






xinxinzhang
每个单元的介绍:
一、add&norm
(1).norm(层正则化):
原文:http://blog.csdn.net/zhangjunhit/article/details/53169308
本文主要是针对 batch normalization 存在的问题 提出了 Layer Normalization 进行改进的。
这里首先来回顾一下 batch normalization :
对于前馈神经网络第 l 隐层,神经元的输入为 a, 激活函数为 f, 激活函数输出为 h。权值 w 通过 SGD学习得到。 如下面的公式所示:
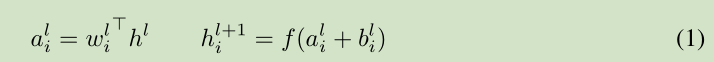
深度学习中的一个挑战就是对于上面公式中 一层的权值 w 的梯度 高度依赖于前一层神经元的输出,特别是当这些输出的改变高度相关的时候。(梯度容易受样本数据的影响,导致权值难以快速的收敛,一会向东,一会向西,走来走去,走了半天也没走多少路啊,这样走到全局最优值要走到哪天。这个问题有个名字,叫 covariate shift)。 针对此问题 [Ioffe and Szegedy, 2015] 提出了 Batch normalization 来降低这个 covariate shift 的影响。对于每个隐层的神经元,我们在所有的训练样本上归一化该神经元的输入。
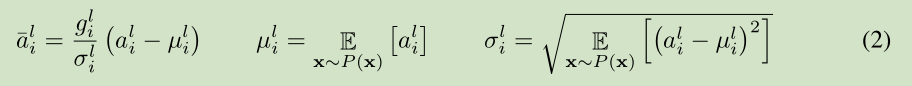
在整个训练样本上计算均值方差,然后对神经元的输入进行归一化。由于对整个训练样本计算均值方差不太有效率(对于训练来说),所以提出了 在最小训练批次上估计 均值方差。 current mini-batch 。 这个约束导致Batch normalization 难以应用于 recurrent neural networks。
3 Layer normalization
针对前面提到的 Batch normalization 的问题,我们提出了 Layer normalization。
注意到一层输出的改变会产生下一层输入的高相关性改变,特别是当使用 ReLU,其输出改变很大。那么我们可以通过固定一层神经元的输入均值和方差来降低 covariate shift 的影响。
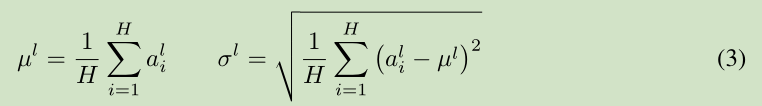
上面公式中 H 是 一层神经元的个数。这里一层网络 共享一个均值和方差,不同训练样本对应不同的均值和方差,这是和 Batch normalization 的最大区别。
Layer normalization 对于recurrent neural networks 的帮助最大。
Layer normalization 对于 Convolutional Networks 作用不是很大,后续研究可以提高其作用。
训练速度快。LayerNorm是Batch Normalization的一个变体,简要对比下BN与LN:LN是本次输入模型的一组样本做进行Normalization,BN是对一个batch数据进行Normalization。因此,LN可以用于RNN规范化操作,但BN不行。
(2):残差连接;
原文:http://www.jianshu.com/p/e58437f39f65
作者:AlanMa 链接:http://www.jianshu.com/p/e58437f39f65 來源:简书 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。网络的深度为什么重要?
因为CNN能够提取low/mid/high-level的特征,网络的层数越多,意味着能够提取到不同level的特征越丰富。并且,越深的网络提取的特征越抽象,越具有语义信息。
为什么不能简单地增加网络层数?
- 对于原来的网络,如果简单地增加深度,会导致梯度弥散或梯度爆炸。
对于该问题的解决方法是正则化初始化和中间的正则化层(Batch Normalization),这样的话可以训练几十层的网络。
- 虽然通过上述方法能够训练了,但是又会出现另一个问题,就是退化问题,网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。 退化问题说明了深度网络不能很简单地被很好地优化。 作者通过实验:通过浅层网络+ y=x 等同映射构造深层模型,结果深层模型并没有比浅层网络有等同或更低的错误率,推断退化问题可能是因为深层的网络并不是那么好训练,也就是求解器很难去利用多层网络拟合同等函数。
怎么解决退化问题?
深度残差网络。如果深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。 但是直接让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难,这可能就是深层网络难以训练的原因。但是,如果把网络设计为H(x) = F(x) + x,如下图。我们可以转换为学习一个残差函数F(x) = H(x) - x. 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。

其他的参考解释
- F是求和前网络映射,H是从输入到求和后的网络映射。比如把5映射到5.1,那么引入残差前是F'(5)=5.1,引入残差后是H(5)=5.1, H(5)=F(5)+5, F(5)=0.1。这里的F'和F都表示网络参数映射,引入残差后的映射对输出的变化更敏感。比如s输出从5.1变到5.2,映射F'的输出增加了1/51=2%,而对于残差结构输出从5.1到5.2,映射F是从0.1到0.2,增加了100%。明显后者输出变化对权重的调整作用更大,所以效果更好。残差的思想都是去掉相同的主体部分,从而突出微小的变化,看到残差网络我第一反应就是差分放大器...地址
- 至于为何shortcut的输入时X,而不是X/2或是其他形式。kaiming大神的另一篇文章[2]中探讨了这个问题,对以下6种结构的残差结构进行实验比较,shortcut是X/2的就是第二种,结果发现还是第一种效果好啊(摊手)。
引入了残差,尽可能保留原始输入x的信息。
(3)结构中逐项的feed-forward网络作用
Attention的sublayer之间嵌入一个FFN层,两个线性变换组成:FFN(x)=max(0,x*W1 + b1)W2 + b2。同层拥有相同的参数,不同层之间拥有不同的参数。目的应该是提高模型特征抽取的能力,考虑到效率,选择两个线性变换。
(4)Position Encoding(位置编码)
网模型的输入embedding中添加position embedding,使网络可以获得输入序列的位置(positions)之间的一个相对或者绝对位置信息。Position embedding有很多种方式获得,比如采用像word2vec方式训练。本文采用较简单的方式,基于正弦和余弦函数,根据位置pos和维度i来计算:
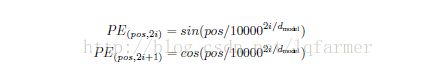
这样做的目的是因为正弦和余弦函数具有周期性,对于固定长度偏差k(类似于周期),post +k位置的PE可以表示成关于pos位置PE的一个线性变化(存在线性关系),这样可以方便模型学习词与词之间的一个相对位置关系。
(5).核心:多头注意力机制:
原文:https://zhuanlan.zhihu.com/p/27469958?refer=xitucheng10
http://blog.csdn.net/mijiaoxiaosan/article/details/73251443
在这篇文章当中有一个对Attention很好的描述,即attention机制实际上来讲是一个由诸多Query和Key-value pair组成的映射函数,即
<img src="https://pic3.zhimg.com/v2-dbadd19b49b92c5770330d9ab3a77342_b.png" data-rawwidth="514" data-rawheight="102" class="origin_image zh-lightbox-thumb" width="514" data-original="https://pic3.zhimg.com/v2-dbadd19b49b92c5770330d9ab3a77342_r.png">
上式被作者们称为Scaled Dot-Product Attention. 在这里面\sqrt{d_k} 是用来约束点积大小的。因为作者认为当query和key的维度很大时,点击倾向于变得比较大,因而上述因子做约束,但是这个因子是如何确定的文中并没有做具体的交待。
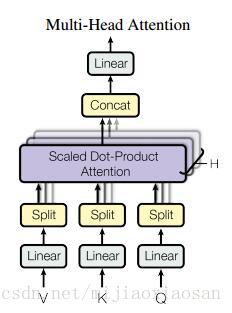
本文中的self-attention的整体结构是以上图中的multi-head attention实现的。所谓的multi-head(多抽头?)在文中实际上就是对query和key进行多次线性映射,然后讲结果串联起来,从这一点上来看有一种浓浓的CNN既视感。
<img src="https://pic1.zhimg.com/v2-56b798bfca2b62e18e8985c57d706f8c_b.png" data-rawwidth="892" data-rawheight="478" class="origin_image zh-lightbox-thumb" width="892" data-original="https://pic1.zhimg.com/v2-56b798bfca2b62e18e8985c57d706f8c_r.png">
具体来讲,在encoder-decoder中,query来自之前上一层decoder,而key和value则是上一层encoder的输出。这种机制使得句子中的每一个Part都可以参与encoder-decoder的过程。而在self attention中,query,key和value都来自相同的上一步的输出。
多头的attention (Multi-Head Attention)
这个应该是本文最核心的部分。本文结构中的Attention并不是简简单单将一个点乘的attention应用进去。作者发现先对queries,keys以及values进行
h
次不同的线性映射效果特别好。学习到的线性映射分别映射到
dk
,
dk
以及
dv
维。分别对每一个映射之后的得到的queries,keys以及values进行attention函数的并行操作,生成
dv
维的output值。具体操作细节如以下公式。
这里映射的参数矩阵, WiQ∈Rdmodel∗dk , WiK∈Rdmodel∗dk , WiV∈Rdmodel∗dv 。
本文中对并行的attention层(或者成为头)使用了 h=8 的设定。其中每层都设置为 dk=dv=dmodel/h=64 . 由于每个头都减少了维度,所以总的计算代价和在所有维度下单头的attention是差不多的。
把这些attention头的output拼接起来作为最终值,就像下图中multihead attention结构示意图所描述的一样。
在本模型中如何使用attention
本文提出的模型Transformer以三种不同的方式使用了多头attention。
1. 在encoder-decoder的attention层,queries来自于之前的decoder层,而keys和values都来自于encoder的输出。这个类似于很多已经提出的seq-to-seq模型所使用的attention机制。
2. 在encoder含有self-attention层。在一个self-attention层中,所有的keys, values以及queries都来自于同一个地方,本例中即encoder之前一层的的输出。
3. 类似的,decoder中的self-attention层也是一样。不同的是在scaled点乘attention操作中加了一个mask的操作(设置为负无穷),这个操作是保证softmax操作之后不会将非法的values连到attention中(个人理解,比如你这一位置queryattention的values不能有这一位置之后的values的信息,只能有该位置前面的values,本人菜鸟欢迎拍砖)。
之前说模型由堆叠在一起的六个层组成,每层由两个支层,attention层就是其中一个,而attention之后的另一个支层就是一个前馈的网络。公式描述如下。
该网络是两个线性变换,中间加了一个ReLU激活函数。每个位置(position)上的线性变换是一样的,但是不同层与层的参数是不一样的。该网络的输入和输出维度都是 dmodel ,不过中间层的维度是2048.
模型的整体框架基本介绍完了,其最重要的创新应该就是Self-Attention的使用级联的多头attention架构。
作者在文中深入讨论了为什么选择使用self attention这一结构。主要从三个方面来谈。第一是每层的总计算复杂性,其次是能并行计算的数量,这点论文用所要求的序列操作的最小值来量化。第三点是针对网络长距离依赖的路径长度。为了提升在长序列上的计算性能,self-attention应该改被限制(restrict)在一个size大小为 r 的邻域内,这样可以将最大路径长度增加到 O(n/r) ,至于具体如何去做作者说在未来工作中会研究。
二:模型整体解析:
模型架构
大多数性能较好的神经序列转导模型都使用了编码器-解码器的结构。Transformer 也借鉴了这一点,并且在编码器-解码器上使用了全连接层。
1.编码器:由 6 个完全相同的层堆叠而成,每个层有 2 个子层。在每个子层后面会跟一个残差连接和层正则化(layer normalization)。第一部分由一个多头(multi-head)自注意力机制,第二部分则是一个位置敏感的全连接前馈网络。
2.解码器:解码器也由 6 个完全相同的层堆叠而成,不同的是这里每层有 3 个子层,第 3 个子层负责处理编码器输出的多头注意力机制。解码器的子层后面也跟了残差连接和层正则化。解码器的自注意力子层也做了相应修改。
3.模型输入。
编码器和解码器的输入就是利用学习好的embeddings将tokens(一般应该是词或者字符)转化为
dmodel
维向量。对解码器来说,利用线性变换以及softmax函数将解码的输出转化为一个预测下一个token的概率。
4.
Encoder端:输入的Embedding,与Positional Embedding(后面会给出positional embedding的计算方法)相加,做为堆叠N(N=6)个完全相同的Layer层的输入。每一个Layer层由Multi-Head attention部分和一个FeedFoward部分组成,两个部分直接通过一个Add & Norm的方式连接。为了加速,模型中所有子层的输出dimension = 512。
Decoder端:decoder也是由N(N=6)个完全相同的Layer组成,decoder中的Layer由encoder的Layer中插入一个Multi-Head Attention + Add&Norm组成。输出的embedding与输出的position embedding求和做为decoder的输入,经过一个Multi-Head Attention + Add&Norm((MA-1)层,MA-1层的输出做为下一Multi-Head Attention + Add&Norm(MA-2)的query(Q)输入,MA-2层的Key和Value输入(从图中看,应该是encoder中第i(i = 1,2,3,4,5,6)层的输出对于decoder中第i(i = 1,2,3,4,5,6)层的输入)。MA-2层的输出输入到一个前馈层(FF),经过AN操作后,经过一个线性+softmax变换得到最后目标输出的概率。
三.Attention机制作用分析
1)、插入decoder的中间层的MAAN结构输入:query来源于output的decoder层输出,memory的keys和values来源于对于的encoder的输出,充当权重。这一操作使得decoder可以获取输入X整个序列的信息,类似于传统Seq2Seq中的decoder端的attention机制。
2)、encoder端包含self-attention layers。当前self-attention的输入k、v,q来源于前一层的输出,encoder中每一个position可以关联前一层所有positions,可以全面获取输入序列X中positions之间依赖关系。对包含self-attention的decoder端也一样。
3)、相比基于CNN和RNN的Seq2Seq模型,基于Self-Attention的Seq2Seq模型计算效率更高,单层计算复杂度更低,学习long-range dependencies的能力更强,三种类型的Seq2Seq模型对比如下表所示:

最重要的是,基于Self-Attention的Seq2Seq网络学习long-range dependencies能力很强。Seq2Seq中的一个关键问题是如何学习sequence中的词与词之间的long-range dependencies关系。在双向LSTM(BLSTM),我们通常分正向和反向分别计算一次Sequence的信息,其中,学习long-range dependencies关键的一点是信号在网络正向和反向计算中传递的Path长度(计算次数),计算次数越多,较远的依赖关系消失情况越严重。在Self-Attention结构中,每一层都直接与前一层的所有position直接连接,因此Path的长度为O(1),最大程度保留了sequence中词与词之间的依赖关系。针对长句子,为了提高计算效率,只考虑某一个词前后r个词时,Path的路径最长长度任然只有O(n/r),其中,n为sequence长度。
参考:http://blog.csdn.net/lqfarmer/article/details/73521811















 987
987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









