







在本项目中,通过数据科学和AI的方法,分析挖掘人力资源流失问题,并基于机器学习构建解决问题的方法,并且,我们通过对AI模型的反向解释,可以深入理解导致人员流失的主要因素,HR部门也可以根据分析做出正确的决定。
探索性数据分析

##1.数据加载
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = pd.read_csv('../data/train.csv')
test_data = pd.read_csv('../data/test2.csv')

查看数据基本信息
#字段,类型,缺失情况
data.info()
data.info() 来获取数据的信息,包括总行数(样本数)和总列数(字段数)、变量的数据类型、数据集中非缺失的数量以及内存使用情况。
从数据集的信息可以看出,一共有31 个特征,Attrition 是目标字段,23个变量是整数类型变量,8个是对象类型变量。

2.数据基本分析
#数据无缺失值,查看数据分布
data.describe()

数据处理操作
# 训练集
X_train = data.drop('Attrition', axis=1)
y_train = data['Attrition']
# 测试集
X_test = test_data.drop('Attrition', axis=1)
y_test = test_data['Attrition']
特征进行独热编码
# 识别非数值型的列(即分类特征)
categorical_features = X_train.select_dtypes(include=['object']).columns
# 对分类特征进行独热编码
X_train_encoded = pd.get_dummies(X_train[categorical_features])
X_test_encoded = pd.get_dummies(X_test[categorical_features])
# 接下来,我们需要合并独热编码的特征回原始的数值型特征中
# 首先,识别数值型的列
numerical_features = X_train.select_dtypes(exclude=['object']).columns
# 选择数值型特征
X_train_numerical = X_train[numerical_features]
X_test_numerical = X_test[numerical_features]
# 合并数值型特征和独热编码的特征
X_train = pd.concat([X_train_numerical, X_train_encoded], axis=1)
X_test = pd.concat([X_test_numerical, X_test_encoded], axis=1)
X_train
# 现在 X_train_encoded 和 X_test_encoded 包含了独热编码后的特征
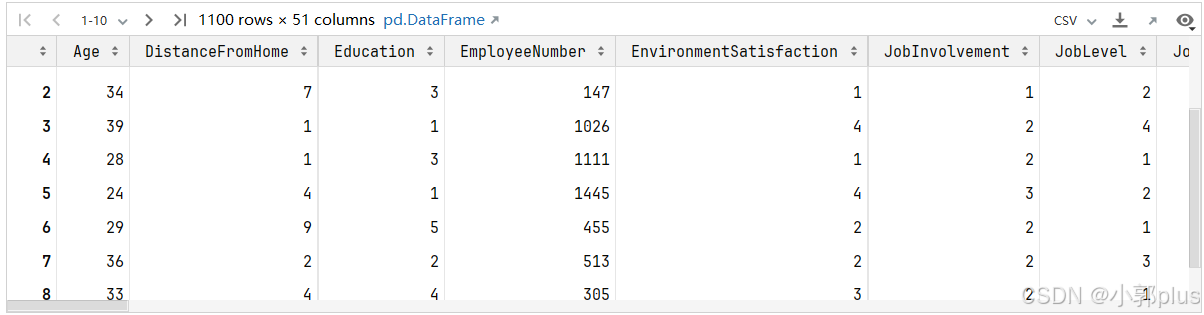
跑baseline模型(使用不同的分类算法)
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
import xgboost as xgb
import lightgbm as lgb
# 逻辑回归
lr = LogisticRegression(random_state=22)
lr.fit(X_train, y_train)
y_pred_lr = lr.predict_proba(X_test)[:,1]
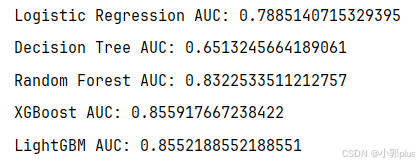
print(f'Logistic Regression AUC: {roc_auc_score(y_test, y_pred_lr)}')
# 决策树
dt = DecisionTreeClassifier(random_state=22)
dt.fit(X_train, y_train)
y_pred_dt = dt.predict_proba(X_test)[:,1]
print(f'Decision Tree AUC: {roc_auc_score(y_test, y_pred_dt)}')
# 随机森林
rf = RandomForestClassifier(random_state=22)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict_proba(X_test)[:,1]
print(f'Random Forest AUC: {roc_auc_score(y_test, y_pred_rf)}')
# XGBoost
xgb_model = xgb.XGBClassifier(random_state=22)
xgb_model.fit(X_train, y_train)
y_pred_xgb = xgb_model.predict_proba(X_test)[:,1]
print(f'XGBoost AUC: {roc_auc_score(y_test, y_pred_xgb)}')
# LightGBM
lgb_model = lgb.LGBMClassifier(random_state=22, verbose=-1)
lgb_model.fit(X_train, y_train)
y_pred_lgb = lgb_model.predict_proba(X_test)[:,1]
print(f'LightGBM AUC: {roc_auc_score(y_test, y_pred_lgb)}')
3.特征工程
做特征筛选,选出对模型贡献度大的特征,并剔除一些不相关的特征
使用 sklearn.feature_selection 类中的mutual_info_classif 方法来获得特征重要度。
特征筛选,选出对模型贡献度大的特征
from sklearn.feature_selection import mutual_info_classif
# 计算特征集 X_train 和目标变量 y_train 之间的互信息
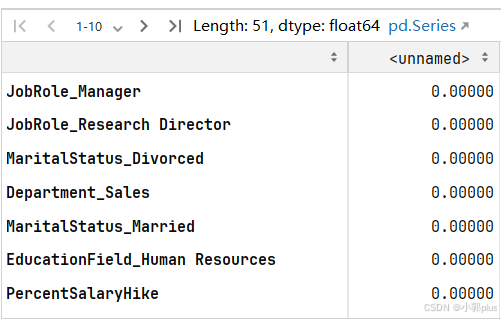
mutual_info = mutual_info_classif(X_train,y_train)
#互信息数组转换成一个Pandas Series 对象
mutual_info = pd.Series(mutual_info)
# 将 Series 对象的索引设置为 X_train 的列名
mutual_info.index = X_train.columns
# 对 Series 对象中的互信息值进行降序排序
mutual_info.sort_values(ascending=True)
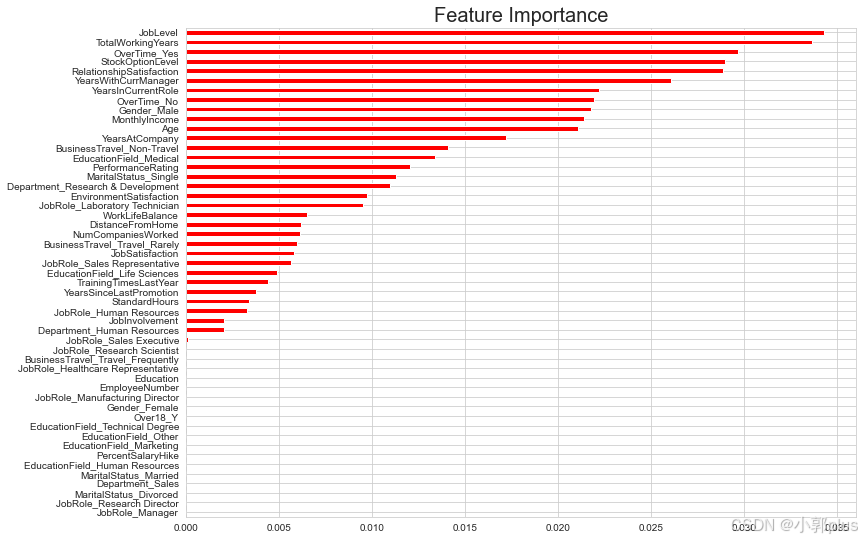
plt.title("Feature Importance",fontsize=20)
mutual_info.sort_values().plot(kind='barh',figsize=(12,9),color='r')
plt.show()
剔除无效特征(后19位)
sorted_mutual_info = mutual_info.sort_values(ascending=False)
# 获取互信息值最低的20个特征的索引(列名)
least_important_feature_indices = sorted_mutual_info.tail(19).index
# 从new_df中删除这些特征
X_train_drop= X_train.drop(columns=least_important_feature_indices)
X_test_drop= X_test.drop(columns=least_important_feature_indices)
X_train_drop
# 接下来是模型训练和评估的代码...
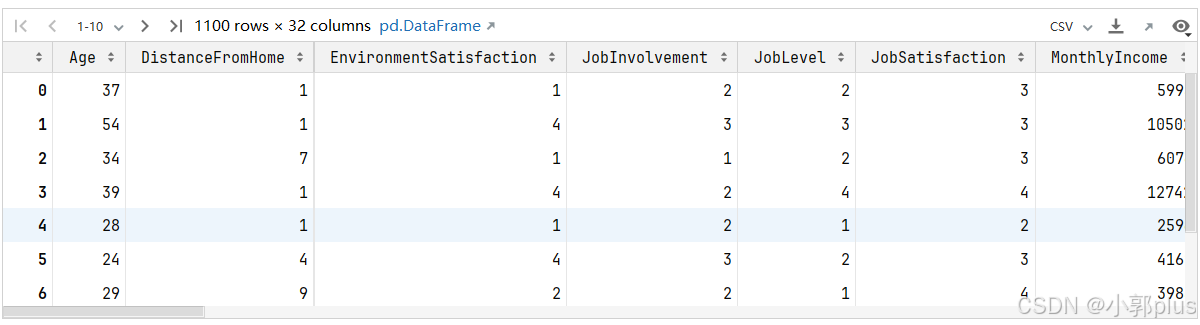
#7.继续又跑模型,看是否有提升(可以使用不同的分类算法)
# 逻辑回归
lr = LogisticRegression(random_state=22)
lr.fit(X_train_drop, y_train)
y_pred_lr = lr.predict_proba(X_test_drop)[:,1]
print(f'Logistic Regression AUC: {roc_auc_score(y_test, y_pred_lr)}')
# 决策树
dt = DecisionTreeClassifier(random_state=22)
dt.fit(X_train_drop, y_train)
y_pred_dt = dt.predict_proba(X_test_drop)[:,1]
print(f'Decision Tree AUC: {roc_auc_score(y_test, y_pred_dt)}')
# 随机森林
rf = RandomForestClassifier(random_state=22)
rf.fit(X_train_drop, y_train)
y_pred_rf = rf.predict_proba(X_test_drop)[:,1]
print(f'Random Forest AUC: {roc_auc_score(y_test, y_pred_rf)}')
# XGBoost
xgb_model = xgb.XGBClassifier(random_state=22)
xgb_model.fit(X_train_drop, y_train)
y_pred_xgb = xgb_model.predict_proba(X_test_drop)[:,1]
print(f'XGBoost AUC: {roc_auc_score(y_test, y_pred_xgb)}')
# LightGBM
lgb_model = lgb.LGBMClassifier(random_state=22)
lgb_model.fit(X_train_drop, y_train)
y_pred_lgb = lgb_model.predict_proba(X_test_drop)[:,1]
print(f'LightGBM AUC: {roc_auc_score(y_test, y_pred_lgb)}')
特征前
特征后

# SMOTE处理样本不均衡问题
# SMOTE处理类别不均衡
# SMOTE处理类别不均衡
from imblearn.over_sampling import SMOTE
# 正确使用 SMOTE 仅对训练集进行过采样
sm = SMOTE(sampling_strategy='minority')
x_smote, y_smote = sm.fit_resample(X_train_drop, y_train)
# 测试集不应该使用 SMOTE
# x_smote_test, y_smote_test 应该是原始的测试集
x_smote_test = X_test_drop
y_smote_test = y_test
#7.继续又跑模型,看是否有提升(可以使用不同的分类算法)
# 逻辑回归
lr = LogisticRegression(random_state=22)
lr.fit(x_smote, y_smote)
y_pred_lr = lr.predict_proba(X_test_drop)[:,1]
print(f'Logistic Regression AUC: {roc_auc_score(y_test, y_pred_lr)}')
# 决策树
dt = DecisionTreeClassifier(random_state=22)
dt.fit(x_smote, y_smote)
y_pred_dt = dt.predict_proba(X_test_drop)[:,1]
print(f'Decision Tree AUC: {roc_auc_score(y_test, y_pred_dt)}')
# 随机森林
rf = RandomForestClassifier(random_state=22)
rf.fit(x_smote, y_smote)
y_pred_rf = rf.predict_proba(X_test_drop)[:,1]
print(f'Random Forest AUC: {roc_auc_score(y_test, y_pred_rf)}')
# XGBoost
xgb_model = xgb.XGBClassifier(random_state=22)
xgb_model.fit(x_smote, y_smote)
y_pred_xgb = xgb_model.predict_proba(X_test_drop)[:,1]
print(f'XGBoost AUC: {roc_auc_score(y_test, y_pred_xgb)}')
# LightGBM
lgb_model = lgb.LGBMClassifier(random_state=22)
lgb_model.fit(x_smote, y_smote)
y_pred_lgb = lgb_model.predict_proba(X_test_drop)[:,1]
print(f'LightGBM AUC: {roc_auc_score(y_test, y_pred_lgb)}')
smote前
smote后
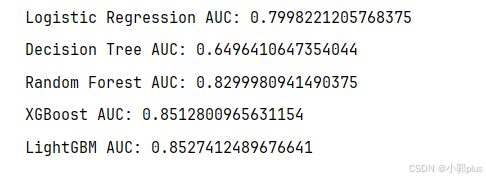
孤立森林处理异常点
from sklearn.ensemble import IsolationForest
# 孤立森林
if_model = IsolationForest(contamination=0.1, random_state=22)
# 随机森林 孤立森林
X_train_clean_rf = if_model.fit_predict(X_train_drop)
X_train_clean_rf = X_train_drop[X_train_clean_rf == 1]
y_train_clean_rf = y_train[X_train_clean_rf.index]
rf_model = RandomForestClassifier(random_state=22)
rf_model.fit(X_train_clean_rf, y_train_clean_rf)
y_pred_rf = rf_model.predict_proba(X_test_drop)[:, 1]
auc_rf = roc_auc_score(y_test, y_pred_rf)
print(f'RandomForest Best AUC and Isolation Forest: {auc_rf}')
# XGBoost 孤立森林
X_train_clean_xgb = if_model.fit_predict(X_train_drop)
X_train_clean_xgb = X_train_drop[X_train_clean_xgb == 1]
y_train_clean_xgb = y_train[X_train_clean_xgb.index]
xgb_model.fit(X_train_clean_xgb, y_train_clean_xgb)
y_pred_xgb = xgb_model.predict_proba(X_test_drop)[:, 1]
auc_xgb = roc_auc_score(y_test, y_pred_xgb)
print(f'XGBoost Best AUC and Isolation Forest: {auc_xgb}')
# lightGBM 孤立森林
X_train_clean_lgb = if_model.fit_predict(X_train_drop)
X_train_clean_lgb = X_train_drop[X_train_clean_lgb == 1]
y_train_clean_lgb = y_train[X_train_clean_lgb.index]
lgb_model.fit(X_train_clean_lgb, y_train_clean_lgb)
y_pred_lgb = lgb_model.predict_proba(X_test_drop)[:, 1]
auc_lgb = roc_auc_score(y_test, y_pred_lgb)
print(f'LightGBM Best AUC and Isolation Forest: {auc_lgb}')
 只有随机森林的auc提高了
只有随机森林的auc提高了
交叉验证和超参数调优
- 网格搜索:模型针对具有一定范围值的超参数网格进行评估,尝试参数值的每种组合,并实验以找到最佳超参数,计算成本很高。
- 随机搜索:这种方法评估模型的超参数值的随机组合以找到最佳参数,计算成本低于网格搜索。
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid_rf = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10]
}
param_grid_xgb = {'n_estimators': [100, 200, 300],
'learning_rate': [0.01, 0.015, 0.025, 0.05, 0.1],
'max_depth': [3, 5, 6, 7, 9, 12, 15, 17, 25],
'min_child_weight': [1, 3, 5, 7],
'subsample': [0.6, 0.7, 0.8, 0.9, 1]
}
param_grid_lgb = {
'n_estimators': [100, 200, 300],
'max_depth': [None, 10, 20, 30],
'min_child_samples': [20, 50, 100]
}
# 随机森林模型的交叉验证网格搜索
rf_model = RandomForestClassifier(random_state=22)
grid_search_rf = GridSearchCV(estimator=rf_model, param_grid=param_grid_rf, cv=5, scoring='roc_auc')
grid_search_rf.fit(X_train_drop, y_train)
best_model_rf = grid_search_rf.best_estimator_
y_pred_best_rf = best_model_rf.predict_proba(X_test_drop)[:, 1]
best_auc_rf = roc_auc_score(y_test, y_pred_best_rf)
print(f'RandomForest Best AUC after tuning: {best_auc_rf}')
# XGBoost模型的交叉验证网格搜索
best_model_xgb = xgb.XGBClassifier(learning_rate=0.025,
max_depth=3,
min_child_weight=3,
n_estimators=300,
subsample=0.6,
random_state=22)
best_model_xgb.fit(X_train_drop, y_train)
y_pred_xgb = best_model_xgb.predict_proba(X_test_drop)[:, 1]
print(f'XGBoost Best AUC after tuning: {roc_auc_score(y_test, y_pred_xgb)}')
# grid_search_xgb = GridSearchCV(estimator=xgb_model, param_grid=param_grid_xgb, cv=4,scoring='roc_auc')
# grid_search_xgb.fit(X_train, y_train)
# best_model_xgb = grid_search_xgb.best_estimator_
# y_pred_best_xgb = best_model_xgb.predict_proba(X_test)[:, 1]
# best_auc_xgb = roc_auc_score(y_test, y_pred_best_xgb)
# print(f'XGBoost Best AUC after tuning: {best_auc_xgb}')
# LightGBM模型的交叉验证网格搜索
lgb_model = lgb.LGBMClassifier(random_state=22)
grid_search_lgb = GridSearchCV(estimator=lgb_model, param_grid=param_grid_lgb, cv=5, scoring='roc_auc')
grid_search_lgb.fit(X_train_drop, y_train)
best_model_lgb = grid_search_lgb.best_estimator_
y_pred_best_lgb = best_model_lgb.predict_proba(X_test_drop)[:, 1]
best_auc_lgb = roc_auc_score(y_test, y_pred_best_lgb)
print(f'LightGBM Best AUC after tuning: {best_auc_lgb}')

有了明显提高
源代码和数据集

















 1477
1477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









