








- ICLR 2021
-本文主要工作:将Transformer运用在视觉领域上
- 网络结构
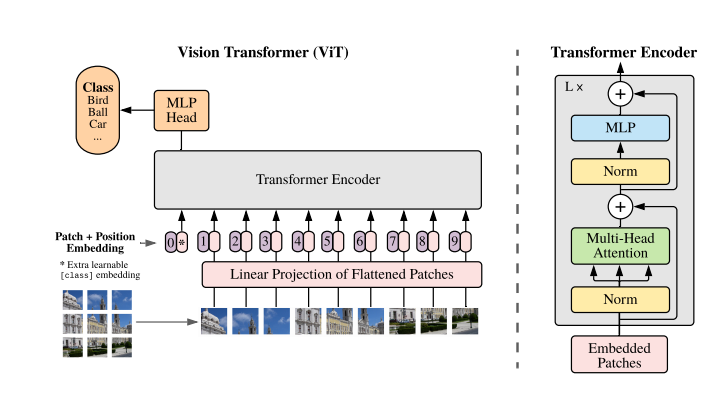
输入为一张大小为224*224的图片,将图片分成14*14个大小为16*16的patch。对每个patch进行embedding操作,使其成为一个向量。同时加入位置编码和额外的名为cls的token,用以输出分类结果
METHOD:
-token embedding
利用卷积操作将224*224的图片分割成14*14个大小为16*16的patch。具体操作为 利用num_dim个窗口大小为16*16,步长也为16的卷积核进行卷积,得到14*14*num_dim的特征图,而后进行reshape操作成196*num_dim的向量。再加入位置编码positional encoding 和 额外的token cls。一共组成197个维度为num_dim向量。
-transformer encoder
将197*num_dim 的向量输入N个到transformer的encoder层中。首先通过layer normalization进行层归一化,有助于网络收敛。再通过多头注意力机制捕获不同patch之间的关系,这个过程中,token cls会收集其他token的信息。
-classify
得到token cls之后,通过一个全连接层输出分类结果。















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









