







一阶段目标检测系列文章
目标检测6——一阶段目标检测概述
目标检测7——SSD
目录
一、Introduction
- SSD: Single Shot MultiBox Detector
- SSD300-VOC2007测试集上达到 74.3% mAP 以及 59 FPS
- SSD512- VOC2007测试集上达到了 76.9% mAP 以及 22 FPS
- 超越当时的 Faster RCNN (73.2% mAP 以及 7FPS) 和 YOLOv1 (63.4 mAP 以及 45 FPS)
二、SSD Network Architecture
1. Network Architecture


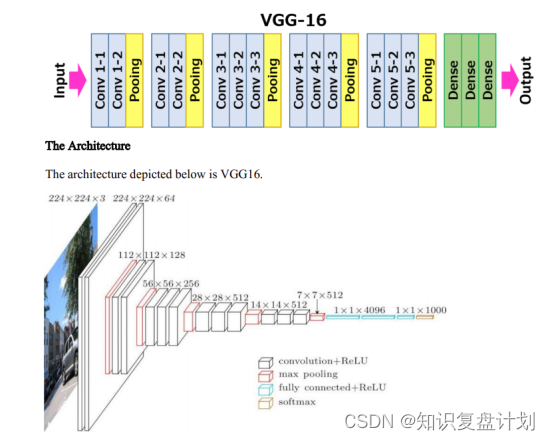
SSD采用的主要网络是VGG16,对其进行了以下修改:
- 为了不改变 Based Network 最后 Conv5_3 层 Feature Map 的大小:
- 去掉所有的 Dropout 层和 FC8 层
- 将 FC6 和 FC7 改成卷积层
- 将 pool5 从 2×2-s2 改成 3×3-s1
- Multi-scale feature maps for detection
- 通过6个不同特征尺度的特征提取层,分别提取不同尺度的 Feature Map
- SSD在VGG16之后又增加了6个辅助卷积层。将添加其中五个用于目标检测
- 新增 Conv6、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2
- Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2 就可以提取 6 个不同尺度的特征
- Convolutional predictors for detection
- 经过卷积进行特征提取后,我们会得到 6 个大小为 m×n (位置数)、p 个通道的 Feature,然后在该 m×n×p 的 Feature Map 上应用 3×3 的卷积
- 对于每个位置,我们都有 k 个默认框 (4或6),并且这个 k 个边界框具有不同的尺寸和长宽比
- 为了计算 c class scores 和相对于 GT Box 的 4 个 offsets,对于每个 Feature Map,我们需要对其做两次 3×3 的卷积
- 一个 k×4 的卷积,对于给定位置的 k 个默认框,产生 k×4 个相对于 GT Box 的 4 个 offsets
- 一个 k×c 的卷积,对于给定位置的 k 个默认框,产生 k×c 个类别的分数
- 因此,我们会得到 m×n×k×(c+4) 个输出(其中 c 包含 20 个物体类别和 1 个背景类别)
2. Multi-scale feature maps for detection
随着CNN逐渐降低空间维度,特征图的分辨率也随之降低,SSD使用比较小的特征图来检测较大尺度的物体,比较大的特征图来检测较小尺度的物体,例如 (a) 与 (c),4×4 特征图用于检测较大尺度的物体

多尺度特征图 (Multi-scale feature maps) 显着提高了准确性,如下所示:

3. Default boxes
默认框 (Default box) 相当于 Faster R-CNN 中的瞄点 (anchors) ,SSD 会在不同尺度大小大的 Feature Map 上提取默认框
- SSD 为每个 feature map layer 定义了 scale 的值,从左边开始,以 Conv4_3 为
s
m
i
n
=
0.2
s_{min}=0.2
smin=0.2,然后线性增加到最右边的层
s
m
a
x
=
0.9
s_{max}=0.9
smax=0.9, 因此对于第k个特征图(m个特征图)以及 aspect ratio={1, 2, 3, 1/2, 1/3},scale 为:

- 对于 aspect ratio=1 时,还设置了一个特殊的 scale: s k ′ = s k ⋅ s k + 1 s_k'=\sqrt{s_k\cdot s_{k+1}} sk′=sk⋅sk+1
- 那么 default box 的 w 和 h 的计算如下: w = s c a l e ⋅ a s p e c t r a t i o 、 h = s c a l e a s p e c t r a t i o w=scale \cdot \sqrt{aspect \ ratio}、h=\frac{scale}{\sqrt{aspect \ ratio}} w=scale⋅aspect ratio、h=aspect ratioscale
因此,每个特征层上的每个特征点对应的默认框数量分别为4、6、6、6、4、4,且总共有 8732 个默认框(均匀密集抽样)


三、Training
1. Matching strategy
正负样本的选取:为了确定哪些 default boxes 应用于 ground truth detection 并训练相应的网络,我们需要做锚点匹配
- 正样本
- 对于每个 gt box,去匹配跟它具有最高 IoU 的 default boxes
- 与 gt box 的 IoU > 0.5 的 default boxes 也进行匹配
- 负样本
- 与 gt box 的 IoU < 0.5 的 default boxes 也进行匹配
- Hard Negtive Mining
- NOTE: Positive Boxes:Negative Boxes = 1:3
2. Loss Function
在SSD中,损失函数被定义为类别损失 (confidence loss, conf) 与定位损失 (locatization loss, loc) 的加权和

localization loss

confidence loss

3. Hard Negative Mining
8732 个默认框中的大多数框都是负的。直接使用所有负框会导致训练期间严重的类别不平衡,因此,一旦匹配完成,仅保留那些具有最高置信度损失的负框,使得正负框之间的比率至少为1:3.
4. Data Augmentation
通过翻转、裁剪和颜色失真来增强数据,为了处理各种对象大小和形状的变体,每个训练图像通过以下选项之一进行随机采样:
- 原始输入图像
- 对 IoU 为 0.1、0.3、0.5、0.7 或 0.9 的 patch 进行采样
- 随机采样 patch
5. Atrous Convolution
- 空洞卷积/扩张卷积
- VGG16 中的 FC6 和 FC7 改为卷积层 Conv6、Conv7,且这两层使用的时空洞卷积
- 可以获得更大的感受野
- 同时与传统卷积相比,参数数量相对较少
四、Interfence
在推理过程中,把图片输入到模型中我们就会得到 8732 个框(包括类别置信度,位置偏移量)。
- 首先,根据类别置信度确定其类别,并过滤调属于背景的预测框
- 然后,根据置信度阈值过滤掉阈值较低的预测框
- 对留下的预测框进行解码
- 根据 default box + offset 做线性转换得到真实的位置参数
- 还需要做clip,防止预测框超出图片位置
- 根据置信度进行降序排列,然后仅保留 top-k (如400) 个预测框
- 最后,运用NMS算法,过滤掉那些重叠度较大的预测框就得到预测结果了

五、Reference
- SSD: Single Shot MultiBox Detector
- PPT-SSD: Single Shot MultiBox Detector
- 睿智的目标检测23——Pytorch搭建SSD目标检测平台-CSDN博客
VGG16















 377
377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









