






笔者是清华在读研究生,主要关注人形机器人、具身智能。将持续分享行业前沿动态、学者观点整理、论文阅读笔记、知识学习路线等。欢迎交流
2024年6月中旬,北大的董豪老师在北京智源大会上发表演讲,主要介绍了其组在具身智能方向上的工作。主要分为Manipulation、Planning、Navigation三个方面
感觉董老师组方向还是比较多的,以下大多是这两年的新工作。该篇为学习整理笔记
引言
2023年4月,谷歌发布了RT1,具身智能逐渐火起来。其在厨房中采集数据,直接训练端到端模型,该模型可以根据人类命令直接输出末端动作,其缺陷在于泛化性,难以适应多样未知场景。这是具身智能目前的发展制约之一。但也许不需要一上来就做端到端模型?
例如,人类的"具身智能": 人类大脑有不同脑区,负责不同功能。比如有的部分负责空间感知,有的部分负责区域导航,有的负责高层级决策规划,有的部分与手腿运动有关
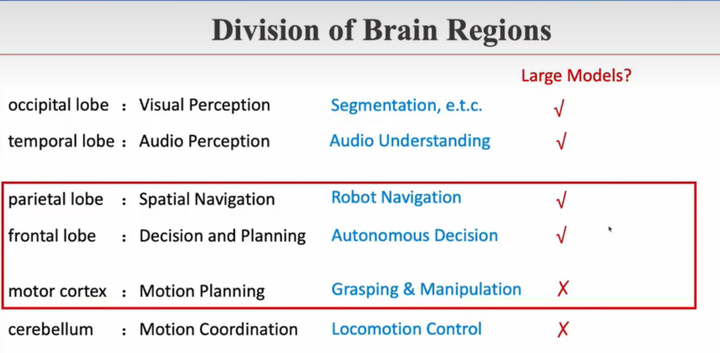
也许可以将机器人的"具身智能"像大脑功能区域划分一样,也分层实现
Manipulation
仿真数据
通过从现实世界或者AIGC生成大量3D物体。从真实世界中扫描各种环境。物体+环境组合,生成Mix Reality Data,不同物体在不同位置上的组合,且减少标注工作
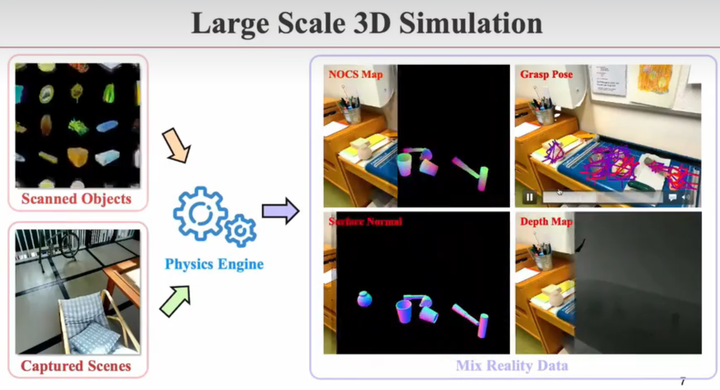
仿真平台
-
发布大一统仿真训练平台OminSim
-
自动生成、组合物体。支持主流仿真器,可以实现一键切换。可实现多仿真器同时训练。支持sim2sim评估,便于超大规模测试。提供真实环境部署迁移工具链

抓取
通过海量仿真数据,训练抓取模型:

添加图片注释,不超过 140 字(可选)
姿态估计
· Generative Category-level Object Pose Estimation via Diffusion Models. NeurIPS 2023
· Omni6DPose: A Benchmark and Model for Universal 6D Object Pose Estimation and Tracking. arXiv 2024
估计放置的物体的位置及朝向。相较以往方法,准确度、稳定性都有很大提升,可以达到商用水平
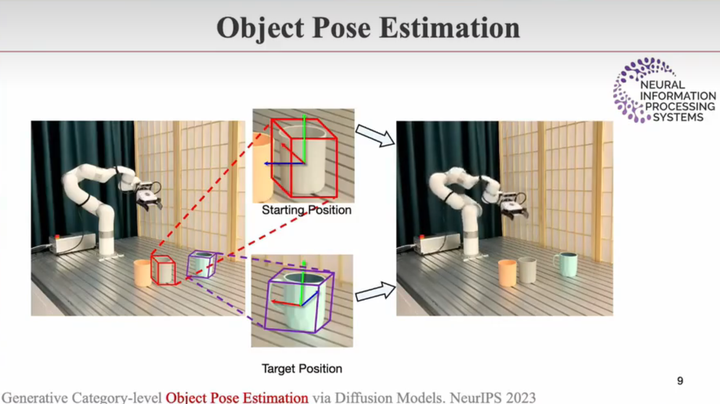

发布bechmark:

抓取+姿态估计,可以完成一些日常操作。如倒水、物体叠放、递东西:

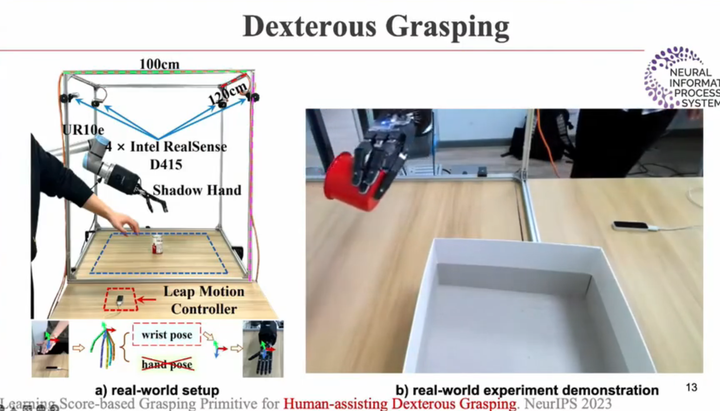
灵巧手抓取
Learning Score-based Grasping Primitive for Human-assisting Dexterous Grasping. NeurIPS 2023
灵巧手也可以通过仿真数据训练:
灵巧手手内预操作
UniDexFPM: Universal Dexterous Functional Pre-grasp Manipulation via Diffusion Policy. arXiv 2024
灵巧手和二指手、三指手,有什么本质区别? ——灵巧的手部,可以进行手内预操作。拿起时需要调整物体姿态,使得方便后续动作


使用前面姿态估计、抓取算法,只能预测出静态一瞬间,而不知道连续的动作。通过强化学习来做 比如下图,想提起这个沐浴露,两手夹住,一个手指按压。需要先将其在桌面旋转,使手可以抓到一个准确的位置 有自适应动作,如果一个物体没抓起来,会多次尝试,直到完成这个工作

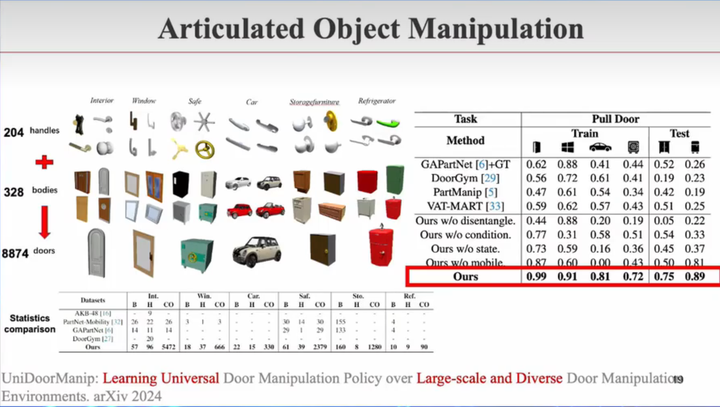
铰链
· VAT-Mart: Learning Visual Action Trajectory Proposals for Manipulating 3D Articulated Objects. ICLR 2022
· UniDoorManip: Learning Universal Door Manipulation Policy over Large-scale and Diverse Door Manipulation Environments. arXiv 2024
· RLAfford: End-to-End Affordance Learning for Robotic Manipulation. ICRA 2023
光有抓取还不够。生活中很多物体是铰链式的,比如柜门、抽屉 最简单的方法是写一个规则,识别把手,然后拉。但很多复杂情况,难以人为定义
像下图的方法,是抓着门边,一点一点地打开。这没有定义规则,是通过强化学习做的。越红的地方代表推该点成功率越高。多种推法,红色线代表成功率最高的方向:

开门不容易,要抓住、拧开,中间有很多步骤。在仿真中收集了很多不同的门把手和门,发现千级,就能做到一个较好的效果:

避障
Learning Environment-Aware Affordance for 3D Articulated Object Manipulation under Occlusions. NeurIPS 2023
在真实世界中,有障碍物,应该如何改变轨迹?

双臂协同
DualAfford: Learning Collaborative Visual Affordance for Dual-gripper Object Manipulation. ICLR 2023
研究双臂操作:比如盒子特别大,平稳地举起来或者旋转它,需要旋转它

交互感知
AdaAfford: Learning to Adapt Manipulation Affordance for 3D Articulated Objects via Few-shot Interactions. ECCV 2022
仿真做得最好的是视觉,画面、质感都可以仿真得很真实,也可以做大量数据增强 日常生活中很多对操作有用的信息,是不一定包括在视觉中的 例如,家里的厨房门没把手,如果要开的话,会先试一边。如果这一边不能开,就去开另一边。再例如,水龙头应该从左边开还是从右边开,顺时针还是顺时针。再例如,不同场景下的不同摩擦力也会影响机器人策略 这需要在现实世界中主动交互感知,是通过尝试才知道物理信息

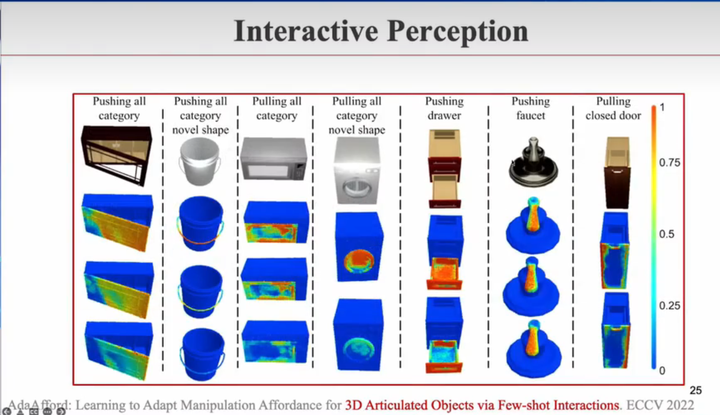
在仿真环境中训练好的模型,部署到现实世界中,应该持续学习改进
如下图,给4个杯子训练样本,它先像玩玩具一样去尝试、探索,如打开杯盖、提下杯把手发现其与杯身是连着的。最后给它没见过,但也属于该类的物品,它能正常交互
整个神经网络模型,会在真实世界部署后,通过这些尝试进一步学习、提升

柔性操作
DefoAfford: Learning Foresightful Dense Visual Affordance for Deformable Object Manipulation. ICCV 2023
柔性物体:将柔性物体抽象为抓取、放置,比如想将一块布摊平、将一根绳子摆为某个符号


基于强化学习,用了2000件衣服在仿真中学习,使得仅用一个模型,就能实现三大类任务,包括布料摊平、衣服折叠、衣物挂置
自动标定
Robot Structure Prior Guided Temporal Attention for Camera-to-Robot Pose Estimation from Image Sequence. CVPR 2023
去年特斯拉放过一个视频,机器人会首先看一下自己的手臂,它其实就是在做相机和机械臂的标定。然后才能更好控制机械臂,比如升到哪个坐标位置

去年董老师组开始研究,如何让AI进行实时自标定。并不需要机械臂中的传感器,而是通过外接相机,就能知道机械臂每一个关节的位姿及朝向
注意,机械臂在干活的时候,相机是可以摆放在随便位置的 过去是不可以的,之前标定完相机和机械臂的相对位置是不能变的,变化的话要重新标定。但现在的标定是自适应的,实时标定

简单的舵机臂:

以前工业机械臂是很高精度的,比如0.01mm的重复定位误差,那是因为是开环的控制,所以需要绝对的定位精度,手才能伸过去
但是有实时的自标定后,有学生在淘宝买零件,自己造了一个机械臂,臂展600mm,负载2kg,但缺点是用舵机做的,重复定位误差高达2cm,所以传统来看,这个机械臂是干不了活的
但是,有实时自标定后,可以进行实时闭环控制。比如如果手伸得过了,就缩回来一点,相当于实时地对机械臂进行调整。因此,这项技术使得,有很大误差的非高精度机械臂,依然可以完成一些精巧动作
大模型
ManipLLM: Embodied Multimodal Large Lanugage Model for Object-Centric Robotic Manipulation. CVPR 2024
仿真中训练的模型泛化性受限。例如,我在仿真里用很多杯子训练,然后在现实世界部署,告诉它我的杯子长得像一只青蛙,那模型还是不懂,因为仿真数据中没有一个青蛙杯子
而大模型具备举一反三能力的知识库(LLM见过互联网上大部分知识,知道长得像青蛙的杯子、长得像冬瓜的杯子)
将仿真的数据,注入到大模型后,部署到现实世界。部署到现实世界的是这个大模型。即使没见过青蛙杯子,但知道杯子怎么用,就可以使用青蛙杯子

询问LLM,应该在哪个点接触、哪个方向动作、以及旋转朝向


Planning
Instruct2Act: Mapping Multi-modality Instructions to Robotic Actions with Large Language Model. arXiv 2023 ManiVAQ: Injecting Robotic Affordance and Physically Grounded Information into Multi-Modal Large Language Models. arXiv 2024 Distilling Functional Rearrangement Priors from Large Models. arXiv 2024 TarGF: Learning Target Gradient Field to Rearrange Objects without Explicit Goal Specification. NeurIPS 2022
任务分解。大模型将任务拆解为若干个可执行的小任务,调用API完成
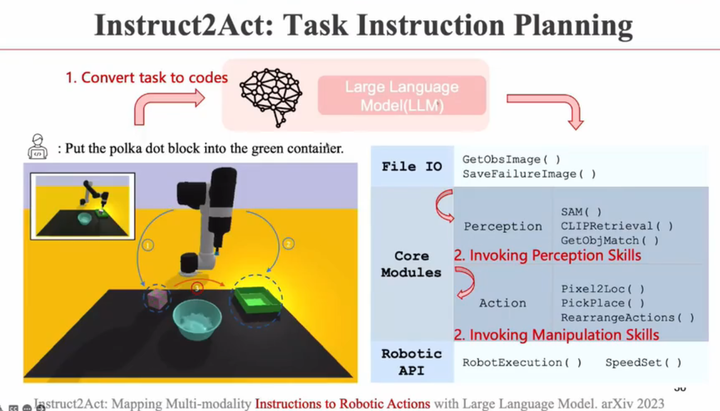

以上左图|将可乐放到篮子里。右图|将积木放到某个积木上,然后复原
今年董老师组希望做更细粒度的事情:比如对于锤子,应该操作把手 给LLM海量图像数据,LLM通过图像中的已有物体,自动生成其应该能执行的任务,反过来生成所需的训练数据。然后用这些数据微调LLM。最终使大模型具备跟机器人任务相关的问答能力
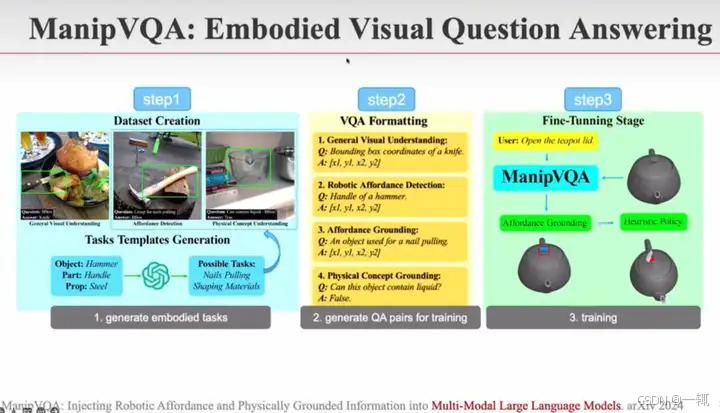
任务实验示例:

模糊描述任务,收纳:把桌面收拾干净一些吧,把餐桌摆成左撇子用的吧。 在网络上直接获取整洁的桌面是什么样子的,或者用AIGC生成。数千张样例图片,就学会了分布。下次就算遇到了从没遇到的桌面、从没遇到的物品,也知道如何摆放它,才能符合这几千张图片构成的样例分布,实现这种模糊难以定义的任务

添加图片注释,不超过 140 字(可选)
Navigation
导航有很多种范式。可以将其分为物体导航、视觉语言导航、需求驱动导航
物体导航
PixNav: Bridging Zero-shot Object Navigation and Foundation Models through Pixel-guided Navigation Skill. ICRA 2024
第一种是物体导航。比如想找个手机

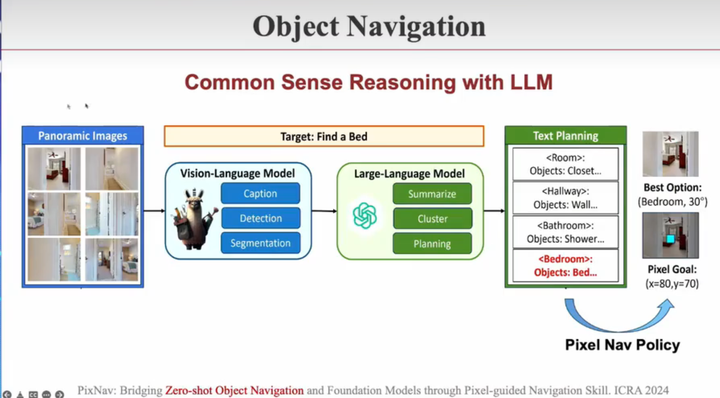
多模态视觉语言大模型感知理解任务,再用大语言模型完成规划任务,并且每一步预测出下一步该走到当前画面的哪个点。这样来实现物体导航
视觉语言导航
Discuss Before Moving: Visual Language Navigation via Multi-expert Discussions. ICRA 2024
另外一种导航范式:视觉-语言导航 跟随人类语言指令,比如出门右拐、直走、上楼 以往在数千个仿真房间中学,但往往效果很差,因为sim2real的gap太大,换一个相机型号就不行了,或者相机高低不同就效果相差很大 基于大模型,提出了一种多专家自问自答算法范式。一个专家将命令拆解,另一个专家理解方位,最后决策专家来下决定,应该往哪个方向走
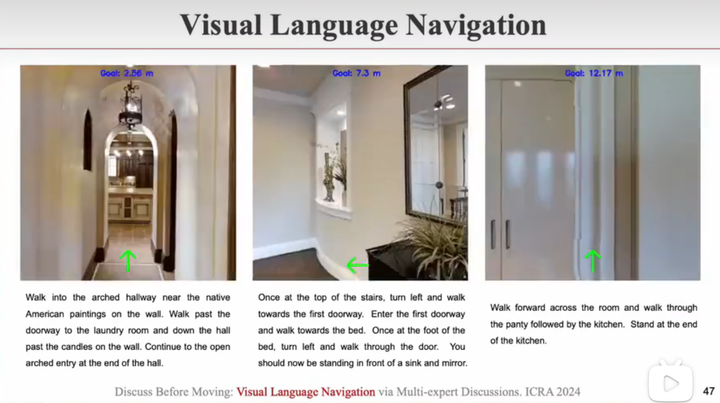

需求驱动导航
Find What You Want: Learning Demand-conditioned Object Attibute Spce for Demand-driven Navigation. NeurIPS 2023
另一种导航范式:需求驱动导航 跟他说我渴了,跑去找水,没找到水,就去找其它解渴的方式,比如说切个西瓜
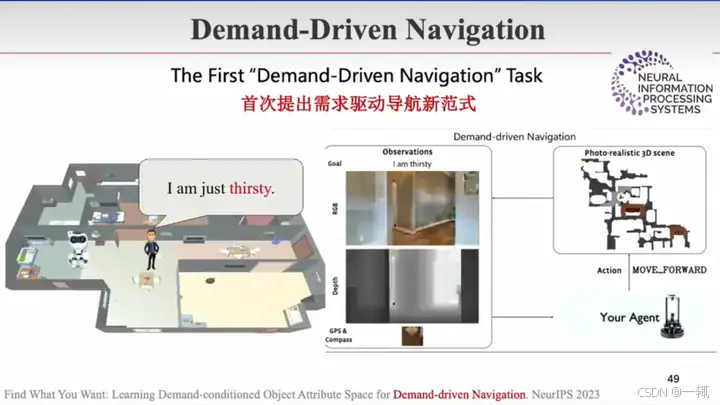
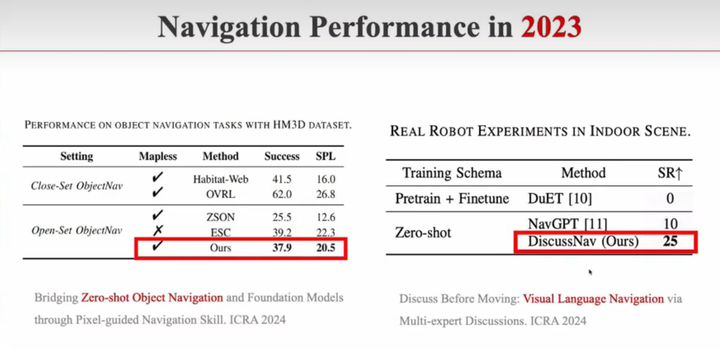
通用导航
InstructNav: Zero-shot System for Generic Instruction Navigation in Unexplored Environment. arXiv 2024
今年年初,董老师组提出了第一个通用指令导航大模型,把这些导航范式都cover: 完全没建图情况下,第一次来家里,第一次做某个任务

基本询问的问题,都能在这三种导航范式中被cover的
研究趋势
具身智能的研究主要集中为三块:导航Navigation、决策Decision、上肢能力Grasping&Manipulation
研究趋势:过去多用仿真,现在多用LLM(可缓解visual sim2real的gap、不需要额外大数据、提供任务编排能力),下一步趋势是使用真实数据(仿真中还是存在巨大physical gap) 需要在未来,把仿真、大模型、真实世界数据,多种数据范式融合,以形成通用具身智能


















 452
452

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









