







点云中基于语义的任务主要分为了传统任务和新兴任务,该github仓库对各类任务的最新论文及对应的开源代码进行了整理:
Jasmine-tjy/Semantic-based-Point-Cloud-Tasks: This is an open-source repository for semantic based point cloud tasks, and we aim to provide a comprehensive summary of various semantic based point cloud tasks. (github.com)
bib引用:
@misc{tang2025implicitguidanceexplicitrepresentation,
title={Implicit Guidance and Explicit Representation of Semantic Information in Points Cloud: A Survey},
author={Jingyuan Tang and Yuhuan Zhao and Songlin Sun and Yangang Cai},
year={2025},
eprint={2501.05473},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2501.05473},
}语义信息在点云中的隐式引导及显式表示:综述
Implicit Guidance and Explicit Representation of Semantic Information In Points Cloud: A Survey
摘要
点云作为三维表示的方法之一,广泛应用于自动驾驶、测绘、电力、建筑、游戏等领域,并以其准确性和稳健性被深入探索。场景中语义信息的提取可以辅助人类理解及机器感知。而语义信息在二维场景的广泛研究使众多学者将其与三维表示中的点云结合,以追求更高效和精准的任务表达。本文全面回顾了语义信息在点云中的各项应用及最新进展,结合传统点云任务及由语义信息引进的新兴任务将语义信息在点云中的应用整合为隐式引导及显式表示两方面。此外,还介绍了基于任务的公开数据集的比较结果,以及启发性观察结果。最后,我们就未来语义信息在点云中的综合应用中可能面临的几个挑战和问题提出自己的见解。
1. 介绍
随着三维采集仪器的发展以及人们对高维数据需求量的增加,静态及动态场景的三维表示及相应任务引起人们的广泛关注。目前主流的三维表示包括体素、点云、网格、及神经辐射场等。其中,点云可由深度传感器直接采集获得,保留三维场景中的原始信息。由于点间无强拓朴关联,使点云表示具有鲁棒性,所以点云表示仍作为诸多三维场景任务及应用的首选。点云广泛应用于自动驾驶、测绘、城市规划、医学等领域。除满足三维场景的呈现需求外,基于点云的实例分割、压缩、配准、重建等任务也在各场景展开,推动三维数据处理技术发展。
在二维图像视频内容中,语义信息可作为局部或全局的精简表示。语义信息一方面更直接地向人类呈现关键信息,另一方面可以辅助机器感知,为携带细分功能的终端提供隐式引导。目前,语义信息在二维表示中研究较三维表示深入。从语义出发,可以利用该先验信息进行图像视频内容检索、内容编辑、目标分割等高维特征处理。此外,语义信息作为高级(high-level)特征提供隐式引导优化目标功能,例如基于语义的图像增强、基于语义的图像识别、压缩等。语义信息在二维表示的发散性探索及不断尝试使其在三维的应用成为可能。而深度扫描仪的数据采集和大规模存储库的建立也使人们愈发关注三维数据的语义分析。
尽管语义信息在二维表示有了广泛研究,但基于点云表示的语义驱动任务还有待继续发掘。而点云表示的日益成熟也使学者开始探索语义信息对点云传统任务的优化,以及其与点云结合可能引入的新兴任务。语义信息的引入使点云不再仅包含空间位置信息,各点获得的标签有助于更准确地理解和分析三维场景。此外,标注语义信息的点云数据可以更高效地应用于聚类、检索等任务,并为处理更复杂的三维数据提供线索。语义信息在点云中的进展包括在传统任务实例分割及目标检测基础上引入语义信息实现多场景的语义分割,基于压缩、配准、重建、语义场景补全等任务通过语义引导提升效率,以及3D密集字幕、场景图预测、点云理解等基于语义的点云新兴任务。
此外,点云语义相关任务仍然缺乏全视角的系统调查,无法提供这系列任务的清晰全貌。而该领域的快速发展使得全面审视最新研究成果成为必要。为此,本文以语义信息与点云传统任务的结合及发展出的新兴任务为基础,从隐式推导及显式表示的角度,对该领域进行全面综述。在本文中,语义信息在点云中的隐式推导指利用高级(high-level)语义特征在任务实现过程中进行引导,以实现相比传统方法的SOTA性能。隐式推导包括点云压缩、配准、重建、语义场景补全等。语义信息在点云中的显式表示指最后任务输出有场景的可视化语义标记或描述性地语义叙述。显式表示包括语义分割、3D密集字幕任务、场景图预测等。
这项研究的贡献主要包括三方面(threefold)。首先,我们跳出传统综述针对特定领域的思路,以“语义”为线索,对最先进的点云语义相关任务进行了详尽地概述,并分析了各分支的优势和局限性。据我们所知,这是第一份关于点云语义全局性分析的综述。其次,我们对各个任务的性能评估指标都进行了汇总,以实现各任务间的多维对比。最后,通过结合二维语义发展及点云自有特征的分析,我们希望向未来研究者提供该领域的工作指南及讨论潜在研究方向。本文其余部分组织结构如图1所示。更多细节将在随后的小节中讨论。
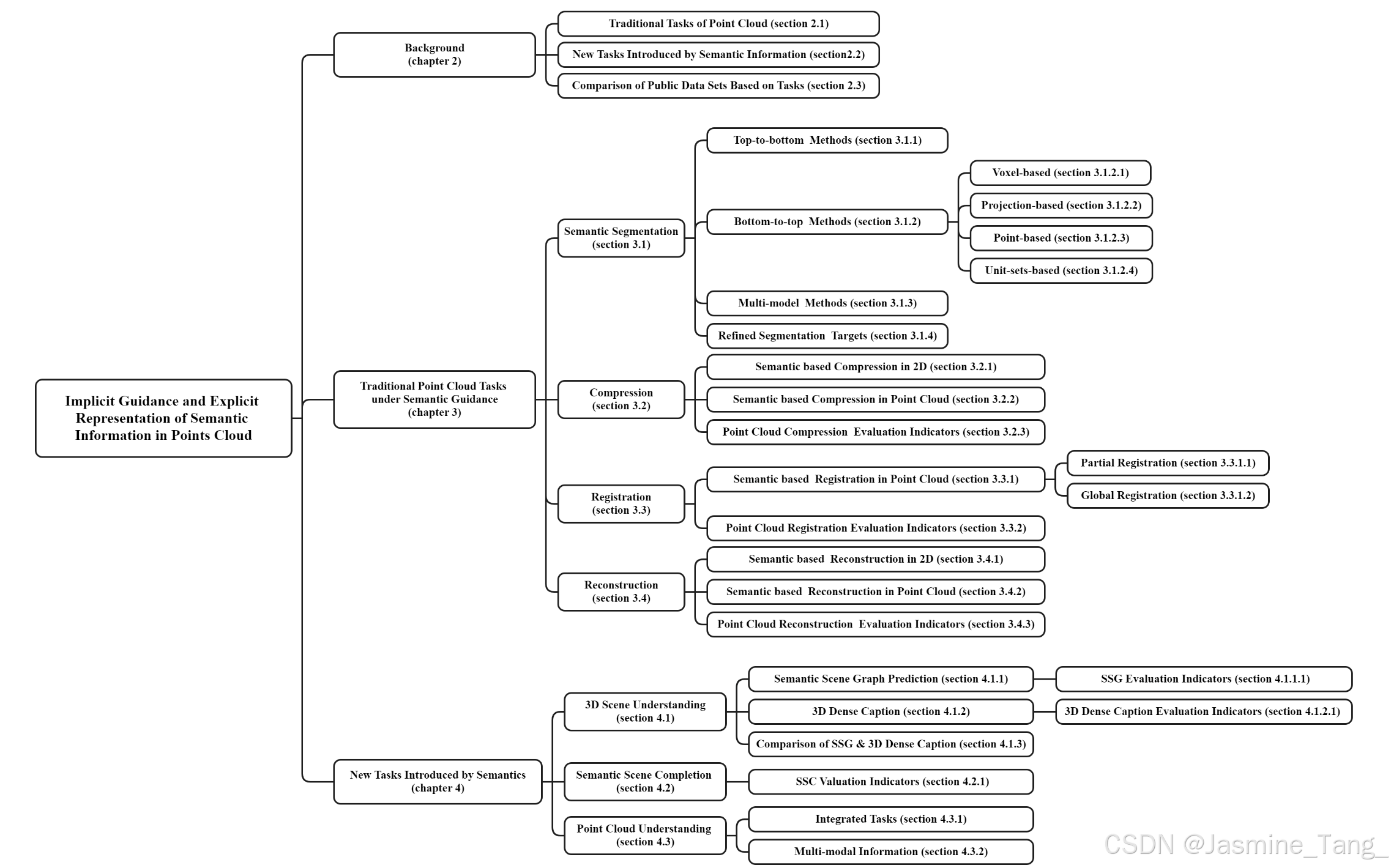
2. 背景
如前所述,我们将从隐式推导和显式表示的角度深入讨论三维点云中任务的开发。该分析基于语义信息与传统和新兴点云任务的集成。图2显示了每个任务的类别。
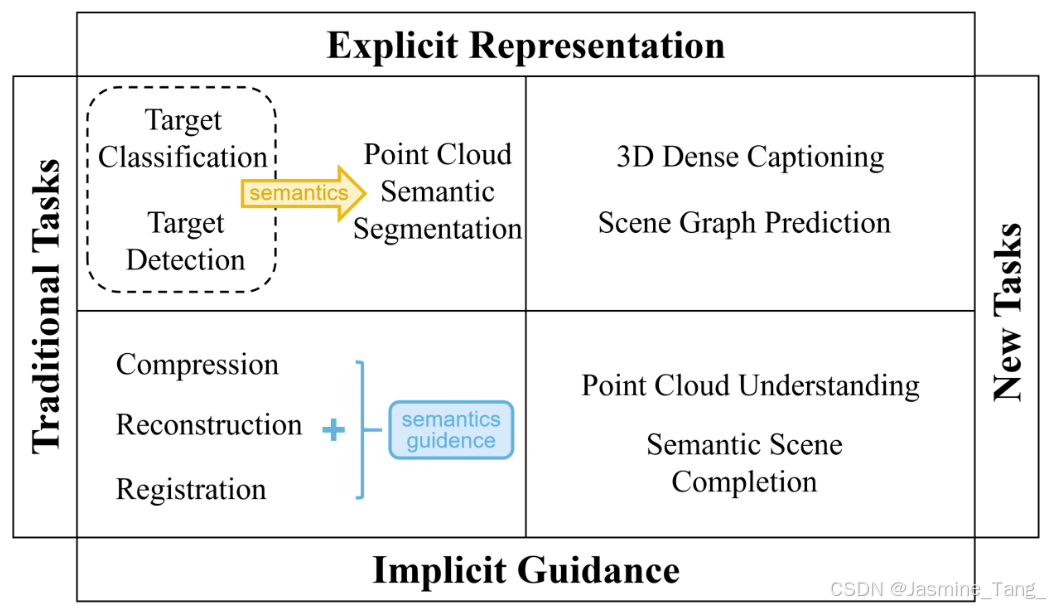
2.1 点云表示传统任务
点云处理的传统任务包括目标分类、检测、配准、压缩、重建等。点云分类旨在将一组3D点表示的对象划分为预定义类之一,常基于所提取的全局特征向量训练机器学习分类器。
点云目标分类近年所涌现的新方法都达到了非常高的精度,性能逐渐趋于饱和,预定义类的多样性及更新的对象数据集或可以为点云分类提供新的动力。点云目标检测主要在场景中用3D边界框进行目标注释,即用长方体框出检测到的目标。目标检测相对目标分类可以实现在场景上多实例的识别,点云分类倾向于单个实例的区分。点云压缩即对点云的庞大数据量根据其几何和属性信息分别进行压缩,以保障点云数据的存储/传输。点云配准即将多个视角的点云对齐成为统一视角以形成一个完整的场景点云,其本质是对在不同坐标系中的数据点进行测量及刚性变换。点云重建是指从离散的点云数据中恢复出连续的、闭合的三维表面或形状的过程。由于捕获原始点云数据时可能获取到噪声点或部分点以非均匀方式分布,因此点云重建也作为一个传统任务中的一个长期挑战。该领域学者结合语义信息属性及深度学习进行特定优化,以期望达到超越传统方法的效果。
基于我们对目前研究成果的调研,点云传统任务中均可将语义信息作为线索为任务提供辅助或输出可视化结果。其中,点云分类及目标检测在引入语义信息后演变为点云语义分割。另外,点云配准、压缩、重建等传统任务仍基于原始优化目标进行。
2.2 语义信息引入的点云新任务
人们对3D视觉理解和自然语言处理交叉领域日益增长的兴趣以及机器感知的发展促使3D点云表示产生新任务。语义信息引入的新任务主要包括上文提到的3D密集字幕任务、场景图预测、语义场景补全及点云理解。3D密集字幕任务即从检测到的目标中生成有意义的文本描述。场景图预测使用计算机图形学中的“场景图”概念对3D场景的实例及其关系进行描述,其中每个节点表示场景中的物体,每条边表示物体之间的关系。场景图预测也旨在实现从视觉到语自然语言的映射,但密集字幕任务更面向对象,侧重于对象外观的精确描述,通常会忽略实例间的复杂几何关系。二者具有相似的目的,但由于两个任务从2D不同初始逻辑演变而来,因此进行分别讨论。语义场景补全强调整个场景的语义和几何信息被联合推断,这一领域在近年来获得了巨大发展势头。相比其他任务,语义场景补全任务有相对针对性数据集,详细内容将在下一节介绍。点云理解是基于点云传统任务之上的新整合性任务,考虑多信息维度(甚至跨维度)和模态之间的底层特征共享,以提高模型的灵活性。
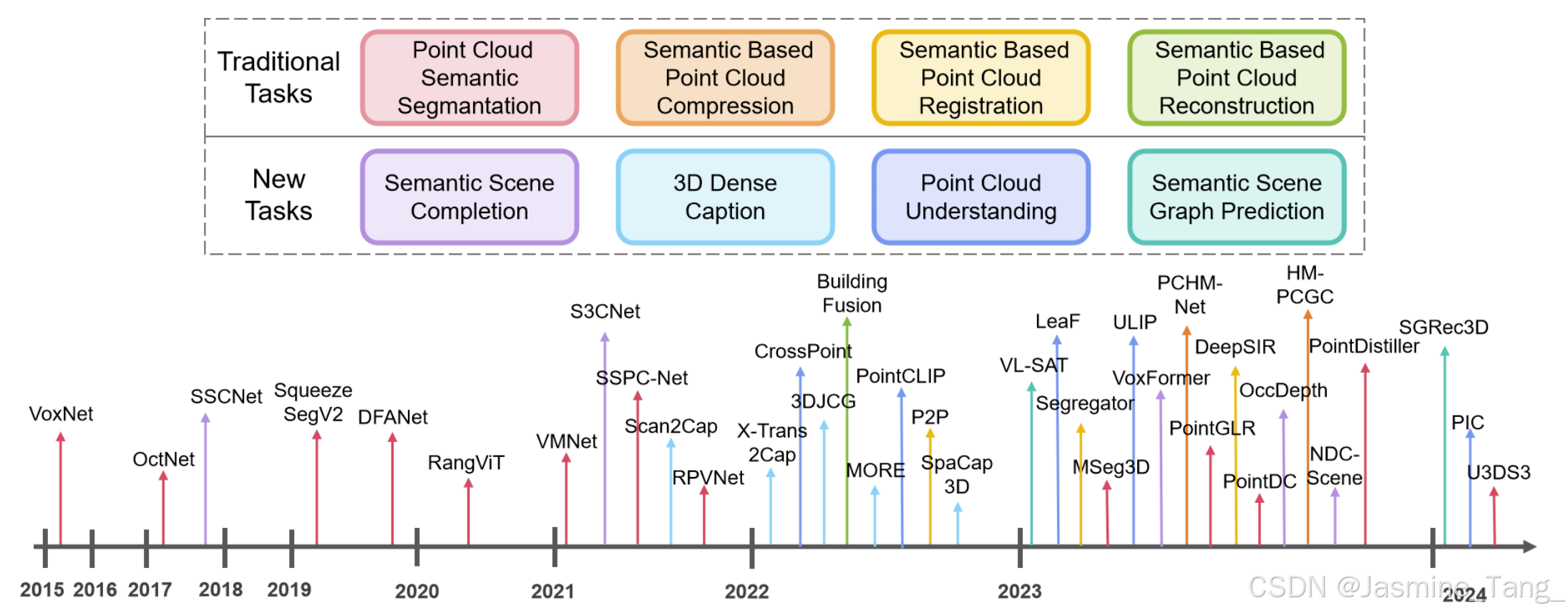
本文旨在以语义信息对点云的传统应用及新任务进行串联概述,侧重相应技术的历史发展及新应用的方向,相关技术发展如图3所示。
2.3 基于任务的公开数据集比较
在本节中,我们基于不同的语义任务总结了一些较为流行的数据集,表提供了这些数据集的描述。
2.3.1 点云语义分割相关数据集
Semantic3D
Semantic3D 数据集为自然场景提供了一个大规模的标注三维点云集合,总计包含超过四十亿个点云数据。该数据集涵盖了多种城市场景,如教堂、街道、铁轨、广场、村庄、足球场、城堡等。这些点云数据是通过先进的静态扫描技术获得的,原始三维点被分为八类,并包含了三维坐标、RGB信息、强度等多种信息。
SemanticKITTI
SemanticKitti 数据集是一个面向自动驾驶领域的大型室外三维点云数据集,专用于三维语义分割任务。该数据集是在Kitti数据集的基础上,通过实施语义分割等处理步骤所构建,其主要目标是对点云数据进行语义预测。
S3DIS
S3DIS数据集是由六个大型室内区域组成的集合,每个区域涵盖了多个场景类型,例如办公室、储藏室、走廊、会议室等。该数据集总共包含了约2.73亿个点,并使用13个语义标签进行标注。该数据集广泛应用于室内点云数据的语义分割和实例分割任务。
SemanticPOSS
SemanticPOSS 数据集是专门为研究三维语义分割任务而构建的。该数据集为自动驾驶领域中的关键任务——三维语义分割,提供了一个新颖的研究资源。它包含了2,988次复杂的激光雷达(LiDAR)扫描,以及大量的动态实例数据。这些数据采用了与SemanticKITTI数据集相同的数据格式,以便于进行跨数据集的比较和研究。
SensatUrban
SensatUrban 数据集包含近三十亿个经过丰富注释的三维点。该数据集涵盖了三个英国城市的大范围区域,总面积约为7.6平方公里的城市景观。在数据集中,每一个三维点均被归类为13个预定义的语义类别之一。
Matterport3D
Matterport3D 数据集是一个大型的 RGB-D 数据集,主要用于室内场景的理解。该数据集包含了90个真实建筑规模场景的10,800个全景视角,这些全景视角是由194,400个RGB-D图像构建而成的。每个场景都是一个包含多个房间和楼层的住宅楼,并且带有表面结构、相机机位和语义分割的注释。
SceneNN
SceneNN 数据集是一个大型的 RGB-D 室内场景数据集,包含了超过 100 个不同的室内场景。这些场景涵盖了多种不同的环境,如办公室、宿舍、教室和食品储藏室等。此数据集的语义类别集涵盖了40个不同的类别。数据集中的所有场景都被重建成了三角形网格,并且每个顶点和每个像素都有注释。%SceneNN 数据集对于研究室内场景理解、3D 语义分割、实例分割等计算机视觉任务非常有用。
ShapeNet
ShapeNet包含来自各种语义类别的3D模型,为每个模型提供广泛的语义注释,包括一致的刚性对齐、零件、双边对称平面、物理尺寸、关键字和其他注释。ShapeNet已经为300多万个模型编制了索引,其中22万个被分为3135个类别。
2.3.2 点云压缩相关数据集
用于语义引导的点云压缩的数据集与传统压缩方法中使用的数据集不同,主要是因为需要已有语义信息的点。因此,来自其他任务的数据集被频繁使用,如ModelNet40、SemanticKITTI和ShapeNet。
2.3.3 点云配准相关数据集
ModelNet40
ModelNet40数据集在点云配准领域得到了广泛的应用。该数据集由12311个网格化计算机辅助设计(CAD)模型组成,涵盖了40个人造物体类别。这些模型被划分为9843个训练形状和2468个测试形状,以便于进行模型训练和性能评估。
2.3.4 点云重建相关数据集
ScanNetV2
ScanNetV2数据集由具有丰富注释的三维室内场景重建构成,涵盖了1613个三维扫描,涉及20个不同的类别。整个数据集被划分为训练集(包含1201次扫描)、验证集(包含312次扫描)和测试集(包含100次扫描)。在此基准测试中,评估涵盖了20个语义类别,其中包括18个不同的对象类别。
VASAD
VASAD数据集由六个完整的建筑模型构成,每个模型均具备详尽的体积描述和语义标签。这些模型共同代表了超过62,000平方米的建筑楼层面积,其规模之大足以支撑基于学习方法的开发与评估。VASAD数据集的构建旨在促进点云表面重建与语义分割任务的联合研究。
2.3.5 点云语义场景图预测相关数据集
3DSSG
3DSSG数据集是一个从三维室内重构中学习三维语义场景图的大型三维数据集。该数据集在3RScan的基础上进行了扩展,并包含了语义场景图的注释,涵盖了关系、属性和类别层次结构。3DSSG的数据结构通过定义节点与边之间的一组元组来构建,其中节点代表三维扫描中的特定三维对象实例。这些节点根据其语义、类别层次结构以及描述对象实例的视觉和物理外观及其可用性的一组属性来进行定义。数据集中的边则表征了节点之间的语义关系。
2.3.6 点云3D密集字幕相关数据集
Nr3D
Nr3D数据集综合了ShapeNet和ScanNet的三维对象模型,覆盖了众多物体类别。每个对象模型均附有相应的三维点云数据及语义分割标签,且Nr3D包含41.5K的自由形式的人类描述。Nr3D数据集对于提升计算机在理解和处理三维场景中物体方面的能力具有显著的帮助作用。
ScanRefer
ScanRefer数据集基于ScanNet数据集构建,是一个专注于三维场景理解领域的重要数据集,致力于推进自然语言与三维场景交互的三维场景理解数据集。该数据集包含了800个ScanNet场景中的11,046个对象,共有51,583个自然语言描述。每个场景均包含了点云、几何图像和语义分割标签等详细信息。自然语言描述部分涉及场景中的物体、位置和动作相关的指令。ScanRefer数据集的目标是通过对自然语言表达的使用,直接在三维空间中执行对象定位,使机器能够理解和执行这些指令。
2.3.7 点云语义场景补全相关数据集
NYUv2
NYUv2数据集由1449张RGBD图像组成,这些图像包括26个场景类别的464个不同的室内场景。每张图像进行了密集的逐像素标记,且每个实例都会具有一个唯一的实例标签。每张图像的支持注释由一组3元组组成,其中
是被支持对象的区域ID,
是支持对象的区域ID, type表示支持的方向。例如,支持对象为桌子,被支持对象为水杯,方向为上面。
SUNCG
SUNCG数据集包含了45,622个室内场景。在技术层面上,该数据集允许通过设定不同的摄像机方向来获取深度图像和语义场景体。作为一个大型的合成三维场景数据集,SUNCG提供了密集的体素注释。该数据集适用于训练算法以执行场景理解任务,例如语义分割、深度估计、视觉导航等。
Scan2CAD
Scan2CAD数据集由1506个ScanNet扫描和来自ShapeNet的14225个CAD模型组成。这个数据集包含了97607个关键点对,这些关键点对分别连接着CAD模型和它们在扫描中的对应物体。数据集中的CAD模型主要包括椅子、桌子和橱柜等室内场景常见的物体。
由于篇幅原因,其余内容请直接参见论文原文,如有引用请使用bib格式或其他格式引用,祝各位科研一路顺利~

















 1066
1066

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









