







通用版
# -*- coding: utf-8 -*-
"""pretrain.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/1zJJnT_Sg4A7i9ST1uv7FwooeY1qW8HLw
"""
import json
from torch.utils.data import DataLoader, Dataset
import torch
from transformers import AutoTokenizer, DataCollatorForLanguageModeling, DataCollatorWithPadding, Trainer, \
AutoModelWithLMHead, TrainingArguments, AutoConfig,RobertaTokenizer,RobertaForMaskedLM
import pandas as pd
from pathlib import Path
pd.set_option('max_colwidth', 300)
# !wget https://s3.amazonaws.com/code-search-net/CodeSearchNet/v2/python.zip
# !unzip python.zip
import ast
def read_jsonfile(file_name):
data = []
with open(file_name, encoding='utf-8') as f:
data = json.loads(f.read(), strict=False)
return data
pydf = pd.DataFrame(read_jsonfile("发明专利数据.json"))
pydf = pydf[['pat_name', 'pat_applicant', 'pat_summary']]
pydf = pydf.dropna()
pydf['source'] = pydf['pat_name'] + pydf['pat_applicant'] + pydf['pat_summary']
tokenizer = AutoTokenizer.from_pretrained('hfl/chinese-roberta-wwm-ext')
#data_collator就是帮忙实现随机mask
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer, mlm=True, mlm_probability=0.15 #15%的词被mask
)
class PDataset(Dataset):
def __init__(self, df, tokenizer):
super().__init__()
self.df = df.reset_index(drop=True)
# maxlen allowed by model config
self.tokenizer = tokenizer
def __getitem__(self, index):
row = self.df.iloc[index]
doc = row.source
sep = self.tokenizer.sep_token_id
cls = self.tokenizer.cls_token_id
inputs = {}
try:
doc_id = tokenizer(doc, truncation=True, max_length=125) #这个是方便动态batch长度处理
#doc_id = tokenizer(doc, truncation=True, max_length=125,padding="max_length") 这就是静态处理,所有batch都是保证相同维度。
doc_id = data_collator([doc_id]) #随机mask处理
inputs['input_ids'] = doc_id['input_ids'][0].tolist() #输入就是mask后的id
inputs['labels'] = doc_id['labels'][0].tolist() #标签就是原始的id
if 'token_type_ids' in inputs:
inputs['token_type_ids'] = [0] * len(inputs['input_ids'])
except:
print('*'*20)
print(doc)
print('*'*20)
return inputs
def __len__(self):
return self.df.shape[0]
mask_id = tokenizer.mask_token_id
#一个batch是由多个字典所组成的列表。然后各个字典的input_ids长度不一样,但是要保证每个bath要保证各自内部文本长度相同,因此需要下面这个函数来批量化处理。
#这是一种的动态的实现方法,就是batch之间维度不同,内部保证是一样。如果是想要静态的话就不需要下面函数
def data_collator_p(batch):
max_length = max([len(i['input_ids']) for i in batch])
input_id, token_type, labels = [], [], []
for i in batch:
input_id.append(i['input_ids'] + [mask_id]*(max_length-len(i['input_ids']))) #这里也可以是pad_id,因为lable为-100的token是不参与loss的计算.也就是说后面这部分不会参与后面的梯度计算。
#token_type.append(i['token_type_ids'] + [1] * (max_length - len(i['token_type_ids']))) #roberta是不需要token_type的,因为只有mlm
labels.append(i['labels'] + [-100] * (max_length - len(i['labels'])))
output={}
output['input_ids'] = torch.as_tensor(input_id, dtype=torch.long)
#output['token_type_ids'] = torch.as_tensor(token_type, dtype=torch.long)
output['labels'] = torch.as_tensor(labels, dtype=torch.long)
return output
training_args = TrainingArguments(
output_dir='./pretrain_domain_code',
overwrite_output_dir=True,
num_train_epochs=4,
per_device_train_batch_size=16,
save_total_limit=1,
save_strategy='epoch',
learning_rate=2e-5,
# fp16=True, 降低精度,加快训练
gradient_accumulation_steps=4,
)
dataset = PDataset(pydf, tokenizer)
model = AutoModelWithLMHead.from_pretrained('hfl/chinese-roberta-wwm-ext')
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator_p,
train_dataset=dataset,
)
trainer.train()
trainer.save_model('./pretrain_domain_code')
1.自己重新来预训练的目的
- 主要任务就是生成一个我们想要的预训练的一个长度的文本。比如生成一个256维长度(maxlen)的句子,而我们不需要原来Bert的512个词那么大,这时候就需要将huggingface中原来的配置信息代码进行修改。(预训练代码基本上都一样,就主要对hugg上的代码进行微调就行)
- 有论文表明,在当前预训练模型里面基础上,通过相关性较强的数据再次进行预训练,更有益于提高当前任务模型的性能。
- 当遇到加密文本时,比如遇到了脱敏数据集,将文本全都转换成了数字的形式,这些脱敏数据不能够对应到预训练的词向量的汉字,因此通过自己训练一个脱敏预训练模型。
怎么样算一个预训练任务效果好?
这个不好说,只能说看到最终的loss比较低就行了。通过自己预训练后用到下游任务效果会有提升,但是不会很大。自己预训练的数据量越大,模型的提升肯定也会更明显。
自己训练时maxlen的设置
需要自己查看数据,长度为256或者512有没有完全覆盖整个句子。
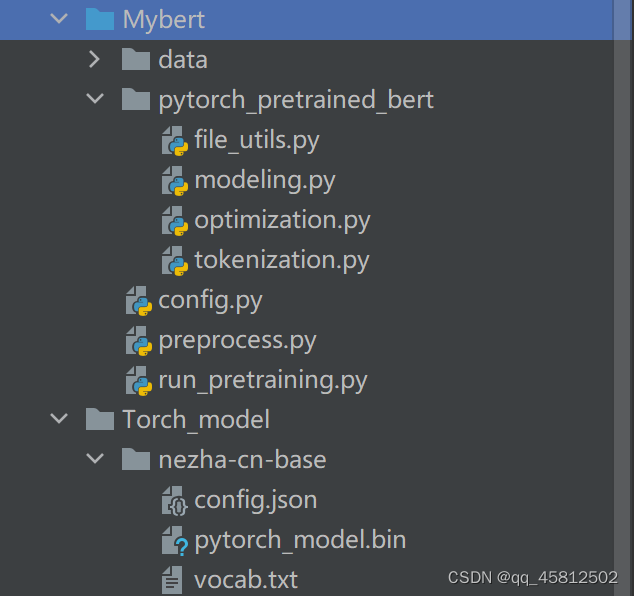
2. 文件目录
- data:是自己的预训练数据
- pytroch_pretrained_bert:不用修改可以理解是为pretrain执行的工具
- config.py:配置文件(自己修改的地方)
- preprocess.py: 将长文档切分成所需配置的预训练语料
- run_pretraining.py:执行整个预训练流程
3. 文件介绍
(1)preprocess.py
我们主要要做的就是预处理部分procesess.py,该文件最终的输出就是一个所有语料corpus.txt,然后该内容会被送到run_pretraining中执行预训练。这里贴上了main函数里的内容,方便理清楚流程。所以需要先运行这个文件生成txt后再拿去pretrain
if __name__ == '__main__':
"""some params"""
split_len = 256 # 长文档切分成所需的预训练语料,这里就是一句话是256个长度
config = Config()
data_path = config.source_data_path
corpus_path = '/root/autodl-tmp/Mybert/data/' #自己需要修改的路径
# 加载数据
unlabeled_df = pd.read_csv(data_path + 'nCoV_900k_train.unlabled.csv', encoding='utf_8_sig')
# 清洗数据
additional_chars = set()
for t in list(unlabeled_df['微博中文内容']):
additional_chars.update(re.findall(u'[^\u4e00-\u9fa5a-zA-Z0-9\*]', str(t)))
print('文中出现的非中英文的数字符号:', additional_chars)
# 一些需要保留的符号
extra_chars = set("!#$%&\()*+,-./:;<=>?@[\\]^_`{|}~!#¥%&?《》{}“”,:‘’。()·、;【】")
print('保留的标点:', extra_chars)
additional_chars = additional_chars.difference(extra_chars)
unlabeled_df['微博中文内容'] = unlabeled_df['微博中文内容'].apply(stop_words)
# 生成bert预训练语料文档
content_text = unlabeled_df['微博中文内容'].tolist()
corpus_list = []
all_char_list = [] # 字表
for doc in tqdm(content_text):
if len(doc) >= split_len:
texts_list, _ = split_text(text=doc, maxlen=split_len, greedy=False)
for text in texts_list:
all_char_list.extend(text)
corpus_list.append(text)
else:
corpus_list.append(doc)
all_char_list.extend(doc) # 加入每一个字
corpus_list.append('') # 不同文档的分隔符
corpus_list = [corpus + '\n' for corpus in corpus_list ]
with open(corpus_path + '{}_corpus.txt'.format(split_len), 'w') as f:
f.writelines(corpus_list)
# # 序列任务从零开始训练时可能需要生成字典,但大部分情况下可以复用google_bert提供的字典。
# #if your need new vocab ,run it!
# generate_vocab(corpus_path,all_char_list)
row_len_list = unlabeled_df['微博中文内容'].apply(len).tolist()
count_64 = []
count_128 = []
count_256 = []
count_384 = []
count_512 = []
count_1024 = []
for len_l in tqdm(row_len_list):
if len_l <= 64:
count_64.append(len_l)
elif 64 < len_l <= 128:
count_128.append(len_l)
elif 128 < len_l <= 256:
count_256.append(len_l)
elif 256 < len_l < 384:
count_384.append(len_l)
elif 384 <= len_l < 512:
count_512.append(len_l)
else:
count_1024.append(len_l)
row_len = len(row_len_list)
print(len(count_64) / row_len)
print(len(count_128) / row_len)
print(len(count_256) / row_len)
print(len(count_384) / row_len)
print(len(count_512) / row_len)
print(len(count_1024) / row_len)
(2)run_pretraining.py
``这个文件基本上就是huggingface里面的内部源码,主要就是介绍了如何跑通源代码,比如说把之前生成的语料送入到模型中、mlm掩码的设计等等都能在这里面看到,因此如果需要自己设计预训练任务的话就是来修改这个文件,其他情况的话就只需要修改一下超参数(如256维度)。
(3)config.py
这个文件时自己主要需要调改的地方。配置自己需要使用的模型
class Config(object):
def __init__(self):
# -----------ARGS---------------------
# 原始数据路径
self.source_data_path = '/root/autodl-tmp/Mybert/data/'
# 预训练数据路径
self.pretrain_train_path = "/root/autodl-tmp/Mybert/data/256_corpus.txt"
# 模型保存路径
self.output_dir = self.source_data_path + "outputs/"
# MLM任务验证集数据,大多数情况选择不验证(predict需要时间,知道验证集只是表现当前MLM任务效果)
self.pretrain_dev_path = ""
# 预训练模型所在路径(文件夹)为''时从零训练,不为''时继续训练。huggingface roberta
# 下载链接为:https://dl.fbaipublicfiles.com/fairseq/models/roberta.base.tar.gz
#我们就是需要基于这个给定的模型再次预训练
self.pretrain_model_path = '/root/autodl-tmp/Torch_model/nezha-cn-base/'
self.bert_config_json = self.pretrain_model_path + "bert_config.json" # 为''时从零训练
self.vocab_file = self.pretrain_model_path + "vocab.txt"
self.init_model = self.pretrain_model_path #这个就是执行的是用初始化好的权重进行训练pytorch_model.bin文件
self.max_seq_length = 256 # 文本长度,这是我们主要结合数据和电脑配置进行调整的数据。就是把长文本分成多个256字长的句子
self.do_train = True
self.do_eval = False
self.do_lower_case = False # 数据是否全变成小写(是否区分大小写)
self.train_batch_size = 24 # 根据GPU卡而定,16G的能够跑24
self.eval_batch_size = 32
# 继续预训练lr:5e-5,重新预训练:1e-4
self.learning_rate = 5e-5
self.num_train_epochs = 16 # 预训练轮次
self.save_epochs = 2 # e % save_epochs == 0 保存
# 前warmup_proportion的步伐 慢热学习比例
self.warmup_proportion = 0.1
self.dupe_factor = 1 # 动态掩盖倍数
self.no_cuda = False # 是否使用gpu
self.local_rank = -1 # 分布式训练
self.seed = 42 # 随机种子,初始化权重相同
# 梯度累积(相同显存下能跑更大的batch_size)1不使用
self.gradient_accumulation_steps = 1
self.fp16 = False # 混合精度训练
self.loss_scale = 0. # 0时为动态
# bert Transormer的参数设置
self.masked_lm_prob = 0.15 # 掩盖率
# 最大掩盖字符数目
self.max_predictions_per_seq = 20
# 冻结word_embedding参数
self.frozen = True
# bert参数解释,这个就是在下载预训练时的config文件
#当自己的数据集比较小的话,可以适当修改下面的一些参数值
"""
{
# 乘法attention时,softmax后dropout概率
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu", # 激活函数
"hidden_dropout_prob": 0.1, #隐藏层dropout概率
"hidden_size": 768, # 最后输出词向量的维度
"initializer_range": 0.02, # 初始化范围
"intermediate_size": 3072, # 升维维度
"max_position_embeddings": 512, # 最大的
"num_attention_heads": 12, # 总的头数
# 隐藏层数 ,也就是transformer的encode运行的次数
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2, # segment_ids类别 [0,1]
"vocab_size": 21128 # 词典中词数
}
"""
















 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









