








第十讲:交叉验证、特征选择
回顾一下上一讲的内容,如果有一个有限的假设类 ∣ H ∣ = k \lvert\mathcal{H}\rvert=k ∣H∣=k,对于给定的 γ , δ \gamma,\delta γ,δ,要保证 ε ( h ^ ) ≤ min h ∈ H ε ( h ) + 2 γ \varepsilon(\hat h)\leq\displaystyle\operatorname*{min}_{h\in\mathcal{H}}\varepsilon(h)+2\gamma ε(h^)≤h∈Hminε(h)+2γ成立,并且在事件“训练误差与泛化误差之差小于 γ \gamma γ”的概率至少为 1 − δ 1-\delta 1−δ时,需要满足:
m ≥ 1 2 γ 2 log 2 k δ = O ( 1 γ 2 log k δ ) \begin{align} m&\geq\frac{1}{2\gamma^2}\log\frac{2k}{\delta}\\ &=O\left(\frac{1}{\gamma^2}\log\frac{k}{\delta}\right) \end{align} m≥2γ21logδ2k=O(γ21logδk)
这是一个与样本复杂度相关的结论。现在我们想要将这一结论推广到无限假设类中。
4. 若 H \mathcal{H} H是无限的
我们已经证明了一些在有限假设类下非常有用的理论,然而,包括“任意以实数为参数的假设函数”(如线性分类器)在内的很多的假设类实际上包含了无数个假设函数。我们能否将有限假设类下成立的结论推广到无限假设类中呢?
我们先抛出一个不严谨的论点,也许在某些方面不够“正确”,但它比较直观。之后,我们会给出一个更好且更普遍的结论。
假设我们要将上面关于样本复杂度的式子应用在逻辑回归中,此时我们的假设类是由线性判别边界构成的,所以
H
\mathcal{H}
H是以
d
d
d个实数作为参数(如果我用逻辑回归解决
n
n
n个特征值的问题,则
d
=
n
+
1
d=n+1
d=n+1,此时逻辑回归会找到一个以
n
+
1
n+1
n+1个实数为参数的线性判别边界
g
(
θ
T
x
)
g\left(\theta^Tx\right)
g(θTx))。而我们都知道,计算机通常使用IEEE双精度浮点数(C语言中的double,
64
64
64位)来近似实数,那么在这个逻辑回归的情况下,计算机需要
64
d
64d
64d个比特位(bits)来表示这些参数。那么对我们的假设类就有
k
=
∣
H
∣
=
2
64
d
k=\lvert\mathcal{H}\rvert=2^{64d}
k=∣H∣=264d个不同的假设函数。根据上一讲最后的结论,带入
O
O
O表达式,为了保证样本复杂度中的条件
ε
h
^
≤
ε
h
∗
+
2
γ
\varepsilon{\hat h}\leq\varepsilon{h^*}+2\gamma
εh^≤εh∗+2γ的概率至少为
1
−
δ
1-\delta
1−δ,就需要满足
m
≥
O
(
1
γ
2
log
2
64
d
δ
)
=
O
(
d
γ
2
log
1
δ
)
=
O
γ
,
δ
(
d
)
m\geq O\left(\frac{1}{\gamma^2}\log\frac{2^{64d}}{\delta}\right) =O\left(\frac{d}{\gamma^2}\log\frac{1}{\delta}\right) =O_{\gamma,\delta}(d)
m≥O(γ21logδ264d)=O(γ2dlogδ1)=Oγ,δ(d)
(最后一个
O
O
O记号的下标
γ
,
δ
\gamma,\delta
γ,δ表明复杂度可能依赖于这两个隐藏参数)。从这里可以大概了解,所需训练样本的数量与模型参数的个数大约最多呈线性关系。
虽然使用 64 64 64位浮点数来推断这个结论并不能完全令人信服,但是这个结论大体上是正确的。如果要保证经验风险最小化生成的假设与最好假设间泛化误差的差距不超过 2 γ 2\gamma 2γ,则 m m m必须大于大 O O O记号中的量级,如果我们尝试最小化训练误差,为了保证学习效果我们使用了含有 d d d个参数的假设类,则所需要的训练样本的数量大致与我们假设类的参数数目呈线性关系,即 m m m与 d d d大致呈线性关系。
(到目前为止,这些结论并不能说明一个使用经验风险最小化的算法的价值。因此,虽然多数尝试最小化或估计训练误差的判别学习算法对参数个数 d d d为线性复杂度,但这个结论并不是对所有判别学习算法有效。对很多非经验风险最小化使用良好的假设保证仍是热门研究方向。)
上面推导出的结论还有一个不那么令人满意的地方——它依赖参数化 H \mathcal{H} H。虽然直观上不容易看出问题,我们将具有 n + 1 n+1 n+1个参数 θ 0 , ⋯ , θ n \theta_0,\cdots,\theta_n θ0,⋯,θn线性分类器所在的类写作 1 { θ 0 T + θ 1 T x 1 + ⋯ + θ n T x n ≥ 0 } 1\left\{\theta_0^T+\theta_1^Tx_1+\cdots+\theta_n^Tx_n\geq0\right\} 1{θ0T+θ1Tx1+⋯+θnTxn≥0},我们也可以将其写作 h u , v ( x ) = 1 { ( u 0 2 − v 0 2 ) + ( u 1 2 − v 1 2 ) x 1 + ⋯ + ( u n 2 − v n 2 ) x n ≥ 0 } h_{u,v}(x)=1\left\{\left(u_0^2-v_0^2\right)+\left(u_1^2-v_1^2\right)x_1+\cdots+\left(u_n^2-v_n^2\right)x_n\geq0\right\} hu,v(x)=1{(u02−v02)+(u12−v12)x1+⋯+(un2−vn2)xn≥0},此时有 2 n + 2 2n+2 2n+2个参数。不过,这两个式子表达的是同一个假设类 H \mathcal{H} H,即 n n n维线性分类器的集合。
为了给出一个更严谨的推导,我们先定义一些新概念。
对于某个由点 x ( i ) ∈ X x^{(i)}\in\mathcal{X} x(i)∈X构成的集合 S = { x ( 1 ) , ⋯ , x ( d ) } S=\left\{x^{(1)},\cdots,x^{(d)}\right\} S={x(1),⋯,x(d)}(并不要求是训练集),如果 H \mathcal{H} H可以实现 S S S任意一种标记方式,即对于任意集合 { y ( 1 ) , ⋯ , y ( d ) } \left\{y^{(1)},\cdots,y^{(d)}\right\} {y(1),⋯,y(d)},存在 h ∈ H h\in\mathcal{H} h∈H能够使 h ( x ( i ) ) = y ( i ) , i = 1 , ⋯ , d h\left(x^{(i)}\right)=y^{(i)},\ i=1,\cdots,d h(x(i))=y(i), i=1,⋯,d成立,我们就称 H \mathcal{H} H分散了(shatters) S S S。
对于给定假设类 H \mathcal{H} H,我们定义Vapnik-Chervonenkis维度(Vapnik-Chervonenkis dimension),写作 V C ( H ) \mathrm{VC}(\mathcal{H}) VC(H),表示能够被 H \mathcal{H} H分散的最大的集合。(如果 H \mathcal{H} H可以分散任意大小的集合,则有 V C ( H ) = ∞ \mathrm{VC}(\mathcal{H})=\infty VC(H)=∞)
举个例子,考虑下图中的点:
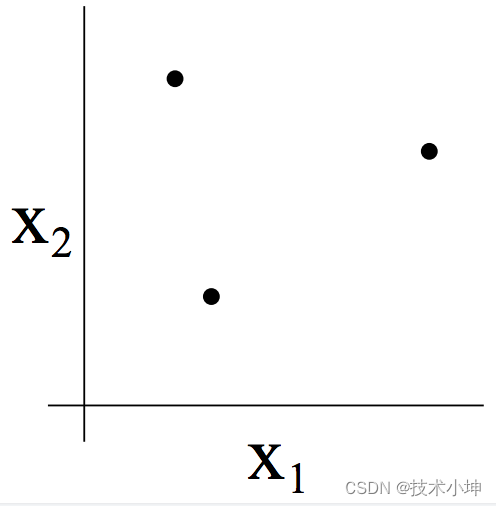
在两个维度上的( h ( x ) = 1 { θ 0 + θ 1 x 1 + θ 2 x 2 ≥ 0 } h(x)=1\left\{\theta_0+\theta_1x_1+\theta_2x_2\geq0\right\} h(x)=1{θ0+θ1x1+θ2x2≥0})线性分类器的集合 H \mathcal{H} H可以分散上面的点集吗?答案是肯定的。我们可以直接给出所有可能的八种分类标记的情况,而且对这个例子我们总是能够找到一个具有零训练误差的线性分类器(即完美分类):
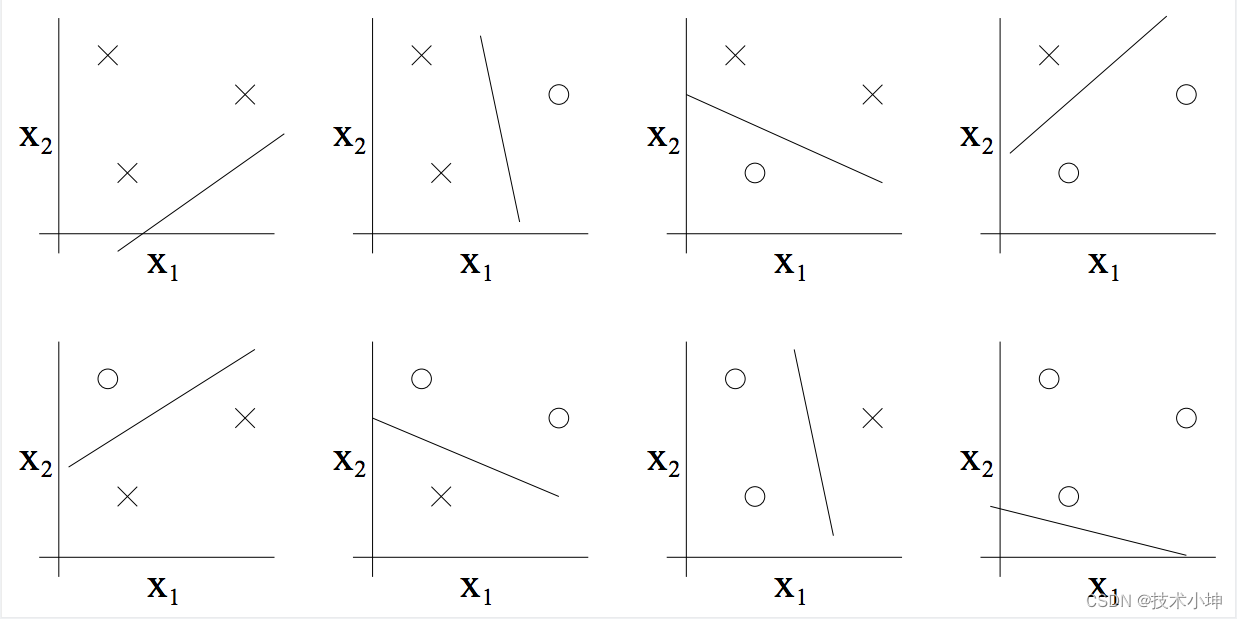
(对于上例的点集 S S S,所有可能的分类情况都有对应的二维分类器将点分散)
此外,通过一系列计算能够证明,此假设类(即二维线性分类器)不可能分开任意含有 4 4 4个点的集合(不论这四个点在 x 1 , x 2 x_1,x_2 x1,x2坐标系上如何排列,我们都无法找到一组能够将“四个点的所有可能的 x , o x,o x,o的标记情况”分开的直线)。因此, H \mathcal{H} H可以分开的集合的元素总数为 3 3 3,有 V C ( H ) = 3 \mathrm{VC}(\mathcal{H})=3 VC(H)=3。
值得注意的是,虽然 H \mathcal{H} H的 V C \mathrm{VC} VC维是 3 3 3,但也存在分不开的布局。比如,如果三点共线(如下方左图所示),则存在二维线性分类器无法分开的标记情况(如下方右图所示):
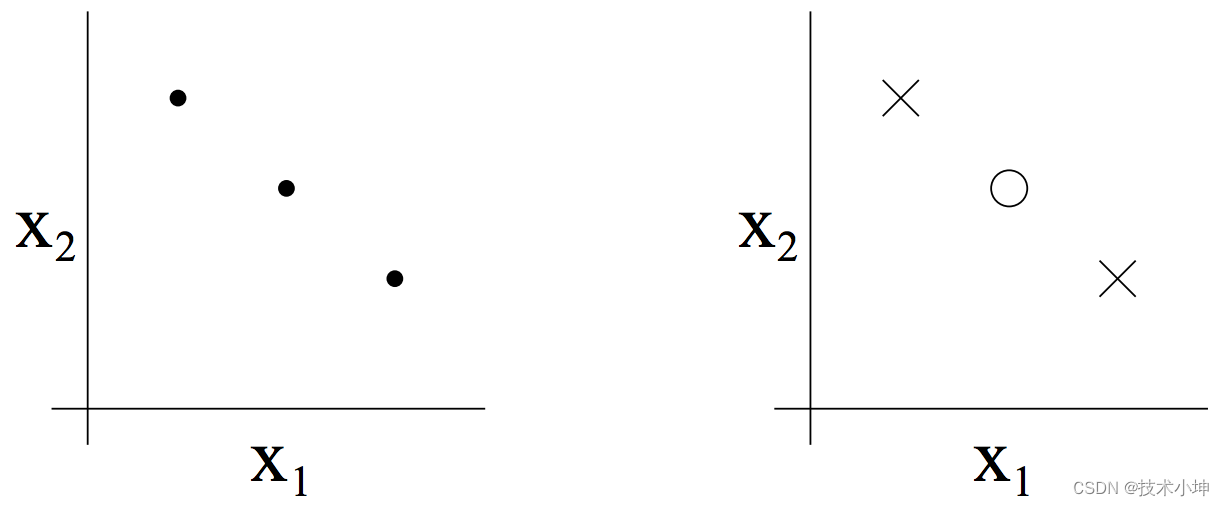
(因为已经存在某个 3 3 3个点的集合可以被二维线性分类器分散,所以这并不影响二维线性分类器的 V C \mathrm{VC} VC维为 3 3 3。)
也就是说,从 V C \mathrm{VC} VC维的定义有,为了证明 V C ( H ) \mathrm{VC}(\mathcal{H}) VC(H)至少是 d d d,那么我们只需要找到一个大小为 d d d的集合可以被 H \mathcal{H} H散列即可。
定理,给定 H \mathcal{H} H,令 d = V C ( H ) d=\mathrm{VC}(\mathcal{H}) d=VC(H),在保证事件“训练误差与泛化误差在 γ \gamma γ以内”的概率至少为 1 − δ 1-\delta 1−δ的条件下,对于 h ∈ H h\in\mathcal{H} h∈H有:
∣ ε ( h ) − ε ^ ( h ) ∣ ≤ O ( d m log m d + 1 m log 1 δ ) \left\lvert\varepsilon(h)-\hat\varepsilon(h)\right\rvert\leq O\left(\sqrt{\frac{d}{m}\log\frac{m}{d}+\frac{1}{m}\log\frac{1}{\delta}}\right) ∣ε(h)−ε^(h)∣≤O(mdlogdm+m1logδ1)
因此,在概率至少为 1 − δ 1-\delta 1−δ时可以得到:
ε ( h ^ ) ≤ ε ( h ∗ ) + O ( d m log m d + 1 m log 1 δ ) \varepsilon\left(\hat h\right)\leq\varepsilon\left(h^*\right)+O\left(\sqrt{\frac{d}{m}\log\frac{m}{d}+\frac{1}{m}\log\frac{1}{\delta}}\right) ε(h^)≤ε(h∗)+O(mdlogdm+m1logδ1)
换句话说,如果一个假设类具有有限的 V C \mathrm{VC} VC维度,则当 m m m越来越大时会产生一致收敛。同上一讲一样,我们可以从中得到一个使用 ε ( h ∗ ) \varepsilon\left(h^*\right) ε(h∗)表示的 ε ( h ) \varepsilon(h) ε(h)的界限。我们还能够得到下面的推论:
推论,对于 h ∈ H h\in\mathcal{H} h∈H(由于 ε ( h ^ ) ≤ ε ( h ∗ ) + 2 γ \varepsilon\left(\hat h\right)\leq\varepsilon\left(h^*\right)+2\gamma ε(h^)≤ε(h∗)+2γ),要保证 ∣ ε ( h ) − ε ^ ( h ) ∣ ≤ γ \left\lvert\varepsilon(h)-\hat\varepsilon(h)\right\rvert\leq\gamma ∣ε(h)−ε^(h)∣≤γ的概率至少为 1 − δ 1-\delta 1−δ,则必须满足 m = O γ , δ ( d ) m=O_{\gamma,\delta}(d) m=Oγ,δ(d)。
也就是说,要保证从 H \mathcal{H} H中选取的假设能够“学的好”,所需的训练样本的个数与 H \mathcal{H} H的 V C \mathrm{VC} VC维数呈线性关系。这个结论也可以解释为,对于“大多数”假设类(我们假设”合理的“参数化),其 V C \mathrm{VC} VC维与其参数个数呈大致的线性关系(其实这两者的大小通常差不多,比如使用维度为 n n n逻辑回归作为线性分类器时,一共需要 n + 1 n+1 n+1个参数,而 n n n维线性分类器的假设类的 V C \mathrm{VC} VC维是 n + 1 n+1 n+1)。综合上面的各结论有,(对于一个尝试最小化训练误差)算法所需的训练样本的数量通常与假设类 H \mathcal{H} H参数的个数呈大致上的线性关系。这也表明了样本复杂度的上下界都是由 V C \mathrm{VC} VC维给出的。
补充一点别的知识:回忆前几讲中的支持向量机算法,我们知道SVM会使用核函数将输入属性投影在无限维的特征空间中。那么,看起来SVM算法的 V C \mathrm{VC} VC维数是无穷。不过,具有较大间隔的线性分类器通常 V C \mathrm{VC} VC维都不会太大。我们可以做一个非正式的简要解释。给定了一个点集,如果我们只考虑使用具有较大间隔的线性分类器分隔这些点,那么我们的假设类将只包含这些间隔较大的判别边界。现在假设这个间隔就是 γ \gamma γ,那么假设类中将不会有太靠近某个点的判别边界(假设类中的假设函数到各点的距离都不会小于 γ \gamma γ)。如果点集中的点都分布在一个半径为 R R R的圆内 ∥ x ( i ) ∥ ≤ R \left\lVert x^{(i)}\right\rVert\leq R x(i) ≤R,那么对于可以分隔这个点集的分类器 h h h(间隔至少为 γ \gamma γ)所在的假设类 H \mathcal{H} H,有 V C ( H ) ≤ ⌈ R 2 4 γ 2 ⌉ + 1 \mathrm{VC}(\mathcal{H})\leq\left\lceil\frac{R^2}{4\gamma^2}\right\rceil+1 VC(H)≤⌈4γ2R2⌉+1( ⌈ x ⌉ \lceil x\rceil ⌈x⌉表示对 x x x向上取整)。关于这个结论的证明我们就不展开介绍了。通过这个结论我们可以知道, V C \mathrm{VC} VC维数的取值范围与输入特征的维数是没有关系的。也就是说,即使输入 x x x来自无限维空间,但只要我们令分类器必须满足一个较大的间隔时, V C \mathrm{VC} VC维实际上是被限制在一个比较小的数字上。所以,如果给定SVM一个需要满足的间隔,SVM将自动找到一个具有较小 V C \mathrm{VC} VC维的假设类,算法并不会发生过拟合的现象。
关于经验风险最小化,如果我们只看其中的一个样本 x x x,对于假设函数 h θ ( x ) = g ( θ T x ) h_\theta(x)=g\left(\theta^Tx\right) hθ(x)=g(θTx),那么指示函数 1 { h θ ( x ) ≠ y } 1\left\{h_\theta(x)\neq y\right\} 1{hθ(x)=y}将会型为一个阶梯函数,假设我们拿到的是一个负样本 y = 0 y=0 y=0,那么如果 θ T x > 0 \theta^Tx\gt0 θTx>0,也就是误分类,此时阶梯函数值为 1 1 1,如果 θ T x ≤ 0 \theta^Tx\leq0 θTx≤0,那么就是分类正确,此时阶梯函数值为 0 0 0。我们所要做的就是找到一组 θ \theta θ,能够使这个阶梯函数最小化,也就是能够正确分类训练样本 x x x(即令指示函数为 0 0 0)。而这个指示函数是一个非凸函数,使用线性分类器最小化训练误差是一个NP困难问题。我们前面介绍的逻辑回归和支持向量机都是在使用凸近似逼近经验风险最小化这个NP困难问题。
第七部分:正则化及模型选择
有时,遇到一个问题,我们需要在几个不同的模型间取舍。比如,我们在使用多项回归模型 h θ ( x ) = g ( θ 0 + θ 1 x + θ 2 x 2 + ⋯ + θ k x k ) h_\theta(x)=g\left(\theta_0+\theta_1x+\theta_2x^2+\cdots+\theta_kx^k\right) hθ(x)=g(θ0+θ1x+θ2x2+⋯+θkxk)时,需要确定 k k k到底取 1 , 2 , ⋯ 10 1,2,\cdots10 1,2,⋯10中的那个值最为合适。那么,如何自动的让模型选择过程在偏差与方差间做出权衡?(原文使用”邪恶的双胞胎“来形容偏差与方差,可能使用”异卵双生“更合适)或者说,想要自动选择局部加权回归中的带宽参数 τ \tau τ,或是希望自动确定 l 1 \mathscr{l}_1 l1正则化的SVM中的参数 C C C(也就是SVM软边界中在间隔大小与惩罚力度之间做权衡的系数),我们应该如何去做呢?
为了更具体的描述问题,我们在本讲中均假设将要从有限的模型集合 M = { M 1 , ⋯ , M d } \mathcal{M}=\left\{M_1,\cdots,M_d\right\} M={M1,⋯,Md}中选取模型。比如说在第一个例子中, M i M_i Mi就表示 i i i阶多项回归模型。(推广到无限的 M \mathcal{M} M也并不难。如果我们尝试从无限的模型集合中做出,使用带宽参数的例子 τ ∈ R + \tau\in\mathbb{R}^+ τ∈R+,我们就可以离散化 τ \tau τ,然后令 M i M_i Mi为 τ i \tau_i τi的函数,再从中选择可能的 M i M_i Mi。一般的,本讲描述的算法可以看做是在模型空间中做优化选择,我们同样可以将这个选择过程应用于无限模型集合中。)再比如我们需要在SVM、神经网络和逻辑回归中做出选择,那么 M \mathcal{M} M将包含这些模型。
1. 交叉验证(Cross validation)
像以前一样,假设有训练集 S S S,从前面的经验风险最小化,我们可以得出一个关于模型选择的、乍看起来像个”算法“的步骤:
- 用 S S S训练每一个 M i M_i Mi,从而得到相应的假设函数 h i h_i hi;
- 选择训练误差最小的假设函数。
遗憾的是,这个”算法“并不能符合我们的预期。比如说用这个”算法“要从多项模型集合中选择阶数,我们知道对于多项回归模型,其阶数越高则对训练集的拟合越好,也就是训练误差越小。于是,该”算法“会始终选择阶数高、方差大的多项模型,而我们通常是不会使用这种模型的。
下面是一个比较好的算法,称为保留交叉验证(hold-out cross validation)(有时也称为简单交叉验证(simple cross validation)):
- 随机把训练集 S S S分为两部分, S t r a i n S_\mathrm{train} Strain(假设有训练集 70 70% 70的样本)和 S c v S_\mathrm{cv} Scv(剩下 30 30% 30的样本),而这个 S c v S_\mathrm{cv} Scv称为保留交叉验证集;
- 仅使用 S t r a i n S_\mathrm{train} Strain训练每一个模型 M i M_i Mi,进而得到相应的假设函数 h i h_i hi;
- 使用保留交叉验证集测试 h i h_i hi,选出测试结果 ε ^ S c v ( h i ) \hat\varepsilon_{S_\mathrm{cv}}(h_i) ε^Scv(hi)最小的假设函数。( ε ^ S c v ( h i ) \hat\varepsilon_{S_\mathrm{cv}}(h_i) ε^Scv(hi)表示 h i h_i hi在训练集 S c v S_\mathrm{cv} Scv上的训练误差。)
通过使用模型没有训练过的样本集 S c v S_\mathrm{cv} Scv的测试,我们对 h i h_i hi的泛化误差就有了更好的估计,从而选择一个估计泛化误差最小的假设函数。我摸一般使用 1 4 \frac{1}{4} 41到 1 3 \frac{1}{3} 31的样本做保留交叉验证集合,而本例中的 30 30% 30是常见的选择。
有时第三步也会选择按照 a r g min i ε ^ S c v ( h i ) \mathrm{arg}\displaystyle\operatorname*{min}_i\hat\varepsilon_{S_\mathrm{cv}}(h_i) argiminε^Scv(hi)直接输出相应的模型 M i M_i Mi,然后在使用整个训练集 M M M重新训练 M i M_i Mi。(这通常是个好点子,不过一些对初始化条件或数据的扰动非常敏感的算法来说,并不能使用这种方法。对这些算法来说,模型在 S t r a i n S_\mathrm{train} Strain上表现的很好并不能得出它在 S c v S_\mathrm{cv} Scv上也会表现的很好。所以,对这种算法最好不要使用这个重新训练的步骤。)
不过,保留交叉验证会“浪费”掉那 30 30% 30的训练样本。即使我们使用改进的第三步,用整个训练集重新训练模型,但对于前面的模型选择过程,我们仍旧每次只使用了 0.7 m 0.7m 0.7m个训练样本,而不是包含 m m m个样本的训练集。这种算法在训练样本有冗余或容易得到时,是没有什么问题的,但对于训练样本稀缺的学习问题(比如一共只有 m = 20 m=20 m=20个样本),我们就需要更好的算法了。
下面的算法称作** k k k重交叉验证( k k k-fold cross validation)**,该算法每次会保留更少的验证样本:
- 随机把训练集 S S S分为 k k k个子集,每个子集有 m k \frac{m}{k} km个样本,记为 S 1 , ⋯ , S k S_1,\cdots,S_k S1,⋯,Sk;
- 对每个模型 M i M_i Mi,我们执行下面的操作:
For
j
=
1
,
⋯
,
k
j=1,\cdots,k
j=1,⋯,k
* 使用$S_1\cup\cdots\cup S_{j-1}\cup S_{j+1}\cup\cdots\cup S_k$(即使用除$S_j$以外的所以子集)训练$M_i$模型,从而得到假设$h_{ij}$;
* 使用$S_j$测试$h_{ij}$,从而得到$\hat\varepsilon_{S_j}\left(h_{ij}\right)$。
M i M_i Mi的泛化误差估计为 ε ^ S j ( h i j ) \hat\varepsilon_{S_j}\left(h_{ij}\right) ε^Sj(hij)(对于每个 j j j)的平均值。
- 选择具有最小泛化误差的 M i M_i Mi,然后使用整个训练集 S S S重新训练模型,这次得到的假设函数就是最终的输出。
我们通常使用 k = 10 k=10 k=10重交叉验证。在这个算法中,虽然每次保留的数据仅为 1 k \frac{1}{k} k1(已经比原始的保留交叉验证小了很多),但整个 k k k重计算过程的代价将比原始的保留交叉验证大很多,因为我们需要训练每个模型 k k k次。
尽管 k = 10 k=10 k=10是我们的常用选择,但是在那些样本非常珍贵的学习问题中,我们可能会选择极端的算法——令 k = m k=m k=m,从而使得每次保留的样本达到最小。在这个算法中,我们将使用 m − 1 m-1 m−1个样本训练模型,用剩下的 1 1 1个保留样本作为测试,模型的泛化误差将通过求这 m = k m=k m=k次训练的平均误差得到。由于该算法仅保留一个样本用做测试,它也被称作留一交叉验证(leave-one-out cross validation)。
上面我们介绍了模型选择时交叉验证算法的几个版本,这些算法还有更简单的用途——评估单个模型或算法的效果。举个例子,如果我们实现了一个学习算法,现在想要评估它在应用中的效果(或者我们发明了一个新的学习算法,并想要在论文中说明它在不同测试集上的表现时),那么交叉验证就给出了一个合理的方法。
2. 特征选择
特征选择是模型选择的一个非常重要的情形,我们把它拿出来单独介绍。假设有一个特征值 n n n非常大(比如 n ≫ m n\gg m n≫m)的监督学习问题,但是我们怀疑这些特征中仅有一小部分与学习问题有关。即使对 n n n个特征使用非常简单的线性分类器(比如第三讲介绍的感知算法),假设类的 V C \mathrm{VC} VC维数也会为 O ( n ) O(n) O(n)的量级,除非有对于 n n n来说大小相当的训练集,否则模型就会存在过拟合问题。
在这种情况下,我就可以使用特征选择算法减小特征值的数量。对于包含 n n n个特征值的集合,有 2 n 2^n 2n种特征值子集(因为 n n n个特征值的中的每一个都包含或不包含在子集中这两种状态)。于是,我们可以把特征选择看做一种在 2 n 2^n 2n个可能的模型中做出选择的模型选择问题。不过,对于过大的 n n n,直接训练 2 n 2^n 2n个模型并进行比较的代价非常大,所以我们通常使用某种启发式搜索过程来寻找好的特征值子集。下面的搜索过程称为向前搜索(forward search):
- 初始化 F = ∅ \mathcal{F}=\emptyset F=∅;
- 重复
{
(a) 循环 i = 1 , ⋯ , n i=1,\cdots,n i=1,⋯,n,如果 i ∉ F i\notin\mathcal{F} i∈/F,令 F i = F ∪ { i } \mathcal{F}_i=\mathcal{F}\cup\{i\} Fi=F∪{i},然后使用某种交叉验证来估计特征 F i \mathcal{F}_i Fi。(即仅使用 F i \mathcal{F}_i Fi中的特征训练模型,然后估计模型的泛化误差。)
(b) 令 F \mathcal{F} F为步骤(a)中找到的最佳特征子集。
}
3. 选择并输出上面的搜索过程得到的最佳的特征子集。
外层循环的终止条件可以设置为当 F = { 1 , 2 , ⋯ , n } \mathcal{F}=\{1,2,\cdots,n\} F={1,2,⋯,n}变为特征值全集时,也可以设置为当 ∣ F ∣ \left\lvert\mathcal{F}\right\rvert ∣F∣达到一个阈值时(也就是我们允许算法使用的特征值个数的上限)。
上面的算法称为封装特征选择(wrapper model feature selection),因为算法中对模型有一个“封装”的过程,算法会重复调用模型检查评估不同特征子集的效果。除了向前搜索之外,我们还可以使用别的搜索过程,比如向后搜索(backward search),该算法从全集 F = { 1 , ⋯ , n } \mathcal{F}=\{1,\cdots,n\} F={1,⋯,n}开始,然后每次删除一个特征值(同向前搜索评估每一个特征值的添加一样,向后搜索用相同的方法评估每一个特征值的删除),直到 F = ∅ \mathcal{F}=\emptyset F=∅。
虽然封装特征选择算法通常都很奏效,但这个算法的计算量较大,因为它会不断的调用学习算法评估特征子集。完成整个向前搜索算法(算法在 F = { 1 , ⋯ , n } \mathcal{F}=\{1,\cdots,n\} F={1,⋯,n}时停止)需要调用学习算法大约 O ( n 2 ) O\left(n^2\right) O(n2)次。(在计算资源能够满足要求的情况下可以使用这些算法,但是对于诸如文本分类的问题,特征值集合可以轻易达到几万个的数量级,如果再使用搜索算法就有些吃力了。)
(向前/向后搜索通常都不会找到最好的特征子集,实际上寻找最好的特征子集是一个NP困难问题。所以,相比较而言,这种搜索算法的效果通常都挺不错。)
下面介绍**过滤特征选择(Filter feature selection)**算法,该算法使用启发式且计算量更小的方法选择特征子集(不过,这种算法下相应的泛化误差可能会比搜索算法大)。算法的思路就是使用 S ( i ) S(i) S(i)给特征 x i x_i xi“打分”,看 x i x_i xi能够为标记为 y y y的类型提供多少信息,接下来就是简单的选择 k k k个 S ( i ) S(i) S(i)最高的特征值了。
“打分”函数 S ( i ) S(i) S(i)的一种可能的定义:测量训练数据中 x i x_i xi与 y y y的相关度。该算法可能会使得我们选择的都是与标签 y y y强相关的特征值。在实践中,我们通常选择能够表示 x i x_i xi与 y y y间的互信息(mutual information) M I ( x i , y ) \mathrm{MI}\left(x_i,y\right) MI(xi,y)的 S ( i ) S(i) S(i):
M I ( x i , y ) = ∑ x i ∈ { 1 , 0 } ∑ y ∈ { 1 , 0 } p ( x i , y ) log p ( x i , y ) p ( x i ) p ( y ) \mathrm{MI}\left(x_i,y\right)=\sum_{x_i\in\{1,0\}}\sum_{y\in\{1,0\}}p\left(x_i,y\right)\log\frac{p\left(x_i,y\right)}{p\left(x_i\right)p(y)} MI(xi,y)=xi∈{1,0}∑y∈{1,0}∑p(xi,y)logp(xi)p(y)p(xi,y)
(上面的式子假设 x i x_i xi和 y y y都是二元取值的变量,而更加一般化的式子应该是计算取值域内所有变量的情况之和。)关于 p ( x i , y ) p\left(x_i,y\right) p(xi,y)、 p ( x i ) p\left(x_i\right) p(xi)和 p ( y ) p(y) p(y)的概率可以从训练集的经验分布中求得。
为了直观的解释这个“打分”函数的作用,应注意到互信息也可以表示成KL散度:
M I ( x i , y ) = K L ( p ( x i , y ) ∥ p ( x i ) p ( y ) ) \mathrm{MI}\left(x_i,y\right)=\mathrm{KL}\left(p\left(x_i,y\right) \parallel p\left(x_i\right)p(y)\right) MI(xi,y)=KL(p(xi,y)∥p(xi)p(y))
在问题集3中有更多关于KL散度的信息,不过在这里,KL散度给出了衡量 p ( x i , y ) p\left(x_i,y\right) p(xi,y)和 p ( x i ) p ( y ) p\left(x_i\right)p(y) p(xi)p(y)间概率分布的差异程度的方法。如果 x i x_i xi与 y y y是独立随机变量,则有 p ( x i , y ) = p ( x i ) p ( y ) p\left(x_i,y\right)=p\left(x_i\right)p(y) p(xi,y)=p(xi)p(y),则这两个分布的KL散度为 0 0 0。这与“ x i x_i xi与 y y y相互独立则 x i x_i xi并不携带与 y y y相关的信息”的观点一致。那么此时, x i x_i xi的得分 S ( i ) S(i) S(i)就应该很小。相反,如果 x i x_i xi携带的信息与 y y y高度相关,那它们间的互信息 M I ( x i , y ) \mathrm{MI}\left(x_i,y\right) MI(xi,y)将会非常大。
现在就有了一个关于特征值 S ( i ) S(i) S(i)的排序,那么我们该选择前多少个特征值呢?其中一个“业界标准方法”就是使用交叉验证来判断究竟该选择多少个特征值。比如当我们使用朴素贝叶斯算法做文本分类时,会遇到词汇表条目数 n n n过大的问题,而使用这个方法通常能够非常有效的提高分类器准确性。















 441
441











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









