







决策树简介
决策树算法是一个可解释性极高的算法,它会把更加重要的指标放在前面来进行判断。某些领域十分看重可解释性,例如银行,风控领域等。
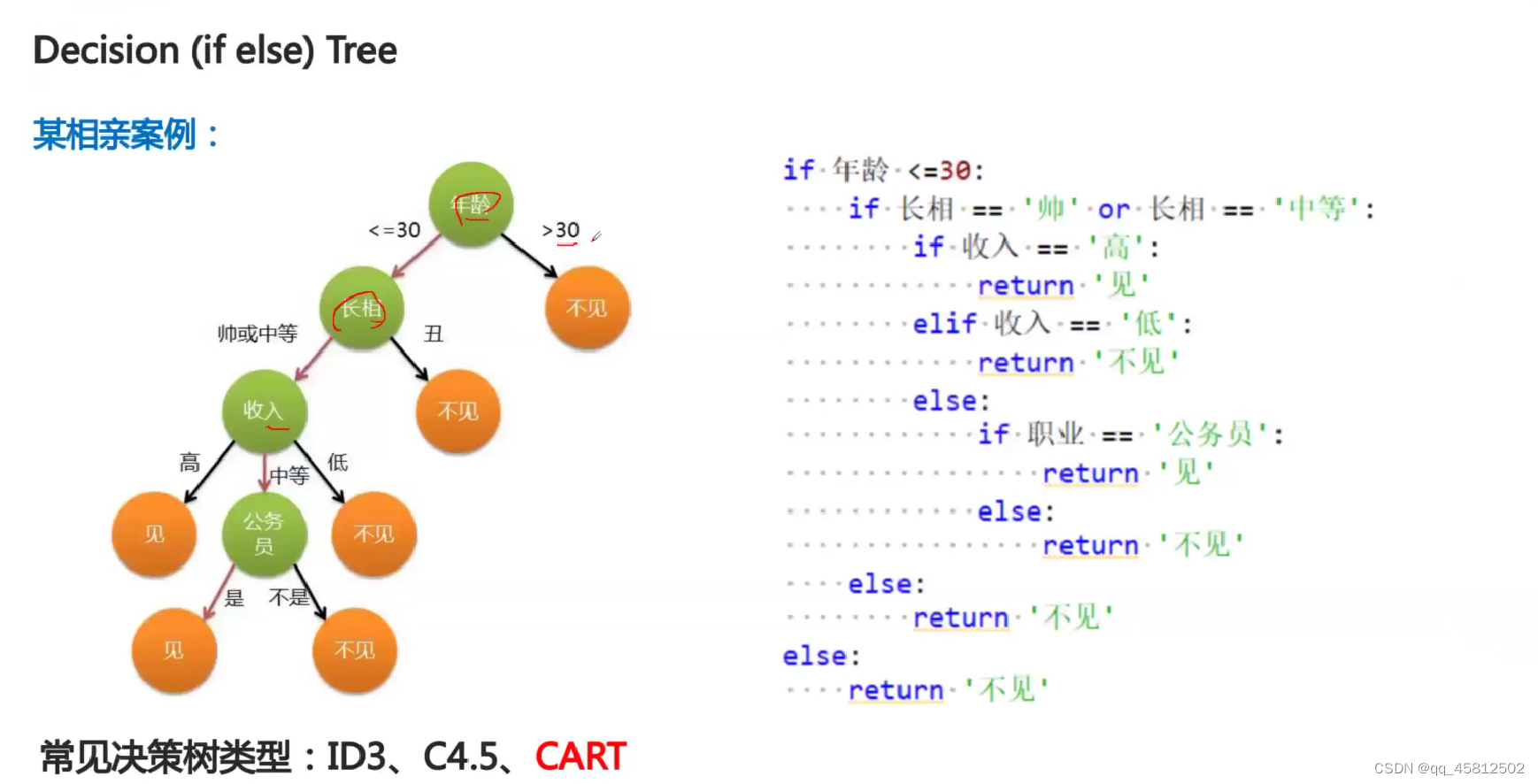
决策树训练的对象
- 对于多元线性回归、神经网络、SVM这种训练的对象都是权重w和b。
- 对于决策树而言,首先训练的对象就是所有特征的排序(越重要越靠前);第二个就是确定每次要分割特征所对应的最优分割点(ID3不需要)。
选取特征和分割标准
对比每个特征选取前后所对应子集信息熵的下降程度(也就是信息增益)。然后每次都选择信息增益最大的那个。例如下图的例子,首先是计算选取之前总的信息熵,然后假设选择了outlook特征作为第一个划分特征。然后特征有sunny,rain,overcast三种离散取值。然后各个取值下都有对应的标签都有样本子集,我们就是要看此时对应标签类别分布情况(看划分的纯度高不高)。
ID3和C4.5是一个模型,唯一的区别就是ID3用的是信息增益,C4.5用的是信息增益率(=信息增益/该特征的取值个数),考虑了特征的取值数对于信息的影响
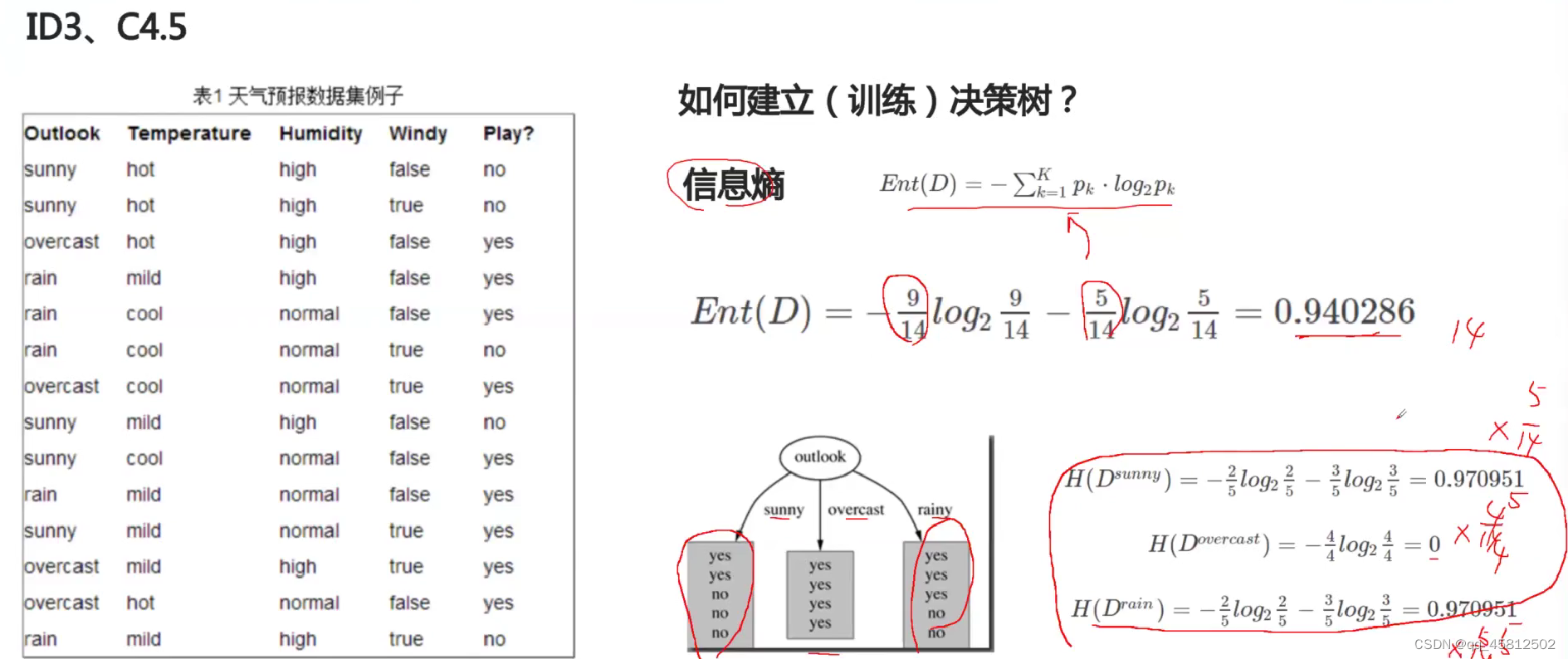
在各自子集计算的信息熵是无法直接原来总的信息熵进行比较,因此需要把该标签下各种取值的信息熵进行加权求和后再进行比较。

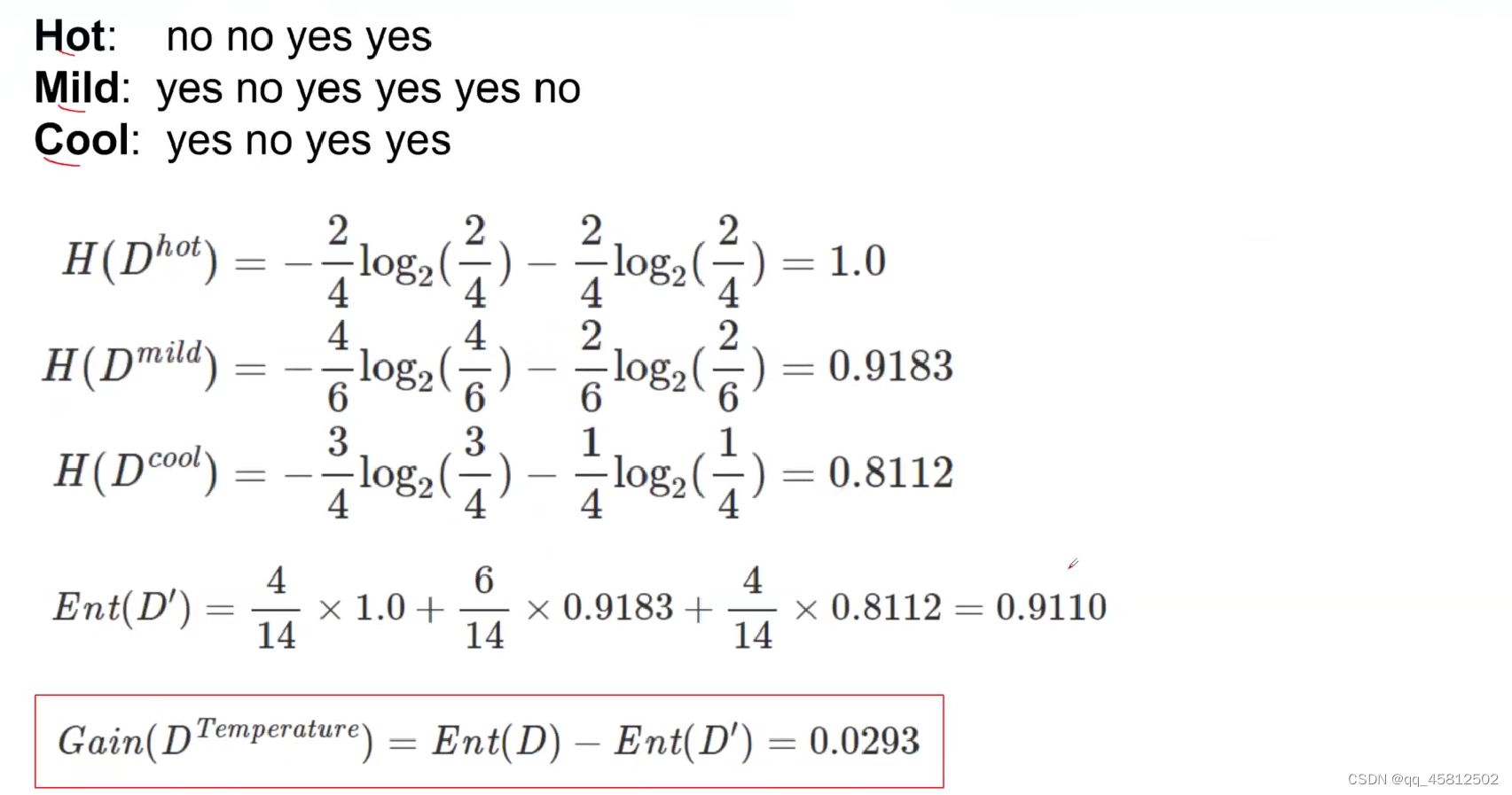
可以看到temperature的信息增益要小于outlook,因此outlook重要性更低。
CART树
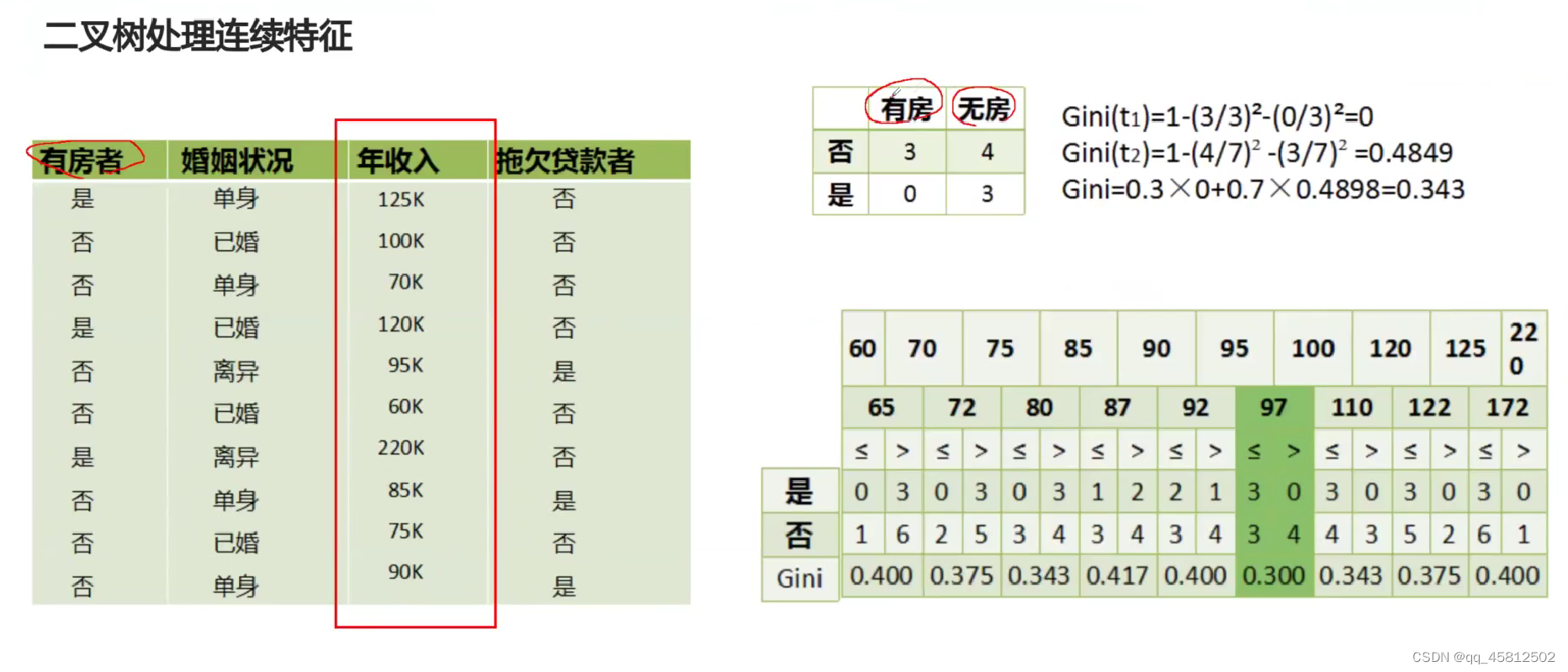
ID3和C4.5最大的缺陷就是遇到连续性数据时,决策树就不能进行分裂了(ID3是特征的离散值进行划分的,当为连续的时候就没办法穷举了)。
CART使用基尼系数而不使用信息熵的原因
因为cart树是一颗二叉树,在二分类的情况下基尼系数值近似等于信息熵,而基尼系数计算会比信息熵更快一些(平方运算比log快)

对于连续特征值的划分点就是暴力穷举,列出所有的取值排序,然后两个数值之间的均值来作为划分点(可以划出大于和小于等于两个区域),然后比较所有的划分点的信息增益,选取最大的那个作为划分点。


















 830
830

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









