







文章目录
前言
以YOLOV4为例,分别用Mobilenetv1,Mobilenetv2,Mobilenetv3替换YOLOV4主干。
一、YOLOV4主干网络

二、Mobilenetv1,Mobilenetv2,Mobilenetv3构建
1.Mobilenetv1构建(深度可分离卷积)

代码如下(示例):
import torch
import torch.nn as nn
def conv_bn(inp, oup, stride = 1):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True)
)
def conv_dw(inp, oup, stride = 1):
return nn.Sequential(
# part1
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU6(inplace=True),
# part2
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True),
)
class MobileNetV1(nn.Module):
def __init__(self):
super(MobileNetV1, self).__init__()
self.stage1 = nn.Sequential(
# 416,416,3 -> 208,208,32
conv_bn(3, 32, 2),
# 208,208,32 -> 208,208,64
conv_dw(32, 64, 1),
# 208,208,64 -> 104,104,128
conv_dw(64, 128, 2),
conv_dw(128, 128, 1),
# 104,104,128 -> 52,52,256
conv_dw(128, 256, 2),
conv_dw(256, 256, 1),
)
# 52,52,256 -> 26,26,512
self.stage2 = nn.Sequential(
conv_dw(256, 512, 2),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
conv_dw(512, 512, 1),
)
# 26,26,512 -> 13,13,1024
self.stage3 = nn.Sequential(
conv_dw(512, 1024, 2),
conv_dw(1024, 1024, 1),
)
self.avg = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(1024, 1000)
def forward(self, x):
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.avg(x)
# x = self.model(x)
x = x.view(-1, 1024)
x = self.fc(x)
return x
def mobilenet_v1(pretrained=False, progress=True):
model = MobileNetV1()
if pretrained:
state_dict = torch.load('./model_data/mobilenet_v1_weights.pth')
model.load_state_dict(state_dict, strict=True)
return model
if __name__ == "__main__":
import torch
from torchsummary import summary
# 需要使用device来指定网络在GPU还是CPU运行
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = mobilenet_v1().to(device)
summary(model, input_size=(3, 416, 416))
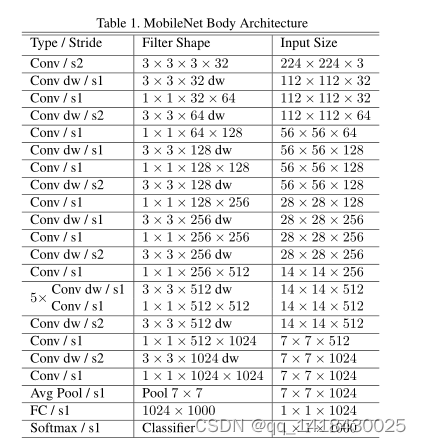
2.Mobilenetv2构建(倒残差结构)
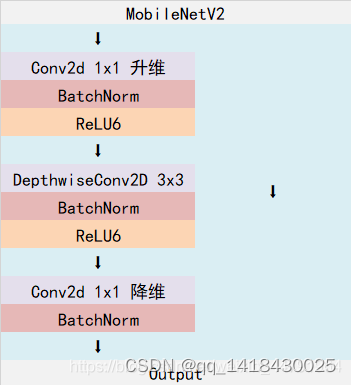
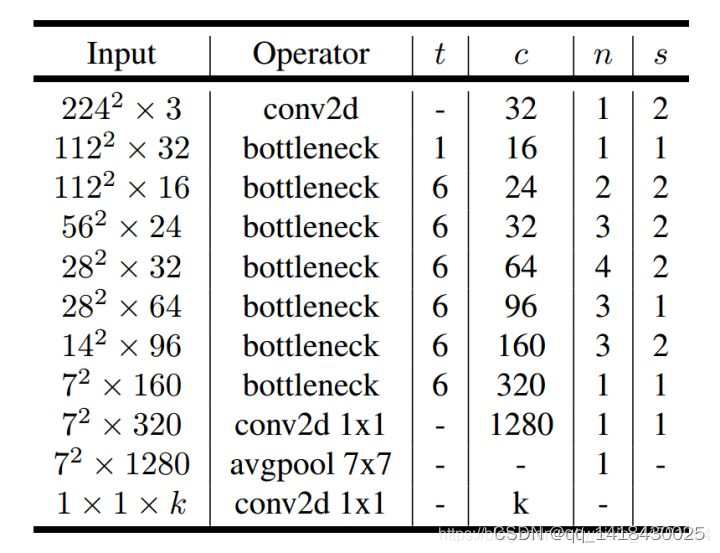

代码如下(示例):
from torch import nn
from torchvision.models.utils import load_state_dict_from_url
model_urls = {
'mobilenet_v2': 'https://download.pytorch.org/models/mobilenet_v2-b0353104.pth',
}
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
class ConvBNReLU(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_planes),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.use_res_connect = self.stride == 1 and inp == oup
layers = []
if expand_ratio != 1:
layers.append(ConvBNReLU(inp, hidden_dim, kernel_size=1))
layers.extend([
ConvBNReLU(hidden_dim, hidden_dim, stride=stride, groups=hidden_dim),
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.0, inverted_residual_setting=None, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = 32
last_channel = 1280
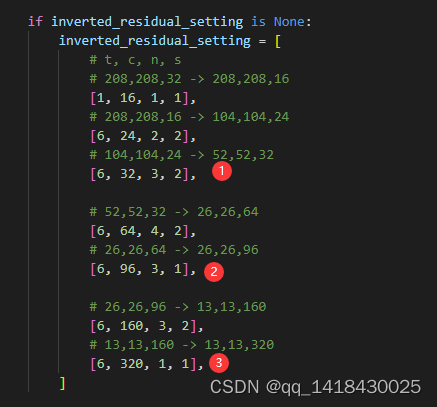
if inverted_residual_setting is None:
inverted_residual_setting = [
# t, c, n, s
# 208,208,32 -> 208,208,16
[1, 16, 1, 1],
# 208,208,16 -> 104,104,24
[6, 24, 2, 2],
# 104,104,24 -> 52,52,32
[6, 32, 3, 2],
# 52,52,32 -> 26,26,64
[6, 64, 4, 2],
# 26,26,64 -> 26,26,96
[6, 96, 3, 1],
# 26,26,96 -> 13,13,160
[6, 160, 3, 2],
# 13,13,160 -> 13,13,320
[6, 320, 1, 1],
]
if len(inverted_residual_setting) == 0 or len(inverted_residual_setting[0]) != 4:
raise ValueError("inverted_residual_setting should be non-empty "
"or a 4-element list, got {}".format(inverted_residual_setting))
input_channel = _make_divisible(input_channel * width_mult, round_nearest)
self.last_channel = _make_divisible(last_channel * max(1.0, width_mult), round_nearest)
# 416,416,3 -> 208,208,32
features = [ConvBNReLU(3, input_channel, stride=2)]
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * width_mult, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
features.append(ConvBNReLU(input_channel, self.last_channel, kernel_size=1))
self.features = nn.Sequential(*features)
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(self.last_channel, num_classes),
)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = x.mean([2, 3])
x = self.classifier(x)
return x
def mobilenet_v2(pretrained=False, progress=True):
model = MobileNetV2()
if pretrained:
state_dict = load_state_dict_from_url(model_urls['mobilenet_v2'], model_dir="model_data",
progress=progress)
model.load_state_dict(state_dict)
return model
if __name__ == "__main__":
print(mobilenet_v2())
3.Mobilenetv3构建(bneck结构)

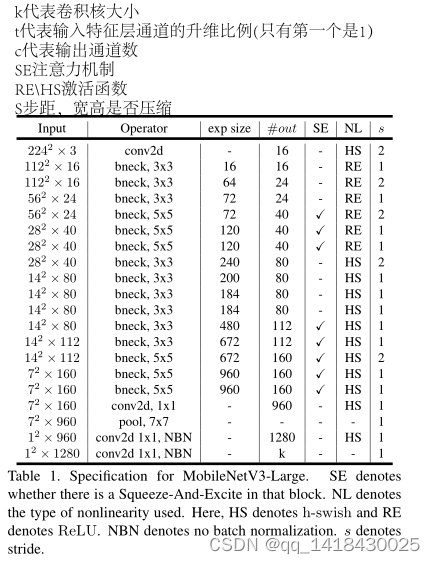
代码如下(示例):
import math
import torch
import torch.nn as nn
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, _make_divisible(channel // reduction, 8)),
nn.ReLU(inplace=True),
nn.Linear(_make_divisible(channel // reduction, 8), channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
def conv_1x1_bn(inp, oup):
return nn.Sequential(
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
class InvertedResidual(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se, use_hs):
super(InvertedResidual, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Identity(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Identity(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.identity:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV3(nn.Module):
def __init__(self, num_classes=1000, width_mult=1.):
super(MobileNetV3, self).__init__()
# setting of inverted residual blocks
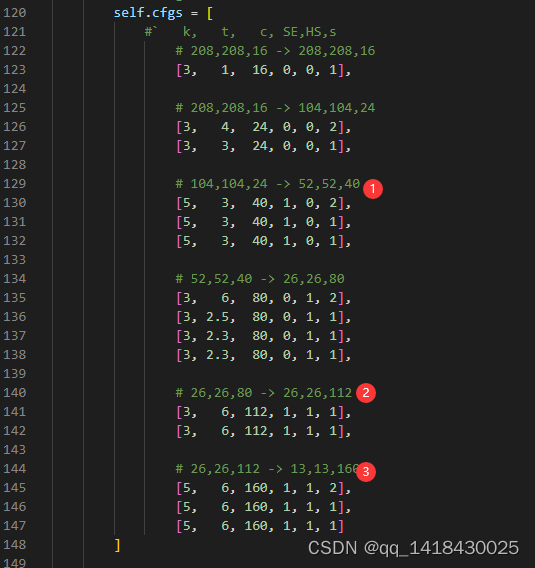
self.cfgs = [
#` k, t, c, SE,HS,s
# 208,208,16 -> 208,208,16
[3, 1, 16, 0, 0, 1],
# 208,208,16 -> 104,104,24
[3, 4, 24, 0, 0, 2],
[3, 3, 24, 0, 0, 1],
# 104,104,24 -> 52,52,40
[5, 3, 40, 1, 0, 2],
[5, 3, 40, 1, 0, 1],
[5, 3, 40, 1, 0, 1],
# 52,52,40 -> 26,26,80
[3, 6, 80, 0, 1, 2],
[3, 2.5, 80, 0, 1, 1],
[3, 2.3, 80, 0, 1, 1],
[3, 2.3, 80, 0, 1, 1],
# 26,26,80 -> 26,26,112
[3, 6, 112, 1, 1, 1],
[3, 6, 112, 1, 1, 1],
# 26,26,112 -> 13,13,160
[5, 6, 160, 1, 1, 2],
[5, 6, 160, 1, 1, 1],
[5, 6, 160, 1, 1, 1]
]
input_channel = _make_divisible(16 * width_mult, 8)
# 416,416,3 -> 208,208,16
layers = [conv_3x3_bn(3, input_channel, 2)]
block = InvertedResidual
for k, t, c, use_se, use_hs, s in self.cfgs:
output_channel = _make_divisible(c * width_mult, 8)
exp_size = _make_divisible(input_channel * t, 8)
layers.append(block(input_channel, exp_size, output_channel, k, s, use_se, use_hs))
input_channel = output_channel
self.features = nn.Sequential(*layers)
self.conv = conv_1x1_bn(input_channel, exp_size)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
output_channel = _make_divisible(1280 * width_mult, 8) if width_mult > 1.0 else 1280
self.classifier = nn.Sequential(
nn.Linear(exp_size, output_channel),
h_swish(),
nn.Dropout(0.2),
nn.Linear(output_channel, num_classes),
)
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = self.conv(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
n = m.weight.size(1)
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def mobilenet_v3(pretrained=False, **kwargs):
model = MobileNetV3(**kwargs)
if pretrained:
state_dict = torch.load('./model_data/mobilenetv3-large-1cd25616.pth')
model.load_state_dict(state_dict, strict=True)
return model
三、获得主干网络中的三个有效特征层(yolo4.py)
1.导入库
import torch
import torch.nn as nn
from collections import OrderedDict
from nets.mobilenet_v1 import mobilenet_v1
from nets.mobilenet_v2 import mobilenet_v2
from nets.mobilenet_v3 import mobilenet_v3
2.Mobilenetv1

class MobileNetV1(nn.Module):
def __init__(self, pretrained = False):
super(MobileNetV1, self).__init__()
self.model = mobilenet_v1(pretrained=pretrained)
def forward(self, x):
out3 = self.model.stage1(x)
out4 = self.model.stage2(out3)
out5 = self.model.stage3(out4)
return out3, out4, out5
3.Mobilenetv2
class MobileNetV2(nn.Module):
def __init__(self, pretrained = False):
super(MobileNetV2, self).__init__()
self.model = mobilenet_v2(pretrained=pretrained)
def forward(self, x):
out3 = self.model.features[:7](x)
out4 = self.model.features[7:14](out3)
out5 = self.model.features[14:18](out4)
return out3, out4, out5
4.Mobilenetv3
class MobileNetV3(nn.Module):
def __init__(self, pretrained = False):
super(MobileNetV3, self).__init__()
self.model = mobilenet_v3(pretrained=pretrained)
def forward(self, x):
out3 = self.model.features[:7](x)
out4 = self.model.features[7:13](out3)
out5 = self.model.features[13:16](out4)
return out3, out4, out5
四、YOLOV4主干特征提取网络的替换(yolo4.py)
1.在YoloBody定义backbone=“mobilenetv2”
class YoloBody(nn.Module):
def __init__(self, anchors_mask, num_classes, backbone="mobilenetv2", pretrained=False):
2.判断backbone是否是上面预先定义的类别
if backbone == "mobilenetv1":
#---------------------------------------------------#
# 52,52,256;26,26,512;13,13,1024
#---------------------------------------------------#
self.backbone = MobileNetV1(pretrained=pretrained)
in_filters = [256, 512, 1024]
elif backbone == "mobilenetv2":
#---------------------------------------------------#
# 52,52,32;26,26,92;13,13,320
#---------------------------------------------------#
self.backbone = MobileNetV2(pretrained=pretrained)
in_filters = [32, 96, 320]
elif backbone == "mobilenetv3":
#---------------------------------------------------#
# 52,52,40;26,26,112;13,13,160
#---------------------------------------------------#
self.backbone = MobileNetV3(pretrained=pretrained)
in_filters = [40, 112, 160]
3.关于通道不匹配错误的问题,需要修改卷积使用的输入通道数。
3.1 首先定义三个有效特征层的输出通道数是多少。
52,52,256;26,26,512;13,13,1024(mobilenetv1)
52,52,32;26,26,92;13,13,320(mobilenetv2)
52,52,40;26,26,112;13,13,160(mobilenetv3)
in_filters = [256, 512, 1024]
in_filters = [32, 96, 320]
in_filters = [40, 112, 160]
3.2 然后需要修改卷积使用的输入通道数
self.conv1 = make_three_conv([512, 1024], in_filters[2]) #1024->in_filters[2]
self.conv_for_P4 = conv2d(in_filters[1], 256,1) #512->in_filters[1]
self.conv_for_P3 = conv2d(in_filters[0], 128,1) #256->in_filters[0]
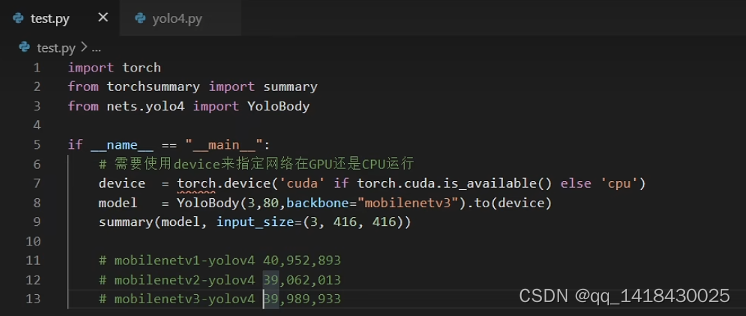
4.参数量(大量的参数是在PAnet里面)
五、PAnet加强特征提取网络修改,使参数量更小(yolo4.py)
5.1 思路:PAnet大部分使用了3x3卷积,而在mobilenetv1里面提到过可以将深度可分离卷积替换3x3卷积,即可实现参数量的大幅度缩小。将下面深度可分离卷积用在yolo4.py中。
def conv_dw(inp, oup, stride = 1):
return nn.Sequential(
# part1
nn.Conv2d(inp, inp, 3, stride, 1, groups=inp, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU6(inplace=True),
# part2
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU6(inplace=True),
)
5.2 在三次卷积块和五次卷积块以及yolo-head都会用到3x3卷积,用深度可分离卷积进行替换。用下面的方式全部进行替换。
conv2d(filters_list[0],filters_list[1],3)修改为下面的代码块:
conv_dw(filters_list[0], filters_list[1])



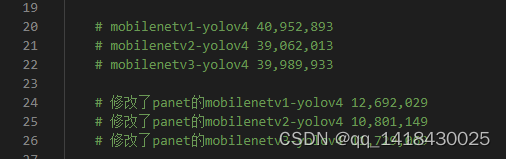
5.3 参数量变化
六、训练参数详解(train.py)
6.1 backbone
backbone = "mobilenetv1"
6.2 model_path(要和backbone相对应,比如采用主干是mobilenetv1,对应的权值文件也是mobilenetv1,即根骨不同主干和权值)
model_path = 'model_data/yolov4_mobilenet_v1_voc.pth'
七、利用训练好的模型进行预测(predict.py),在yolo.py文件中更改三个地方:model_path(训练好的权值文件logs),classes_path(类别文件),backbone(与训练好的权值文件logs主干特征提取网络相对应).
"model_path" : 'model_data/yolov4_mobilenet_v1_voc.pth',
"classes_path" : 'model_data/voc_classes.txt',
"backbone" : 'mobilenetv1',
总结
完成了主干的修改和PAnet的修改,主干部分就是将yolo主干替换成mobilenet,PAnet部分是利用mobilenetv1的思想,利用深度可分离卷积3x3卷积+1x1卷积替换普通的卷积块。根据这个思想可以进一步减少yolo的参数。

















 480
480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











