







(搜了一下,好像很少几乎没有关于熵正则的代码,本文就展示一下AC算法中熵正则是如何应用的吧)
1、代码
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 定义一个策略网络,用于输出动作的概率分布
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
# 使用两层全连接层和ReLU激活函数
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, action_dim)
def forward(self, state):
# 输入状态,输出动作的对数概率
x = F.relu(self.fc1(state))
x = self.fc2(x)
log_prob = F.log_softmax(x, dim=-1)
log_prob = log_prob.squeeze(-1)
return log_prob
# 定义一个值函数网络,用于估计状态的价值
class ValueNetwork(nn.Module):
def __init__(self, state_dim):
super(ValueNetwork, self).__init__()
# 使用两层全连接层和ReLU激活函数
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, 1)
def forward(self, state):
# 输入状态,输出状态值
x = F.relu(self.fc1(state))
x = self.fc2(x)
x = x.squeeze(-1)
return x
# 定义一些超参数
env_name = "CartPole-v0" # 环境名称
gamma = 0.99 # 折扣因子
alpha = 0.01 # 学习率
beta = 0.01 # 熵正则系数
num_episodes = 300 # 训练的回合数
# 创建环境和网络
env = gym.make(env_name) # 创建环境
state_dim = env.observation_space.shape[0] # 状态空间维度
action_dim = env.action_space.n # 动作空间维度
policy_net = PolicyNetwork(state_dim, action_dim) # 创建策略网络
value_net = ValueNetwork(state_dim) # 创建值函数网络
policy_optimizer = optim.Adam(policy_net.parameters(), lr=alpha) # 创建策略网络的优化器
value_optimizer = optim.Adam(value_net.parameters(), lr=alpha) # 创建值函数网络的优化器
# 训练循环
for i_episode in range(num_episodes):
# 初始化状态和回报
state = env.reset() # 重置环境,获取初始状态
state = torch.tensor(state, dtype=torch.float) # 转换为张量
total_reward = 0.0 # 累积回报
# 采样一条轨迹
log_probs = [] # 存储动作的对数概率
values = [] # 存储状态值
rewards = [] # 存储即时奖励
entropies = [] # 存储动作分布的熵
while True:
# 选择动作并执行
log_prob = policy_net(state) # 计算动作的对数概率
prob = torch.exp(log_prob) # 计算动作的概率
entropy = -torch.sum(prob * log_prob) # 计算动作分布的熵
action = torch.multinomial(prob, 1).item() # 按照概率采样一个动作
next_state, reward, done, _ = env.step(action) # 执行动作,获取下一个状态,奖励和结束标志
next_state = torch.tensor(next_state, dtype=torch.float) # 转换为张量
value = value_net(state) # 计算当前状态
# 存储相关信息
log_probs.append(log_prob[action]) # 存储选择的动作的对数概率
values.append(value) # 存储当前状态值
rewards.append(reward) # 存储即时奖励
entropies.append(entropy) # 存储动作分布的熵
# 更新状态和回报
state = next_state # 更新状态
total_reward += reward # 累积回报
# 判断是否结束
if done:
break
# 计算优势函数和目标值函数
advantages = [] # 存储优势函数
returns = [] # 存储目标值函数
R = 0.0 # 初始化累积回报
for r in rewards[::-1]: # 逆序遍历奖励序列
R = r + gamma * R # 计算累积回报
returns.insert(0, R) # 插入到目标值函数序列的开头
returns = torch.tensor(returns) # 转换为张量
for value, R in zip(values, returns): # 遍历状态值和目标值函数序列
advantage = R - value.item() # 计算优势函数
advantages.append(advantage) # 存储优势函数
advantages = torch.tensor(advantages) # 转换为张量
# 更新策略网络和值函数网络
policy_loss = 0.0 # 初始化策略网络的损失函数
value_loss = 0.0 # 初始化值函数网络的损失函数
for log_prob, value, advantage, entropy,returnss in zip(log_probs, values, advantages, entropies,returns): # 遍历相关信息序列
policy_loss += -log_prob * advantage - beta * entropy # 累积策略网络的损失函数,包括熵正则项
value_loss += F.mse_loss(value, returnss) # 累积值函数网络的损失函数,使用均方误差作为损失函数
# values=torch.tensor(values,requires_grad=True)
# value_loss=F.mse_loss(values,returns)
policy_optimizer.zero_grad() # 清空策略网络的梯度
policy_loss.backward() # 反向传播计算策略网络的梯度
policy_optimizer.step() # 更新策略网络的参数
value_optimizer.zero_grad() # 清空值函数网络的梯度
value_loss.backward() # 反向传播计算值函数网络的梯度
value_optimizer.step() # 更新值函数网络的参数
# 打印训练信息
print(f"Episode {i_episode}, Reward {total_reward}")
2、理论
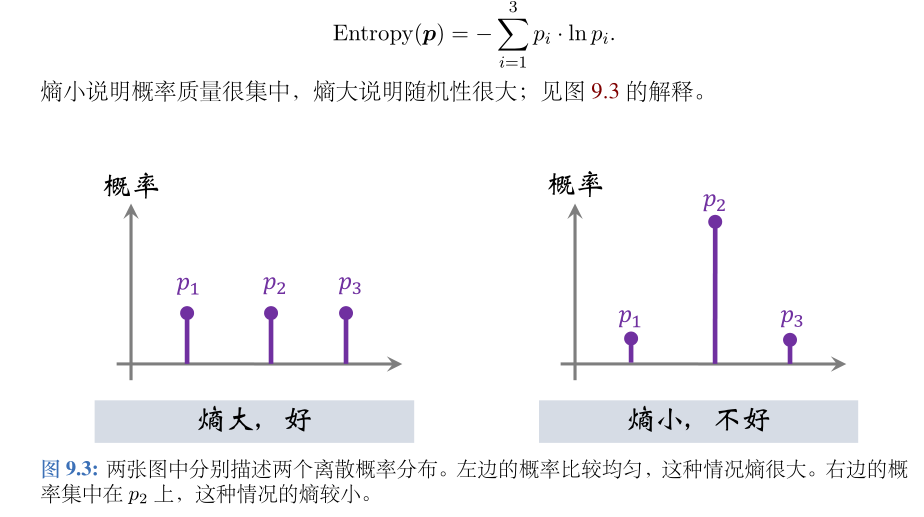
希望对于大多数的状态 s,熵都会比较大,也就是让
E
s
[
H
(
S
;
θ
)
]
Es[H(S;θ)]
Es[H(S;θ)] 比较大。

3、注意点
-
torch.multinomial()函数是用来从一个多项式概率分布中进行采样的,返回一个张量,其中每行包含从输入对应行中的概率分布中抽取的num_samples个样本的索引。这个函数可以用来实现随机采样、重采样、负采样等操作。你可以通过设置replacement参数来控制是否进行有放回或无放回的采样。
-
逆序的原因
for r in rewards[::-1]: # 逆序遍历奖励序列 R = r + gamma * R # 计算累积回报 returns.insert(0, R) # 插入到目标值函数序列的开头- 逆序遍历是为了计算累积回报,也就是从最后一个奖励开始,依次乘以折扣因子gamma并累加到前面的奖励上,得到每个状态的目标值。
- 这样做的原因是为了让目标值反映未来的奖励信息,而不仅仅是当前的奖励。逆序遍历可以方便地实现这个计算过程,而且可以节省空间和时间。
-
注意:代码中是减去:-log_prob * advantage - beta * entropy,而不是加上它们。这是因为优化器通常是用梯度下降法来最小化损失函数的,而我们的目标是最大化优势函数和熵,所以要用负号来转换一下。其中
- 第一项是最大化动作的优势函数,也就是让策略更倾向于选择那些比平均水平更好的动作。
- 第二项是最大化策略的熵,也就是让策略更多样化,避免过早收敛到局部最优或者陷入某些动作。















 9330
9330











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









