






拟合数据
该组数据无明显关系,无法拟合,由于最终模型训练使用前两组数据,因此,将对数据进行相关性分析,查看哪个特征与前两个特征有线性相关关系,并替代原有特征
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('D:/JupyterNotebook/寒假/Myjupyter/zhw/血糖/2024.01.15/大板子高血糖数据.csv')
x = data.drop(['name','glucose','age','armTemp','enviTemp'],axis = 1)
# 选择要分析的特征
target_feature = 'Pha_10.0'
other_features = x.drop(columns=target_feature)
other_features = other_features.columns.tolist()
type(other_features)
# 绘制散点图
for feature in other_features:
plt.scatter(x[feature], x[target_feature], label=feature)
plt.xlabel('Other Features')
plt.ylabel('Target Feature')
plt.legend()
plt.show()
# 计算相关系数
correlation_matrix = data[other_features + [target_feature]].corr()
# print(correlation_matrix)
target_correlation = correlation_matrix.loc[target_feature, other_features]
print(target_correlation)
type(target_correlation)
target_correlation.abs().sort_values(ascending=False)
降序排列后,使用线性关系最强的特征代替原有特征
2024.02.28
因数据不平衡,将以前的数据进行拟合。
查看数据间的关系
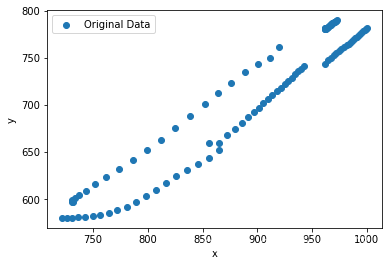
由上图可得,数据间的关系是一段一段的。为了高效的拟合数据,先筛选特征。
读取数据
from sklearn.decomposition import PCA
from sklearn.svm import SVR
from sklearn.tree import DecisionTreeRegressor
import pandas as pd
from sklearn.feature_selection import SelectKBest,RFE,SelectFromModel
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.feature_selection import VarianceThreshold
data = pd.read_csv('data')
features = data.drop(['glucose','name'],axis = 1)
target = data['glucose']
x_train,x_test,y_train,y_test = train_test_split(features,target,test_size=0.2,random_state=0)
在机器学习中,常量特征指的是在训练数据中取值始终相同的特征。这种特征对于建模和预测任务来说是没有任何信息的,因为它们没有助于区分不同的样本或提供任何有关目标变量的信息。如果一个特征的方差很小(比如0.1),它可能是一个低方差特征。低方差特征的取值变化非常有限,无论对目标变量还是其他特征来说,它们都提供的信息量非常少。
常量特征及低方差特征都可能会对机器学习模型产生负面影响,因为它们不会提供任何变化或区分性,或很难提供有用的区分性信息。当存在大量常量特征时,模型可能会出现以下问题:
-
方差为零:由于常量特征的取值始终相同,它们的方差为零。这可能导致某些模型(例如线性回归)的训练过程出现问题。
-
无关特征:常量特征对于目标变量没有预测能力,因为它们的取值不随目标变量的变化而变化。这可能会导致模型在预测时产生不准确或无效的结果。
为了处理常量特征,通常会采取以下方法:
-
特征选择:使用特征选择技术(例如方差阈值)来识别并删除常量特征。方差阈值是通过计算特征的方差来判断特征是否为常量。如果方差低于预定义的阈值,则将其视为常量特征并将其删除。
-
手动检查:手动检查数据集中的特征,并识别那些取值始终相同的特征。在发现常量特征后,可以选择将其删除或进行进一步的分析。
-
模型评估:在训练模型之前,可以对数据集中的特征进行初步评估。通过观察特征的分布和统计信息,可以快速识别常量特征。
处理常量特征的目的是减少模型的复杂性并提高模型的效率和准确性。通过删除常量特征,可以降低模型训练和预测的计算成本,并避免不必要的噪声和混淆。
处理低方差特征的方法包括:
-
特征选择:使用方差阈值或其他特征选择技术,选择具有较高方差的特征,并将低方差特征排除在模型之外。
-
组合特征:有时,将低方差特征与其他相关特征进行组合或进行数学变换可能会产生更有信息量的特征。这可以通过添加新的特征,例如特征差异、特征比率、特征乘积等来实现。
-
预处理方法:对低方差特征进行预处理可能有助于提高模型的性能。一种常见的方法是进行特征缩放,例如将特征标准化或归一化,使其值范围更接近。
需要注意的是,低方差特征本身并不一定意味着它们是无用的或应该被完全排除的。在某些情况下,低方差特征可能携带了一些重要的信息。因此,在处理低方差特征时,需要结合领域知识和实际情况进行判断和决策。
最佳的处理方法取决于具体的数据集和任务要求。通过评估特征的方差和与目标变量的相关性,可以确定是否需要处理低方差特征以及选择适当的处理方法。
#删除常量特征
constant_filter = VarianceThreshold(threshold=0)
constant_filter.fit(features)
constant_filter.get_support().sum()#得到非常量特征的个数
constant_list = [not temp for temp in constant_filter.get_support()]
features.columns[constant_list]
x_train_filter = constant_filter.transform(x_train)
x_test_filter = constant_filter.transform(x_test)
print(x_train_filter.shape,x_test_filter.shape,x_train.shape,x_test.shape)
#删除准常量特征
#删除准常量特征
quasi_constant_filter = VarianceThreshold(threshold=0.01)
quasi_constant_filter.fit(features)
quasi_constant_filter.get_support().sum()
x_train_quasi_filter = quasi_constant_filter.transform(x_train)
x_test_quasi_filter = quasi_constant_filter.transform(x_test)
print(x_train_filter.shape,x_test_filter.shape,x_train_quasi_filter.shape,x_test_quasi_filter.shape)
x_train_quasi_filter_features = features.columns[quasi_constant_filter.get_support()]
x_train_quasi_filter_features
#删除重复的特征
x_train_T = x_train_quasi_filter.T
x_test_T = x_test_quasi_filter.T
type(x_train_T)
x_train_T = pd.DataFrame(x_train_T)
# 使用 rename() 方法给行索引换名字
x_train_T.rename(index=dict(zip(x_train_T.index, x_train_quasi_filter_features)), inplace=True)
# 打印修改后的 DataFrame
# print(x_train_T)
x_test_T = pd.DataFrame(x_test_T)
x_test_T.rename(index=dict(zip(x_test_T.index, x_train_quasi_filter_features)), inplace=True)
print(x_train_T.shape,x_test_T.shape)
print(x_train_T.duplicated().sum())
duplicated_features = x_train_T.duplicated()
print(duplicated_features)
features_to_keep = [not index for index in duplicated_features]
x_train_unique = x_train_T[features_to_keep].T
x_test_unique = x_test_T[features_to_keep].T
print(x_train_unique.shape,x_train.shape)
查看特征之间的相关性
当特征之间存在线性相关性时,这可能会对机器学习模型的性能产生负面影响。线性相关性指的是两个或多个特征之间存在线性的关系,即它们可以通过线性方程表示或高度相关。
特征之间的线性相关性可能导致以下问题:
-
多重共线性:多个特征之间存在高度相关性时,称为多重共线性。多重共线性可能导致模型参数估计不准确或不稳定,使得模型的解释性和泛化能力降低。
-
过拟合:当特征之间存在强烈的线性相关性时,模型可能过度依赖这些特征进行预测。这可能导致过拟合,即模型在训练数据上表现良好,但在新数据上的泛化能力较差。
处理特征之间线性相关性的方法包括:
-
特征选择:通过选择具有较高相关性的特征子集,可以减少多重共线性的影响。可以使用相关性矩阵或其他特征选择方法来选择与目标变量相关性较高但特征之间相关性较低的特征。
-
主成分分析(PCA):PCA是一种降维技术,可以将高维特征空间转换为具有较低相关性的新特征空间。通过保留最重要的主成分,PCA可以减少特征之间的相关性,并提高模型的性能。
-
正则化方法:正则化方法(例如岭回归、Lasso回归)可以通过加入正则化项来惩罚模型中的相关特征。这有助于减少特征之间的相关性,并提高模型的鲁棒性和泛化能力。
-
领域知识和特征工程:了解数据背后的领域知识可以帮助识别和处理特征之间的相关性。根据领域知识,可以进行特征工程来创建新的特征,将相关性转化为更有意义的特征表示。
处理特征之间线性相关性的最佳方法取决于具体的数据集和任务要求。使用相关性分析和实验评估不同方法的效果,选择合适的方法来处理特征之间的线性相关性。
corrmat = x_train_unique.corr()
plt.figure(figsize=(12,8))
sns.heatmap(corrmat)
选择模型
使用自动机器学习模型,选择模型,回归问题
import pandas as pd
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
data = pd.read_csv('data.csv')
data.head()
#使用自动机器学习模型,确定模型
from pycaret.regression import setup, compare_models
exp_clf = setup(data,
target=' '
)
best = compare_models(sort='MAE')
结果图
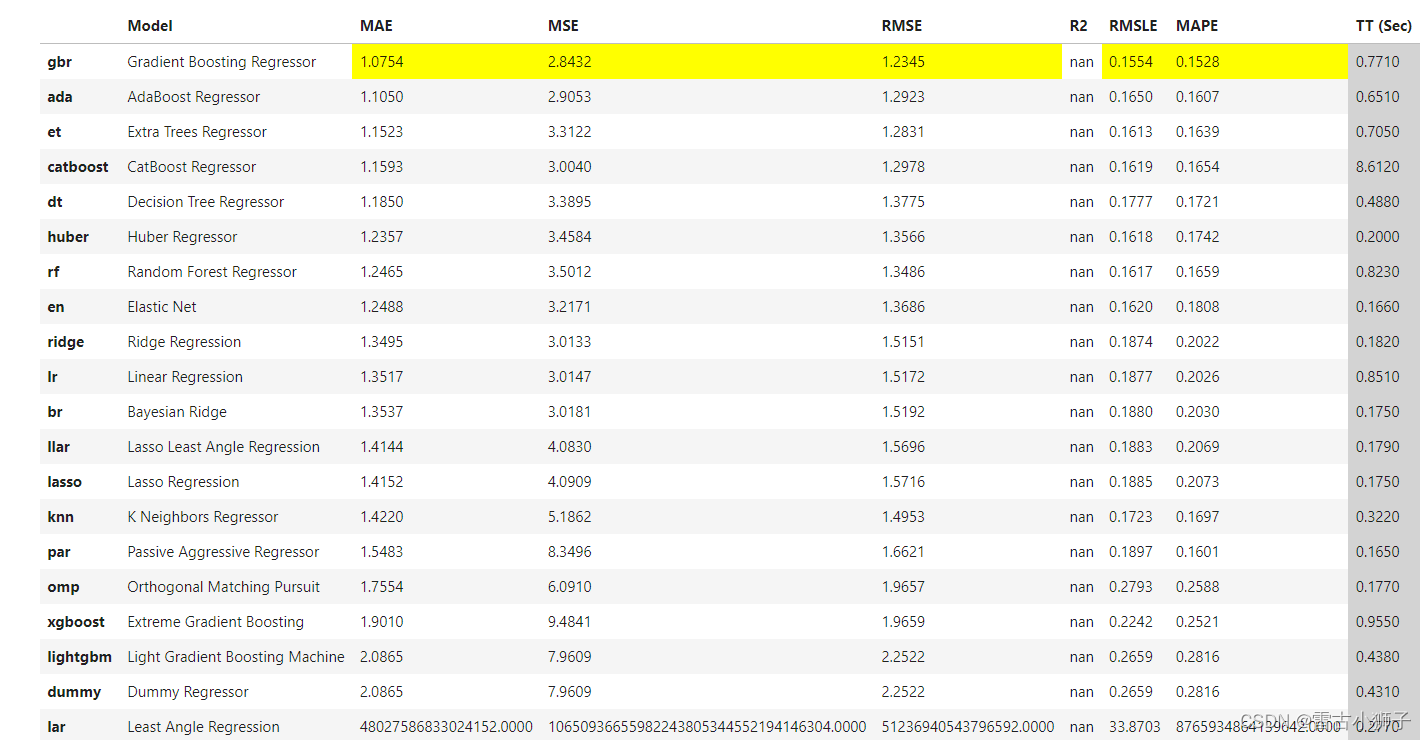
使用网格搜索的方法,将前三个效果好一点的模型调参
import pandas as pd
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import GradientBoostingRegressor, AdaBoostRegressor, ExtraTreesRegressor
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import GradientBoostingRegressor, AdaBoostRegressor, ExtraTreesRegressor
data = pd.read_csv(data.csv')
features = ['']
target = data['']
X_train, X_test, y_train, y_test = train_test_split(data[features], target, test_size=0.2, random_state=3000)
# 定义模型对象
gradient_boosting = GradientBoostingRegressor()
adaboost = AdaBoostRegressor()
extra_trees = ExtraTreesRegressor()
# 定义管道
pipeline = Pipeline([
('model', None) # 模型对象将在网格搜索中替换
])
# 定义超参数空间
param_grid = [
{
'model': [gradient_boosting],
'model__n_estimators': [50, 100, 200],
'model__learning_rate': [0.1, 0.01, 0.001],
'model__max_depth': [3, 5, 7]
},
{
'model': [adaboost],
'model__n_estimators': [50, 100, 200],
'model__learning_rate': [0.1, 0.01, 0.001]
},
{
'model': [extra_trees],
'model__n_estimators': [50, 100, 200],
'model__max_depth': [None, 5, 10]
}
]
# 创建网格搜索对象
grid_search = GridSearchCV(pipeline, param_grid, scoring='neg_mean_squared_error', cv=5)
# 执行网格搜索
grid_search.fit(X_train, y_train)
# 输出最佳模型和超参数组合
best_model = grid_search.best_estimator_
best_params = grid_search.best_params_
best_score = grid_search.best_score_
print("Best Model:", best_model)
print("Best Parameters:", best_params)
print("Best Score:", best_score)
在选择适当的评估指标来评估模型的性能时,需要考虑以下几个因素:
-
问题类型:首先要了解你面对的是什么类型的问题。是回归问题还是分类问题?不同类型的问题可能需要不同的评估指标。
-
业务需求:了解业务需求对模型性能的特定要求。例如,在某些应用中,模型对于错误分类的惩罚可能比较大,因此准确率和召回率可能是更重要的指标。
-
数据特点:考虑你的数据的特点。例如,如果数据存在类别不平衡问题,精确度可能不是一个合适的评估指标,而应该考虑使用召回率或F1得分等指标。
-
预测误差的影响:了解模型预测误差对最终结果的影响程度。对于一些应用,预测误差可能会对业务决策产生重大影响,因此需要选择更加敏感的评估指标。
以下是一些常用的评估指标,根据问题类型进行分类:
对于回归问题:
- 均方误差(Mean Squared Error,MSE)
- 均方根误差(Root Mean Squared Error,RMSE)
- 平均绝对误差(Mean Absolute Error,MAE)
- 决定系数(Coefficient of Determination,R^2)
对于分类问题:
- 准确率(Accuracy)
- 精确度(Precision)
- 召回率(Recall)
- F1得分(F1 Score)
- ROC曲线和AUC(Area Under the Curve)
对于聚类问题:
- 轮廓系数(Silhouette Coefficient)
- Calinski-Harabasz指数
- Davies-Bouldin指数
在实际应用中,选择适当的评估指标需要综合考虑以上因素。通常,你可以根据问题类型和业务需求选择一个主要的评估指标,并结合其他指标来进行综合评估。
此外,还可以使用交叉验证、验证集和测试集等技术来更全面地评估模型的性能。通过在不同数据集上进行评估,可以更好地了解模型的泛化能力和稳定性。
最终,选择适当的评估指标是根据具体问题的特点和需求进行的,需要在实践中进行试验和验证,以确保评估指标能够准确反映模型的性能和满足业务需求。















 775
775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









