







 本文介绍了在强化学习中如何处理离散和连续动作的参数化动作空间,特别是H-PPO算法,它在PPO基础上扩展以适应混合动作空间。作者提供了Actor和Critic网络的代码实现,展示了离散和连续动作部分的处理方式以及训练过程。
本文介绍了在强化学习中如何处理离散和连续动作的参数化动作空间,特别是H-PPO算法,它在PPO基础上扩展以适应混合动作空间。作者提供了Actor和Critic网络的代码实现,展示了离散和连续动作部分的处理方式以及训练过程。
参考链接: 知乎
参数化动作空间
在强化学习中,参数化动作空间是指使用参数来表示和控制智能体可选取的动作的一种方法。在强化学习任务中,智能体通常需要选择一个动作来执行,以最大化其在环境中的累积奖励。
在离散动作空间中,每个动作通常由一个离散的标识符或索引表示。例如,一个智能体在一个格子世界中可以选择向上、向下、向左或向右移动,每个移动方向可以用一个整数(1、2、3、4)表示。这是一个离散动作空间的例子。
而在参数化动作空间中,动作被表示为一组连续的参数。这意味着动作的选择是通过一组实数或向量来表示的,而不是通过离散的标识符。例如,一个机器人在连续的动作空间中选择它的速度和方向,这两个参数可以是实数,表示机器人在每个时刻的线速度和角速度。
参数化动作空间通常出现在需要处理连续动作的问题中,其中动作的可能取值是一个连续的范围,而不是一个离散的集合。在这种情况下,使用参数化动作空间的方法可以更灵活地表示和控制动作,有助于应对连续性动作空间带来的挑战。
- 参数化动作空间说的就是一个离散动作带有一个向量化的参数。在每个决策步,一个智能体需要决策哪个动作去执行,并且这个动作带哪个参数去执行。
连续与离散动作HPPO:
PN-46: H-PPO for Hybrid Action Space (IJCAI 2019) - 黑猫紧张的文章 - 知乎

【论文阅读IJCAI-19】Hybrid Actor-Critic Reinforcement Learning in Parameterized Action Space - 海星的文章 - 知乎
policy gradient 和 PPO 都可以有效的同时处理离散的和连续的空间,文章选择了在PPO基础上提出H-PPO算法。
代码
直接先上代码:
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.distributions as distributions
from sklearn.utils import shuffle
from torch.distributions import Categorical
# Advantage Actor-Critic algorithm (A2C)
# Paper:
def gaussian_likelihood(x, mu, log_std):
pre_sum = -0.5 * (((x - mu) / (torch.exp(log_std) + 1e-8)).pow(2) + 2 * log_std + np.log(2 * np.pi))
likelihood = pre_sum.sum(dim=1).view(-1, 1)
return likelihood
class Actor(nn.Module):
def __init__(self, state_dim, discrete_action_dim, parameter_action_dim, max_action, ):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3_1 = nn.Linear(256, discrete_action_dim)
self.l3_2 = nn.Linear(256, parameter_action_dim)
self.max_action = max_action
self.log_std = nn.Parameter(torch.zeros([10, parameter_action_dim]).view(-1, parameter_action_dim))
def forward(self, x):
# 共享部分--这里的l1只有一个,同时用于离散的连续的动作;
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
# 离散
discrete_prob = F.softmax(self.l3_1(x),dim=1)
# 连续
mu = torch.tanh(self.l3_2(x))
log_std = self.log_std.sum(dim=0).view(1, -1) - 0.5
std = torch.exp(log_std)
return discrete_prob, mu, std, log_std
class Critic(nn.Module):
def __init__(self, state_dim):
super(Critic, self).__init__()
self.l1 = nn.Linear(state_dim, 256)
self.l2 = nn.Linear(256, 256)
self.l3 = nn.Linear(256, 1)
def forward(self, x):
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = self.l3(x)
return x
class PPO(object):
def __init__(self, state_dim, discrete_action_dim, parameter_action_dim, max_action, device,
clipping_ratio=0.2):
self.device = device
self.actor = Actor(state_dim, discrete_action_dim, parameter_action_dim, max_action).to(device)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=1e-4)
self.critic = Critic(state_dim).to(device)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=1e-3)
self.max_action = max_action
self.clipping_ratio = clipping_ratio
def select_action(self, state, is_test=False):
state = torch.FloatTensor(state.reshape(1, -1)).to(self.device)
with torch.no_grad():
discrete_prob, mu, std, log_std = self.actor(state)
# dist = distributions.Normal(mu, std)
# pi = dist.sample()
# 离散 softmax 然后在分布中选择
discrete_action = Categorical(discrete_prob)
discrete_action = discrete_action.sample().item()
# 连续 均值方差分布
# dist = distributions.Normal(mu, std)
# pi = dist.sample()
noise = torch.FloatTensor(np.random.normal(0, 1, size=(std.size()))).to(self.device)
pi = mu + noise * std
pi = pi.clamp(-1, 1)
parameter_action = pi * self.max_action
# print("parameter_action",parameter_action)
if is_test:
return discrete_prob.cpu().data.numpy().flatten(), discrete_action, parameter_action.cpu().data.numpy().flatten()
else:
logp = gaussian_likelihood(pi, mu, log_std)
return discrete_prob.cpu().data.numpy().flatten(), discrete_action, parameter_action.cpu().data.numpy().flatten(), pi.cpu().data.numpy().flatten(), logp.cpu().data.numpy().flatten()
# def calc_logp(self, state, action):
# state = torch.FloatTensor(state.reshape(1, -1)).to(self.device)
# discrete_prob, mu, std, log_std = self.actor(state)
# dist = distributions.Normal(mu, std)
# parameter_action_log_prob = dist.log_prob(action)
#
# return discrete_prob,parameter_action_log_prob
def get_value(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(self.device)
with torch.no_grad():
value = self.critic(state)
return value.cpu().data.numpy().squeeze(0)
def train(self, replay_buffer, batch_size=32, c_epoch=10, a_epoch=10):
obs_buf, discrete_act_buf, parameter_act_buf, adv_buf, ret_buf, discrete_logp_buf, parameter_logp_buf = replay_buffer.get()
c_loss_list, a_loss_list, discrete_a_loss_list, parameter_a_loss_list = [], [], [], []
for ce in range(c_epoch):
c_loss = self.update_v(obs_buf, ret_buf, batch_size=batch_size)
c_loss_list.append(c_loss)
obss = torch.FloatTensor(obs_buf).to(self.device)
discrete_act_buf = torch.FloatTensor(discrete_act_buf).to(self.device)
parameter_act_buf = torch.FloatTensor(parameter_act_buf).to(self.device)
advs = torch.FloatTensor(adv_buf).view(-1, 1).to(self.device)
discrete_logp_olds = torch.FloatTensor(discrete_logp_buf).view(-1, 1).to(self.device)
parameter_logp_olds = torch.FloatTensor(parameter_logp_buf).view(-1, 1).to(self.device)
for ae in range(a_epoch):
discrete_prob, mu, std, parameter_log_std = self.actor(obss)
# 离散
discrete_logp_t = discrete_prob.gather(1, discrete_act_buf.long())
discrete_ratio = torch.exp(discrete_logp_t - discrete_logp_olds)
# print("discrete_ratio",discrete_ratio)
discrete_L1 = discrete_ratio * advs
discrete_L2 = torch.clamp(discrete_ratio, 1 - self.clipping_ratio, 1 + self.clipping_ratio) * advs
discrete_a_loss = -torch.min(discrete_L1, discrete_L2).mean()
discrete_a_loss_list.append(discrete_a_loss.cpu().data.numpy())
# print("parameter_act_buf",parameter_act_buf)
# 连续
parameter_logp = gaussian_likelihood(parameter_act_buf, mu, parameter_log_std)
parameter_ratio = torch.exp(parameter_logp - parameter_logp_olds)
# print("parameter_ratio",parameter_ratio)
parameter_L1 = parameter_ratio * advs
parameter_L2 = torch.clamp(parameter_ratio, 1 - self.clipping_ratio, 1 + self.clipping_ratio) * advs
parameter_a_loss = -torch.min(parameter_L1, parameter_L2).mean()
parameter_a_loss_list.append(parameter_a_loss.cpu().data.numpy())
# loss 离散部分和连续部分相加
a_loss = discrete_a_loss + parameter_a_loss
# print("1111111",a_loss)
self.actor_optimizer.zero_grad()
a_loss.backward()
# nn.utils.clip_grad_norm_(self.actor_net.parameters(), self.max_grad_norm)
self.actor_optimizer.step()
a_loss_list.append(a_loss.cpu().data.numpy())
return sum(c_loss_list) / c_epoch, sum(a_loss_list) / a_epoch, sum(discrete_a_loss_list) / a_epoch, sum(
parameter_a_loss_list) / a_epoch
def update_v(self, x, y, batch_size):
""" Fit model to current data batch + previous data batch
Args:
x: features
y: target
logger: logger to save training loss and % explained variance
"""
num_batches = max(x.shape[0] // batch_size, 1)
batch_size = x.shape[0] // num_batches
x_train, y_train = shuffle(x, y)
losses = 0
for j in range(num_batches):
start = j * batch_size
end = (j + 1) * batch_size
b_x = torch.FloatTensor(x_train[start:end]).to(self.device)
b_y = torch.FloatTensor(y_train[start:end].reshape(-1, 1)).to(self.device)
v_loss = F.mse_loss(self.critic(b_x), b_y)
self.critic_optimizer.zero_grad()
v_loss.backward()
# nn.utils.clip_grad_norm_(self.critic_net.parameters(), self.max_grad_norm)
self.critic_optimizer.step()
losses += v_loss.cpu().data.numpy()
return losses / num_batches
def save(self, filename, directory):
torch.save(self.actor.state_dict(), '%s/%s_actor.pth' % (directory, filename))
torch.save(self.critic.state_dict(), '%s/%s_critic.pth' % (directory, filename))
def load(self, filename, directory):
self.actor.load_state_dict(torch.load('%s/%s_actor.pth' % (directory, filename)))
self.critic.load_state_dict(torch.load('%s/%s_critic.pth' % (directory, filename)))
网络结构
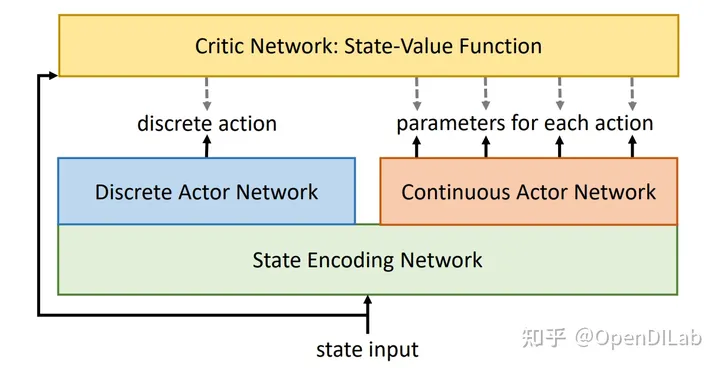
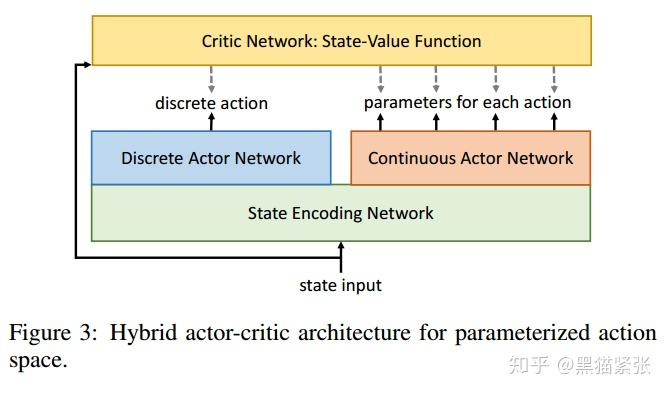
- H-PPO的网络结构中有两个 Actor 网络,分别是Discrete Actor Network和Continuous Actor Network,用于表示动作的离散和连续部分。对应代码:

注意,这里使用了共享前面MLP参数的方法,也可以不一样。 - 由于H-PPO有离散和连续两类 Actor,一般可以沿用PPO的更新公式,但关键区别在于——对不同的 Actor 计算各自独立的的重要性采样值,然后使用一个共同的 advantage 值来进行更新。


















 8222
8222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









