







R语言
R语言学习笔记——入门篇:第二章-创建数据集
一、数据集的概念
- 进行数据分析的第一步就是需要创建一个含有信息的数据集。
其在R中大致被分为两步:
1.选择一种数据集来存放数据
2.将数据导入这种数据集中 - 数据集:通常是由数据构成的一个矩形数组,行表示观测,列表示变量(不同学家对其称呼不同)。
- 数据类型:数值型,字符型,逻辑性(bool型TRUE/FALSE,R中区分大小写),复数型(序数)和原生型(字节)
二、数据结构
数据结构:标量,向量,矩阵,数组,数据框,列表。
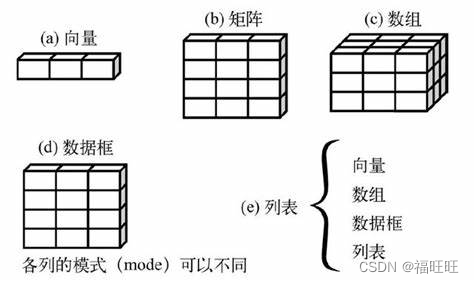
2.1、向量
2.1.1、基础概念
- 向量:一种用于存储数值型,字符型,逻辑型数据的一维数组
- 创建方法:
x <- c( )
- 示例:
a <- c(1,2,3,4) #数值型向量
b <- c("one","two","three","four") #字符型向量
c <- c(TRUE,FALSE,TRUE,FALSE) #逻辑型向量
- 注意:单个向量中的数据必须拥有相同的数据类型
- 标量:只含一个元素的向量
2.1.2、数据的提取
- 用 [ ] 来提取向量中的数据
- 数值之间使用 冒号(:) 可以生成一个数值序列。如c(1:4)等价于c(1,2,3,4)
- 示例:
# 向量的创建
x1 <- c("G", "I", "B", "H") #创建由GIBH四个英文大写字母的向量
x1[2] #用英文中括号进行提取,对向量x的第二位元素提取
x1[2:4] #提取向量x的第2~4位元素
x1[c(2,4)] #提取向量x的第2和第4位元素
x1[c(1:2,4)] #提取向量x的第1~2和第4位元素
#错误用法
x1[2,4]
x1[1:2,4]
- 结果:
> x1 <- c("G", "I", "B", "H") #创建由GIBH四个英文大写字母的向量
> x1[2] #用英文中括号进行提取,对向量x的第二位元素提取
[1] "I"
> x1[2:4] #提取向量x的第2~4位元素
[1] "I" "B" "H"
> x1[c(2,4)] #提取向量x的第2和第4位元素
[1] "I" "H"
> x1[c(1:2,4)] #提取向量x的第1~2和第4位元素
[1] "G" "I" "H"
> #错误用法
> x1[2,4]
Error in x1[2, 4] : incorrect number of dimensions
> x1[1:2,4]
Error in x1[1:2, 4] : incorrect number of dimensions
2.2、矩阵
2.2.1、基础概念
- 矩阵:一种用于存储数值型,字符型,逻辑型数据的二维数组,每个元素要求数据类型相同。
- 创建方法:
x <- matrix(vector, nrow = number_of_rows, ncol = number_of_columns , byrow = TRUE/FALSE, dimnames = list(rownames,colnames))
# vector:数组中的数据,数据
# nrow行的维数
# ncol列的维数
# byrow表明矩阵按行填充(TURE)或按列填充(FALSE)
# dimnames:可选,各维度名称标签,各维度名称
- 也可以在向量基础上利用 dim( ) 函数升阶为矩阵(/数组)
- 例如:
b <- c(1,2,3,4)
dim(b) <- c(2,2)
class(b)
> b <- c(1,2,3,4)
> dim(b) <- c(2,2)
> b
[,1] [,2]
[1,] 1 3
[2,] 2 4
> class(b)
[1] "matrix" "array"
- 示例:
a <- c("A1","A2")
b <- c("B1","B2","B3","B4")
x <- matrix(1:8,2,4,TRUE,list(a,b))#按行排列
x
y <- matrix(1:8,2,4)#默认按列排列
y
- 结果:
> x <- matrix(1:8,2,4,TRUE,list(a,b))
> x
B1 B2 B3 B4
A1 1 2 3 4
A2 5 6 7 8
> y <- matrix(1:8,2,4)
> y
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
2.2.2、数据的提取
- 使用下标和方括号来选择矩阵中的列,行或者元素。
- x[i,]指矩阵x中的第i行
- x[,j]指矩阵x中的第j列
- x[x,j]指矩阵x中第i行第j列的元素
- 示例:
a <- c("A1","A2")
b <- c("B1","B2","B3","B4")
x <- matrix(1:8,2,4,TRUE,list(a,b))
x
x[1,]
x[,2]
x[1,3]
x[1:2,c(1,3)]
x[1:2,1:2]
- 结果:
> x
B1 B2 B3 B4
A1 1 2 3 4
A2 5 6 7 8
> x[1,]
B1 B2 B3 B4
1 2 3 4
> x[,2]
A1 A2
2 6
> x[1,3]
[1] 3
> x[1:2,c(1,3)]
B1 B3
A1 1 3
A2 5 7
> x[1:2,1:2]
B1 B2
A1 1 2
A2 5 6
2.3、数组
- 数组:与矩阵类似,维度可以大于2,每个元素要求数据类型相同。
- 创建方法:
x <- array(vector,dimensions,dimnames)
# vector:数组中的数据,数据
# dimensions:数值型向量,给出各维度下标最大值,各维度的值
# dimnames:可选,各维度名称标签,各维度名称
- 示例:
a <- c("A1","A2")
b <- c("B1","B2","B3")
c <- c("C1","C2","C3","C4")
x <- array(1:24,c(2,3,4),list(a,b,c))
x
- 结果:
, , C1
B1 B2 B3
A1 1 3 5
A2 2 4 6
, , C2
B1 B2 B3
A1 7 9 11
A2 8 10 12
, , C3
B1 B2 B3
A1 13 15 17
A2 14 16 18
, , C4
B1 B2 B3
A1 19 21 23
A2 20 22 24
- 提取数据:与矩阵类似,使用x[a,b,c…]来提取数组x中的元素。
2.4、数据框
2.4.1、基础概念
- 数据框:与矩阵的区别在于每一列可以包含不同数据类型(任何类型),但是要求每一列的数据类型相同。
- 创建方法
x <- data.frame(col1,col2,col3,...)
- 示例
a <- c(1,2,3,4)
b <- c(1.1,2.2,1.1,4.4)
c <- c("C1","C1","C3","C4")
d <- c(TRUE,TRUE,TRUE,FALSE)
x <- data.frame(a,b,c,d)
x
- 结果:
> x
a b c d
1 1 1.1 C1 TRUE
2 2 2.2 C1 TRUE
3 3 1.1 C3 TRUE
4 4 4.4 C4 FALSE
2.4.2、数据的提取
- 可以使用类似矩阵的的下标法,也可以指定列名来调用
- 指定列名有两种方法
- x[c(“coln1”,“coln2”,…)]
- x$coln
- 可以利用table函数来进行列联表
- 示例:
x[2]
x[2:3]
x[c(2,4)]
x[c("a","c")]
x$c
table(x$d,x$b)
- 结果:
> x[2]
b
1 1.1
2 2.2
3 1.1
4 4.4
> x[2:3]
b c
1 1.1 C1
2 2.2 C1
3 1.1 C3
4 4.4 C4
> x[c(2,4)]
b d
1 1.1 TRUE
2 2.2 TRUE
3 1.1 TRUE
4 4.4 FALSE
> x[c("a","c")]
a c
1 1 C1
2 2 C1
3 3 C3
4 4 C4
> x$c
[1] "C1" "C1" "C3" "C4"
> table(x$d,x$b)
1.1 2.2 4.4
FALSE 0 0 1
TRUE 2 1 0
- 对行数据的提取:
数据框名[c("行名1","行名2"),]
# 区别就是后面加了个逗号
2.4.3、代码简化
每次调用数据框中的数据时都需要键入一次变量名,显得繁琐,可以通过联用attach( ),detach( )函数或者单独用with函数来简化代码
2.4.3.1、attach( ),detach( )
- attch( ):将数据框添加到R的搜索路径中
- detach( ):将数据框从搜索路径中移除
- 此函数对数据框无影响,可以省略
- 示例:
# 以上面数据框的示例为例
# mean是函数,用来求算术平均值
# x为数据框,a为x中的变量(就是列名)
mean(x$a)
#与下面的函数是等价的
attach(x)
mean(a)
detach(x)
2.4.3.2、with( )
- 使用方法:
with(数据框名,{操作空间})
- 示例
with(x,{mean(a)}) #与上面示例等价
# mean是函数,用来求算术平均值
# x为数据框,a为x中的变量(就是列名)
- with中定义的变量皆为局部变量,除非用<<-往上级写。
2.4.4、实例标识符
- 利用rowname选项来指定一列的数据作为行名
- 这一列数据不能有重复
- 示例:
x <- data.frame(a,b,c,d,row.names = a)
2.5、因子
- 变量分类:名义型,有序型,连续型
- 名义型:无顺序之分的变量,例如姓名排序
- 有序型:不涉及数量关系的一种顺序关系,例如健康状态,差,一般,好之间有顺序但不清楚之间具体相差多少
- 连续型:同时表示了数量和顺序,例如15岁比14岁大一岁
- 因子:名义型和有序型变量,其决定了数据的分析方式和如何数据可视化
- 函数:factor( x = character(), levels, labels = levels, ordered = TRUE/FALSE)
- 存储类别:整数向量
- 取值范围:[1-k] (k是名义型变量中唯一值的个数)
- 原始数据组成的内部向量会映射到这些整数上
- 参数
- x:导入的原始向量
- levels:默认的水平因子排序是按照字母顺序,可以用levels参数来覆盖默认排序
- labels:可以与levels函数联用来编码成因子,将数值型变量改为字符型变量。
- order:默认为FALSE,TRUE为有序型变量,FALSE为名义型变量
- 示例:
ID <- c(1,2,3,4)
Age <- c(22,29,40,55)
Type <- c("A","A","B","A")
Status <- c("Poor","Improved","Excellent","Poor")
Type <- factor(Type)
Status <- factor(Status,ordered = TRUE)
# 按照首字母的顺序来排也就是"Poor","Improved","Excellent"——3,2,1
Status <- factor(Status,ordered = TRUE,levels = c("Poor","Improved","Excellent"))
# 按照"Poor","Improved","Excellent"——1,2,3的顺序来排序
Data <- data.frame(ID,Age,Type,Status)
Data
str(Data)
summary(Data)
Data$Status <- c("1","2","3","1")
Data$Status <- factor(Status,ordered = TRUE,levels = c(1,2,3),labels = c("Poor","Improved","Excellent"))
# 将1,2,3替换为"Poor","Improved","Excellent",存在1,2,3以外的数字时将被设为缺失值。
- 结果:
- 函数str(object)可以提供R中某个对象的信息
- 结果中显示了Type是一个名义型因子,Status是一个有序型因子,以及如何编码的
- 函数summary显示了连续型变量age的最小值,最大值,均值和各四分位数,顺序显示了因子的频数
- 函数str(object)可以提供R中某个对象的信息
> Data
ID Age Type Status
1 1 22 A Poor
2 2 29 A Improved
3 3 40 B Excellent
4 4 55 A Poor
> str(Data)
'data.frame': 4 obs. of 4 variables:
$ ID : num 1 2 3 4
$ Age : num 22 29 40 55
$ Type : Factor w/ 2 levels "A","B": 1 1 2 1
$ Status: Ord.factor w/ 3 levels "Poor"<"Improved"<..: 1 2 3 1
> summary(Data)
ID Age Type Status
Min. :1.00 Min. :22.00 A:3 Poor :2
1st Qu.:1.75 1st Qu.:27.25 B:1 Improved :1
Median :2.50 Median :34.50 Excellent:1
Mean :2.50 Mean :36.50
3rd Qu.:3.25 3rd Qu.:43.75
Max. :4.00 Max. :55.00
2.6、列表
2.6.1、基础概念
- 列表:一些对象的有序合集,将若干对象整合到单个对象中。
- 创建方法:
x <- list(object1.object2,...)
- 示例:
a <- "My First List"
b <- c(1,2,3,4)
c <- matrix(1:8,nrow = 2,ncol = 4)
d <- c("A","B","C","D")
e <- data.frame(b,d)
f <- list(title=a,values=b,c,d,e)
f
- 结果:
$title
[1] "My First List"
$values
[1] 1 2 3 4
[[3]]
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
[[4]]
[1] "A" "B" "C" "D"
[[5]]
b d
1 1 A
2 2 B
3 3 C
4 4 D
2.6.2、数据的操作
2.6.2.1、提取
- 利用 [[ ]] 或者 $
- 示例:
f[[2]]
f[["values"]]
f$values
f[[3]]
- 结果:
> f[[2]]
[1] 1 2 3 4
> f[["values"]]
[1] 1 2 3 4
> f$values
[1] 1 2 3 4
> f[[3]]
[,1] [,2] [,3] [,4]
[1,] 1 3 5 7
[2,] 2 4 6 8
>
- 注:如果和上述对数据框等数据提取一样使用 [ ],提取出来的不是数值而是子列表,因为列表是双层的,外面一层list壳,里面包裹着变量的壳,变量里面才是数值,[ ] 类似于剥壳操作,列表需要剥两次才能取到值。
- 示例:
f[2]
class(f[2])
f[[2]]
class(f[[2]])
f[2][1]
f[[2]][1]
- 结果:
> f[2]
$values
[1] 1 2 3 4
> class(f[2])
[1] "list"
> f[[2]]
[1] 1 2 3 4
> class(f[[2]])
[1] "numeric"
> f[2][1]
$values
[1] 1 2 3 4
> f[[2]][1]
[1] 1
2.6.2.2、添加
- 将新的数据赋给当前维度+1的空间内
f[6] <- "添加"
2.6.2.3、删除
- 将NULL赋给需要删除的维度空间内
f[1] <- NULL
2.6.2.4、合并
- 将多个列表放在向量中赋给新的列表
list1 <- list("1","2","3")
list2 <- list("4","5","6")
new_list <- c(list1,list2)
2.6.2.5、拆分
- 使用unlist( ) 函数将列表转换为向量
list1 <- list(1,2,3)
list2 <- list(4,5,6)
v1 <- unlist(list1)
v2 <- unlist(list2)
#向量算法
v3 <- v1+v2 # 只有数值型可以进行向量之间的算法
> v3
[1] 5 7 9
补充——基础定义介绍
- 对象:可以赋值给变量的任何事物(常量,数据结构,函数,图形等)
- 对象的模式:描述对象如何存储的
- 对象的类:某类函数如何处理对象的
补充——注意事项
- 对象名称中的 “.” 没有特殊意义
- R不提供多行注释的功能
- 调试:可以将想让解释器忽视的代码放在if(FALSE){ }中,将FALSE改为TRUE就可以允许运行代码
- 将值赋给某个列表,矩阵,数组或列表中时如果超出容纳范围,R会自动扩充其范围
x <- c(1,2,3)
x[6] <- 6
> x
[1] 1 2 3 NA NA 6
x <- x[1:3]
> x
[1] 1 2 3
- R中没有标量,以单元素向量的形式出现
- R中的下标从x[1]开始而不是x[0]
- R中不能声明变量,只有在首次被赋值时生成
补充——查询,判断,修改数据类型
- 查询:class( ),mode( ), typeof( )
- 判断:is.arrary(/list/character …) 输出TRUE或FALSE
- 修改:as.arrary(/list/character …)
三、数据的输入
向R中导入数据的权威指南可以在这里下载
3.1 、使用键盘输入数据
适用于处理小数据集
3.1.1、R内置的文本编辑器
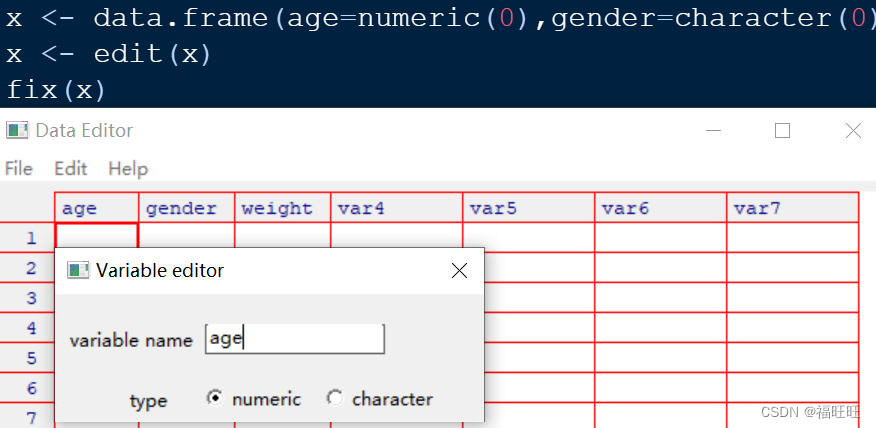
- 导入方法:函数edit( )/fix( )
- x <- edit(x) 等价于 fix(x)
- 示例:
x <- data.frame(age=numeric(0),gender=character(0),weight=numeric(0))
x <- edit(x)
fix(x)
# age=numeric(0)创建一个数值型数据模式(character为字符型),但是不包含数据的变量
# edit( )函数本身是在对象的一个副本上修改的,所以如果不将修改结果赋给一个目标,修改内容将丢失
# x <- edit(x)等价于fix(x)
# 当然你也可以什么都不创建,直接在数据框里添加
y <- data.frame()
y <- edit(y)
- 结果:
3.1.2、代码中嵌套数据
- 导入方法:函数read.table( )
- 示例:
x <- "
ID Age gender
1 11 male
2 22 female
3 33 female
4 44 male
"
y <- read.table(header=TRUE,text = x)
- 结果:
> y
ID Age gender
1 1 11 male
2 2 22 female
3 3 33 female
4 4 44 male
3.2、导入带分隔符的文本数据(.txt, .csv)
- 导入方法:函数read.table( )
- 此函数可以导入表格格式文件,并保存为数据框。
- 语法:
x <- read.table(file,options)
# file为带分隔符的ASCLL文本文件
# options为控制数据的选项
read.table(file, header = FALSE, sep = "", quote = "\"'",
dec = ".", numerals = c("allow.loss", "warn.loss", "no.loss"),
row.names, col.names, as.is = !stringsAsFactors,
na.strings = "NA", colClasses = NA, nrows = -1,
skip = 0, check.names = TRUE, fill = !blank.lines.skip,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#",
allowEscapes = FALSE, flush = FALSE,
stringsAsFactors = FALSE,
fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)
| 选项 | 功能 |
|---|---|
| header=TRUE/FALSE | TURE:文件第一行包含了变量名 |
| sep | 按什么分隔符来读取数据,默认为sep=” “表示一个(或多个)空格、制表符、换行或回车。sep=",“表示逗号sep=”\t"表示制表符 |
| row.name | 指定一列(或多列)数据,作为行名,可选参数 |
| col.name | header=FALSE时,指定一个包含变量名的字符向量,作为列名 |
| na.strings | 表示缺失值的可选字符向量,如na.strings=c(“-9”),就会将-9读为NA |
| colClasses | 可选的分配到每一列的类向量。如colClasses=c(“numeric”,“character”,“NULL”),会将第一列设为数值型,第二列为字符型,跳过第三列,当数据不止3列,会循环利用colClasses的值。处理大文本数据时,十分有效 |
| quote | 用于对有特殊字符的字符串划定界限的自负床,默认为双引号(” “)或单引号(’ ') |
| skip | 读取数据前跳过的行数(用来跳注释) |
| stringsAsFactors=TRUE/FALSE | 标记字符向量是否需要转化为因子,默认值为TRUE,将该选项设置为FALSE会大幅提升处理速度 |
| text | 代码中嵌套数据,不能与file同时存在 |
- 注:当导入的数据中存在空白数据时,使用NA填充,同时在函数 read.table( ) 中写入参数选项,fill=TRUE
3.3、导入Excel数据
- 最方便的方法就是将Excel中的数据导出为(.csv)文件,然后用前面的方法导入。
- 此外亦可以用xlsx包直接导入Excel文件,另外还需要xlxjars和rJava包,以及一个可以正常运行的Java。
- 导入方法:
install.packages("xlsx")
library(xlsx)
x <- read.xlsx(file,n)
#file是Excel的绝对路径,n表示要导入的工作表序号
- 替代的包包含有XLConnect和openxlsx包,前者依赖于Java,后者不是。
- 所有的包都可以创建和操作Excel文件。
3.4、导入XML数据
- XML包允许你读取,写入和操作XML文件
3.5、从网页抓取数据
- 通过Web数据抓取或者应用程序接口(application programming interface,API)实现
3.6、导入SPSS数据
- 可以通过foreign包中的read.spss( )函数导入R中,或Hmisc包中的spss.get( )函数。spss.get( )函数是对read.spss( )函数的封装,更加的快捷方便。
- 导入方法
install.packages("Hmisc")
library(Hmisc)
x <- spss.get("filename.sav",use.value.labels=TRUE)
# use.value.labels=TRUE表示让函数将带有标签的变量导入R中水平对应的相同因子
3.7、导入SAS数据
- foreign包中的read.ssd( ) 函数,Hmisc包中的sas.get( ),以及sas7bdat包中的read.sas7dbat( ),前面两种方法需要安装SAS软件。
- 导入数据
install.packages("Hmisc")
library(Hmisc)
datadir <- "data的绝对路径"
sasexw <- "sas.exe的绝对路径"
mydata <- sas.get(libraryName = datadir,member = "clients",sasprog = sasexe)
# libraryName是包含SAS数据集的文件夹,membership数据集的名字(去掉后缀sas7dbat),sasprog是sas。exe的绝对路径
也可以在SAS中导出为csv文件
sas程序
liobname datadir "data的绝对路径"
proc export data=datadir.clients
outfile="clients.csv"
dbms=csv;
run;
R程序
mydata <- read.table("client.csv",header=TRUE.sep=",")
sas7dbat函数
install.packages("sas7dbat")
library(sas7dbat)
mydata <- read.sas7dbat(sas7dbat文件的绝对路径)
3.8、导入Stata数据
- 导入方法
library(foreign)
x <- read.dta("mydata.dta")
3.9、导入NetCDF数据
- 开源软件库NetCDF(网络通用数据格式),定义了一种机器无关的数据格式,可用于创建和分发面向数组的科学依据。
- 其通常用来存储地球物理数据。
- ncdf包与ncdf4包为NetCDF提供了R接口
- 导入方法
install.packages("ncdf")
library(ncdf)
nc <- nc_open("mynetCDFfile")
myarray <- get.var.ncdf(nc,myvar)
# myvar为mynetCDFfile中的变量
3.10、导入HDF5数据
- HDF5(分层数据格式)是一套用于管理超大型和结构极端负载的数据集的软件技术方案。
- rhdf5包为R提供了一个HDF5接口,用以下代码安装,此包在Bioconductor网站上面。
source(”http://bioconductor.org/bioLite.R“)
bioLite(”rhdf5“)
3.11、访问数据库管理系统
R有许多面向关系型数据库管理系统的(DBMS)的接口。
3.11.1、ODBC接口
- 通过RODBC包来访问数据库
- 第一步需要针对系统和数据库类型安装并配置合适的ODBC驱动
- 第二步安装RODBC包
- RODBC包允许R与数据库双向通信,意味着可以对数据库内容进行读写。
- 导入数据
install.packages("ODBC")
library(ODBC)
myconn <- odbcConnect("mydsn",uid="name",pwd="password")
数据框1 <- sqlFetch(myconn,sql表1)
数据框2 <- sqlQuery(myconn,"select * from Punishment")
close(mycoon)
# 首先载入RODBC包,通过一个已经注册的数据源(mycoon)和用户名name密码password打开数据库连接
# 连接字符串被传递给sqlFetch,其将sql表1复制到数据框1
# 函数sqlQuery()中可以插入任意的sql语句,这里全选了sql表2的数据赋给了数据框2
3.11.2、DBI相关包
DBI包为访问数据库提供了一个通用且一致的客户端接口
3.12、通过Stat/Transfer导入数据
Stat/Transfer是一款可以在32款数据格式之间转换的应用程序,包括R
补充——用连接来导入数据
- 函数file( ) 允许访问文件,剪切板和C级别的标准输入
- 函数gzfile( ), bzfie(), xzfile( ), unz( ) 允许读取要锁文件
- 函数url( ) 可以访问网上文件
四、数据集的标注
其实就是对数据集的变量名和值进行重命名(修改)
4.1、变量标签
- 方法:
names(变量)[第几列数据] <- "修改后的名称"
- 示例:
a <- c(1,2,3,4)
b <- c(1.1,2.2,1.1,4.4)
c <- c("C1","C1","C3","C4")
d <- c(TRUE,TRUE,TRUE,FALSE)
x <- data.frame(a,b,c,d)
names(x)[2] <- "age"
> x
a age c d
1 1 1.1 C1 TRUE
2 2 2.2 C1 TRUE
3 3 1.1 C3 TRUE
4 4 4.4 C4 FALSE
4.2、值标签
- 方法:利用因子中的levels和labels
- 示例:
ID <- c(1,2,3,4)
Age <- c(22,29,40,55)
Type <- c("A","A","B","A")
Status <- c("1","2","3","1")
Type <- factor(Type)
Status <- factor(Status,ordered = TRUE,levels = c(1,2,3),labels = c("Poor","Improved","Excellent"))
# 将1,2,3替换为"Poor","Improved","Excellent",存在1,2,3以外的数字时将被设为缺失值。
Data <- data.frame(ID,Age,Type,Status)
五、函数总结
5.1、RODBC中的函数
| 函数 | 功能 |
|---|---|
| odbcConnect(dsn,uid" “,pwd=” ") | 建立一个到ODBC数据库的连接 |
| sqlFetch(channel,sqltable) | 读取ODBC数据库中某个表到一个数据框中 |
| sqlQuery(channel,query) | 向ODBC数据框提交一个查询并返回结果 |
| sqlSave(channel,mydf,tablename=sqtable,append=FALSE) | 将数据框写入或更新(append=TRUE)到ODBC数据库中的某个表 |
| sqlDrop(channel,sqtable) | 删除ODBC数据库中的某个表 |
| close(channel) | 关闭连接 |
5.2、处理数据对象的实用函数
| 函数 | 功能 |
|---|---|
| length(object) | 显示对象中元素的数量 |
| dim(object) | 显示某个对象的维度 |
| str(object) | 显示某个对象的结构 |
| class(object) | 显示某个对象的类或类型 |
| mode(object) | 显示某个对象的模式 |
| names(object) | 显示某个对象中各成分的名称 |
| c(object1,object2,…) | 将对象合并入一个向量 |
| cbind(object1,object2,…) | 按列合并对象 |
| rbind(object1,object2,…) | 按行合并对象 |
| object | 输出某个对象 |
| head(object) | 列出某个对象的开始部分 |
| tail(object) | 列出某个对象的结束部分 |
| ls() | 显示当前的对象列表 |
| rm(object1,object2,…) | 删除一个/多个对象 |
| rm(list=ls()) | 删除环境中几乎所有对象 |
| newobject <- edit(object1,object2,…) | 编辑对象并将其保存到newobject |
| fix(object) | 直接编译对象 |

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









