






目录
三、find(以文件为单位进行查找后删除复制移动)
一、常见系统特殊符号
(一)基础符号系列
1)美元符号 $
1.用于取出变量中的内容
2.用于取出指定列的信息(awk)
3.表示用户命令提示符号
超级用户为 #
普通用户为 $2)叹号符号 !
1.用于表示取反或者排除意思
2.命令行中表示取出最近命令
!awk(慎用)
history|grep awk
3.用于表示强制操作处理
vim底行模式保存 退出 wq! q!3)竖线符号 |
1.表示管道符号,管道前面命令,交给管道后面执行
2.经常配合xargs命令使用
经常配合xargs命令使用
查找指定数据信息进行删除
find /test -type f -name "test*.txt"|xargs rm
find /test -type f -name "test*.txt" -exec rm -rf {} \;
find /test -type f -name "test*.txt" -delete
查找指定数据信息进行复制
find /test -type f -name "test*.txt" |xargs -i cp {} /test01/
find /test -type f -name "test*.txt" |xargs cp -t /test01/
find /test -type f -name "test*.txt" -exec cp -a {} /test01 \;
查找指定数据信息进行移动
find /test -type f -name "test*.txt" |xargs -i mv {} /test01/
find /test -type f -name "test*.txt" |xargs mv -t /test01/
find /test -type f -name "test*.txt" -exec mv {} /test01 \;
查找指定数据信息按照日期 --主要用于批量删除历史数据信息
查找7天以前的数据: find /test -type f -mtime +7
查找最近7天的数据: find /test -type f -mtime -7
查找距今第7天数据: find /test -type f -mtime 7
4)井号符号 #
1.表示文件内容注释符号
2.表示用户命令提示符号
超级用户为 #
普通用户为 $(二)引号符号系列
1.美元括号:
$()
表示命令执行结果留下,用于其他命令调用
2.引号符号:
双引号
""
表示输入内容,就是输出内容,但是部分信息会被解析
单引号
''
表示输入内容,就是输出内容(所见即所得)
反引号
``
表示命令执行结果留下,用于其他命令调用(三)定向符号系列
1.小于符号:
单个小于符号
<
标准输入重定向符号
两个小于符号
<<
标准输入追加重定向符号
2.大于符号:
单个大于符号
>/2>
标准输出重定向符号
错误输出重定向符号
两个大于符号
>>/2>>
标准输出追加重定向符号
错误输出追加重定向符号(四)路径符号系列
1.单点符号:
.
表示当前目录
2.双点符号:
..
表示上级目录
3.波浪符号
~
表示用户家目录信息
超级用户:/root
普通用户:/home/用户名称(五)逻辑符号系列
1.并且符号:
&&
表示前面的名称执行成功,再执行后面的命令
2.或者符号:
||
表示前面的名称执行失败,再执行后面的命令二、常见通配符号
作用说明:查找文件名称信息
使用场景:命令行经常使用
(一)通配符号作用
通配符号作用说明:方便匹配找出多个数据文件(按照文件名称进行匹配查找)
(二)通配符号企业应用
通配符号企业应用(wildcard)
1.星号:*
表示匹配所有内容信息
# 找出以什么结尾的文件信息
find /test -type f -name "*.txt"
# 找出以什么开头的文件信息
find /test -type f -name "test*"
2.花括号:{}
表示生成序列信息
# 生成连续数字序列
echo {01..10}
# 生成不连续数字序列
echo {01,03,05}
# 生成连续字母序列
echo {a..d}
# 生成不连续字母序列
echo {a,d,f,h}
表示生成组合序列
# 生成组合序列
echo A{A,B}
# 生成组合序列
echo {A,B}{C,D}
# 生成备份文件
cp oldboy.txt{,.bak}三、find(以文件为单位进行查找后删除复制移动)
find:查找符合条件的文件
01、精确查找:
find 路径信息 -type 文件类型 -name "文件名"
02、模糊查找:
find 路径信息 -type 文件类型 -name "文件名*"
find 路径信息 -type 文件类型 -name "*文件名"
find 路径信息 -type 文件类型 -name "文*件名"
03、忽略字符大小写查找:
find 路径信息 -type 文件类型 -iname "文件名*"
04、根据数据大小查找数据:
find /test -type f -size +100 --找出大于100k的文件
find /test -type f -size -100 --找出小于100k的文件
find /test -type f -size +1M --找出大于1M的文件
`b' for 512-byte blocks (this is the default if no suffix is used)
`c' for bytes (推荐)
`w' for two-byte words
`k' for Kilobytes (units of 1024 bytes) (推荐)
`M' for Megabytes (units of 1048576 bytes) (推荐)
`G' for Gigabytes (units of 1073741824 bytes)
05、根据目录指定层级进行查找数据(进行递归查找):
find /test -maxdepth 1 -type f -name "test*"
06、实际应用:
01. 如何找出/test/目录中.txt结尾的文件,将找出的文件进行统一删除
a find /test/ -maxdepth 1 -type f -name "*.txt" -delete
b find /test/ -type f -name "*.txt" -exec rm -rf {} \;
c find /test/ -type f -name "*.txt" | xargs rm -f
d rm -rf $(find /test -type f -name "*.txt")
e rm -f `find /test/ -type f -name "*.txt"`
02.如何找出/test/目录中.txt结尾的文件,将找出的文件进行批量复制/移动到/tmp目录中
find /test/ -maxdepth 1 -type f -name "*.txt" -exec cp {} /tmp \;
find /test/ -maxdepth 1 -type f -name "*.txt" | xargs cp /tmp ---xargs其作用是将查找内容一列变为1行
补充:
1.查找指定数据信息进行删除
01.find /test -type f -name "test*.txt"|xargs rm
02.find /test -type f -name "test*.txt" -exec rm -rf {} \;
03.find /test -type f -name "test*.txt" -delete
2.查找指定数据信息进行复制
01.find /test -type f -name "test*.txt"|xargs -i cp {} /test01/
02.find /test -type f -name "test*.txt"|xargs cp -t /test01/
03.find /test -type f -name "test*.txt" -exec cp -a {} /test01 \;
3.查找指定数据信息进行移动
01.find /test -type f -name "test*.txt"|xargs -i mv {} /test01/
02.find /test -type f -name "test*.txt"|xargs mv -t /test01/
03.find /test -type f -name "test*.txt" -exec mv {} /test01 \;
4.查找指定数据信息按照日期(主要用于批量删除历史数据信息)
01.查找7天以前的数据:find /test -type f -mtime +7
02.查找最近7天的数据:find /test -type f -mtime -7
03.查找距今第7天数据:find /test -type f -mtime 7
三、正则符号
作用说明:查找文件内容信息
使用场景:三剑客命令常用/各种语言经常使用
(一)正则符号作用说明
方便匹配找出文件中的内容信息
(二)正则表达符号分类
1.基础正则表达式(basic regular expression)
^ $ . * [] [^]
2.扩展正则表达式(extended regular expression)
| + () {} ?(三)正则符号注意事项
①. 按照每行信息进行过滤处理
②. 注意正则表达符号禁止中文
③. 附上颜色信息进行正则过滤
--color=auto/--color(四)基础正则符号说明
01.尖角符号:^
表示以什么字符开头的一行信息
02.美元符号:$
表示以什么字符结尾的一行信息
03.空行符号:^$
表示过滤空行信息
04.点号符号:.
表示匹配任意一个且只有一个字符
grep -o "." test.txt
-o:表示显示grep命令执行过程
05.星号符号:*
表示前一个字符出现0次或者多次
06.点星符号:.*
表示匹配文件中所有信息(包含空行)
^.*xxx
表示以任意字符开头xxx结尾(贪婪匹配)
^xxx.*xxx$
表示以xxx开头,xxx结尾的所有行
07.转移符号:\
表示还原字符的本来意思
'\.$'
表示查询出以点结尾的行信息
tr 源信息 替换后信息 <文件信息
表示对数据信息进行替换处理,采用一对一替换(sed命令的阉割版)
转移符号的常见用法汇总
\n
表示匹配一个换行符号
\r
表示匹配一个换行符号
\t
表示匹配一个制表符号
08.括号符号:[ ]
表示包含括号中信息的
[abc]
表示匹配包含a或b或c信息的字符
^[abc]
表示匹配包含a或b或c信息的字符开头的信息
[a-zA-Z0-9]
找出所有以小写字母大写字母和数字信息的字符
[a-Z]
找出所有以小写字母或大写字母组成字符(只能grep/egrep使用)
^[a-z].*[.!]$
表示以小写字母开头并且以点或叹号结尾的信息过滤出来
09.排除符号:[^]
表示排除括号中信息的
[^abc]
表示排除包含a或b或c信息的字符
^[^abc]
表示排除包含a或b或c信息的字符开头的行(不包含空行)(五)扩展正则符号说明
01.加号符号:+
表示前一个字符连续出现了1次或多次以上
egrep "0+" file
表示取出数字0字符,以及连续的多个数字0字符
egrep "[a-z]+" file
表示取出文件中的所有连续的小写字母(其实是取出单词信息)
补充总结说明
一般加号符号经常是与中括号使用,可以匹配出多个不同的连续字符
02.竖线符号:|
表示匹配多个满足条件的信息(或者)
03.括号符号:()
表示匹配一个整体信息
egrep “oldb(o|e)y" file
表示过滤指定整体信息
表示用于后项引用前项
sed -r 's#(.*)#<\1>#g'
利用sed命令实现后项引用前项
sed -r 's#([0-9]+)#<\1>#g'
利用sed命令实现后项引用前项
sed -r 's#(..)(...)(..)#<\1><\2>#g'
利用sed命令实现后项引用前项
04.括号符号:{}
表示定义前面字符出现次数
x{n,m}
表示前一个字符至少连续出现n次,最多出现m次
x{n}
表示前一个字符正好连续出现了n次
x{n,}
表示前一个字符至少连续出现n次,最多出现多少次不限
x{,m}
表示前一个字符至少连续出现0次,最多出现m次
05.问号符号:?
表示定义前面字符出现0次或1次
PS:扩展正则符号
默认grep sed 命令不能直接识别
grep 提升自己 egrep/grep -E
sed 提升自己 sed -r(六)正则符号使用问题
①. 问题:尖角符号和星号符号区别?
^d和d*
②. 问题:星号符号匹配不存在信息?
grep ''
③. 问题:过滤时是否使用引号区别?
egrep [ab]{1,} oldboy.txt(七)正则符号特性说明
①. 正则表达符号具有贪婪特性
②扩展正则转换 基础正则方法.
grep 'go\+d'五、grep(过滤筛选信息)
grep参数介绍
-A after 在什么后面
-B before 在什么前面
-C centre 在什么中间
-c 统计信息出现的次数
grep命令如何进行过滤
1.筛选出有test的信息
grep "test" test.txt --从test.txt文件中筛选出有test的信息
2.筛选出有test的信息,但要有test信息的上一行信息也显示
grep -B 1 "test" test.txt
3.筛选出有test的信息,但要有test信息的下一行信息也显示
grep -A 1 "test" test.txt
4.筛选出有test的信息,但要有test信息的上一行和下一行信息也显示
grep -C 1 "test" test.txt
5.统计test信息在文件中出现了几次
grep -c 1 "test" test.txt
六、sed(修改替换文件内容 擅长对文件中的行进行操作)
1)概念介绍
官方概念:字符流过滤编辑和文本字符流转换工具
功能应用说明:
01.处理文本信息
文本文件信息(小文件)
日志文件信息(grep awk分析)
配置文件信息(sed)
02.处理文件方式
增加信息
删除信息
修改信息
查找信息2)sed命令的执行流程
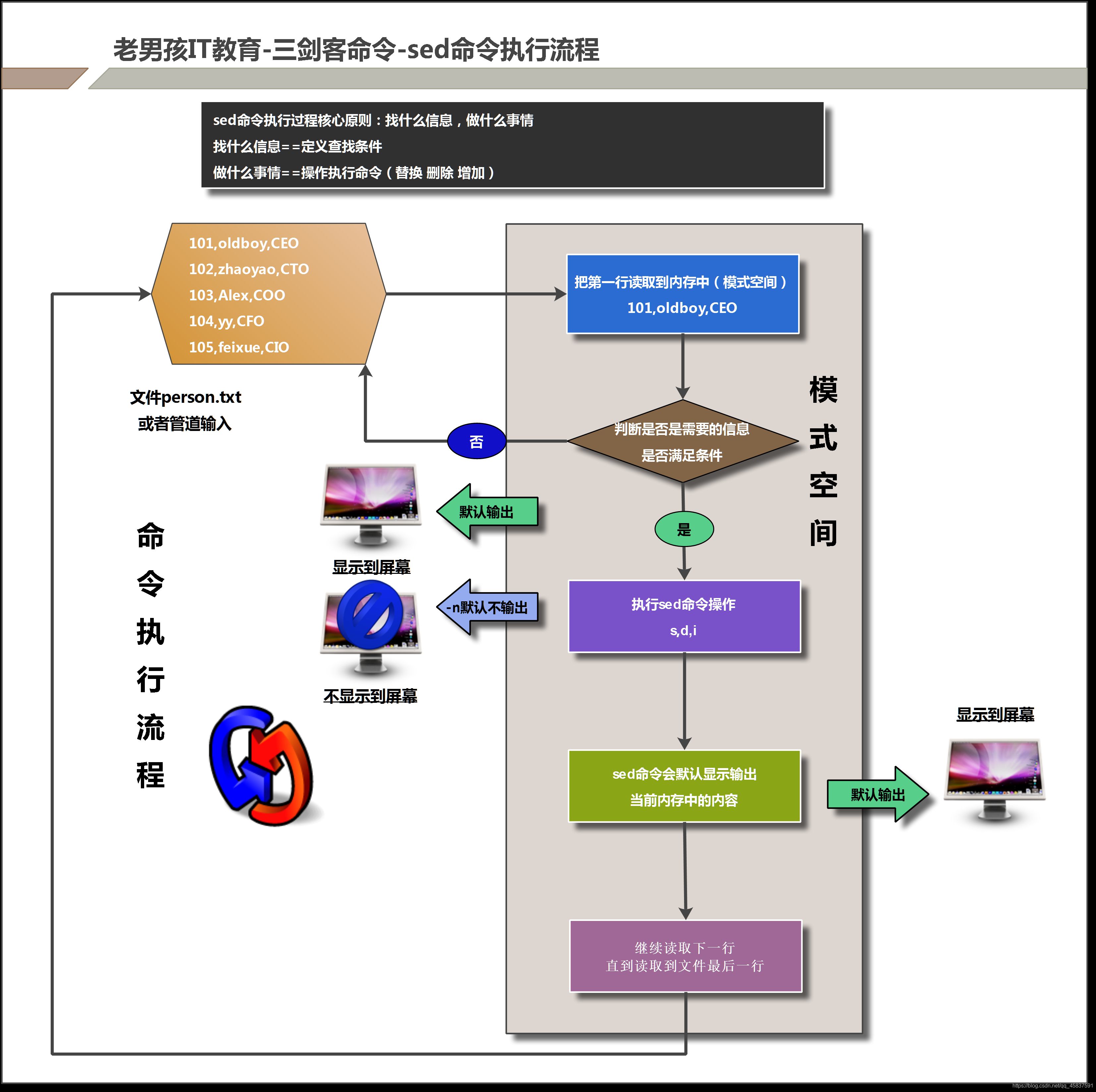
3)sed命令实际应用
命令语法格式:
标准格式:sed [选项] [sed指令] [文件信息]
举例说明:sed -i.bak 's#test#test01#g' test.txt
sed命令参数信息:
-n 取消默认输出
-r 识别扩展正则
-i 真实编辑文件(将内存中的信息覆盖到磁盘中)
-e 识别sed命令多个操作指令
sed命令指令信息:
p print 输出信息
i insert 插入信息,在指定信息前面插入新的信息
a append 附加信息,在指定信息后面附加新的信息
d delete 删除指定信息
s substitute 替换信息 s###g(全局替换)
c 替换修改指定的一整行信息
指令修饰:g
PS:相同指令信息只能使用一次,想使用多次需要加上分号
1.sed查询信息
#01.根据文件内容的行号查询
sed -n '3p' person.txt --显示单行信息
sed -n '1,3p' person.txt --显示1-3行信息(连续)
sed -n '1p;3p' person.txt --显示第1、第3共两行(不连续)
#02.根据内容信息输出单行内容
sed -n '/test/p' person.txt --将含有test的行显示出来
sed -n '/test/,/Alex/p' person.txt --显示包含test到Alex行之间的所有行信息(连续)
sed -n '/test/p;/Alex/p' person.txt --只显示包含test、Alex的行
2.sed命令增加信息(i:行前、a:行后)
sed '1iHelloworld' test.txt --在文件最前面增加一行Helloworld
sed '$abaibai' test.txt --在文件最后面增加一行baibai
sed '3afour' test.txt --在第三行后面增加一行four
sed '2itwo' test.txt --在第二行前面增加一行two
sed -e '/test/iqian' -e '/test/ahou' test.txt --在包含test行的前天增加一行qian,后面增加一行hou
sed '$a100\n101' test.txt --增加多行信息
企业中编写配置文件:
IPaddress=10.10.10.1
mask=255.255.255.0
gateway=10.10.10.254
sed '$aIPaddress=10.10.10.1\nmask=255.255.255.0\ngateway=10.10.10.254' 文件名称
3.sed命令删除信息
sed '3d' test.txt --删除第3行(单行)
sed '2,6d' test.txt --删除第2-6行(连续行)
sed '3d;6d' test.txt --删除第3行和第6行
如何利用sed命令取消空行显示?
sed -n '/./p' test.txt
sed '/^$/d' test.txt
sed -n '/^$/!p' test.txt
4.sed命令修改信息
vim 替换: :%s#one#two#g
sed 's#要修改的内容#修改后的内容#g' test.txt
sed 's#one#two#g'
sed 's/#one/two/g' test.txt
后项引用前项进行替换修改
sed 's#()#\n#g' test.txt
ip a s eth0|sed -rn '3s#^.*net(.*)/24.*#\1#gp' --取出IP地址
sed -i.bak 's#one#two#g' test.txt --修改文件内容并自动备份
PS:在真实替换文件内容时候,一定不能让n和i参数同时出现
ni和参数同时使用,会将文件内容进行清空
测验替换功能:
创建测试环境:
-rw-r--r-- 1 root root 0 Jun 7 19:43 test00.txt
-rw-r--r-- 1 root root 0 Jun 7 19:43 test01.txt
-rw-r--r-- 1 root root 0 Jun 7 19:43 test02.txt
-rw-r--r-- 1 root root 0 Jun 7 19:43 test03.txt
批量修改文件的扩展名称 将testxx.txt扩展名修改为testxx.jpg
ls test*.txt|sed -r 's#(.*)txt#mv & \1jpg#g'
mv test00.txt test00.jpg
mv test01.txt test01.jpg
mv test02.txt test02.jpg
mv test03.txt test03.jpg
批量重命名专业命令: rename
rename .txt .jpg test*.txt
命令 文件名称需要修改的部分信息 修改成什么信息 将什么样的文件进行修改
七、awk(擅长统计分析文件内容 擅长对文件中列进行操作)
1)概念介绍
处理文件信息:
1.文本文件信息
2.日志文件信息
3.配置文件信息
处理文件方式:
1. 排除信息
2. 查询信息
3. 统计信息
4. 替换信息
语法格式:
sed [参数] '条件-处理方式' 文件
awk [选项] '模式{动作}' [文件信息]
内置变量
FS:field separator -F ":" == BEGIN{FS=":"} == -vFS=":" 字段分隔符变量
NR:number records --表示行号信息
NF:number of fields --表示每一行有多少列(默认表示总列数)
2)awk命令执行过程
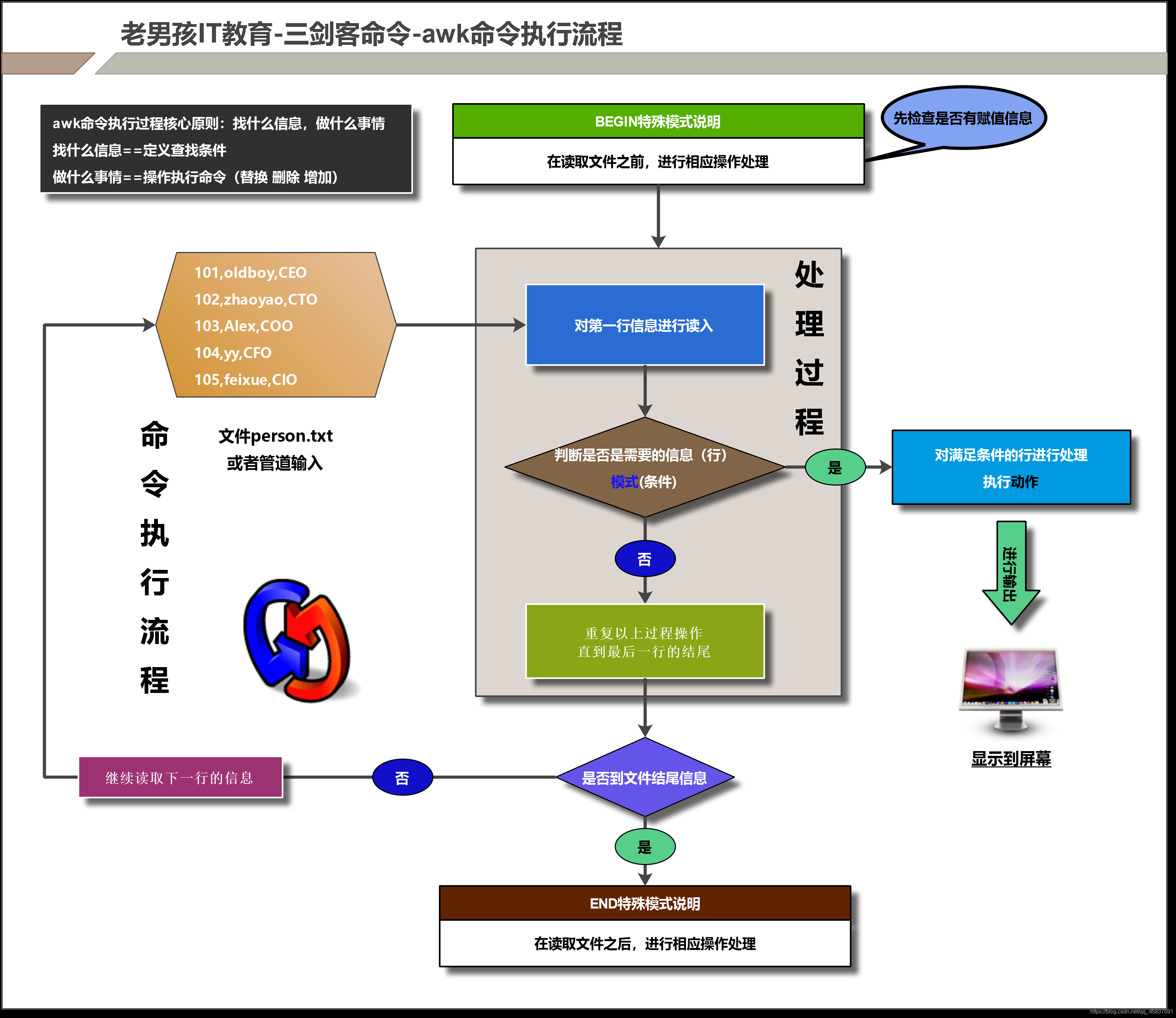
3)awk命令的实际应用
一、awk的实际操作过程
测试环境:
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
1.awk查询信息
#01.按照行号查询
awk 'NR==2' test.txt --显示第2行信息
awk 'NR==2,NR==4' test.txt --显示第2-4行信息
awk 'NR==2;NR==4' test.txt --显示第2行和第4行信息
PS:在linux中
test=10 --赋值变量信息
test==10 --test等于10
#02.按照字符查询
awk '/one/' test.txt --显示含有字符one的行
awk '/one/,/three/' test.txt --显示含有字符one的行到含有three字符的行之间的所有行
awk '/one/;/three/' test.txt --显示含有字符one的行和含有字符three字符的行
显示xiaoyu的姓氏和ID号码
awk '/Xiaoyu/{print $1,$3}' test.txt
姓氏是zhang的人,显示他的第二次捐款金额及他的名字
awk '/Zhang/{print $NF}' test.txt|awk -F ":" '{print $3}' -F:指定分隔符
awk -F ":" '/^Zhang/{print $3}' test.txt
awk -F "[ :]+" '/^Zhang/{print $1,$2,$(NF-1)}' test.txt --以空格和冒号为分隔符
#03.显示所有以41开头的ID号码的人的全名和ID号码
awk '$3~/^41/{print $1,$2,$3}' test.txt --找出第三列以41开头的所有行,输出该行的1,2,3列信息
#04. 显示所有ID号码最后一位数字是1或5的人的全名
方法一:
awk '$3~/1$|5$/{print $1,$2}' test.txt|column -t ##column -t 以表格形式显示(整齐)
方法二:
awk '$3~/[15]$/{print $1,$2}' awk_test.txt|column -t
方法三:
awk '$3~/(1|5)$/{print $1,$2}' awk_test.txt|column -t
05. 显示Xiaoyu的捐款,每个捐款数值前面都有以$开头, 如$110$220$330
#gsub(/需要替换的信息/,"修改成什么信息",将哪列信息进行修改)
awk '$2~/Xiaoyu/{gsub(/:/,"$",$NF);print $NF}' test.txt --找出第4列含有Xiaoyu的所有行,将最后一列的分隔符:替换为$并输出最后一列
文件中空行进行排除/文件中注释信息进行排除
grep -Ev "^#|^$" 文件信息
sed -n '/^#|^$/!p' 文件信息
awk '/^#|^$/' 文件信息
如何利用awk取出IP地址信息:
ip a s eth0|awk -F "[ /]+" 'NR==3{print $6}' --将以连续空格或/为分隔符,取出第3行的第6列
hostname -i
二、awk高级功能说明
普通的模式:
01. 正则表达式作为模式
awk '/^oldboy/{print xx}'
02. 利用比较匹配信息
NR==2
NR>=2
NR<=2
03. NR==2,NR==10
特殊的模式
01.BEGIN{} 在awk执行命令前做什么事情:
awk 'BEGIN{print "姓","名","QQ号","捐款记录"}{print $0}' test.txt |column -t
姓 名 QQ号 捐款记录
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
...
修改内置分隔符变量
awk -F ":" '{print $2}' test.txt
awk 'BEGIN{FS=":"}{print $2}' test.txt
02.END{} 在awk执行命令结束之后做的操作
awk 'BEGIN{print "姓","名","QQ号","捐款记录"}{print $0}END{print "操作结束"}' test.txt |column -t
姓 名 QQ号 捐款记录
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
...
操作结束
统计累加运算测试:
01. 统计/etc/services文件中空行数量
利用awk公式进行累加运算
awk '/^$/{i=i+1;print i}' /etc/services
awk '/^$/{i=i+1}END{print i}' /etc/services --输出最终多少行
02. 统计/etc/services文件中有井号开头的行
awk '/^#/{i++}END{print i}' /etc/services
03. 统计系统中有多少个虚拟用户 普通用户
第一个历程: 用户信息都保存在什么文件中了
用户信息保存文件: /etc/passwd
第二个历程: 从文件中匹配出虚拟用户 普通用户
匹配普通用户
awk '$NF~/bash/' /etc/passwd
awk '$NF~/\/bin\/bash/' /etc/passwd
第三个历程: 进行统计
普通用户数量
awk '$NF~/bash/{i=i+1}END{print i}' /etc/passwd --统计最后一列含有bash的所有行
63
虚拟用户数量
awk '$NF!~/bash/{i=i+1}END{print i}' /etc/passwd --统计最后一列不含bash的所有行
22
求和运算:
sum=sum+$n(需要进行数值求和的列)
seq 10|awk '{sum=sum+$1;print sum}'
总结:awk命令中$符号用法
$1 $2 $3 : 取第几列信息
$NF : 取最后一列
$(NF-n) : 取倒数第几列
$0 : 取所有列的信息三剑客命令
老三: grep 过滤筛选信息
老二: sed 修改替换文件内容 擅长对文件中的行进行操作
老大: awk 擅长统计分析文件内容 擅长对文件中列进行操作

















 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









