






这里写目录标题
摘要
CNN的基本结构由输入层、卷积层(convolutional layer)、池化层(pooling layer,也称为取样层)、全连接层及输出层构成。卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征图的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,
Abstract
The basic structure of CNN consists of an input layer, a convolutional layer, a pooling layer, a fully connected layer and an output layer. Generally, there are several convolutional layers and pooling layers, and the convolutional layer and pooling layer are alternately set, that is, a convolutional layer is connected to a pooling layer, and then a convolutional layer is connected to the pooling layer, and so on. Since each neuron of the output feature map in the convolutional layer is locally connected to its input, and the input value of the neuron is obtained by the weighted sum of the corresponding connection weight and the local input plus the bias value, this process is equivalent to the convolution process.
1.1 卷积神经网络的概念
1.1.1 什么是CNN?
CNN是一种带有卷积结构的前馈神经网络,卷积结构可以减少深层网络占用的内存量,其中三个关键操作——局部感受野、权值共享、池化层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征图的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,CNN也由此而得名1。
与ANN(Artificial Neural Networks,人工神经网络)的区别:
ANN通过调整内部神经元与神经元之间的权重关系,从而达到处理信息的目的。而在CNN中,其全连接层就是就是MLP,只不过在前面加入了卷积层和池化层。
CNN主要应用于图像识别(计算机视觉,CV),应用有:图像分类和检索、目标定位检测、目标分割、人脸识别、骨骼识别和追踪,具体可见MNIST手写数据识别、猫狗大战、ImageNet LSVRC等,还可应用于自然语言处理和语音识别。
1.1.2 为什么要用CNN?
总的来说,是为了解决两个难题:① 图像需要处理的数据量太大,导致成本很高,效率很低;② 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高。
原因1:图像很大(全连接BP神经网络的缺点)
补充:图像的数据结构
首先了解:计算机存储图片,实际是存储了一个W × H × D的数组(W , H , D )分别表示宽、高、维数,彩色图片包含RGB三维<红、绿、蓝三种颜色通道>)。每一个数字对应一个像素的亮度。
在黑白图像中,我们只需要一个矩阵。每个矩阵都存储0到255之间的值。这个范围是存储图像信息的效率(256之内的值正好可以用一个字节表达)和人眼的敏感度(我们区分有限数量的相同颜色灰度值)之间的折衷。
目前用于计算机视觉问题的图像通常为224x224甚至更大,而如果处理彩色图片则又需加入3个颜色通道(RGB),即224x224x3。
如果构建一个BP神经网络,其要处理的像素点就有224x224x3=150528个,也就是需要处理150528个输入权重,而如果这个网络的隐藏层有1024个节点(这种网络中的典型隐藏层可能有1024个节点),那么,仅第一层隐含层我们就必须训练150528x1024=15亿个权重。这几乎是不可能完成训练的,更别说还有更大的图片了。
原因2:位置可变
如果你训练了一个网络来检测狗,那么无论图像出现在哪张照片中,你都希望它能够检测到狗。
如果构建一个BP神经网络,则需要把输入的图片“展平”(即把这个数组变成一列,然后输入神经网络进行训练)。但这破坏了图片的空间信息。想象一下,训练一个在某个狗图像上运行良好的网络,然后为它提供相同图像的略微移位版本,此时的网络可能就会有完全不同的反应。
并且,有相关研究表明,人类大脑在理解图片信息的过程中,并不是同时观察整个图片,而是更倾向于观察部分特征,然后根据特征匹配、组合,最后得出整图信息。CNN用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。
换句话说,在BP全连接神经网络中,隐含层每一个神经元,都对输入图片 每个像素点 做出反应。这种机制包含了太多冗余连接。为了减少这些冗余,只需要每个隐含神经元,对图片的一小部分区域,做出反应就好了。而卷积神经网络,正是基于这种想法而实现的。
3.1.3 人类的视觉原理
深度学习的许多研究成果,离不开对大脑认知原理的研究,尤其是视觉原理的研究。
人类的视觉原理如下:从原始信号摄入开始(瞳孔摄入像素 Pixels),接着做初步处理(大脑皮层某些细胞发现边缘和方向),然后抽象(大脑判定,眼前的物体的形状,是圆形的),然后进一步抽象(大脑进一步判定该物体是只气球)。
对于不同的物体,人类视觉也是通过这样逐层分级,来进行认知的:

我们可以看到,在最底层特征基本上是类似的,就是各种边缘,越往上,越能提取出此类物体的一些特征(轮子、眼睛、躯干等),到最上层,不同的高级特征最终组合成相应的图像,从而能够让人类准确的区分不同的物体。
那么我们可以很自然的想到:可以不可以模仿人类大脑的这个特点,构造多层的神经网络,较低层的识别初级的图像特征,若干底层特征组成更上一层特征,最终通过多个层级的组合,最终在顶层做出分类呢?
答案是肯定的,这也是许多深度学习算法(包括CNN)的灵感来源。
通过学习,卷积层可以学习到边缘(颜色变化的分界线)、斑块(局部的块状区域)及其他“高级”信息;随着层次加深,提取的信息(正确地讲,是反映强烈的神经元)也越来越抽象,神经元从简单的形状向“高级”信息变化。
1.2 CNN的基本原理
1.2.1 主要结构
CNN主要包括以下结构:
- 输入层(Input layer):输入数据;
- 卷积层(Convolution layer,CONV):使用卷积核进行特征提取和特征映射;
- 激活层:非线性映射(ReLU)
- 池化层(Pooling layer,POOL):进行下采样降维;
- 光栅化(Rasterization):展开像素,与全连接层全连接,某些情况下这一层可以省去;
- 全连接层(Affine layer / Fully Connected layer,FC):在尾部进行拟合,减少特征信息的损失;
- 激活层:非线性映射(ReLU)
- 输出层(Output layer):输出结果。
其中,卷积层、激活层和池化层可叠加重复使用,这是CNN的核心结构。
在经过数次卷积和池化之后,最后会先将多维的数据进行“扁平化”,也就是把(height,width,channel)的数据压缩成长度为height × width × channel的一维数组,然后再与FC层连接,这之后就跟普通的神经网络无异了。
1.2.2 卷积层(Convolution layer)
卷积层由一组滤波器组成,滤波器为三维结构,其深度由输入数据的深度决定,一个滤波器可以看作由多个卷积核堆叠形成。这些滤波器在输入数据上滑动做卷积运算,从输入数据中提取特征。在训练时,滤波器上的权重使用随机值进行初始化,并根据训练集进行学习,逐步优化。
1. 卷积运算
卷积核(Kernel)
- 卷积运算是指以一定间隔滑动卷积核的窗口,将各个位置上卷积核的元素和输入的对应元素相乘,然后再求和(有时将这个计算称为乘积累加运算),将这个结果保存到输出的对应位置。卷积运算如下所示:
对于一张图像,卷积核从图像最始端,从左往右、从上往下,以一个像素或指定个像素的间距依次滑过图像的每一个区域。

- 卷积核大小(f × f )也可以变化,比如1 × 1 、 5 × 5等,此时需要根据卷积核的大小来调节填充尺寸(Padding Size)。一般来说,卷积核尺寸取奇数(因为我们希望卷积核有一个中心,便于处理输出)。卷积核尺寸为奇数时,填充尺寸可以根据以下公式确定:Padding Size = f − 1 2 \frac{f-1}{2} 2f−1 。
可以把卷积核理解为权重。每一个卷积核都可以当做一个“特征提取算子”,把一个算子在原图上不断滑动,得出的滤波结果就被叫做“特征图”(Feature Map),这些算子被称为“卷积核”(Convolution Kernel)。我们不必人工设计这些算子,而是使用随机初始化,来得到很多卷积核,然后通过反向传播优化这些卷积核,以期望得到更好的识别结果。
填充/填白(Padding)
- 在进行卷积层的处理之前,有时要向输入数据的周围填入固定的数据(比如0等),使用填充的目的是调整输出的尺寸,使输出维度和输入维度一致;
如果不调整尺寸,经过很多层卷积之后,输出尺寸会变的很小。所以,为了减少卷积操作导致的,边缘信息丢失,我们就需要进行填充(Padding)。
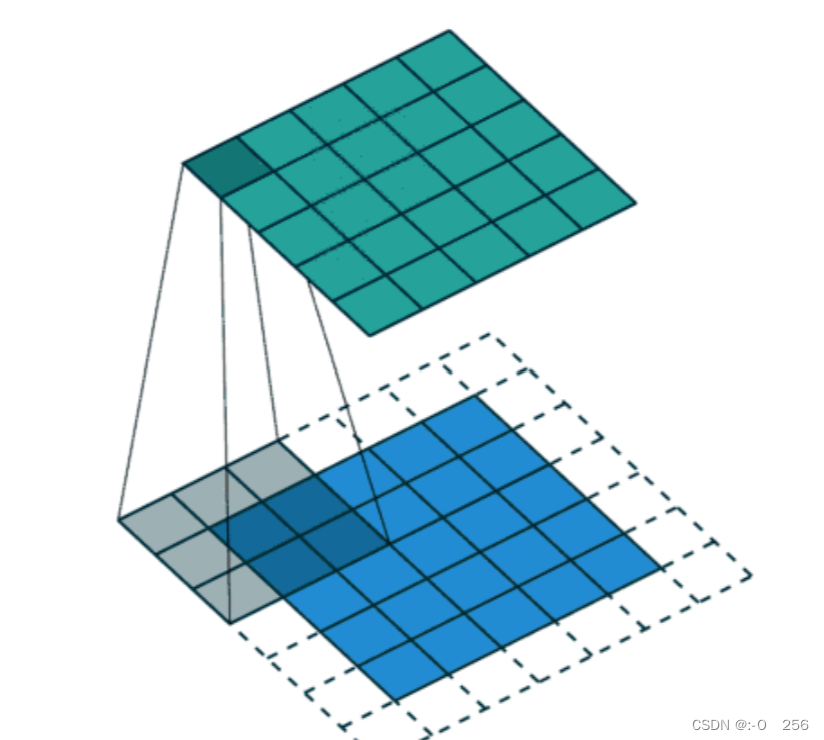
步幅/步长(Stride)
- 即卷积核每次滑动几个像素。前面我们默认卷积核每次滑动一个像素,其实也可以每次滑动2个像素。其中,每次滑动的像素数称为“步长”,步长为2的卷积核计算过程如下;

- 若希望输出尺寸比输入尺寸小很多,可以采取增大步幅的措施。但是不能频繁使用步长为2,因为如果输出尺寸变得过小的话,即使卷积核参数优化的再好,也会必可避免地丢失大量信息;
- 如果用f表示卷积核大小,s 表示步长,w表示图片宽度,h表示图片高度,那么输出尺寸可以表示为:
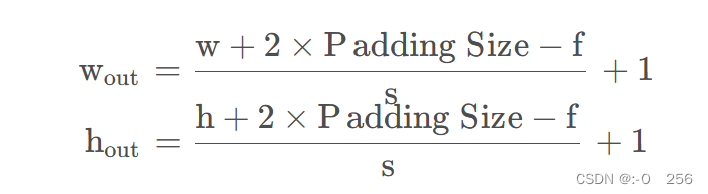
滤波器(Filter) - 卷积核(算子)是二维的权重矩阵;而滤波器(Filter)是多个卷积核堆叠而成的三维矩阵。
在只有一个通道(二维)的情况下,“卷积核”就相当于“filter”,这两个概念是可以互换的
- 上面的卷积过程,没有考虑彩色图片有RGB三维通道(Channel),如果考虑RGB通道,那么每个通道都需要一个卷积核,只不过计算的时候,卷积核的每个通道在对应通道滑动,三个通道的计算结果相加得到输出。即:每个滤波器有且只有一个输出通道
当滤波器中的各个卷积核在输入数据上滑动时,它们会输出不同的处理结果,其中一些卷积核的权重可能更高,而它相应通道的数据也会被更加重视,滤波器会更关注这个通道的特征差异。
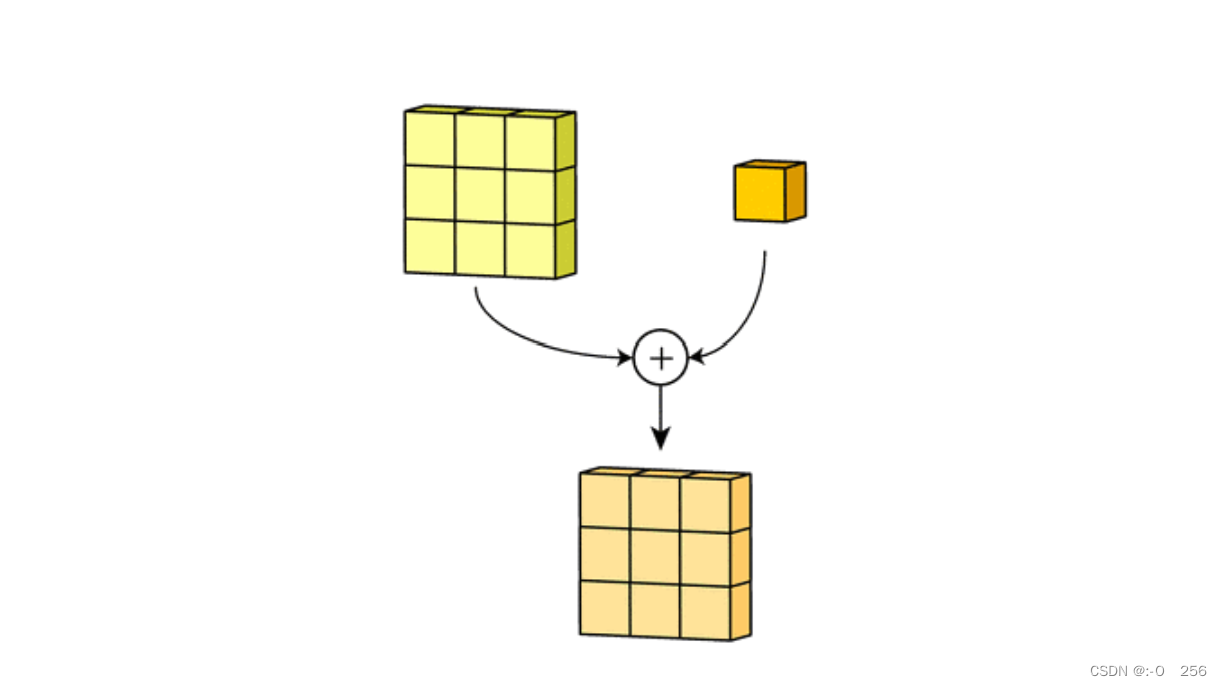
偏置
- 最后,偏置项和滤波器一起作用产生最终的输出通道。
-
多个filter也是一样的工作原理:如果存在多个filter,这时我们可以把这些最终的单通道输出组合成一个总输出,它的通道数就等于filter数。这个总输出经过非线性处理后,继续被作为输入馈送进下一个卷积层,然后重复上述过程。
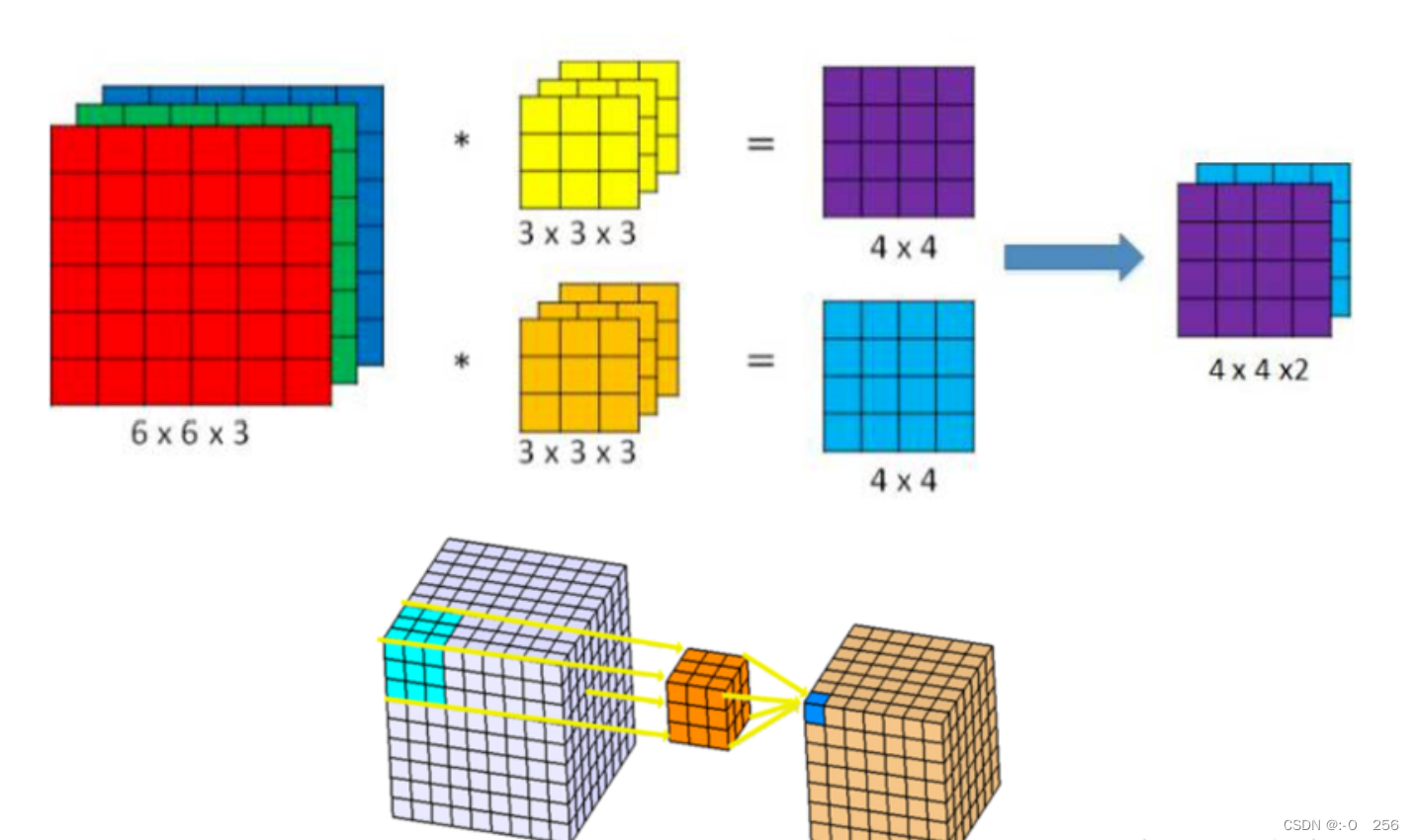
因此,这部分一共4个超参数:滤波器数量K ,滤波器大小F,步长S ,零填充大小P 。
总结
这周复习了CNN的基本原理,对CNN的基础概念更加的清晰了。















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









