







集成算法
bagging
每个模型之间相互独立,各自训练之后取平均就是结果。典型代表就是随机森林,基础模型就是决策树。
- 优点:各个基础模型独立训练,因此并行性更高,速度更快。
- 缺点:因为模型独立,而基础模型的精度也有限,因此总体模型的精度上限也不算很高。
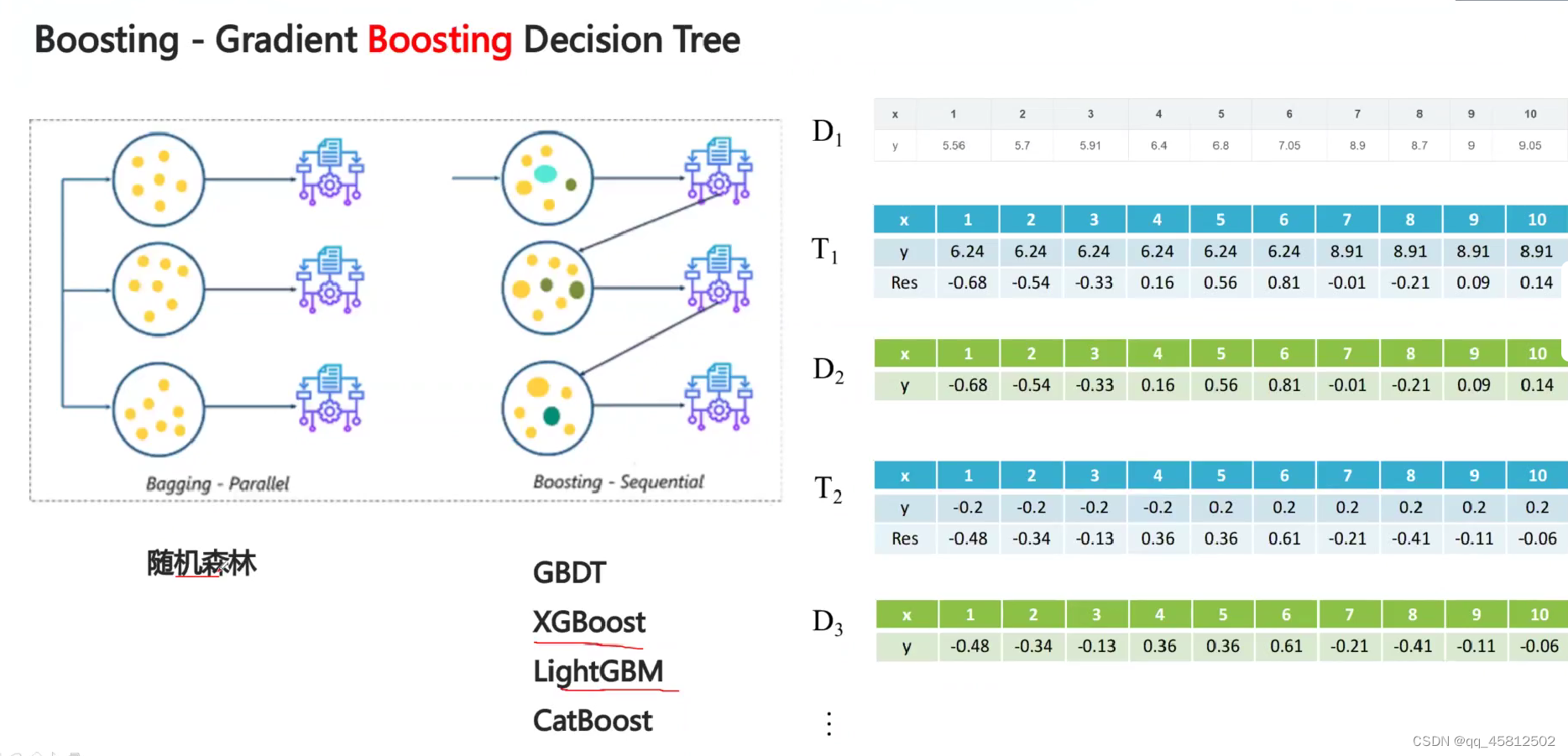
Boosting
模型和模型训练是有关联的。训练完一个模型后,会根据它的结果专门训练下一个模型去修补某些误差。就像打高尔夫球一样,不能一杆进洞,但每次都是靠着目标不断逼近。

GBDT
梯度提升树实际上就是梯度下降的应用。它的计算沿用了boosting思想一步步进行迭代,当计算第n+1步的损失值时,前n步的预测值
F
n
(
x
)
F_n(x)
Fn(x)已经是个定值了,因此我们需要找到移到第n+1步的距离,也就是
δ
n
\delta_n
δn,使得损失函数值最小。GDBT的策略就是让
δ
n
\delta_n
δn为第n步时损失函数的梯度。但是因为梯度是泰勒的一阶展开,因此GDBT的精度也有限。因此自然而然就想到了用二阶导数(海森矩阵)来更加逼近,这也就是Xgboost的核心思想。

Xgboost
但是因为梯度是泰勒的一阶展开,因此GDBT的精度也有限。因此自然而然就想到了用二阶导数(海森矩阵)来更加逼近,这也就是Xgboost的核心思想。
但是因为每一棵决策树都需要等到前面的决策树运行完了之后才能进行跑当前的树(串型),并且每次都计算了二阶泰勒项,因此Xgboost会很慢。

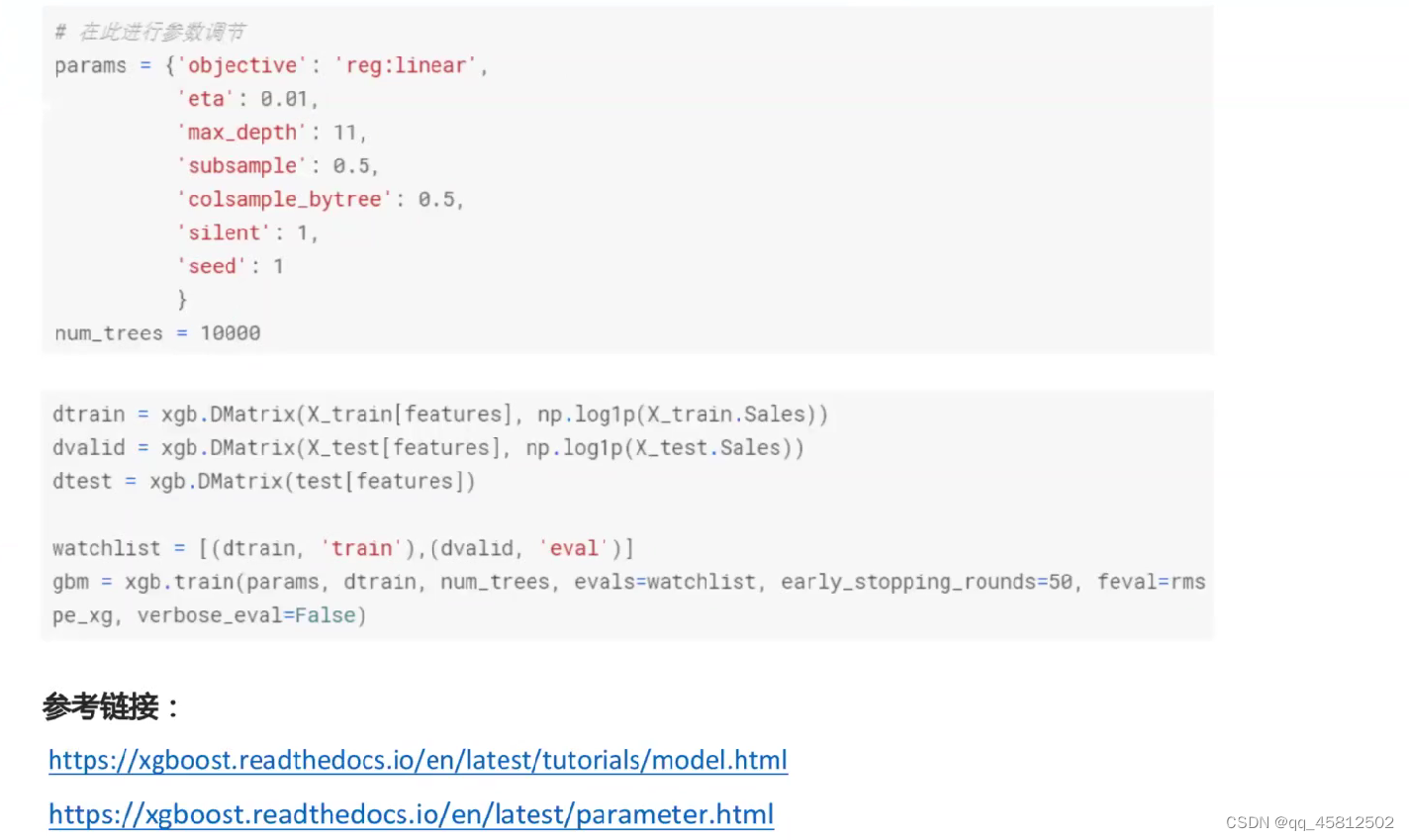
Xgboost的代码模板相对比较固定,只需要结合实际任务与文档描述修改字典里相应的参数值就行了。
lightGBM
Xgboost虽然精度较高,但是由于算法架构导致了执行的速度非常的慢,因此在工业级数据集的规模很有可能会被卡死。因此微软就提出了lightGBM,在保证了精度的同时,运行效率也更快。因此也是目前kaggle数据挖掘比赛的主流算法(最优可能不是它,但是baseline基本上都是基于lightGBM搭建的)
lightGBM的底层实现十分复杂,并且每个人写的lightGBM代码也可能风格不一样(接口很多),因此需要多阅读官方文档了解清楚。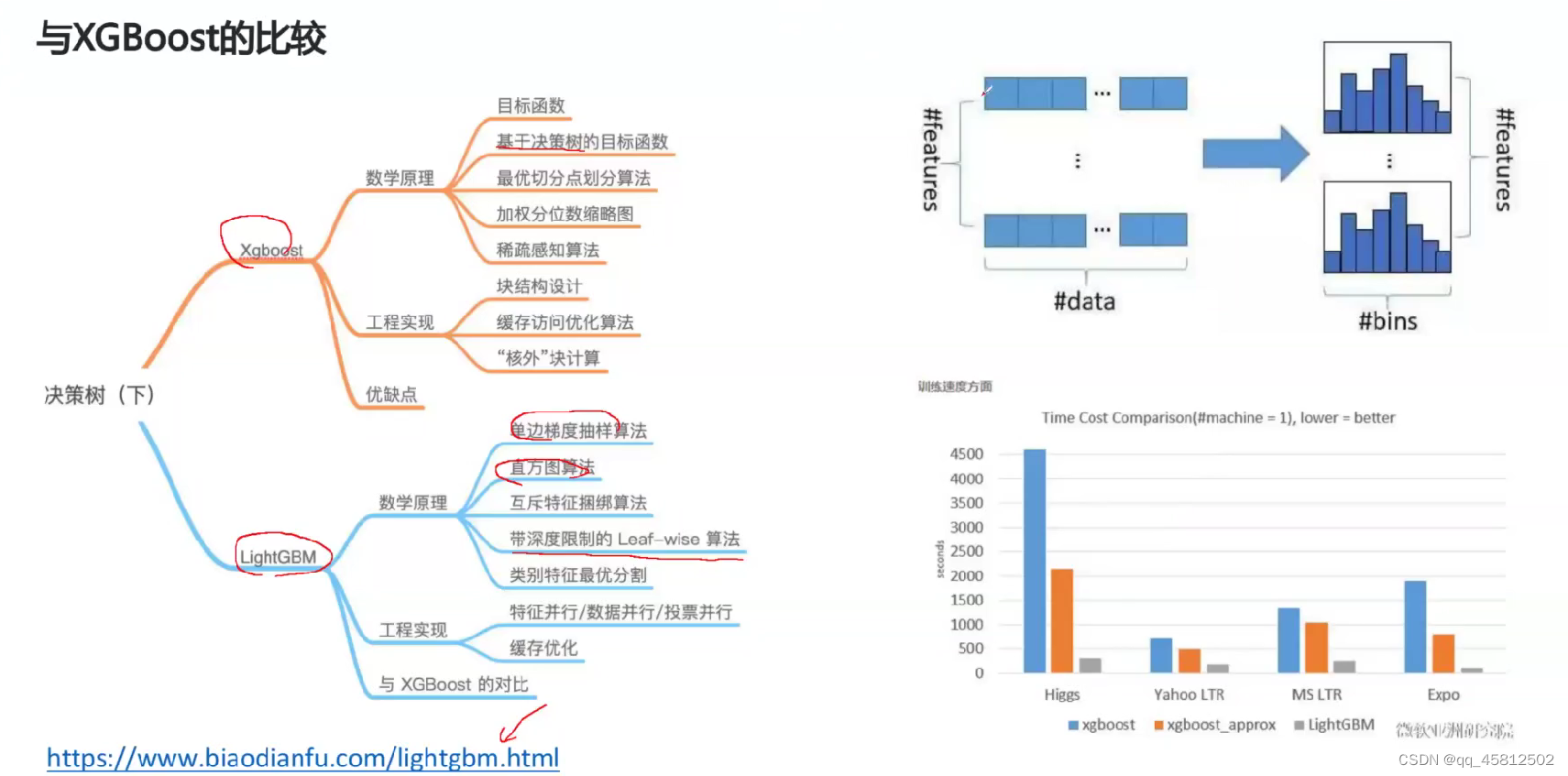
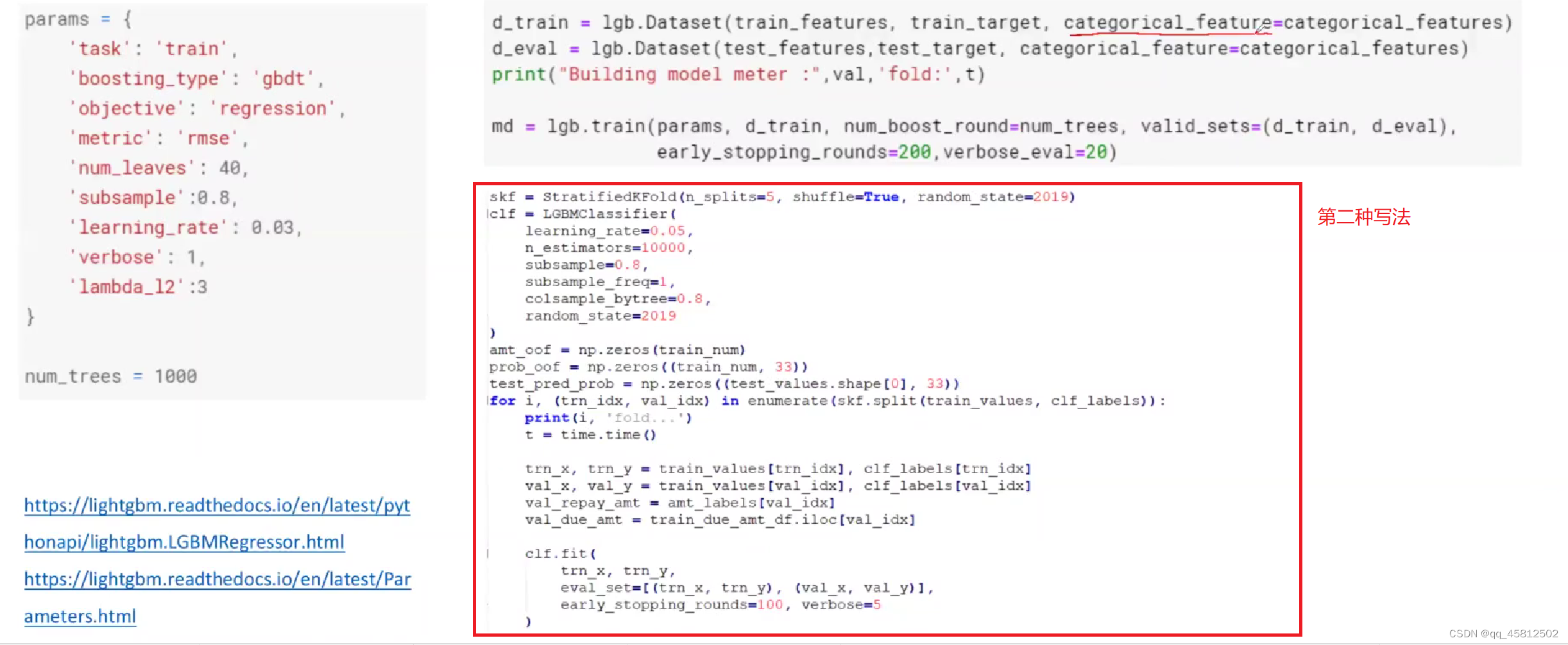
下面这个就是lightGBM的代码,其中这个num_leaves的参数值就是叶子节点数,通常的值就是32-256。图中圈起来的部分就是国内常用的baseline写法。(其实按照上面老师写的字典格式更加清晰)
Catboost
相较于lightGBM性能要低一点,但是代码风格较为统一,并且GPU支持好。

















 9496
9496











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









