







大家好,我是带我去滑雪!
神经网络投照是否存在反锁与记忆可以分为静态神经网络与动态神经网络。动态神经网络是指神经网络带有反做与记忆功能,无论是局部反馈还是全局反锁。通过反馈与记忆,神经网络能将前一时刻的数据保留,使其加人到下一时刻数据的计算,使网络不仅具有动态性而且保留的系统信息也更加完整。动态神经网络有许多应用,例如,金融分析师用于分析某只股票、基金或者其他金融工具未来某时点的价格,工程师用于预测最近一次可能的飞机引擎故障时间等,可见动态神经网络在分析、仿真、系统监测与控制等领域有重要应用。根据动态神经网络实现系统动态的方法不同,将之分为两类:一类是回归神经网络,它是由静态神经元和网络输出反馈构成的动态网络,典型的有 NARX 回归神经网络;另一类是通过神经元反馈形成,的神经网络,如全回归神经网络、Elman 神经网络、PID神经网络等等。本期将动态网络应用于时间序列的预测中,实现通过 NARX 动态神经网络对时问序列数据的建模仿真及效果评价。
目录
一、问题描述与模型建立
(1)问题描述
中和反应是化学反应中复分解反应的一种,是指酸和破互相交换组分、生成盐和水的反应,在中和的过程中,酸里的氢离子和碱中的氢氧根离子会结合成水。中和反应发生后最终产物的PH 值不一定是7。如果一强酸与强破参与中和反应,其产物的PH则会是7。如强酸盐酸和强碱氢氧化钠发生中和反应,产生氣化钠和水。本案例使用 MATLAB 自带案例数据,即给定两个酸碱溶液的流速来预测和反应过程后溶液的PH值。
(2)模型建立
数据使用两个含有2001 个监测点的时间序列数据。其中 PhInputs 为一个1×2001维的cell,代表了2001 个监测时间点酸碱溶液的流速。PhTargets 为 1×2001 维的cell,代表中和反应后溶液的pH 值。本研究的目的就是通过当前的酸碱溶液流速预测中和反应后溶液的pH 值大小。
二、代码实现与结果分析
(1)建立非线性自回归模型
load phdata
inputSeries = phInputs;
targetSeries = phTargets;
%% 建立非线性自回归模型
inputDelays = 1:2;
feedbackDelays = 1:2;
hiddenLayerSize = 10;
net = narxnet(inputDelays,feedbackDelays,hiddenLayerSize);
(2)数据准备工作
net.inputs{1}.processFcns = {'removeconstantrows','mapminmax'};
net.inputs{2}.processFcns = {'removeconstantrows','mapminmax'};
%% 时间序列数据准备工作
[inputs,inputStates,layerStates,targets] = preparets(net,inputSeries,{},targetSeries);
%% 训练数据、验证数据、测试数据划分
net.divideFcn = 'dividerand';
net.divideMode = 'value';
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;
(3)训练函数、误差函数、绘图函数确定
net.trainFcn = 'trainlm'; % Levenberg-Marquardt
net.performFcn = 'mse'; % Mean squared error
net.plotFcns = {'plotperform','plottrainstate','plotresponse', ...
'ploterrcorr', 'plotinerrcorr'};
[net,tr] = train(net,inputs,targets,inputStates,layerStates);
outputs = net(inputs,inputStates,layerStates);
errors = gsubtract(targets,outputs);
performance = perform(net,targets,outputs)
trainTargets = gmultiply(targets,tr.trainMask);
valTargets = gmultiply(targets,tr.valMask);
testTargets = gmultiply(targets,tr.testMask);
trainPerformance = perform(net,trainTargets,outputs)
valPerformance = perform(net,valTargets,outputs)
testPerformance = perform(net,testTargets,outputs)
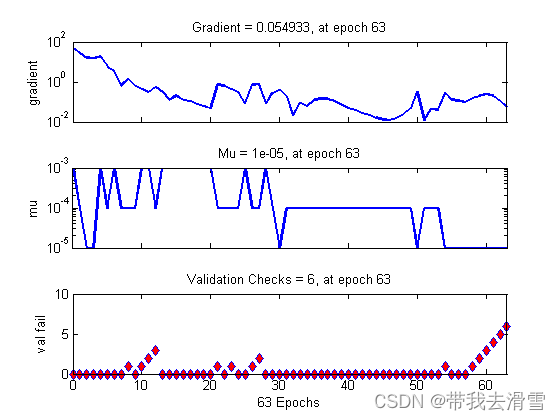
figure, plotperform(tr)
figure, plottrainstate(tr)
figure, plotregression(targets,outputs)
figure, plotresponse(targets,outputs)
figure, ploterrcorr(errors)
figure, plotinerrcorr(inputs,errors)(3)NARX神经网络模型
narx_net_closed = closeloop(net);
view(net)
view(narx_net_closed)
phInputs_c=phInputs(1500:2000);
PhTargets_c=phTargets(1500:2000);
[p1,Pi1,Ai1,t1] = preparets(narx_net_closed,phInputs_c,{},PhTargets_c);
yp1 = narx_net_closed(p1,Pi1,Ai1);
plot([cell2mat(yp1)' cell2mat(t1)'])
(5)结果分析
更多优质内容持续发布中,请移步主页查看。
若有问题可邮箱联系:1736732074@qq.com
博主的WeChat:TCB1736732074
点赞+关注,下次不迷路!
















 3948
3948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











