






这里写目录标题
摘要
在梯度下降过程中,当梯度为0时,模型参数无法继续更新,这是由于此时梯度为0的点为局部最小点或鞍点,为了提高梯度下降计算效率,在进行梯度下降过程中,学习率是一个重要的参数,学习率的大小决定着模型训练的平滑程度和稳定性。本文也介绍了如何自动调整学习率,学习率会随着梯度的改变而改变。从而在各个情况下采用合适的学习率。同时也介绍了 Adagrad算法和RMSProp算法,Learning Rate Decay和Warm up是机器学习中的优化技术,这两种方式可以改变学习率中的η,将η随着时间的改变而改变,从而可以避免 “梯度爆炸” 等现象,
Abstract
In the process of gradient descent, when the gradient is 0, the model parameters cannot be updated, which is because the point with gradient 0 at this time is the local minimum point or the saddle point. This paper makes a detailed comparative analysis of the local minimum point and the saddle point, and deduces and verifies the method of judging the local minimum point and the saddle point. Multivariate Taylor’s formula, Hassian matrices, igenvalues, and positive definite matrices are used. In order to improve the computational efficiency of gradient descent, the learning rate is an important parameter in the process of gradient descent, and the learning rate determines the smoothness and stability of the model training. This article also describes how to automatically adjust the learning rate, which will change as the gradient changes. Thus, the appropriate learning rate is adopted in each case. At the same time, Adagrad algorithm and RMSProp algorithm are also introduced. Learning Rate Decay and Warm up are optimization techniques in machine learning. These two methods can change η in the learning rate and change η with the change of time, so as to avoid “gradient explosion” and other phenomena.
1、批次(batch)
1.1 、Review: Optimization with Batch
在计算微分的时候,并不是把所有的data对计算出来的L做微分,而是把data分成一个一个的Batch。如下图所示,每一个Batch的大小是B笔资料,每次在更新资料时,用B笔资料计算Loss,计算gradient;再用另外B笔资料计算Loss,计算gradient;以此类推。因此,我们不会把所有的资料全部去计算Loss,而是用一个Batch的资料去计算Loss。
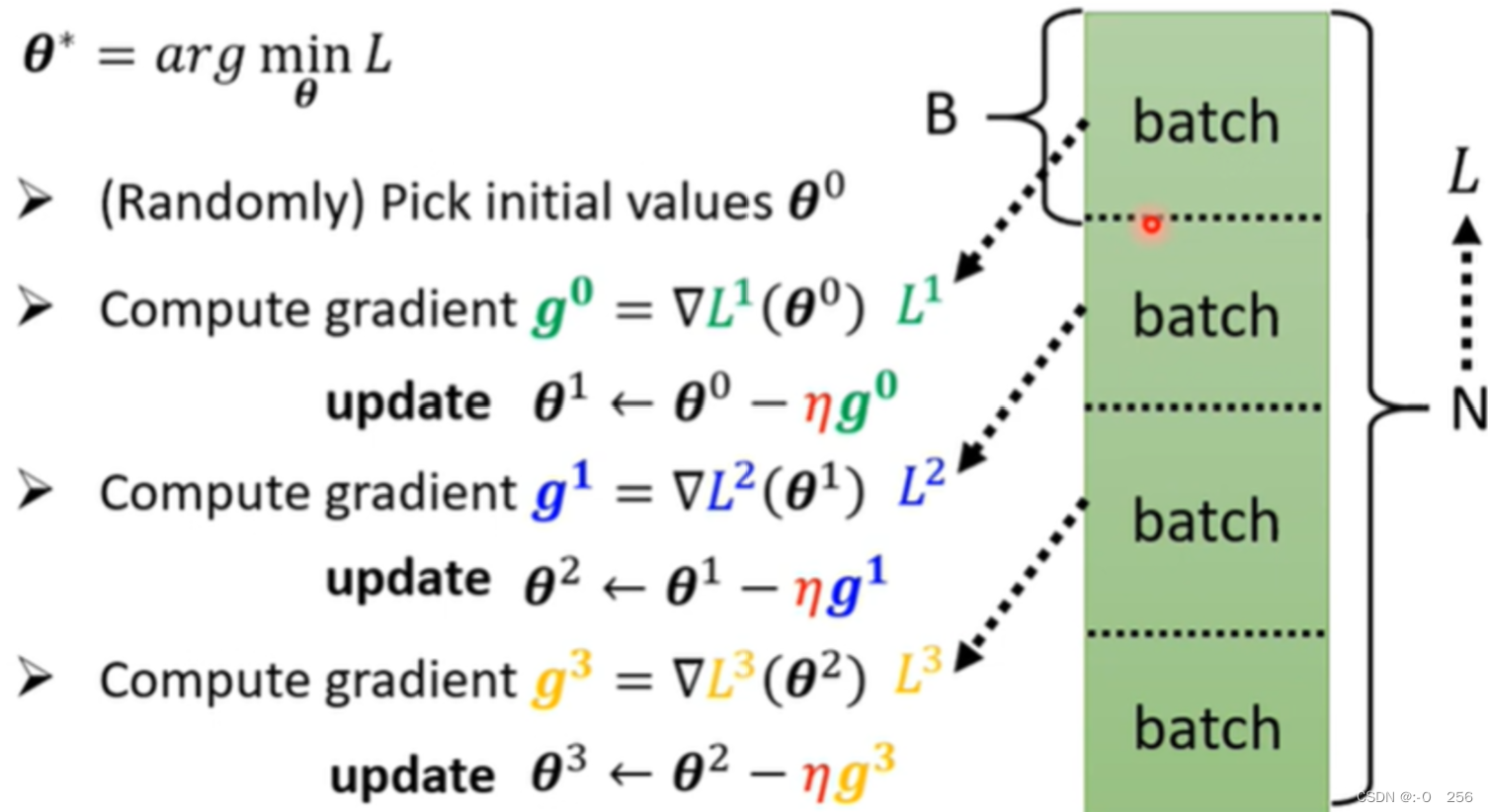
将所有的batch都用过一遍就叫做 1 epoch。在进行training的时候会有多次epoch,在每次epoch之前会重新再分一次batch,并且每一个epoch分的batch都不一样,这件事情就叫做 Shuffle 。Shuffle是一种用于随机打乱训练数据顺序的方法。它的作用是为了减少训练数据之间的相关性,避免模型过度依赖某一些固定的数据并降低模型的泛化能力。在机器学习中对数据进行shuffle通常是在每个epoch结束时进行的,即在模型对整个训练集完成一次完整的学习后,重新打乱数据顺序并重新开始下一轮训练。这样做可以让模型更好地学习数据之间的关系,提高模型的可靠性。需要注意的是,在使用Shuffle时要注意保证数据之间的关联性并不受到影响,否则可能会导致模型性能下降。例如地图上的行政区划,彼此间存在清晰的层级关系,如果在shuffle过程中不注意保持这种关联性,就可能导致模型的训练失真,因为其与真实数据之间的匹配程度降低,得到的结果也可能会出现偏差或错误。
1.2、Small Batch v.s. Large Batch
1、如下图所示,假设有20个训练资料,看这两个Case最极端的情况。
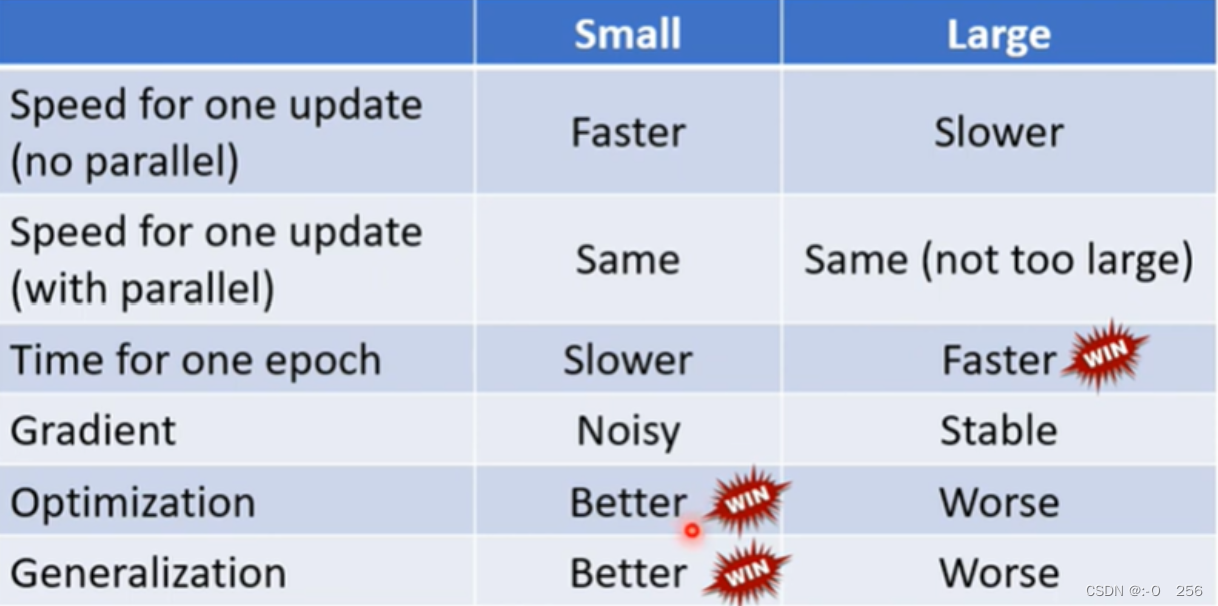
当 Batch Size = 20 时, 此时 Batch Size 最大,可以利用并行计算的优势,提高训练过程的效率,但是需要消耗更多的内存和计算资源,Batch Size过大时,参数更新频率较低,模型的训练过程更加稳定。
当 Batch Size = 1 时,此时 Batch Size 最小,此时参数更新频率较高,模型的训练过程不稳定,同时在进行梯度估计时,会引入更多的噪声,导致梯度估计的不准确性增加。

2、现在比较左边和右边哪个更好?
1)左边的蓄力时间比较长,需要把所有的资料全部看过一遍,才会更新一次参数,所以它是稳定的。
2)右边的Batch Size = 1,蓄力时间比较短,每看到一笔资料,就会更新一次参数,所以它是不稳定的。
3)总的来说,左边和右边都各有所长、各有所短。但是如果考虑并行运算的话,左边的运行时间就并不一定比右边长。
3、通过实验结果表明,比较大的Batch Size所花的时间并不一定比比较小的Batch Size所花的时间多。
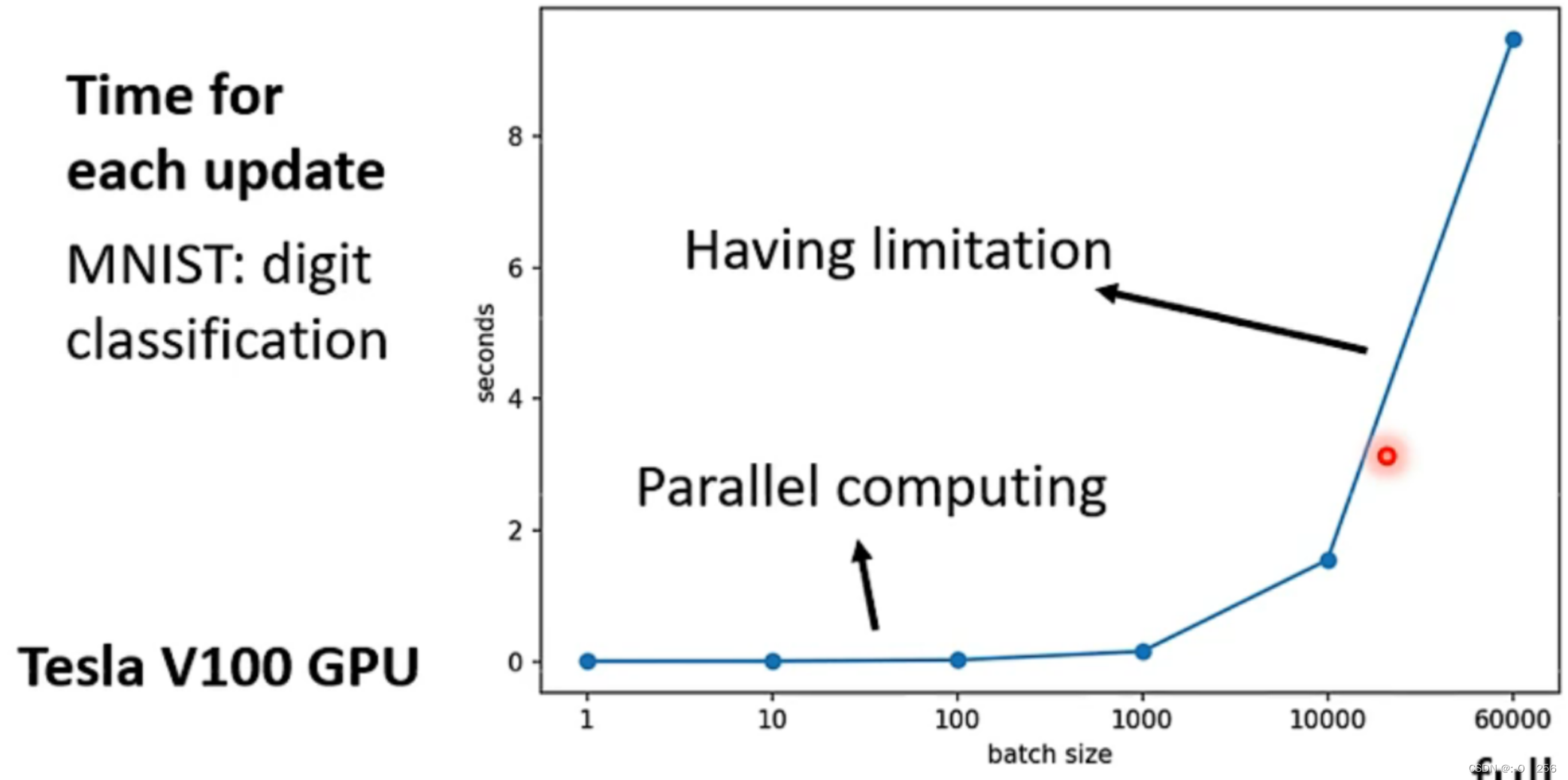
当 Batch Size 比较大时,训练过程所花费的时间不一定比 Batch Size 比较小的时候所花费的时间长。如下图所示,这是一个手写数字辨识案例,在该案例中,Batch Size为1时所花费的时间与 Batch Size为1000时所花费的时间几乎相等。这是因为我们有GPU做平行运算,但是GPU做平行运算是有极限的,一旦超过这个极限,所花费时间还是会随Batch Size的增长而增加。
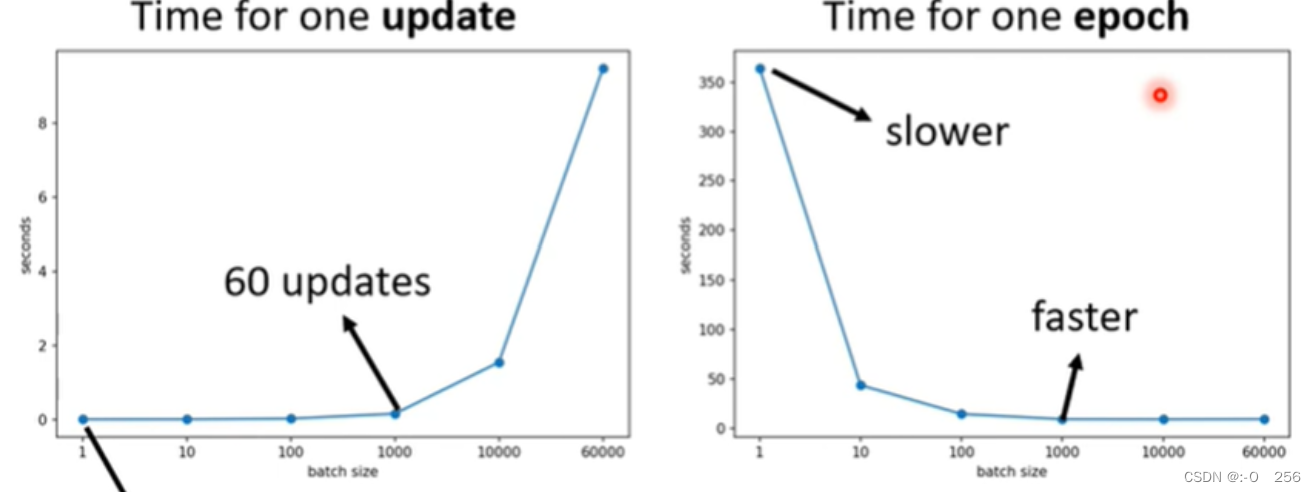
4、当Batch Size比较小时,因为GPU的平行运算,跑完一个epoch所花的时间比Batch Size比较大的所花的时间更长。
1)如下图所示,假设训练资料只有60000笔,当Batch Size = 1时,需要60000个update才能跑完一个epoch;当Batch Size = 1000时,需要60个update才能跑完一个epoch;因此通过左右两边的图告诉我们一个Batch Size大的跑完一个epoch所花的时间反而更短,也更有效率。
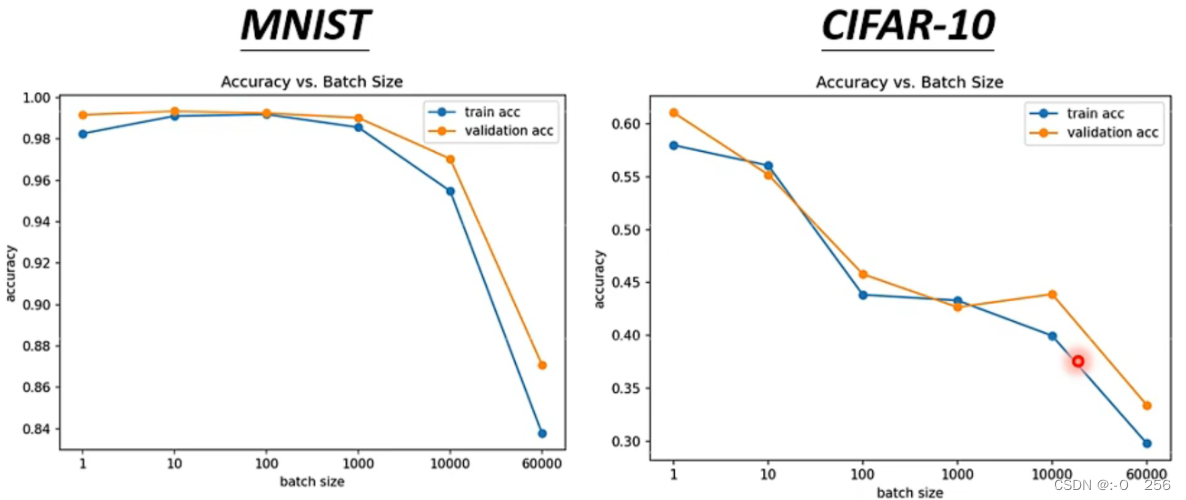
2)比较大Batch的Update比较稳定,比较小的Batch的gradient的方向比较Noisy,但是Noisy的gradient更有利于Training。

3)尽管 Batch Size 比较小时会引入更多的噪声,但是有时候 Small Batch 产生的noisy的gradient可以帮助training,拿不同的batch来训练同一个模型,会得到如下的结果。
为什么 Batch Size 较小时引入更多噪声,但却能使得我们的训练结果更好呢?
假设我们此时选择的是 Full Batch,那我们在更新参数时,则是沿着一个 Loss function来更新,当参数更新到局部最小点或者鞍点时,梯度下降也就随之停止。如果此时我们选择的是 Small Batch,我们在更新参数时,选择第一个 Batch 时,是用L1 这个function来更新,选择第二个 Batch 时,我们是用 L2来更新,如果我们用L1计算梯度时,更新到梯度为0的点停止了,由于 L2的funciton与 L 1 不同,因此在L1 更新至梯度为0的点,此点在L2不一定梯度为0,因此即便在 L 1处无法更新参数了,但是在 L2 处仍然可以更新参数。
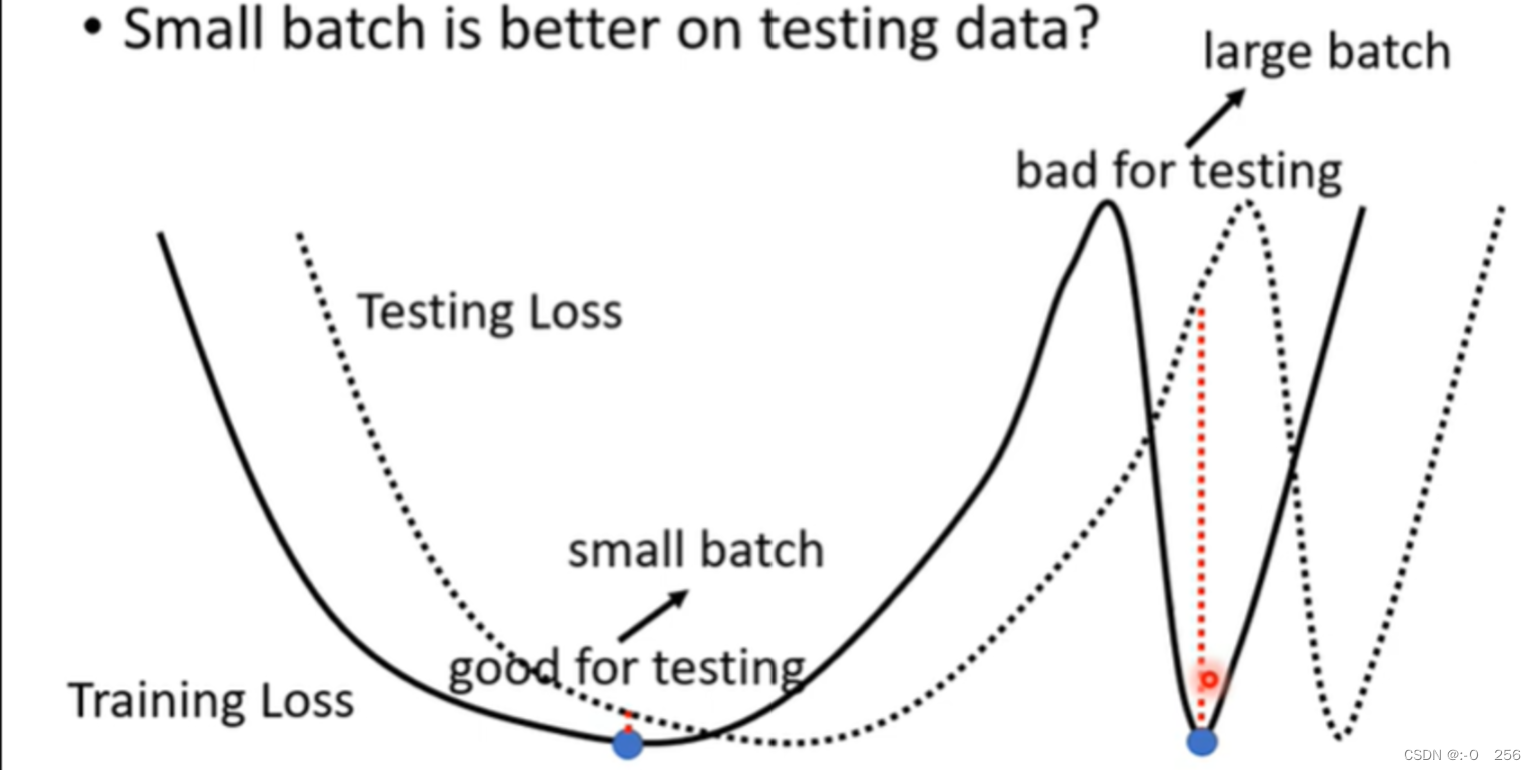
比较小的Batch对Testing有帮助。因为假设我们把大的Batch和小的Batch都Training到一样好,结果是小的Batch在Testing上结果更好。大的Batch和小的Batch都Training到差不多的Training Accuracy,但是Testing时小的Batch比大的Batch的结果好,大的Batch就是Overfitting。

5、如下图所示,对于左边的Minima来说,它的Training和Testing上面的结果差不多,但是对于右边的Minima来说,它的Training和Testing上面的结果差距特别大。比较小的Batch有很多Loss,它每次update的方向不一样,因此小的峡谷困不住它。但是比较大的Batch,他会顺着update的方向,因此它就很容易走进小的峡谷。
6、比较大的Batch Size和比较小的Batch Size
2、动量(momentum)
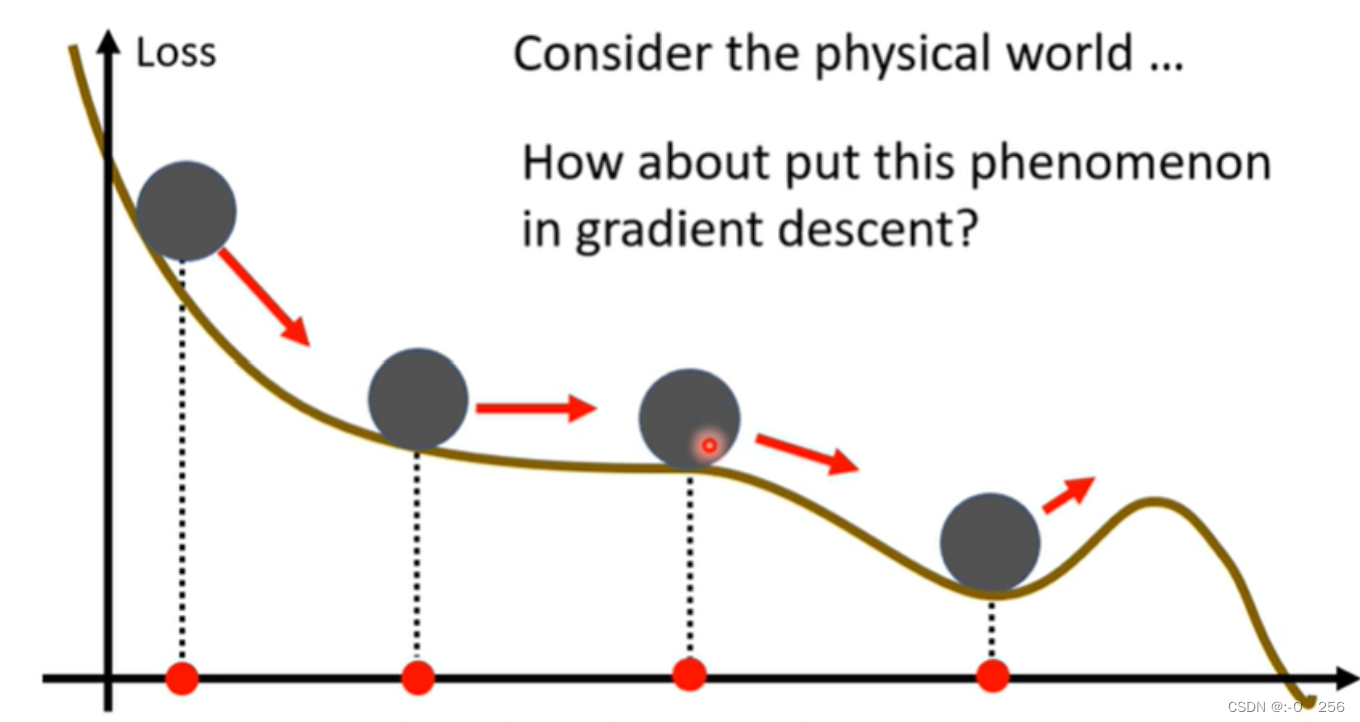
Momentum(动量)是机器学习中一种常用的优化算法,用于加快模型收敛速度并减少震荡。它通过累积梯度更新的动量来控制梯度下降的方向和速度,可以有效地避免陷入局部最优解并加速模型训练。从物理的角度来解释,假如一个小球从山坡上滚落,即便小球滚落到局部最小值的点,可能会借助惯性和动量继续滚落,从而滚出局部最小值点。我们可以将这种规律运用到机器学习中的梯度下降中去。Momentum算法在计算每个梯度的时候会考虑这个梯度在先前更新中的权重,将当前梯度与先前权重的指数加权和相加,然后再通过这个更新结果来更新权重值。
2.1、momentum实现
对一般的Gradient Descent来说,有一个初始参数θ^0,然后计算出gradient,再往gradient的反方向去更新参数,以此类推。现在要考虑到Momentum,我们是按照gradient的反方向加上前一步移动的方向的结果,去调整参数。
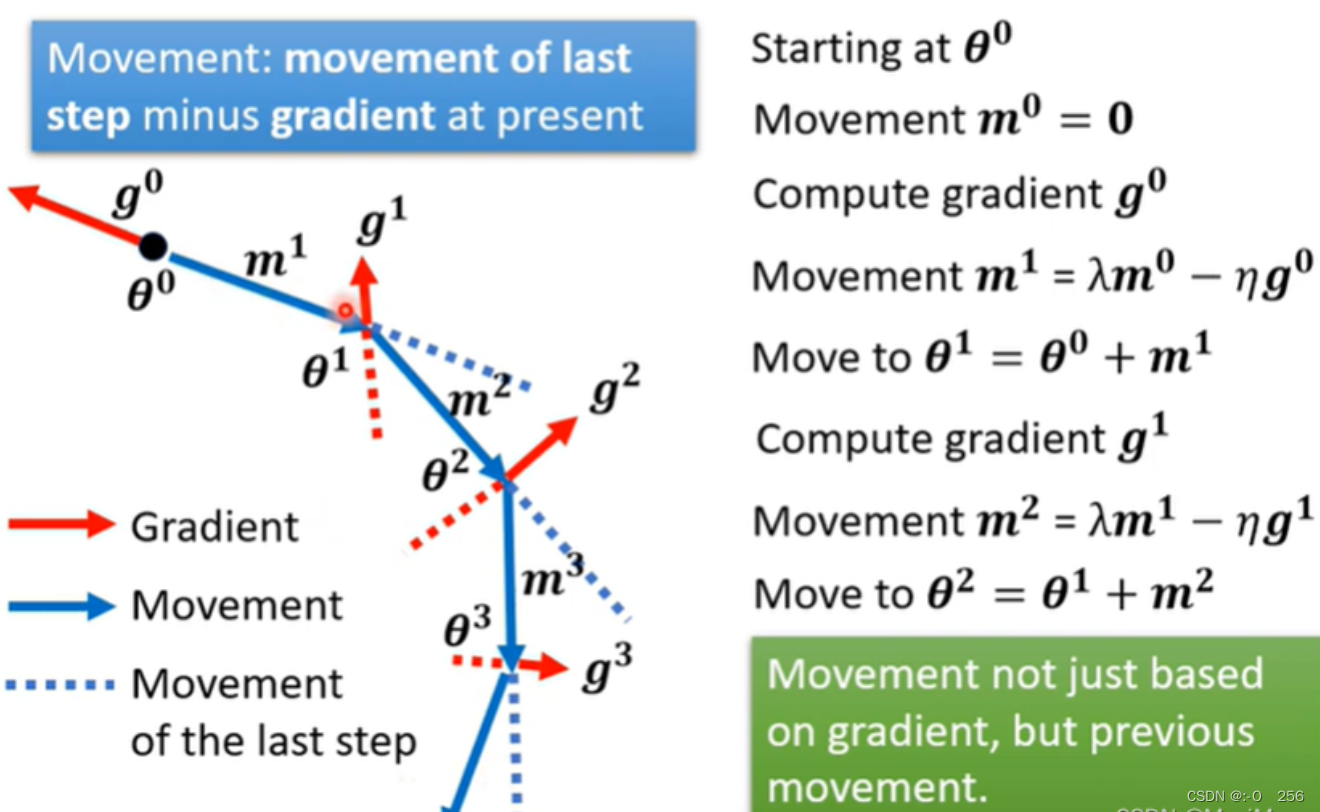
我们用m来表示每一步的移动,也就是之前所有算出来的gradient的Weighted Sum,而这里的λ和η是需要自己调整的。
这里有两种解读,第一种是Momentum是gradient的负反方向加上前一次移动的方向,第二种是加上Momentum时,Update的方向不只考虑现在的gradient,而是考虑过去所有的gradient 的总和。
3、自动调整学习速率 (Learning Rate)
大多数人认为训练受阻是因为参数到达了critical point附近,但是critical point不一定是我们训练过程中最大的障碍。
如下图所示,在训练一个network时,我们会把loss记录下来,随着更新参数,这个loss会逐渐下降,一直到loss不在下降为止。当走到critical point时,gradient是非常小的,但是当loss不在下降时,gradient并没有变得很小。如下第二张图所示,随着参数地不断更新,虽然loss不再变小了,但是gradient并没有变得很小,反而有时会有增长的趋势。
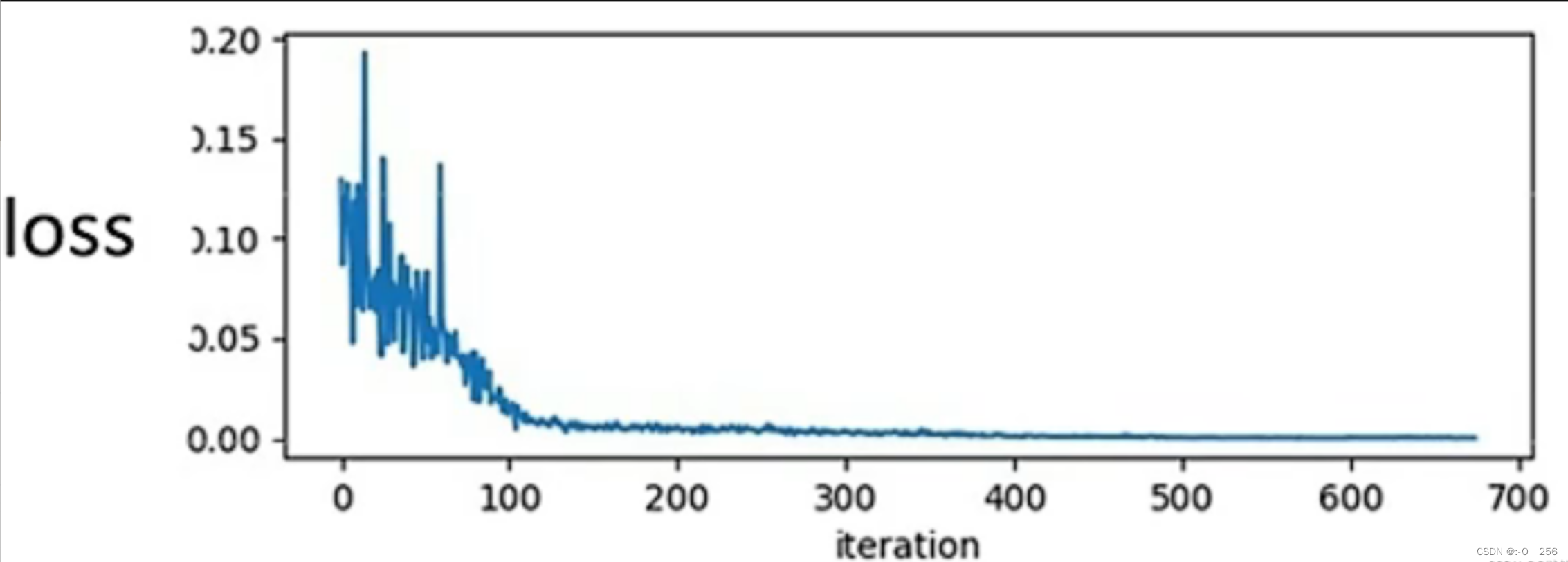
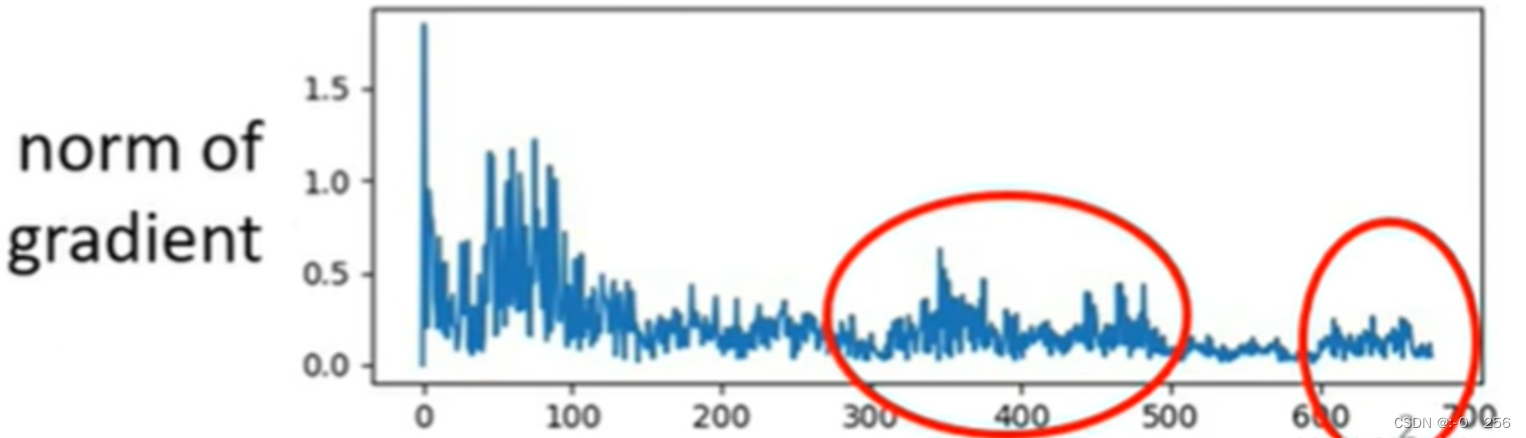
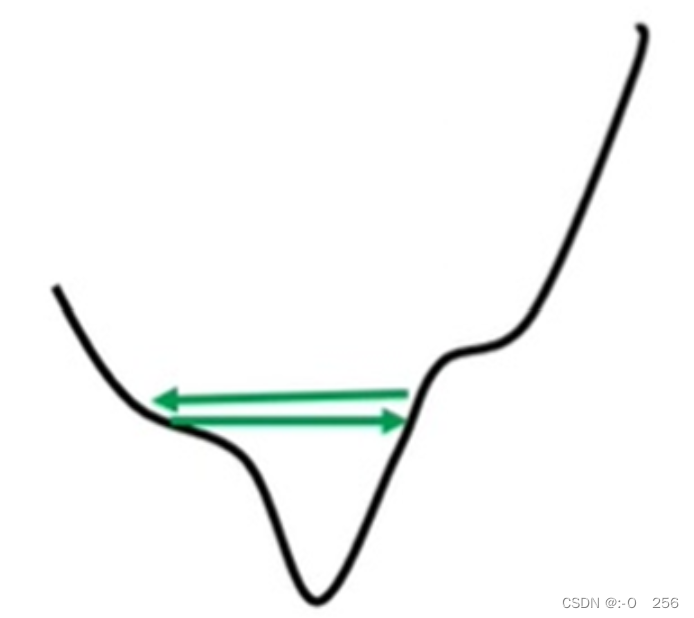
如下图所示,这里是error surface,现在gradient在error surface的山谷间不断来回的振荡,这个时候loss不会再下降了。因此,在训练一个network时,发现loss不会再下降了,它可能不是local minima和saddle point,它只是loss没有办法再下降了。
事实上走到critical point其实是一件困难的事情,因为大多数training还没有到critical point就已经停止了。因此,目前用gradient descend来做optimization时,我们要怪罪的对象不是critical point,而是其他的原因。
1、即使没到critical point,训练也会很困难
1、如下图所示,当参数w和b不一样时,loss的值就不一样,这样就画出了error surface。这个error surface是convex形状,它的最低点在黄色叉的地方,它的等高线是椭圆形的。它在横轴的地方,gradient变化很小,坡度变化很小,比较平滑,在纵轴的地方,gradient变化很大,坡度变化很大,比较陡峭。
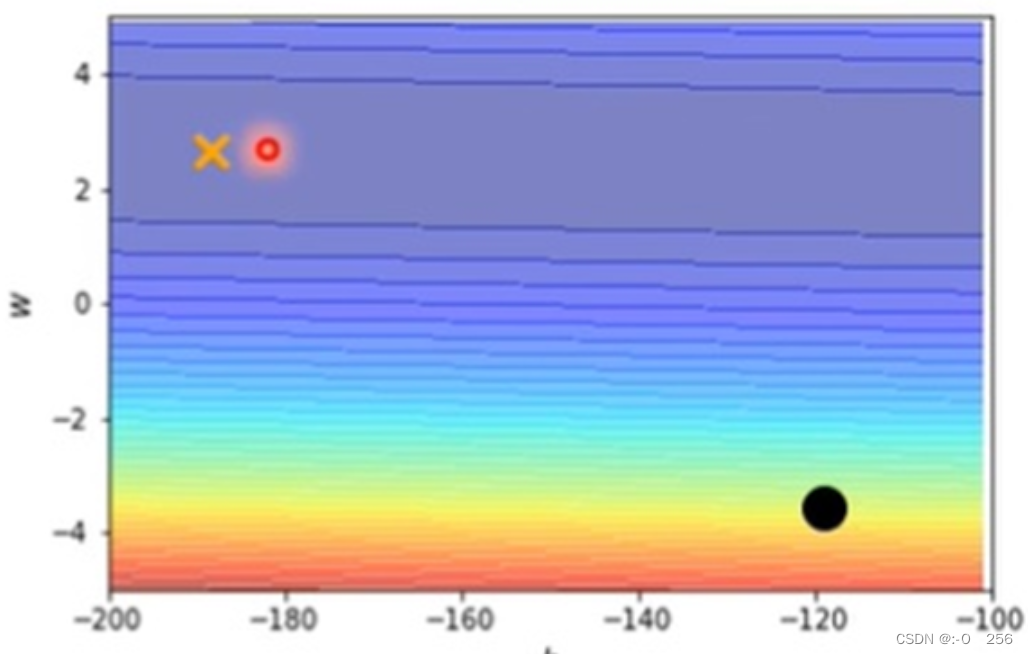
现在从黑色的点开始做gradient descend。
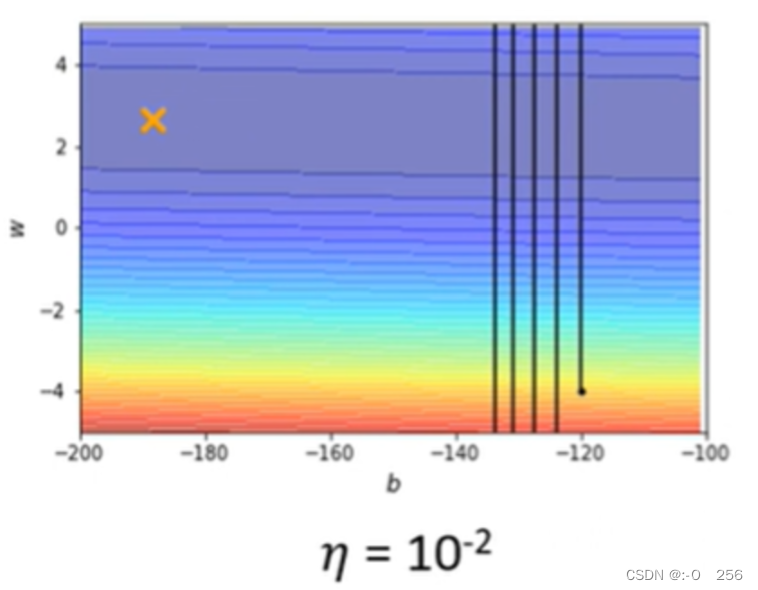
1)上图的learning rate = 10^(-2),参数在山谷间来回振荡,loss不会下降,但gradient依然很大,这是因为learning rate太大了,它决定了更新参数时步伐的大小。
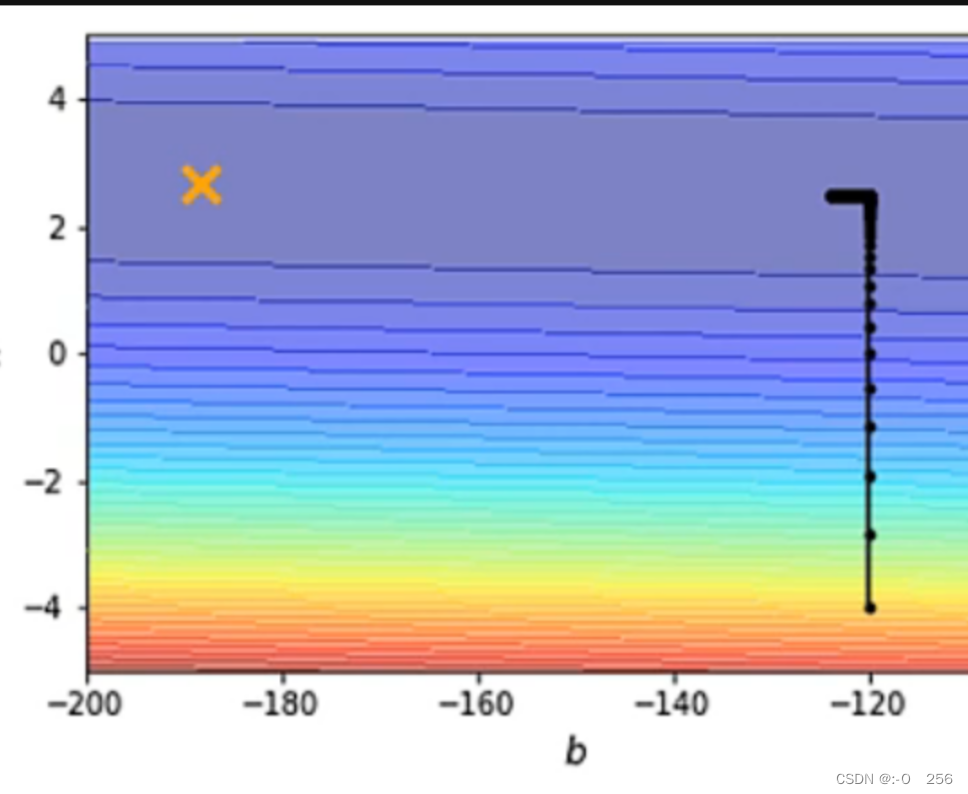
2)上图的learning rate = 10^(-7),参数不再振荡,但是这个训练到不了终点,这是因为learning rate太小了,不能让我们的训练前进。
3)这个convex的optimization问题其实是有解的,我们需要更好的gradient descend版本,learning rate要为每一个参数定制化。
2、 设置学习率
那么我们应该如何合理的设置学习率呢?
我们往常都是采用所有参数都采用同一个学习率,这样显然不可行,不同的参数应该设置不同的学习率。如果在某个方向上梯度值很小,那我们会增加学习率,如果在某个方向上梯度值很大,那我们会相应的降低学习率。

3、RMSProp 算法
RMSProp 是一种优化算法,用于在机器学习中自适应地调整学习率。它是Adagrad算法的改进版本,用于解决Adagrad算法可能出现的学习率过于下降的问题。与Adagrad算法不同,RMSProp算法引入了一个衰减系数α ,用来控制梯度平方累加项的贡献程度。具体而言,给定一个优化目标和一组参数。
1、Root mean square
1. 如下图所示,这是一个计算gradient的Root Mean Square。
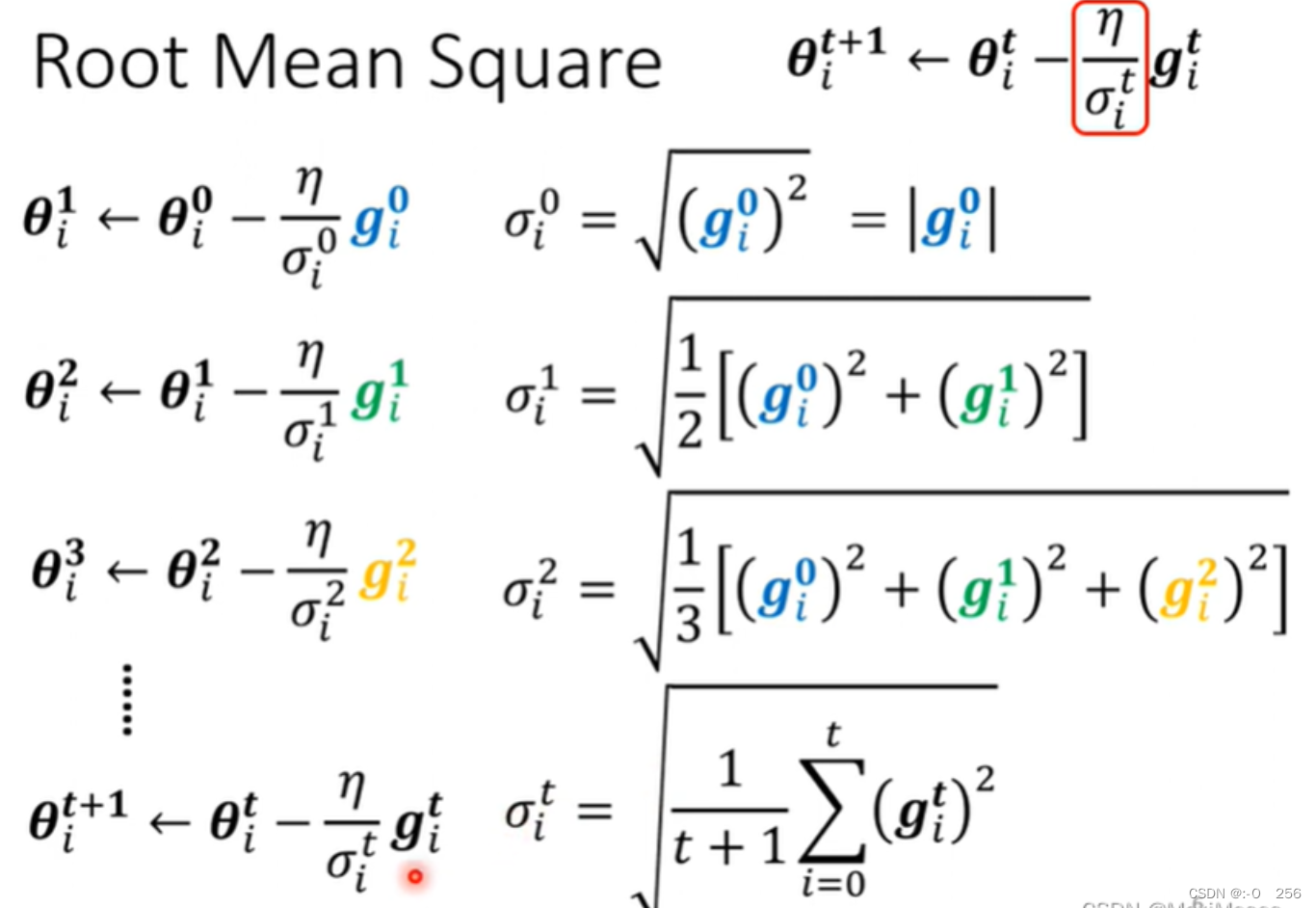
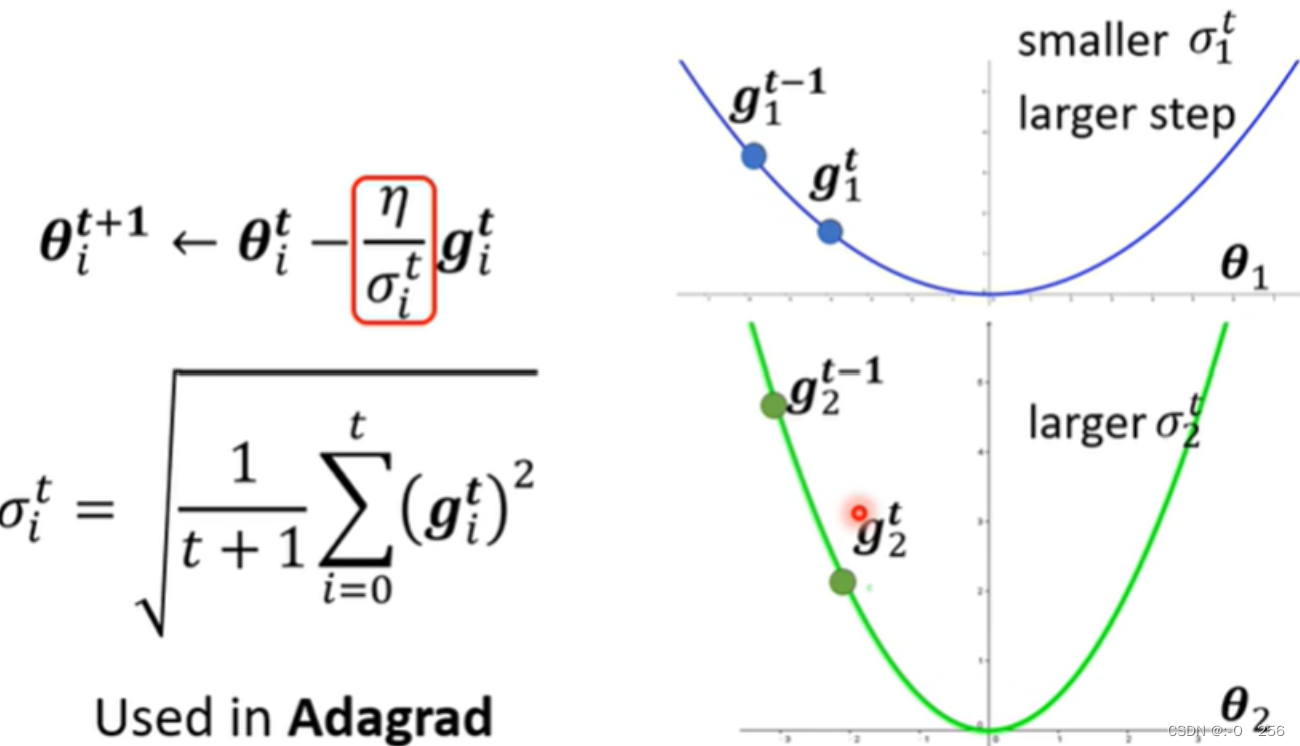
2、 如下图所示,这里是用在Adagrad的方法里面。当坡度比较大时,gradient就比较大,σ就比较大,所以learning rate就比较小。当坡度比较小时,gradient就比较小,σ就比较小,所以learning rate就比较大。因此,有了σ后,我们就可以随着参数的不同,自动地调整learning rate的大小。
2、RMSProp
RMSProp算法引入了一个衰减系数α ,用来控制梯度平方累加项的贡献程度。具体而言,给定一个优化目标和一组参数。如下图所示,RMSProp第一步和Root Mean Square是一样的,在下面的步骤中不一样的是在计算Root Mean Square时,每一个gradient都有同等的重要性,在RMSProp中,你可以调整它的重要性。
1. 如下图所示,RMSProp第一步和Root Mean Square是一样的,在下面的步骤中不一样的是在计算Root Mean Square时,每一个gradient都有同等的重要性,在RMSProp中,你可以调整它的重要性。α如果设很小趋近于0时,就对与我们计算出来的gradient重要;α如果设很大趋近于1时,就对与我们计算出来的gradient不重要。

4、怎么避免“梯度爆炸”
如下图中黑点表示更新的参数,我们不自动调整学习率时,参数更新到梯度为0时(局部最小点或鞍点),就不再更新。但是距离橙色的目标点还仍有距离
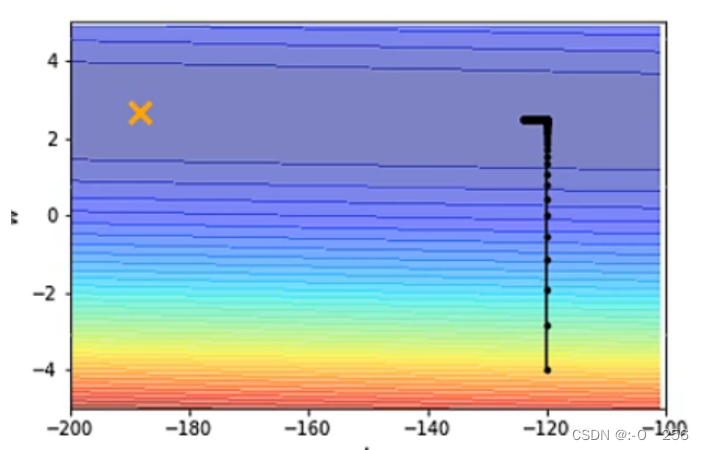
我们运用传统的 Adagrad 算法进行梯度下降,参数可以更新到橙色目标点处,我们在计算σt 时是将过去梯度之和,然后取平均值开根号,因为在纵轴的方向,刚开始梯度比较大学习率比较小,因此在纵轴方向积累了很多很小的σt 累计到一定量之后,梯度就会变很大,这时就会走到梯度比较大的地方,累计的σt。又会慢慢变大,学习率降低,参数更新的步伐又会变小,慢慢的又回到横轴位置。如下图
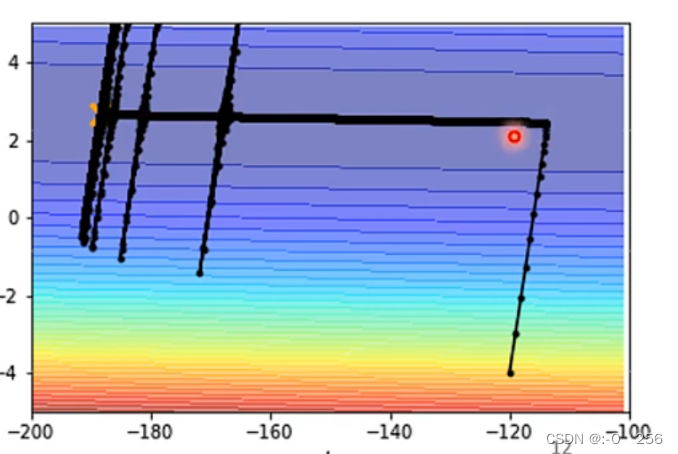
我们可以使用 Learning Rate Scheduling,Learning Rate Scheduling(学习率调度)是机器学习中的一种优化技术,用于在训练过程中动态地调整学习率的数值。
怎么避免这种“梯度爆炸”的出现呢?
我们可以使用 Learning Rate Scheduling,Learning Rate Scheduling(学习率调度)是机器学习中的一种优化技术,用于在训练过程中动态地调整学习率的数值。 如下图所示,之前的η一直是固定值,但应该把它跟时间联系在一起。这里要用到最常用的策略是Learning Rate Decay,这样我们就可以很平稳地走到终点。当越靠近终点时,η就会越小,当它想乱喷的时候,乘上一个很小的η,就可以平稳到达终点。
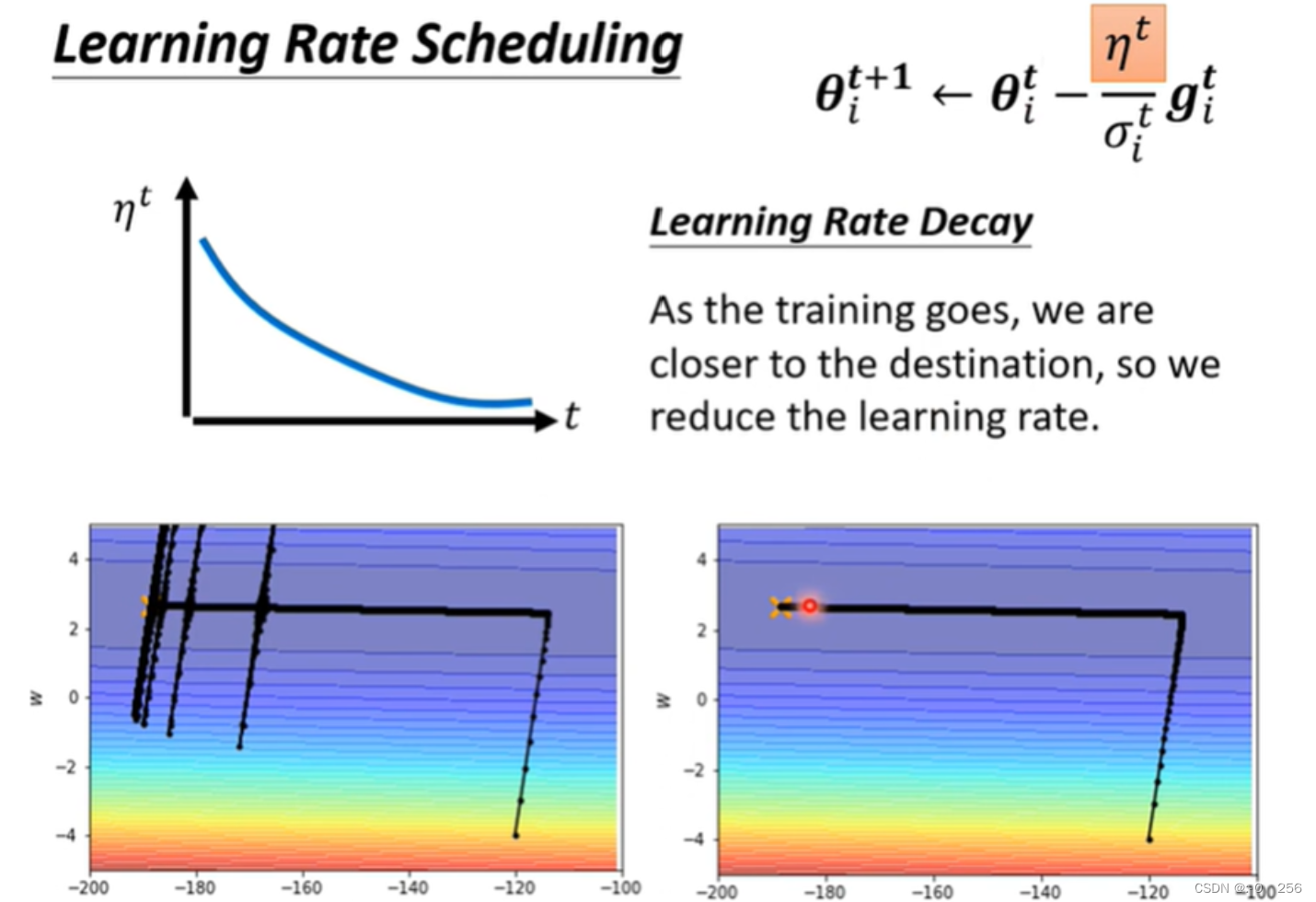
除了 Learning Rate Decay 以外,另外还有一种比较常用的 Learning Rate Scheduling 的方式,叫做 Warm up 。Warm up 与 Learning Rate Decay 不同,通过 Warm up 使 ηt先增大后减小。使用 Warm up 的目的是在训练初期防止模型陷入局部最优解,并帮助模型跳出局部最优点,更好地探索训练空间。通过逐渐增加学习率,模型可以在初始阶段进行更大的权重更新,然后在后期以较小的步伐进行微调。通俗的来说,由于 σt是告诉我们梯度下降过程中某个方向的平滑度和陡峭度,但是需要堆叠多笔梯度后才能更加精准,梯度下降初始阶段,由于迭代次数较少,σt是不精准的,并不能精准的体现梯度下降过程的平滑度和陡峭度,此时如果我们采用较大的学习率,有很大的可能使模型对于数据“过拟合”(“学偏”),后续需要更多的轮次才能“拉回来”。因而一开始我们不要让模型的参数更新过快,也就是不要让学习率过大。在初始阶段逐步增加学习率,进行一定的迭代次数后,使得 σt 逐步精准后,模型对数据具有一定的先验知识,此时使用较大的学习率模型就不容易学“偏”,可以使用较大的学习率加速模型收敛,通过自动调整学习率,合理的提高和降低学习率,进行参数调优。
总结
当模型在训练数据集上误差偏大时应该将模型复杂化 (重新设计模型)或者接近optimization的问题,但模型太过于复杂,训练也会出现过拟合,此时我们需要通过模型评估来选出一个适中的模型。梯度下降是通过不断更新参数,从而降低loss值,当梯度更新至0时,不一定就是最优参数。如果此时loss值仍然没有达到我们的预期,我们此时需要判断梯度为0的点是局部最小点还是鞍点。如果梯度接近0的点是局部最小点,那之后将无法跳出该点搜索全局最小点,无法进一步降低模型的loss值。如果是鞍点,则可以继续更新参数,搜索更优的参数。同时学习到如何合理选择batch的大小,如果过大,模型参数更新至局部最小点或鞍点处就无法更新。如果过小,模型参数仍可以继续更新,这通过batch间接的解决了局部最小点和鞍点的问题。同时也了解了如何自动调整学习率,















 1575
1575











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









