









学习自:http://t.csdnimg.cn/mga1j
【深入浅出Self-Attention自注意力机制与Transformer模块-自注意力机制详解】https://www.bilibili.com/video/BV1Rm411S7ML?vd_source=da2cf0642d93108949f85aeccf95736a

用于将一组实数转换为概率分布 softmax函数对向量中的每个元素进行指数运算,然后将得到的值除以所有元素指数之和,以确保最终的概率值之和为1
1.计算向量z的指数:通过np.exp(z)将向量z的每个元素取指数,并得到一个新的向量t。 2。计算指数之和:通过np.sum(t, axis=-1)对向量t进行按行求和,得到一个一维向量。np.sum(t, axis=-1)对数组t按照最后一个维度进行求和,得到一个一维数组。 np.expand_dims函数在这个一维数组的最后一个位置插入一个新的维度(-1),使其变成一个二维数组。这样做的目的是为了与分子的分母长度一致,以便在之后的除法操作中进行相除。 3.计算softmax概率:通过将向量t除以指数之和的结果,即np.exp(z) / np.expand_dims(np.sum(t, axis=-1), -1),得到最终的softmax概率向量a。
def soft_max(z):
t = np.exp(z)
a = np.exp(z) / np.expand_dims(np.sum(t, axis=-1), -1)
return a
# attention demo
print("attention demo")
Query = np.array([
[1,0,2],
[2,2,2],
[2,1,3]
])
Key = np.array([
[0,1,1],
[4,4,0],
[2,3,1]
])
Value = np.array([
[1,2,3],
[2,8,0],
[2,6,3]
])
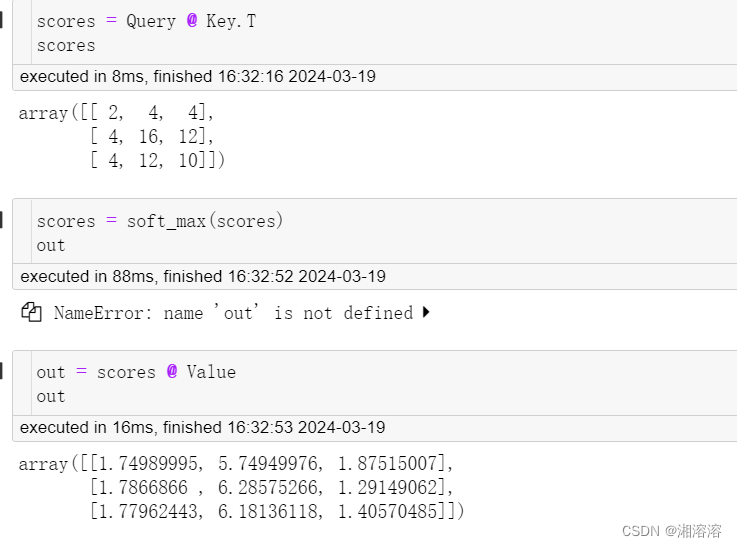
scores = Query @ Key.T
print(scores)
scores = soft_max(scores)
print(scores)
out = scores @ Value
print(out)
Multi-Head多头注意力机制
12头
(3,768)-》(3,12,64){最后一个维度拆分}
-》(12,3,64){维度调换 12头最为batchsize}
-》【QK】(12,3,3){Q维度364 K维度643}
-》【scoresv】(12,3,64){scores维度33 V维度364}
-》(3,12,64) {调换维度}
-》(3,768){还原}

values_length = 3
num_attention_heads = 8
hidden_size = 768
attention_head_size = hidden_size // num_attention_heads
Query = np.random.rand(values_length, hidden_size)
Key = np.random.rand(values_length, hidden_size)
Value = np.random.rand(values_length, hidden_size)
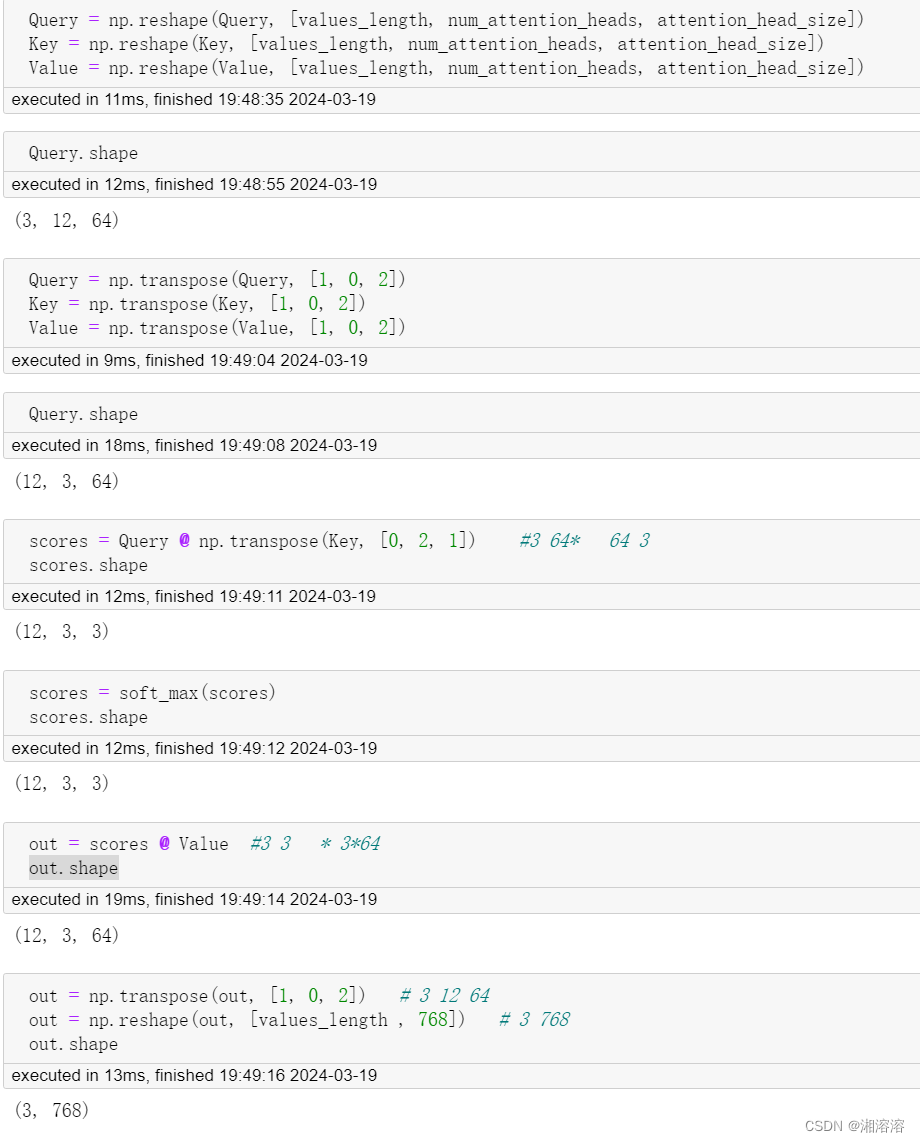
Query = np.reshape(Query, [values_length, num_attention_heads, attention_head_size])
Key = np.reshape(Key, [values_length, num_attention_heads, attention_head_size])
Value = np.reshape(Value, [values_length, num_attention_heads, attention_head_size])
Query = np.transpose(Query, [1, 0, 2])
Key = np.transpose(Key, [1, 0, 2])
Value = np.transpose(Value, [1, 0, 2])
scores = Query @ np.transpose(Key, [0, 2, 1])
print(np.shape(scores))
scores = soft_max(scores)
print(np.shape(scores))
out = scores @ Value
print(np.shape(out))
out = np.transpose(out, [1, 0, 2])
print(np.shape(out))
out = np.reshape(out, [values_length , 768])
print(np.shape(out))
Self-Attention机制中全局感知
在Self-Attention机制中,模型在处理输入序列时,每个输出都会考虑到输入序列中的所有元素。这意味着每个元素在生成输出时都会参考整个序列,从而实现了对全局信息的感知。
Self-Attention通过计算序列中每个元素与其他所有元素之间的关联权重来实现这一点。这些权重表明了序列中各个元素对当前元素的重要性。然后,模型会根据这些权重对输入序列进行加权求和,生成考虑了全局信息的输出。
Self-Attention机制能够捕捉序列中长距离的依赖关系,这对于处理自然语言等序列数据非常重要,因为语言中的词汇往往与距离较远的其他词汇有着密切的关联。这种全局感知能力是Self-Attention在自然语言处理和其他领域应用广泛的重要原因之一。















 478
478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









