







文章目录
Introduction
Supervised Learning与Semi-supervised Learning的区别
-
Supervised Learning的training data中每组data都有input x r x^r xr和对应的output y r y^r yr,即 ( x r , y ^ r ) (x^r,\hat y^r) (xr,y^r) r = 1 R _{r=1}^R r=1R
-
Semi-supervised Learning的training data中部分data只有input x u x^u xu没有output y r y^r yr,即 { ( x r , y ^ r ) } r = 1 R \{(x^r,\hat y^r)\}_{r=1}^R {(xr,y^r)}r=1R + { x u } u = R R + U \{x^u\}_{u=R}^{R+U} {xu}u=RR+U ;并且通常无标签的数据量远大于有标签的数据量,即U>>R。
Semi-supervised Learning的分类
- 转导推理——Transductive Learning:无标签数据就是测试数据
- 归纳学习——Inductive Learning:无标签数据不是测试数据(更普遍)
Why semi-supervised learning help?
"The distribution of the unlabeled data tell us something",unlabeled data虽然只有input,但通过它的数据分布可以作为信息对机器决策做出影响。
 labeled data labeled data
|
 labeled data + unlabeled data labeled data + unlabeled data
|
上图中在只有labeled data的情况下,红线是二元分类的分界线;但当我们加入unlabeled data的时候,由于数据的特征分布发生了变化,分界线也随之改变。semi-supervised learning的使用往往伴随着假设,而该假设的合理与否,决定了结果的好坏程度;上图中的unlabeled data,它显然是一只狗,而特征分布却与猫被划分在了一起,很可能是由于这两张图片的背景都是绿色导致的,因此假设是否合理显得至关重要。
Semi-supervised Learning for Generative Model
Supervised Generative Model
在监督学习的概率生成模型中,二元分类问题中在已知 P ( C 1 ) , P ( C 2 ) P(C_1),P(C_2) P(C1),P(C2)的情况下,假设class1和class2的分布都为高斯分布,然后以极大似然估计来估测两个分布的参数为 μ 1 、 μ 2 、 Σ ( Σ 1 = Σ 2 ) μ_1、μ_2、\Sigma(\Sigma_1=\Sigma_2) μ1、μ2、Σ(Σ1=Σ2),预测时直接通过贝叶斯公式 P ( C 1 ∣ x ) = P ( C 1 ) P ( x ∣ C 1 ) P ( C 1 ) P ( x ∣ C 1 ) + P ( C 2 ) P ( x ∣ C 2 ) P(C_1|x)=\frac{P(C_1)P(x|C_1)}{P(C_1)P(x|C_1)+P(C_2)P(x|C_2)} P(C1∣x)=P(C1)P(x∣C1)+P(C2)P(x∣C2)P(C1)P(x∣C1)生成所属类别的概率。
Semi-supervised Generative Model
在上述model的基础上,Semi-supervised中添加了unlabeled data。现在的任务不仅要寻找对全体数据拟合效果良好的分布,同时 P ( C 1 ) , P ( C 2 ) P(C_1),P(C_2) P(C1),P(C2)也未知。也就是说,现在需要根据全体数据来学习 P ( C 1 ) , P ( C 2 ) , u 1 , u 2 , Σ P(C_1),P(C_2),u^1,u^2,\Sigma P(C1),P(C2),u1,u2,Σ。
 Supervised Model Supervised Model
|
 Semi-supervised Model Semi-supervised Model
|
二元Semi-supervised Generative Model:
-
随机初始化参数 θ = { P ( C 1 ) , P ( C 2 ) , u 1 , u 2 , Σ } \theta=\{P(C_1),P(C_2),u^1,u^2,\Sigma\} θ={P(C1),P(C2),u1,u2,Σ}
-
Repeat:
- 在以当前 θ \theta θ为参数的概率分布下,计算每一笔unlabeled data x u x^u xu属于class 1的概率 P θ ( C 1 ∣ x u ) P_{\theta}(C_1|x^u) Pθ(C1∣xu)
- 更新参数
θ
\theta
θ(公式
=
=
=labeled data部分
+
+
+unlabeled data部分)
P ( C 1 ) = N 1 + ∑ x u P ( C 1 ∣ x u ) N μ 1 = 1 N 1 ∑ x r ∈ C 1 x r + 1 ∑ x u P ( C 1 ∣ x u ) ∑ x u P ( C 1 ∣ x u ) x u P(C_1)=\frac{N_1+\sum_{x^u}P(C_1|x^u)}{N}\\ μ_1=\frac{1}{N_1}\sum\limits_{x^r\in C_1} x^r+\frac{1}{\sum_{x^u}P(C_1|x^u)}\sum\limits_{x^u}P(C_1|x^u)x^u P(C1)=NN1+∑xuP(C1∣xu)μ1=N11xr∈C1∑xr+∑xuP(C1∣xu)1xu∑P(C1∣xu)xu
上述方法被称为最大期望算法(EM Algorithm),类似gradient descent理论上可以收敛,同时初始参数 θ \theta θ影响收敛的结果。
Low-density Separation Assumption
上述方法是使用概率生成模型(Generative Model)的方式,另一种方式是生成分类决策面decision boundary,某一数据只可能处于决策面一侧而非概率,Low-density separation低密度分离,实质是对决策面好坏的一种衡量,它认为处于低密度的决策面优于处于高密度的决策面。
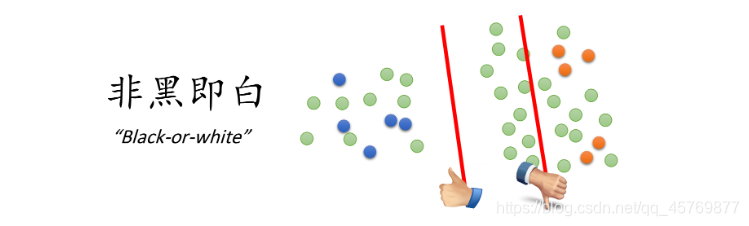
low-density separation最具代表性也最简单的方法是Self-training:
- Repeat:
- 根据labeled data训练决策面 f ∗ f^* f∗(训练方式没有限制)
- 用该决策面 f ∗ f^* f∗对unlabeled data打上label(pseudo label伪标签)
- 从打上lable的unlabeled data中拿出一些加到labeled data(选取算法不定)
decision boundary与generative model的区别
- decision boundary使用hard label——强制属于某已类
- Generative Model使用soft label——生成类型概率
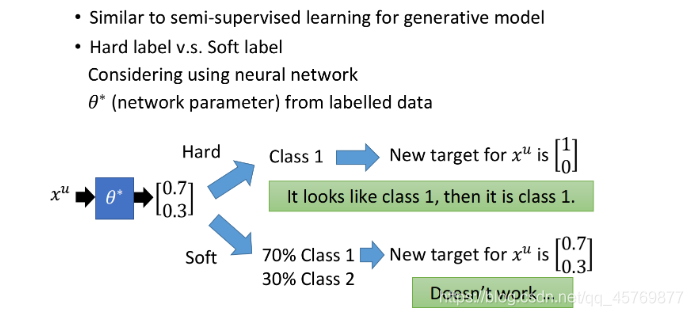
在neural network里使用soft label是没有用的,因为把原始的model里的某个点丢回去重新训练,得到的依旧是同一组参数,实际上low density separation就是通过强制分类来提升分类效果的方法。
Entropy-based Regularization
Entropy-based Regularization是对hard label和soft label之间的折中,Entropy-based Regularization产生的仍然是概率,但偏向于分布集中的结果,而分布是比较分散的意味着分类效果较差。

数值化分布集中程度的方法叫Entropy:
E
(
y
u
)
=
−
∑
m
=
1
n
y
m
u
l
n
(
y
m
u
)
E(y^u)=-\sum\limits_{m=1}^n y_m^u ln(y_m^u)
E(yu)=−m=1∑nymuln(ymu)
entropy越大distribution就越分散,分类结果越差;entropy越小distribution就越集中,分类结果也就越好。
添加上述Regularization的Loss function:
- 对labeled data来说,它的output要跟自身label越接近越好,用cross entropy表示:
L = ∑ x r C ( y r , y ^ r ) L=\sum\limits_{x^r} C(y^r,\hat y^r) L=xr∑C(yr,y^r) - 对unlabeled data来说,使得output distribution越集中越好,用entropy表示:
L = ∑ x u E ( y u ) L=\sum\limits_{x^u} E(y^u) L=xu∑E(yu) - 两项综合,并可以用weight
λ
\lambda
λ来加权决定两项的重要程度:
L = ∑ x r C ( y r , y ^ r ) + λ ∑ x u E ( y u ) L=\sum\limits_{x^r} C(y^r,\hat y^r) + \lambda \sum\limits_{x^u} E(y^u) L=xr∑C(yr,y^r)+λxu∑E(yu)
Semi-supervised SVM
Semi-supervised SVM是在SVM的基础上加上考虑unabled data,并寻找decision boundary:
- 对于labled data,以SVM训练好一个boundary
- 对于unlabled data,穷举所有可能的label,找出最大话margin同时又最小化error情况
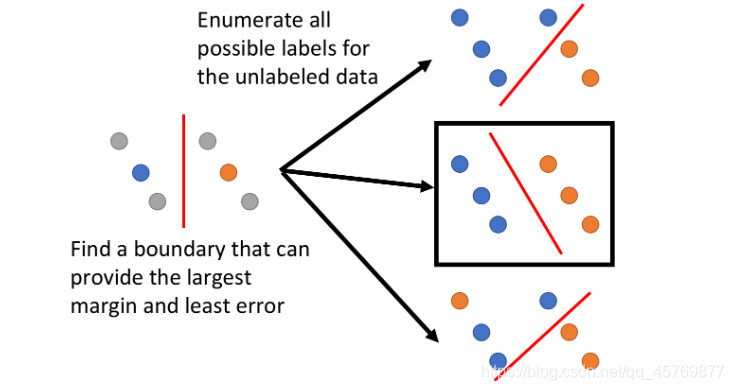
上述方法存在问题,对于n笔unlabeled data,意味着即使在二元分类里也有
2
n
2^n
2n种可能的情况,穷举情况太多,paper提出了一种approximate的方法,基本精神是:一开始你先得到一些label,然后每次改一笔unlabeled data的label,看看可不可以让你的objective function变大,如果变大就去改变该label。(参考文献:Thorsten Joachims, ”Transductive Inference for Text Classification using Support Vector Machines”, ICML, 1999)














 1948
1948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









