:0]data_C ;
wire [15:0]outA ;
wire [15:0]outB ;
reg [7:0]test;
reg signed [16:0] test1;
reg signed [3:0]data_B_s ;
initial begin
sys_clk = 1;
rst_n = 0;
data_A = 8'd00000010;
//data_A = 4'b0001;
data_B = 8'b00001110; //-6
//data_B = 4'b0000;
data_B_s = 4'b1111; //-6
//data_C = 4'b1011;//-5
data_C = 8'b11111011;
#100;
rst_n = 1;
test = data_C*$signed({0,data_B});
test1 = $unsigned({{4{1'b1}},data_A,1'b0,{4{1'b0}},data_B})*$signed(data_C);
#200;
data_A = 8'd1; //1
data_B = 8'd0; //0
data_C = 8'b11111011;//-5
#200
data_A = 8'd2; //2
data_B = 8'b00000001; //1
data_C = 8'b11111011;//-5
#200
data_A = 8'd11111001; //-7
data_B = 8'b00000001; //1
data_C = 8'b00000011;//3
#200
data_A = 8'd11111001; //-7
data_B = 8'b01111111; //1
data_C = 8'b00000011;//3
end
always #10 sys_clk = ~sys_clk;
mult2 u_mult(
.sys_clk (sys_clk),
.rst_n (rst_n) ,
.data_A (data_A) ,
.data_B (data_B) , //-3~+3
.data_C (data_C) ,
.outA (outA) ,
.outB (outB)
);
endmodule
3实验结果
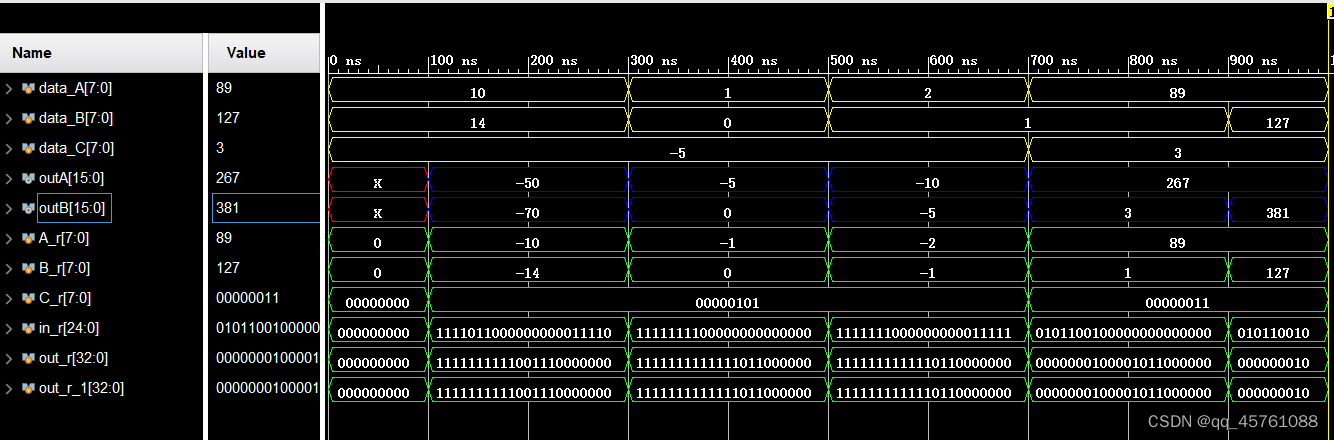
黄色信号为输入,蓝色信号为输出。 可以看到使用双乘法器进行有符号数的乘法操作成功实现。
总结
本次设计是根据阅读论文《基于FPGA的双乘法器卷积加速算子的封装方法》来进行的。如果想要有更深的了解,可以去阅读这篇论文。 学识浅薄,叙述中如有不妥之处,还望大家多多批评指正。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









