






WiTUnet:一种集成CNN和Transformer的u型架构,用于改进特征对齐和局部信息融合
WiTUnet: A U-Shaped Architecture Integrating CNN and Transformer for Improved Feature Alignment and Local Information Fusion.
摘要
低剂量计算机断层扫描(LDCT)已成为诊断医学成像的首选技术,这是由于与X射线辐射和传统计算机断层扫描(CT)技术相关的潜在健康风险。尽管LDCT与标准CT相比使用较低的辐射剂量,但它导致了图像噪声的增加,这可能会影响诊断的准确性。
为了解决这一问题,已经开发了基于高级深度学习的LDCT去噪算法。这些算法主要利用卷积神经网络(CNNs)或Transformer网络,并且通常采用Unet架构,通过 Short-Cut (skip connections)整合编码器和解码器的特征图来增强图像细节。然而,现有方法过分关注编码器和解码器结构的优化,而忽视了Unet架构本身潜在的增强。
由于编码器和解码器在特征图特性上有显著差异,这种疏忽可能会成为问题,简单的融合策略可能会阻碍有效的图像重建。在本文中,作者介绍了WiTUnet,这是一种新颖的LDCT图像去噪方法,它使用嵌套的密集 Short-Cut 路径代替传统的 Short-Cut ,以改善特征融合。
此外,为了应对传统Transformer在大图像上的高计算需求,WiTUnet融入了一种窗口化Transformer结构,该结构以较小的、不重叠的片段处理图像,显著降低了计算负载。
此外,作者的方法在编码器和解码器中均包含一个局部图像感知增强(LiPe)模块,以替代Transformer中的标准多层感知机(MLP),从而提高局部图像特征的捕捉和表示。通过大量的实验比较,WiTUnet在峰值信噪比(PSNR)、结构相似性(SSIM)和均方根误差(RMSE)等关键指标上已经显示出优于现有方法的表现,显著提高了去噪和图像质量。
代码: https://github.com/woldier/WiTUNet.
Introduction
近年来,低剂量计算机断层扫描(LDCT)作为降低X射线辐射暴露的有前景的方法,受到了医学界和公众的广泛关注[11]。尽管LDCT技术在一定程度上减轻了与全剂量计算机断层扫描(FDCT)相关联的辐射风险,但同时它也导致了图像质量的显著下降。这种质量下降主要是由LDCT图像中存在的严重噪声和伪影[18]引起的,这给准确疾病诊断带来了挑战。因此,在确保辐射安全[16]的同时提高图像质量的双重目标,已经成为医学成像领域的关键研究课题。
为了提高低剂量计算机断层扫描(LDCT)图像的质量,降噪是一项主要且直接的战略。然而,由于LDCT图像降噪问题的不适定性,这依然是一个艰巨的挑战[7]。为了解决这个问题,研究行人采取了两种主要方法:传统方法和深度学习方法(例如,卷积神经网络(CNN)[2][6]和Transformer[21][22])。传统方法采用迭代技术和配备特定先验信息的物理模型有效抑制噪声和伪影。然而,由于硬件限制和计算需求,这些方法对于商用CT扫描仪来说通常是不可行的[25]。相反,随着深度学习技术的发展,基于CNN的方法已经取得了最先进的表现[28]。特别是,Chen等[2]引入了一种残差编码器-解码器CNN结构,即RedCNN,它通过利用残差学习和与Unet[14]类似的结构实现了有效的降噪。此外,像DnCNN[28]、CBDnet[5]和NBNet[3]这样的架构在图像处理中表现出了鲁棒性,并且适合处理实际噪声。DnCNN通过使用残差学习和批量归一化有效地去除了高斯噪声。相比之下,CBDnet通过五个卷积层增强噪声水平估计,显著提高了网络在噪声滤波中的泛化性能。NBNet通过在编码器和解码器之间的不同下采样层集成卷积网络来优化特征图的融合,显著提高了去噪性能。这些深度学习方法已被证明是LDCT图像降噪的有效解决方案,在实际应用中取得了令人满意的结果。它们为提高医学图像质量和临床诊断的精确性提供了关键的技术支持。
尽管基于卷积神经网络(CNN)的方法在图像去噪方面最近取得了显著的进展,但这些方法主要还是依赖于使用卷积层来提取特征。然而,卷积层在捕捉局部信息方面存在限制,导致基于CNN的方法严重依赖于多层相互连接的卷积层来获取非局部信息。此外,对编码器-解码器结构的研究仍然相当匮乏。
近年来, Transformer 模型[20]因其强大的全局感知能力,显著推进了自然语言处理(NLP)领域的发展。这些模型在计算机视觉(CV)领域也取得了实质性进展。在这种整合中的一个显著努力是Dosovitskiy等人开发的视觉 Transformer (ViT)[4],通过将图像转换为作为 Transformer Token 的块,建立了CV与 Transformer 之间的联系。继此之后,Liu等人引入了Swin Transformer [9],通过块融合和循环移位机制增强每个 Token 的上下文敏感性。
然而,LDCT图像(通常是512 x 512)的大尺寸由于全局注意力的计算需求而带来挑战。对此,Wang等人[21]提出了CTformer,采用编码器-解码器架构中的重叠窗口 Transformer 和Token2Token扩张策略进行LDCT图像去噪,取得了令人印象深刻的结果。 Transformer 的全局感知能力,结合注意机制的引入,使这些模型能够克服仅限于局部特征感知的卷积层的局限性。这使得基于 Transformer 的方法能够增强全局特征提取,促进远程特征交互,从而为LDCT图像去噪利用更全面的信息。
当前的方法,无论是基于卷积神经网络(CNNs)还是 Transformer (Transformers),都表现出一定的局限性。基于CNN的模型受到其感受野的限制,这限制了它们在特征图内提取远距离上下文信息的能力。另一方面,基于Transformer的方法虽然在全局信息提取方面很强大,但往往忽视局部细节,并且由于其全局注意力机制,计算复杂度较高。此外,利用CNN或Transformer的方法通常在编码器和解码器之间直接通过跳跃连接连接特征图,这可能导致这些组件间上下文信息的最优对齐不佳。这种错位可能会对重建结果产生不利影响,从而影响临床诊断的准确性。
本文介绍了一种新颖的编码器-解码器架构,该架构融合了卷积神经网络(CNNs)和Transformer,以利用它们的互补优势。在这种架构中,使用嵌套的密集跳跃路径确保了编码器与解码器之间的语义一致性,从而增强了特征图的整合。通过结合CNNs和Transformers,该网络在关注全局信息的同时,保持了对于局部细节的敏感性,有效地提取了局部和非局部特征。与现有网络的广泛实验研究及对比表明,此方法显著降低了低剂量计算机断层扫描(LDCT)图像中的噪声,并提升了图像质量。
本文的主要贡献如下:
为了解决低剂量计算机断层扫描(LDCT)的去噪挑战,作者引入了一种新颖的编码器-解码器架构。该架构具有一系列嵌套的密集跳跃通路,这些通路被特别设计用来有效地将编码器中的高分辨率特征图与解码器中语义丰富的特征图整合在一起,从而增强信息对齐。
认识到非局部信息对全局感知的重要性,同时考虑到传统全局注意力机制的计算需求较高,作者提出了一种非重叠窗口自注意力模块。这个模块被整合到作者新的编码器-解码器架构中,显著提高了对非局部信息全局感知的能力。
为了提高 Transformer 模块内对局部信息的敏感度,作者开发了一个新的基于CNN的块,名为局部图像视角增强(LiPe)。这个块替换了 Transformer 中的传统MLP,从而增强了局部细节的捕捉。
Related work
Cnn
图像重建(去噪)旨在从图像的损坏版本中恢复清晰度。在图像去噪领域,一个受欢迎的解决方案是使用带有跳跃连接的U形结构逐步捕捉多尺度信息以构建高效模型[3][27][7]。张等人[29]提出了一种基于卷积神经网络(CNN)的图像去噪方法,通过引入残差学习技术,使网络能够更好地学习图像中的噪声模式。通过引入残差学习技术,网络可以更好地学习图像中的噪声模式,从而提高去噪效果。这种方法已经在实验中被证明在去噪性能上有明显优势,对各种类型和强度的噪声表现出良好的鲁棒性,为残差学习图像去噪方法的发展带来了新的突破。陈等人[2],在低剂量计算机断层扫描(LDCT)图像去噪领域的先驱,提出了RED-CNN,将卷积、反卷积和跳跃连接融入到具有U形结构的编码器-解码器卷积神经网络中,展示了深度学习方法。杨等人[24]使用带有Wasserstein距离的生成对抗网络(WGAN)来借助感知损失提高去噪后图像的质量。
由于WGAN在生成丰富的真实世界CT图像中的作用,以及感知损失在提高去噪图像质量中的作用,该模型避免了去噪图像中的过渡平滑现象,并保留了图像中的重要信息。通过关注如何使用损失函数,网络可以更好地训练以产生尽可能接近FDCT的图像。田等[7]提出了一种关注引导的去噪卷积神经网络(ADNet)。该网络通过使用稀疏的膨胀卷积块和普通卷积去除噪声,平衡了性能和效率。特征增强块整合全局和局部特征信息,解决复杂背景中隐藏噪声的问题。作者提出了三个相互补充的有效块来解决去噪问题:稀疏块提高了效率,但可能导致信息丢失;特征增强块弥补了这一缺陷;关注块有助于从复杂背景中提取噪声。
陈等[3]提出了一种利用U形结构的深度卷积神经网络NBNet。该网络能够学习图像的噪声基础,并通过子空间投影将噪声从图像中分离。其U形结构使得网络能够在编码器和解码器之间交换信息,更好地捕捉图像中的细微特征并进行准确去噪。该研究的实验结果表明,NBNet在各种类型和强度的噪声下都取得了优秀的去噪效果,为图像去噪领域带来了新的高效方法。
黄等[7]提出了用于LDCT图像去噪的DU-GAN方法,该方法利用基于U-Net的判别器在图像和梯度域中学习去噪图像与FDCT图像之间的差异。他们还应用了另一个基于U-Net的判别器来减少去噪CT图像的伪影并增强边缘。尽管在GAN中使用U-Net作为判别器以及双域训练策略增加了一些计算成本,但性能的提升是可以接受的。
尽管前面的讨论突出了基于卷积神经网络架构的各种图像去噪方法,但这些方法经常遇到特定的限制。首先,卷积神经网络模型受到局部感受野的限制,这阻碍了它们捕获大距离范围内的全局信息,特别是在大图像中。这个限制可能会对它们的表现产生不利影响。其次,尽管卷积神经网络中的U型结构和跳跃连接有助于低层次和高层次特征的有效传输,但编码器和解码器之间进行高效信息交换的机制尚未完全优化,可能导致信息丢失或冗余。相比之下,Transformer模型在全球感知方面表现出色,可以在不受局部感受野限制的情况下捕获长距离依赖关系,与CNN不同。此外,Transformer内的注意力机制能有效关联不同图像位置的信息,从而促进更一体化的全局和局部特征结合方法。
Transformer
杨等人[23]深入研究了CT成像机制和正弦图统计特性,设计了一种内部结构损失,该损失包含了全局和局部内部结构,以增强CT图像质量。此外,他们引入了一个正弦图变换模块,以更有效地捕捉正弦图特征。通过关注常常被忽视的正弦图的内部结构,他们显著减少了图像伪影。王等人[22]提出了一种新颖的局部增强窗口(LeWin)转换块,使用非重叠的基于窗口的注意力机制,以降低在捕捉局部信息时对高分辨率特征图的计算需求。将此模块应用于U-net架构中,他们的方法在图像重建中取得了优异的结果。在另一项贡献中,王等人[21]在U型编码器-解码器架构中使用了重叠窗口 Transformer 和Token2Token膨胀策略开发了一种CT前馈网络,用于LDCT图像去噪,取得了卓越的性能。 Transformer 的全局感知能力和注意力机制的整合不仅克服了卷积层局部特征感知的限制,而且增强了全局特征提取并促进远距离特征交互,从而丰富了用于LDCT图像去噪的信息。
虽然Transformers擅长处理全局信息,但与CNN相比,在局部感知方面相对较弱。这种局限性在处理详细图像信息时可能导致次优性能。此外,现有研究大量集中在提高Transformers在图像处理任务上的能力,却常常忽略了与Unet架构的整合。这种疏忽可能会限制它们在同时捕捉局部和全局特征方面的有效性。因此,将CNN与Transformers结合起来,利用两种架构的优势,并彻底研究在这一背景下Unet结构的兼容性和有效性是至关重要的。
Method
在本节中,作者首先描述了网络的总体架构。随后,作者介绍了窗口 Transformer (WT)模块,它包括窗口化多 Head 注意力(W-MSA)和局部信息感知增强(LiPe)。这些元素构成了编码器和解码器中的基础组件。最后,作者讨论了嵌套密集块,其特点在于嵌套密集的跳跃路径,这些路径促进了编码器特征图与解码器特征图之间的跳跃连接。
WiTUnet被提出为一种U形的网络架构,如图1 (a)所示。该网络由编码器、瓶颈、解码器和中间嵌套的密集块组成。特别是,在处理损坏的图像时,即表示为
y
∈
R
1
×
H
×
W
y \in \mathbb{R}^{1\times H \times W}
y∈R1×H×W的低剂量计算机断层扫描(LDCT)图像,WiTUnet首先使用一个输入嵌入层,一个步长和填充设置为1的
3
×
3
3\times 3
3×3卷积层,将原始数据转换为特征图
a
∈
R
C
×
H
×
W
a \in \mathbb{R}^{C \times H \times W}
a∈RC×H×W。遵循U形架构[14],这些特征图通过
D
D
D个编码器块进行处理,每个编码器块包含几个窗口Transformer (WT)块,其中包含一个窗口化多Head自注意力(W-MSA)块。W-MSA块通过其自注意力机制捕捉非局部信息,并通过非重叠窗口减少计算复杂性,结合局部信息感知增强(LiPe))以精确捕捉特征图中的局部细节和全局信息。编码器每一级的输出都通过一个步长为2的
4
×
4
4\times 4
4×4卷积层进行下采样,作为下一编码器层的输入,其中特征图的通道数翻倍,其尺寸减半。经过
k
k
k层编码后,特征映射表示为
a
k
0
∈
R
2
C
×
H
′
×
W
′
a_k^0 \in \mathbb{R}^{2C \times H' \times W'}
ak0∈R2C×H′×W′,其中
k
∈
[
0
,
D
)
k \in [0, D)
k∈[0,D)。
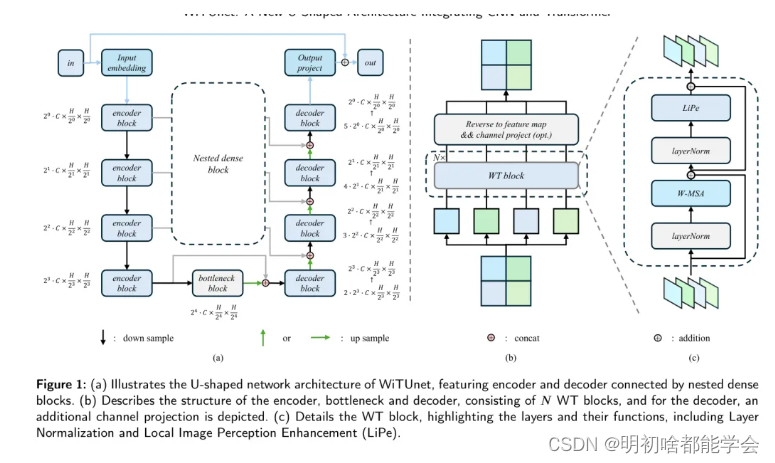
在最后一个编码器层和解码器之间,引入了一个由WT块组成的瓶颈层,输出特征图为
Z
D
0
∈
R
C
×
H
′
×
W
′
Z_{D}^{0} \in \mathbb{R}^{C \times H' \times W'}
ZD0∈RC×H′×W′。这个瓶颈层被设计为更有效地捕捉全局信息。例如,当编码器深度足够时,最深特征图的尺寸与窗口大小相匹配,使得W-MSA能够高效地捕捉全局信息,而LiPe模块则保持对局部细节的敏感性。因此,网络可以在不需要循环移位[9]的情况下感知全局信息。
在解码器部分,特征图
z
p
0
z_{p}^{0}
zp0经历D个Level的解码处理。解码器的结构与编码器相似,采用堆叠的WT块。特征图通过使用
2
×
2
2 \times 2
2×2转置卷积核进行上采样,该卷积核的步长为2,这会使得通道数减半,尺寸加倍。与传统的U形网络设计[14][22]一致,解码器接收来自相应编码器Level的跳跃路径连接,并将它们与来自前一个解码层的上采样输入相结合。在引入嵌套密集块之后,输入特征图的通道数增加,因此,在与编码器输出结合后,解码器的第k级输入为
a
k
,
v
,
i
n
0
∈
R
(
D
−
k
+
1
)
×
C
×
H
′
×
W
′
a_{k,v,in}^{0} \in \mathbb{R}^{(D-k+1) \times C \times H' \times W'}
ak,v,in0∈R(D−k+1)×C×H′×W′。为了与传统的U形网络解码器输出保持一致,解码器中的WT块调整输出特征图的通道数,得到
a
k
,
v
,
o
u
t
0
∈
R
2
C
×
H
′
×
W
′
a_{k,v,out}^{0} \in \mathbb{R}^{2C \times H' \times W'}
ak,v,out0∈R2C×H′×W′,其中
k
∈
[
0
,
D
)
k \in [0,D)
k∈[0,D)且
0
=
D
−
k
0 = D - k
0=D−k。这种命名约定旨在简化在后续讨论中引入嵌套密集块。经过D级解码处理后,最终的输出是
a
0
,
4
,
o
u
t
0
∈
R
C
×
H
×
W
a_{0,4,out}^{0} \in \mathbb{R}^{C \times H \times W}
a0,4,out0∈RC×H×W,然后使用一个填充且步长设置为1的
3
×
3
3 \times 3
3×3卷积输出投影层将其投影到
r
∈
R
1
×
H
×
W
r \in \mathbb{R}^{1 \times H \times W}
r∈R1×H×W,并将其加到原始LDCT图像
y
y
y上以产生最终的重建图像
g
+
r
g + r
g+r,其中
r
∈
R
1
×
H
×
W
r \in \mathbb{R}^{1 \times H \times W}
r∈R1×H×W。
WiTUnet架构专门为满足LDCT去噪的独特要求而设计。最初,嵌套的密集块的使用加强了不同网络层之间的信息流动,这有助于在保留关键图像细节的同时减少噪声。此外,W-MSA模块与LiPe模块的结合使得通过窗口多头自注意力机制有效地捕获全局信息,并通过局部信息增强组件细化局部细节。这种整合优化了全局与局部信息之间的协同作用,使WiTUnet在LDCT图像处理中能够有效地平衡计算效率与重建质量。总的来说,WiTUnet以其创新的U形网络结构,优化了信息流和特征整合,为LDCT去噪提供了一个有效的解决方案。它显著提高了图像质量,而不会牺牲细节丰富性,从而为临床诊断提供了更清晰、更可靠的图像。
Window Transformer block
将Transformer应用于低剂量计算机断层扫描(LDCT)图像去噪领域面临着多重挑战。首先,标准的Transformer需要对所有标记进行全局自注意力计算,这导致了高计算复杂性[4][20],特别是考虑到LDCT图像的高分辨率特性,这会增加特征图的维度并复杂化全局注意力计算。其次,尽管Transformer通过自注意力机制擅长捕捉长距离信息,但在图像去噪任务中保留局部信息至关重要,尤其是在对后续临床诊断至关重要的LDCT去噪中。考虑到Transformer可能不如卷积神经网络(CNN)那样有效地捕捉局部细节,融合CNN以获得更多局部细节变得尤为重要。
为了应对这些挑战,本研究采用了窗口Transformer (WT)块,如图1©所示。WT块利用W-MSA有效捕获长距离信息,并通过窗口化方法显著降低计算成本。此外,LiPe替换了传统的MLP层,以增强WT块捕获局部信息的能力。图1(b)展示了多个WT块的堆叠效果。在解码器中,由于WT块后通道数的变化,在WT块后进行通道投影,而在编码器和瓶颈层中不这样做。值得注意的是,来自第(l一1)块的输入,表示为
X
i
−
1
X_{i-1}
Xi−1,通过W-MSA和LiPe进行处理。WT块内的计算可以用以下数学表达式表示:
[X_{t}^{1} = \text{W-MSA}(\text{LN}(X_{i-1})) + X_{i-1} = \text{LiPe}(\text{LN}(X_{t-1})) + X_{t-1}]
在公式中,
X
t
X_{t}
Xt 和
X
X
X 分别代表W-MSA和LiPe的输出,而LN表示层归一化[1]。
基于非重叠窗口的多头自注意力(W-MSA)。在本文中,作者采用了非重叠的W-MSA机制,与视觉Transformer中使用的全局自注意力机制相比,大大降低了计算复杂性。考虑一个二维特征图
X
∈
R
C
×
H
×
W
X \in \mathbb{R}^{C \times H \times W}
X∈RC×H×W,其中C、H和W分别表示通道数、高度和宽度。作者将X划分为N=M个大小为M×M的非重叠窗口,每个窗口被展平并转换为
X
i
∈
R
M
′
×
C
X_{i} \in \mathbb{R}^{M' \times C}
Xi∈RM′×C。然后,每个窗口都通过W-MSA进行处理,如果它有d个头,那么每个头分配一个维度
d
=
C
/
d
d = C/d
d=C/d。每个窗口内的自注意力计算如下:
[X = [X_{1}, X_{2}, X_{3}, …, X_{N}]; \text{ where } N = \frac{H \times W}{M^{2}}]
[U = \text{Attention}(X_{i}W^{Q}, X_{i}W^{K}, X_{i}W^{V}), i = 1, 2, …, N = {Y_{1}', Y_{2}, Y_{3}, …, Y_{N}}]
[O = \text{concat}(Y_{1}, Y_{2}, Y_{3}, …, Y_{a})]
在这里,
W
Q
W^{Q}
WQ,
W
K
W^{K}
WK,
W
V
W^{V}
WV 分别属于第k个Head的Query、键和值的投影矩阵,且
W
R
W^{R}
WR
[W^{Q}, W^{K}, W^{V} \in \mathbb{R}^{C \times d_{s}}]。其中,
Y
i
Y_{i}
Yi 表示第k个Head从所有窗口获得的输出。通过连接所有Head的输出并应用线性投影,可以得到最终的输出。与之前的工作 [9][17]一致,作者将相对位置编码纳入到作者的注意力机制中。因此,注意力的计算在数学上定义为:
[ \text{Attention}(Q, K, V) = \text{SoftMax} \left( \frac{QK^T}{\sqrt{d_s}} + B \right) V ]
在公式中,B代表相对位置编码偏差,这是从可学习的参数
B
∈
R
(
2
M
−
1
)
×
(
2
M
−
1
)
B \in \mathbb{R}^{(2M-1) \times (2M-1)}
B∈R(2M−1)×(2M−1)获得的。W-MSA将全局自注意力计算复杂度从
O
(
H
2
W
2
C
)
O(H^2W^2C)
O(H2W2C)降低到了
O
(
M
2
H
W
C
)
O(M^2HWC)
O(M2HWC)。
局部图像视角增强(LiPe)。标准Transformer中的前馈网络(FFN),通常采用多层感知机(MLP),在捕捉局部信息方面能力有限。对于低剂量CT图像去噪,精确恢复图像细节至关重要,因为这些细节对准确疾病诊断至关重要。由于卷积神经网络(CNN)卷积核的性质,CNN对局部信息表现出更高的敏感性。为了弥补MLP的不足,作者采用了先前研究中的策略,用卷积块替换传统的FFN。如图2所示,作者首先使用线性投影来增加每个窗口特征图的通道数。随后,作者将窗口Reshape回原始特征图形式,并应用一个3×3的卷积核来捕捉局部细节。之后,特征图被窗口化和展平,然后通过另一个线性投影将通道数恢复到原来的维度。在每一层之间,作者使用高斯误差线性单元(GELU)作为激活函数。
嵌套密集块
图3(a)展示了WiTUnet结构的另一种视角,特别突出了嵌套密集块中的复杂嵌套密集跳跃路径连接。在图3中,
X
k
,
o
X_{k,o}
Xk,o 代表编码器的阶段,其中
k
∈
[
0
,
D
)
k \in [0, D)
k∈[0,D),而
X
k
,
v
X_{k,v}
Xk,v表示解码器的阶段,其中
k
∈
[
0
,
D
)
k \in[0,D)
k∈[0,D)且
v
=
D
−
k
v= D - k
v=D−k;
X
p
,
o
X_{p,o}
Xp,o表示瓶颈分。剩余的图解重点介绍了本文中提到的嵌套密集块,与传统的U-Net架构的主要区别在于重新设计的跳跃路径(由绿色和蓝色箭头指示)。这些重新设计的关系改变了编码器与解码器之间的交互方式。不同于传统U-Net中,编码器的特征图直接传递给解码器,在这里,它们首先通过一系列密集卷积块传输。这些块中的层数与从跳跃连接收到的特征图的总通道数相关。本质上,密集卷积块将编码器特征图的语义层次与解码器中将要处理的特征图拉近。作者假设,当接收到的编码器特征图在语义上与对应的解码器特征图相似时,优化器在解决优化问题时面临更简单的任务。正式地,跳跃路径可以表示如下。设
L
k
,
o
L_{k,o}
Lk,o为节点
X
k
X_{k}
Xk的输出。
k
k
k表示下采样的深度,
v
v
v表示在嵌套块中的横向位置。
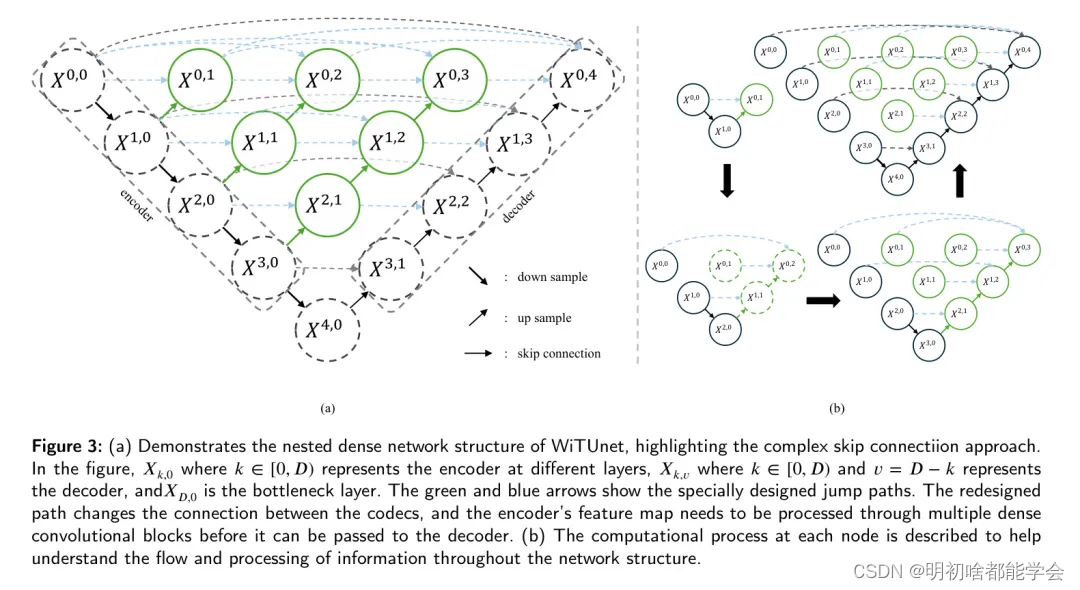

需要指出的是,
X
0
,
0
=
X
o
,
o
(
T
i
n
)
X_{0,0} = X_{o,o}(T_{in})
X0,0=Xo,o(Tin)。其中符号
U
U
U表示上采样层,上采样操作如第3.1节所述。通常,
v
=
1
v=1
v=1的节点接收来自两个源的输入,
v
=
2
v=2
v=2的节点接收来自三个源的输入,以此类推,
v
=
i
v=i
v=i的节点接收
i
+
1
i+1
i+1个输入。为了更清晰地理解所涉及的计算,图3(b)直观地描述了每个节点的计算过程。














 8713
8713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









