







卷积神经网络
1. 卷积神经网络
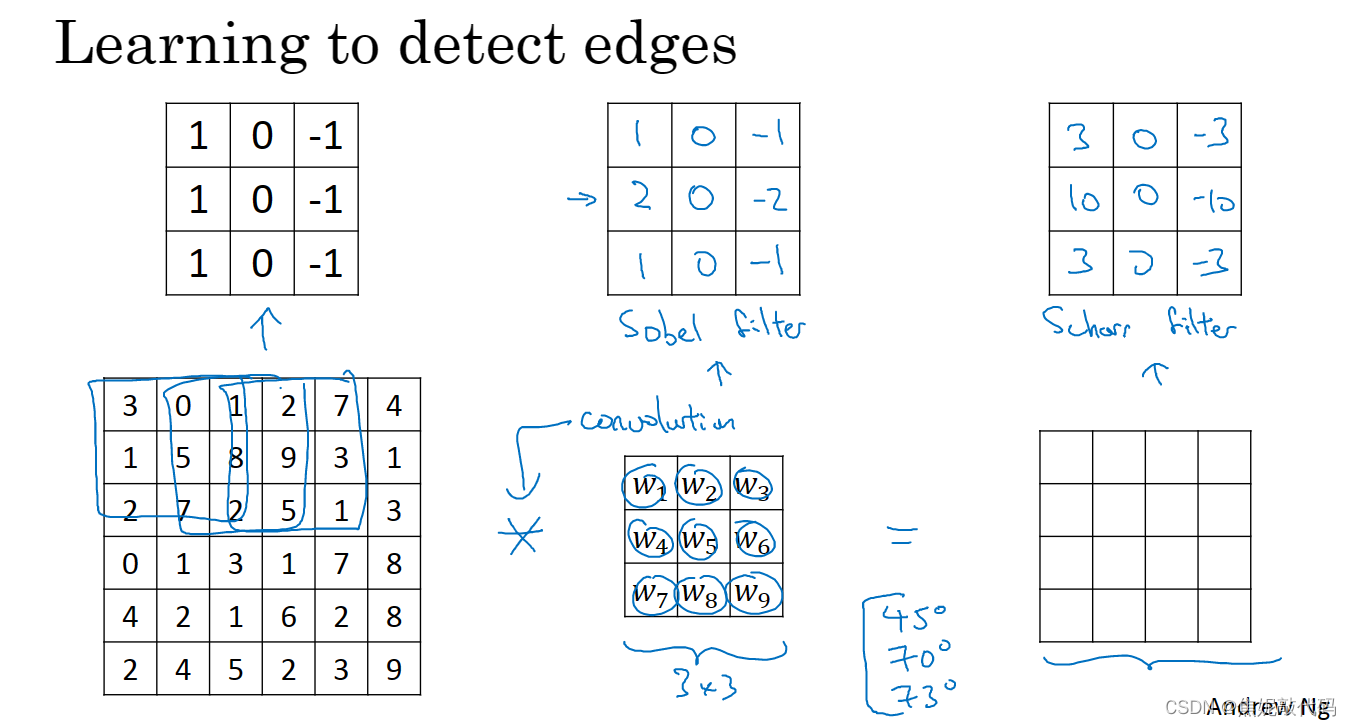
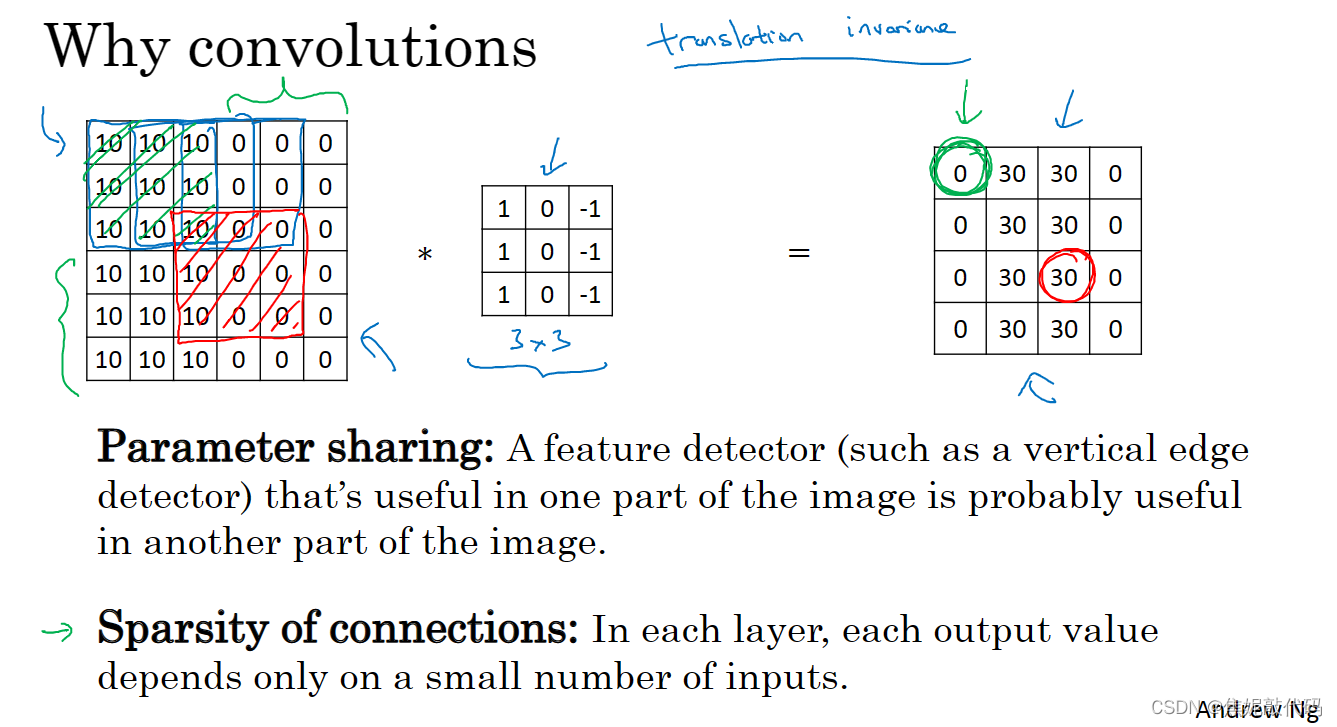
边缘检测示例

卷积运算是卷积神经网路最基本的组成部分。
这是一个6 x 6的灰度图像,是6 x 6 x 1的矩阵而不是6 x 6 x 3的(因为并没有RGB三通道)。为了检测图像中的垂直边缘,你可以构造一个3 x 3的矩阵(过滤器 或者 核)。对这个6 x 6的图像用3 x 3的过滤器对其进行卷积,这个卷积运算的输出将会是一个4 x 4的矩阵。
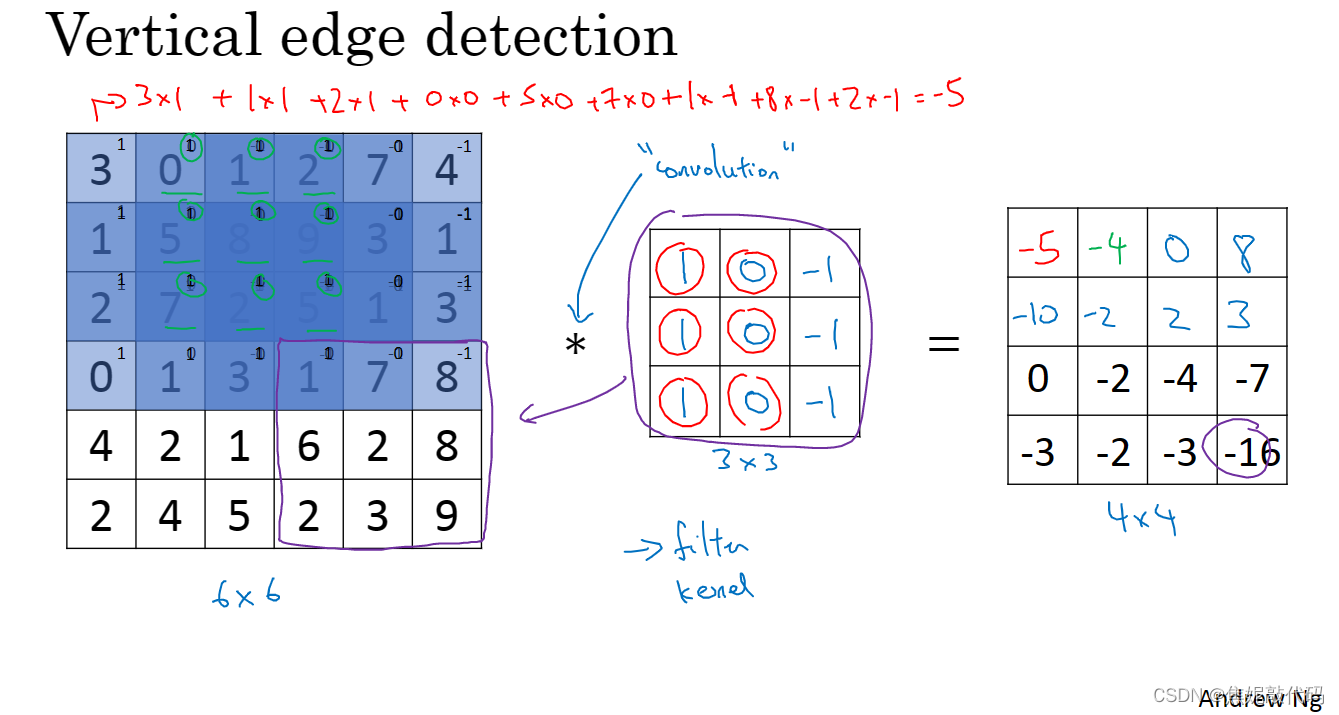
如下是垂直边缘检测器
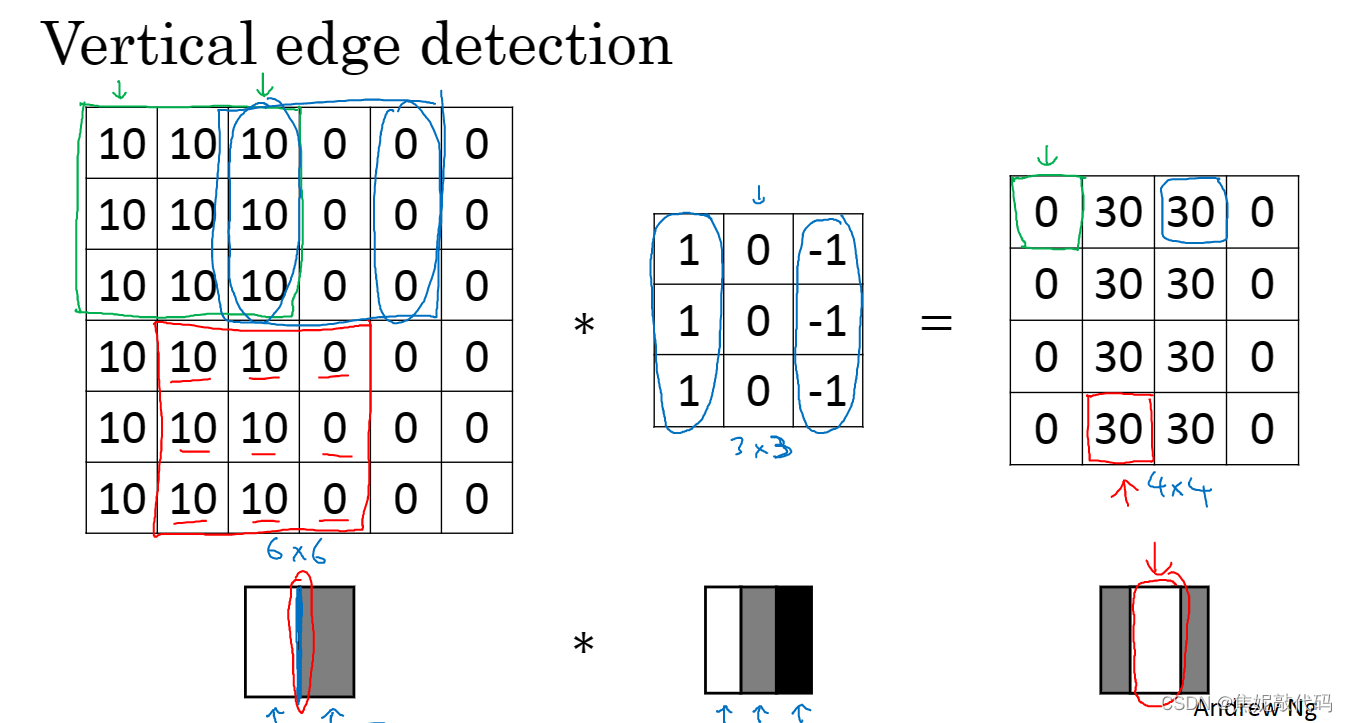
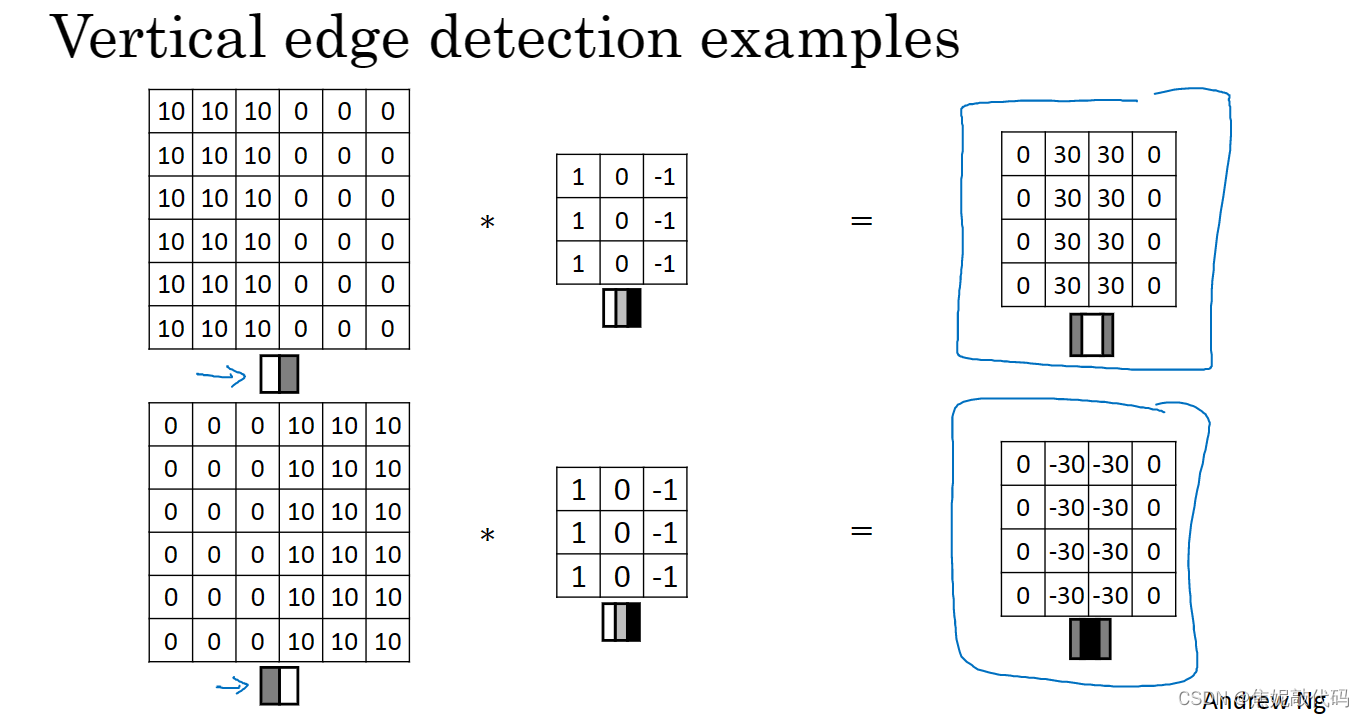
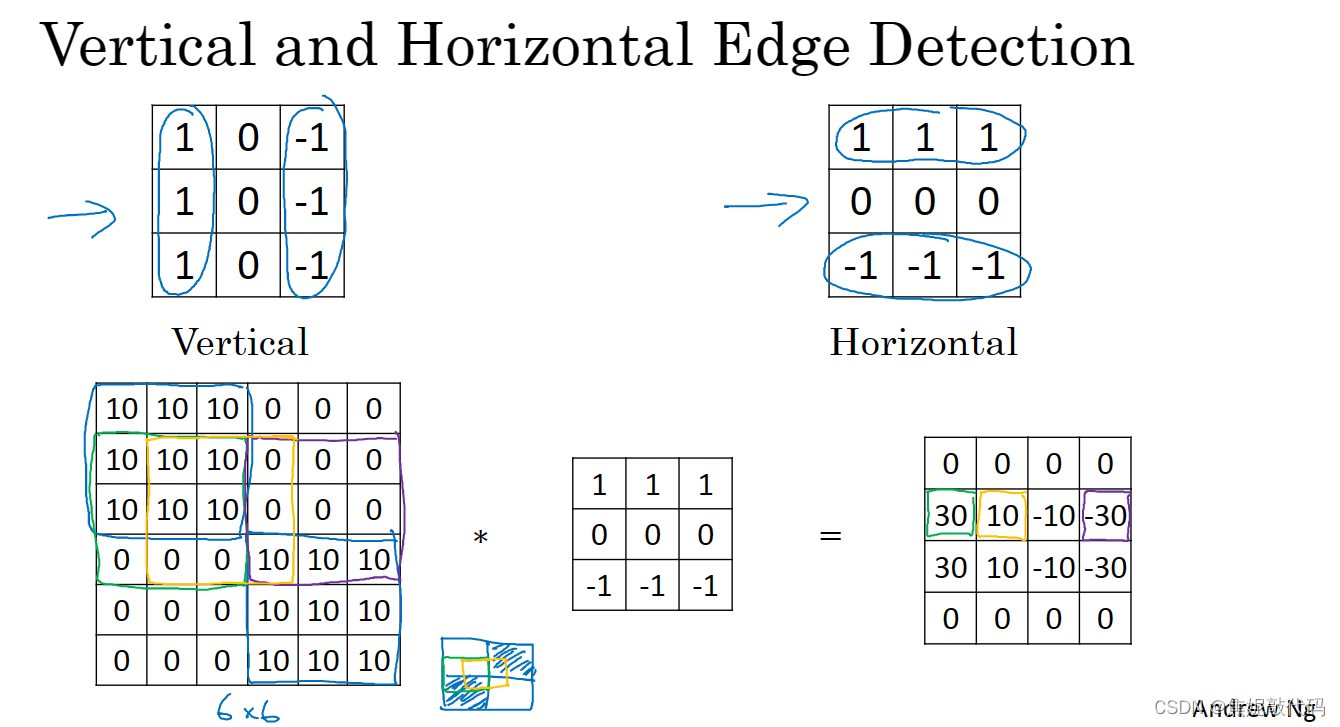
所以将矩阵的所有数字都设置成参数,通过数据反馈,让神经网络自动去学习它们。我们会发现神经网络可以学习一些低级的特征,例如这些边缘的特征。
Padding
如果我们有一个nxn的图像,用一个fxf的过滤器做卷积,那么输出结果的维度就是(n-f+1)x(n-f+1)。
这样的话会有两个缺点:
- 第一个缺点是每次做卷积操作,你的图像就会缩小。
- 第二个缺点是如果你注意角落边的像素,这个像素点只被一个输出所触碰或者说使用。所以那些在角落或者边缘区域的像素点在输出中采用较少,意味着你丢掉了图像边缘位置的许多信息
为了解决这些问题,你可以在卷积操作之前填充这幅图像。习惯上,你可以用0去填充,如果p是填充的数量,输出也就变成了(n+2p-f+1)x(n+2p-f+1)。
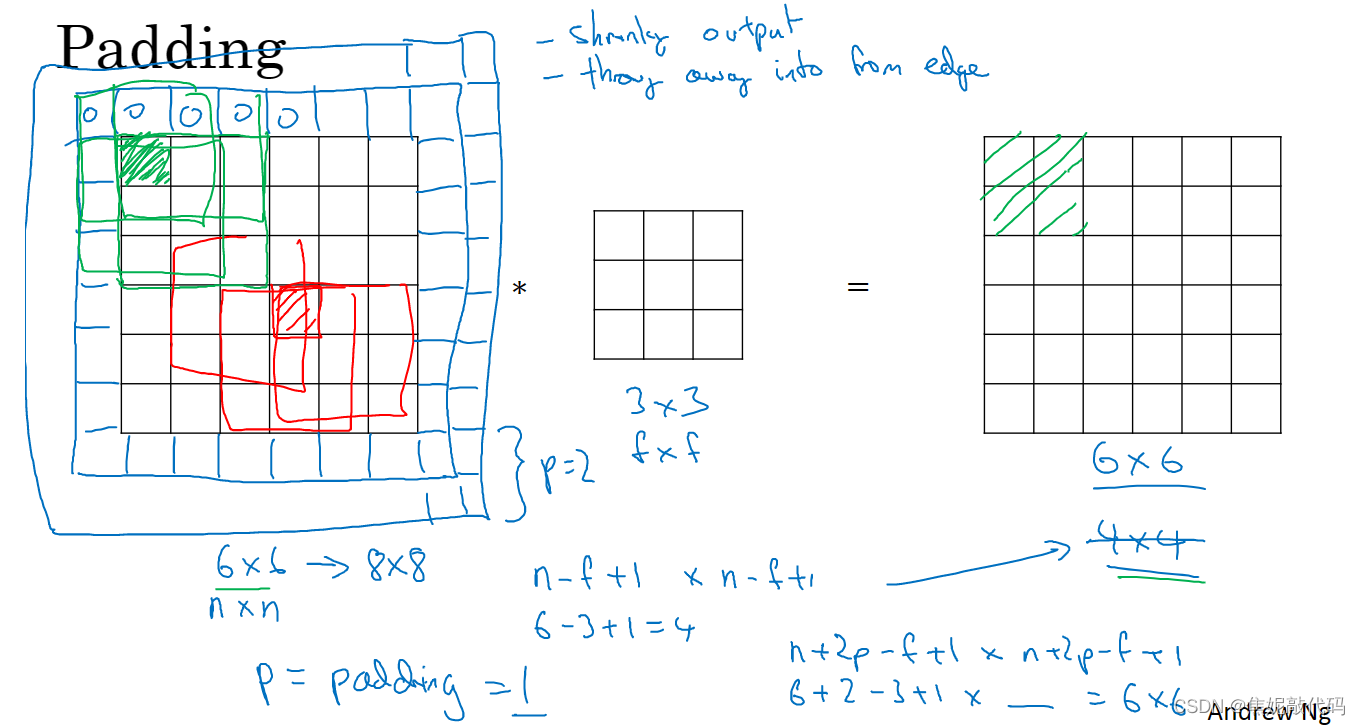
这样一来,丢失信息或者更准确来说角落或图像边缘的信息发挥的作用较小这一缺点 就被削弱了。
至于选择填充多少像素,通常有两个选择,分别叫做Valid卷积和Same卷积。Valid卷积意味着不填充。Same卷积意味着你填充后你的输出大小和输入大小是一样的,这时p的取值为p =(f-1)/2。

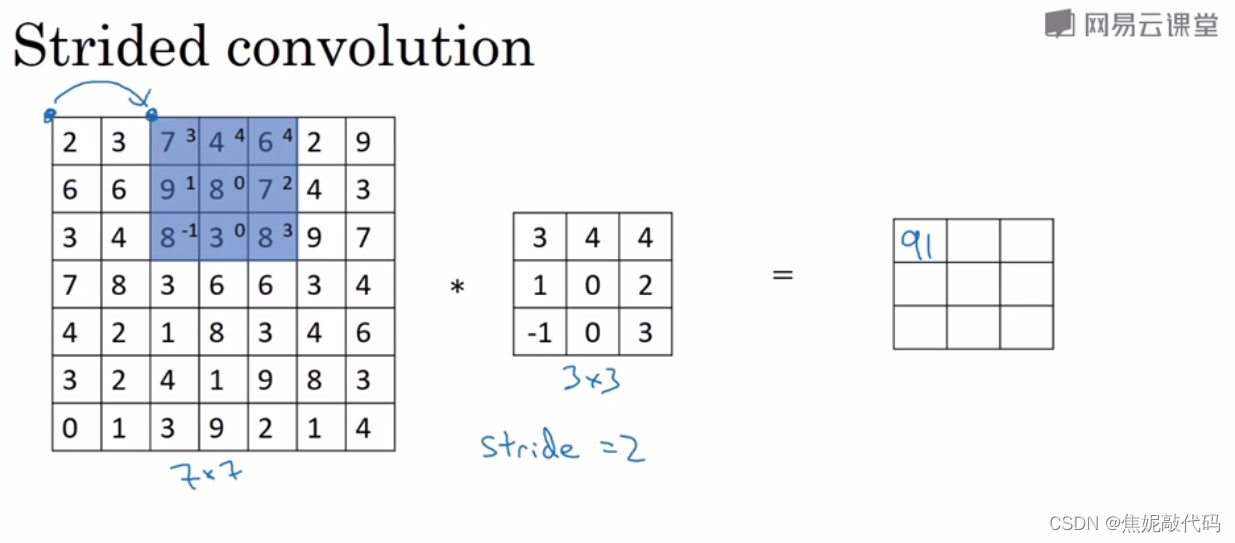
卷积步长
当我们把把步长设置成了2,你还是和之前一样取左上方的3x3区域的元素的乘积得到91,只是之前我们移动蓝框的步长是1,现在移动的步长是2,我们让过滤器跳过2个步长。
当你移动到下一行的时候,你也是使用步长2而不是步长1,所以我们将蓝框移动到这里
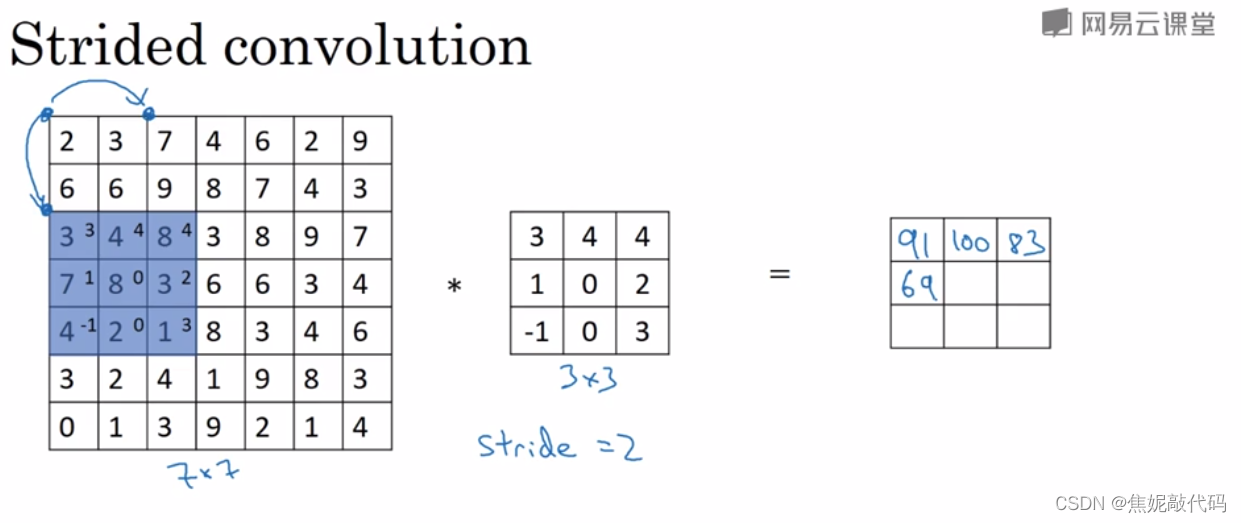
输入和输出的维度,是由以下的公式决定的:如果你用一个fxf的过滤器,卷积一个nxn的图像,你的 padding 为p,步幅为s,你会得到一个输出等于 (n+2p-f)/s +1 x (n+2p-f)/s + 1。如果商不是一个整数,在这种情况下我们向下取整。这个原则实现的方式是你只在蓝框完全包括在图像或填充完的图像内部时才对它进行运算,如果有任意一个蓝框移动到了外面,那么你就不要进行相乘操作。

三维卷积
如果彩色图像大小是6*6*3(高、宽 和通道),你可以把它想象成三个6*6的图像的堆叠。为了检测图像的边缘,可以使用一个3*3*3的三维过滤器,这个的输出会是一个4*4*1的图像,而不是4*4*3。图像的通道数必须和过滤器的通道数匹配。
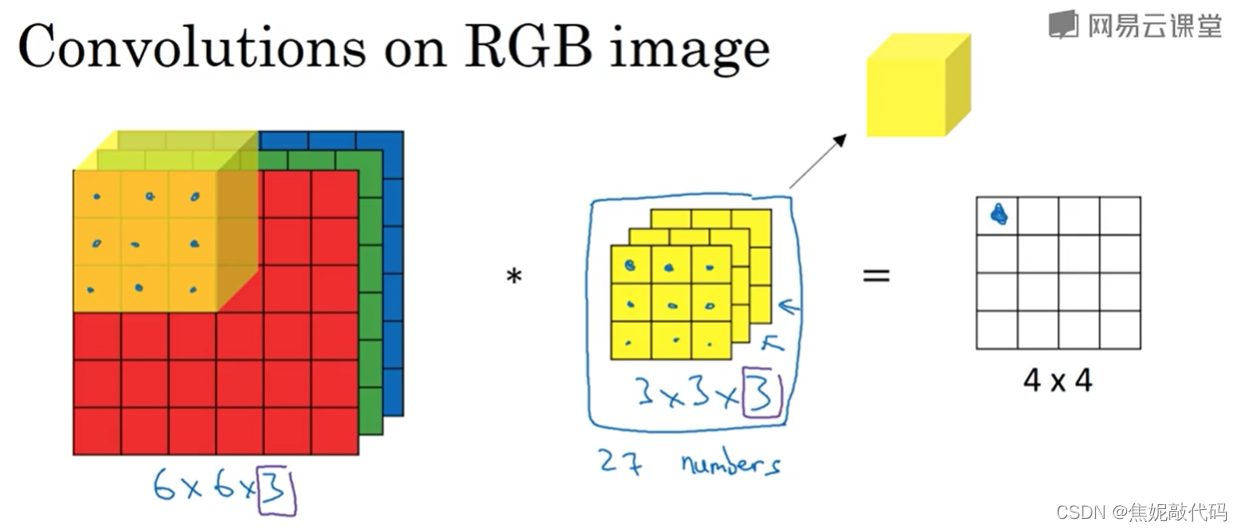
如果你有一个n*n*nc(nc为通道数)的输入图像,然后卷积上一个f*f*nc的过滤器,然后你就得到了(n-f+1)*(n-f+1)*m的输出,它就是你用的过滤器的个数。
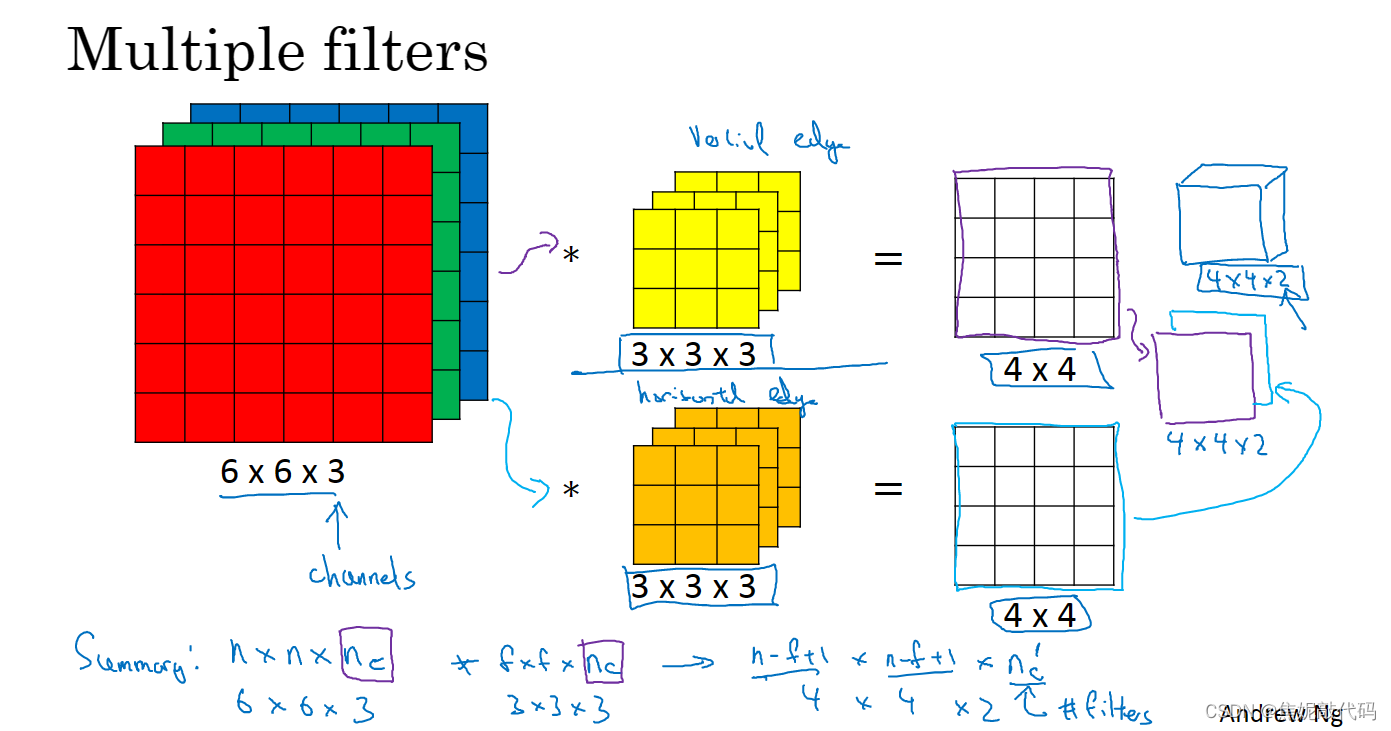
单层卷积网络
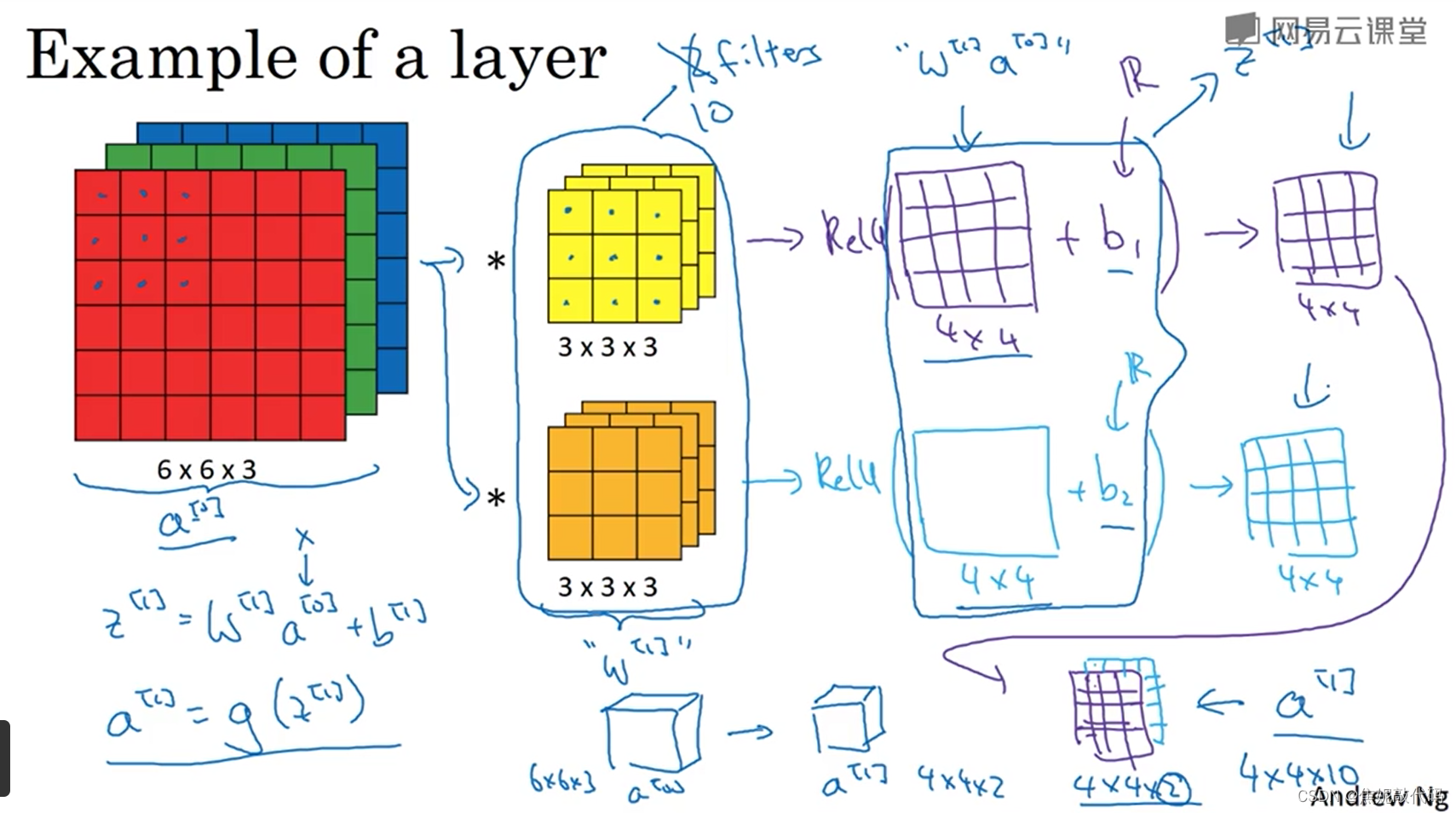

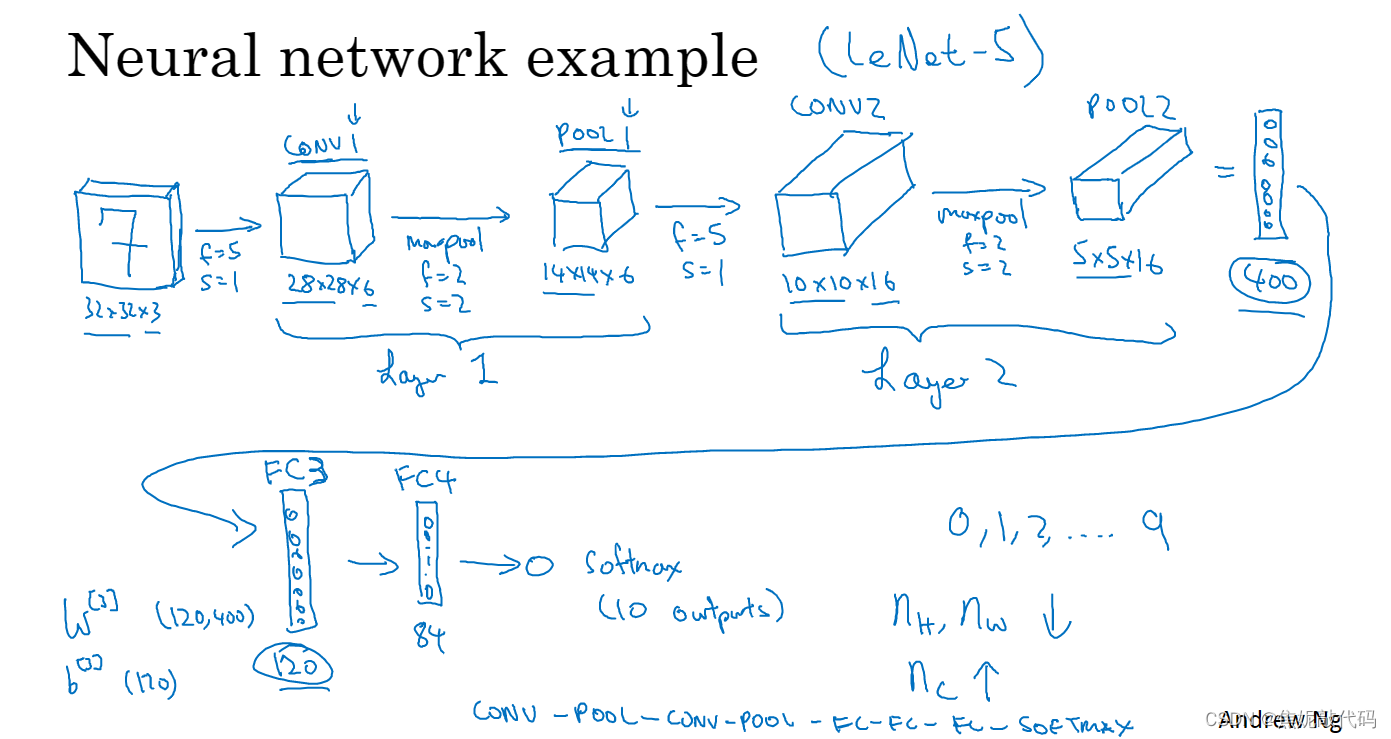
简单卷积网络示例
最后这一步是处理所有数字,即全部1960个数字把它们展开成一个很长的向量,然后填充到softmax回归函数中,最后得到结果。
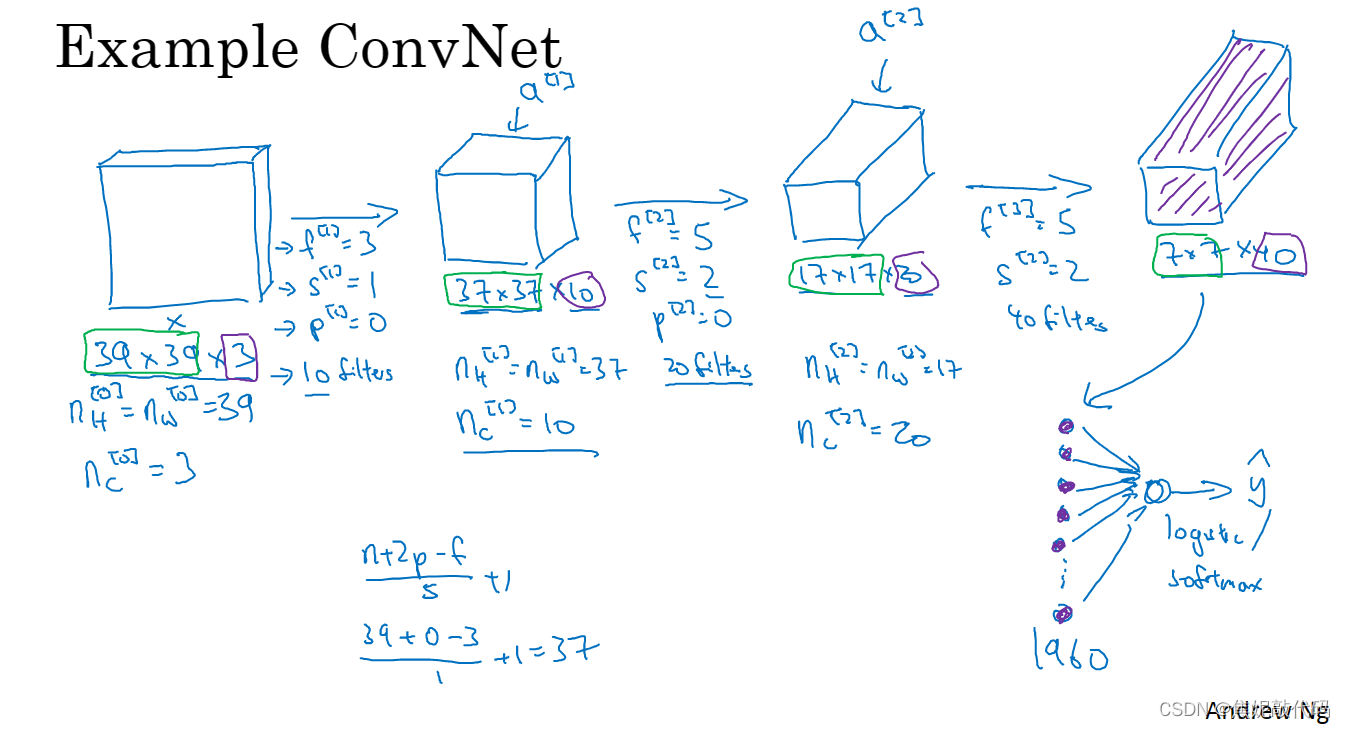
一个典型的卷积网络通常有三层,一个是卷积层(conv)、一个是池化层(pool)、最后一个是全连接层(FC)。

池化层
除了卷积层,卷积网络也经常使用池化层来缩减模型的大小、提高计算速度。
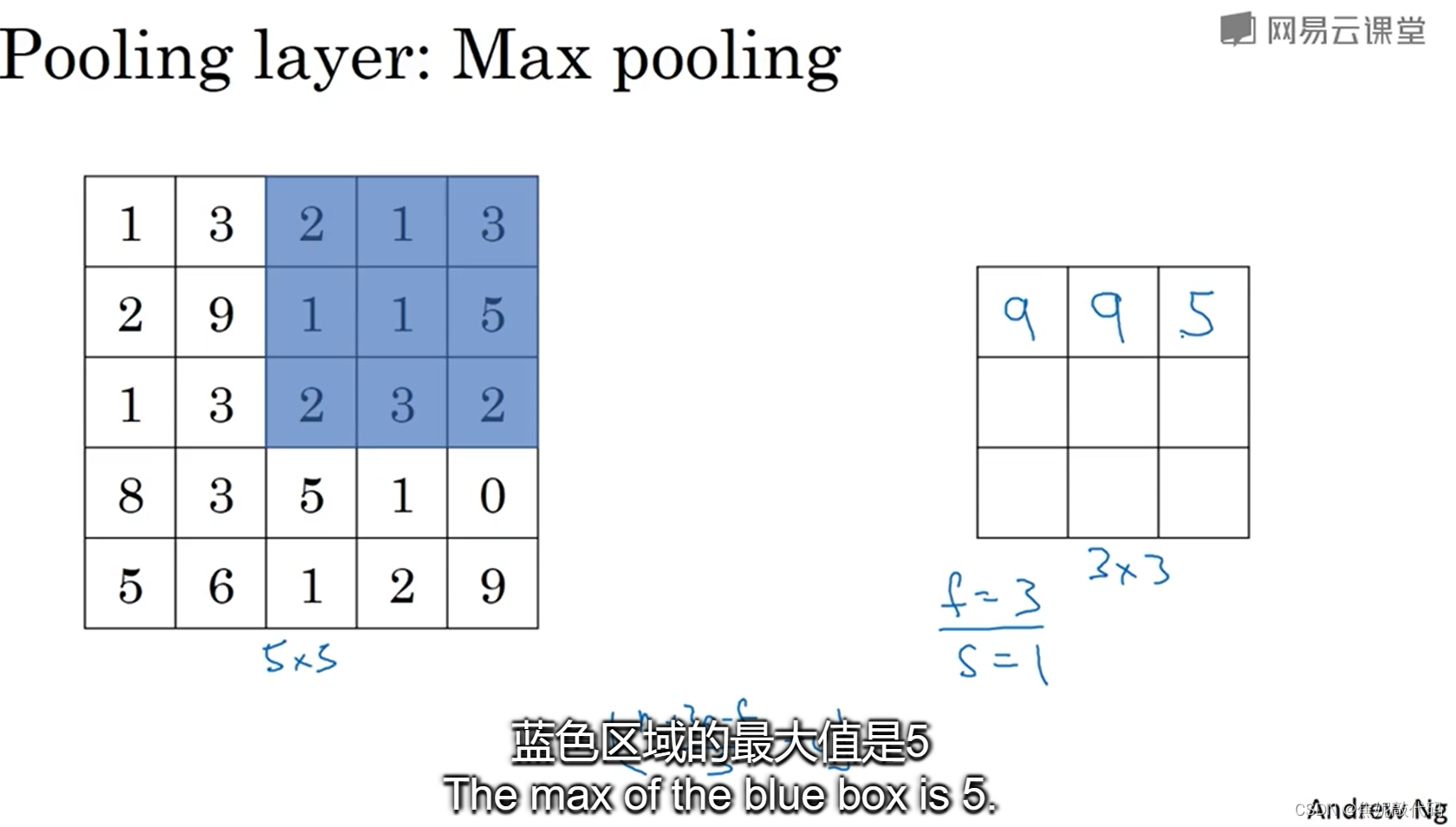
最大池化层中一个有意思的特点就是,它有一组超级参数,但是并没有参数需要学习。之前讲的计算卷积层输出大小的公式,同样适用于最大池化,即(n+2p-f)/s + 1。
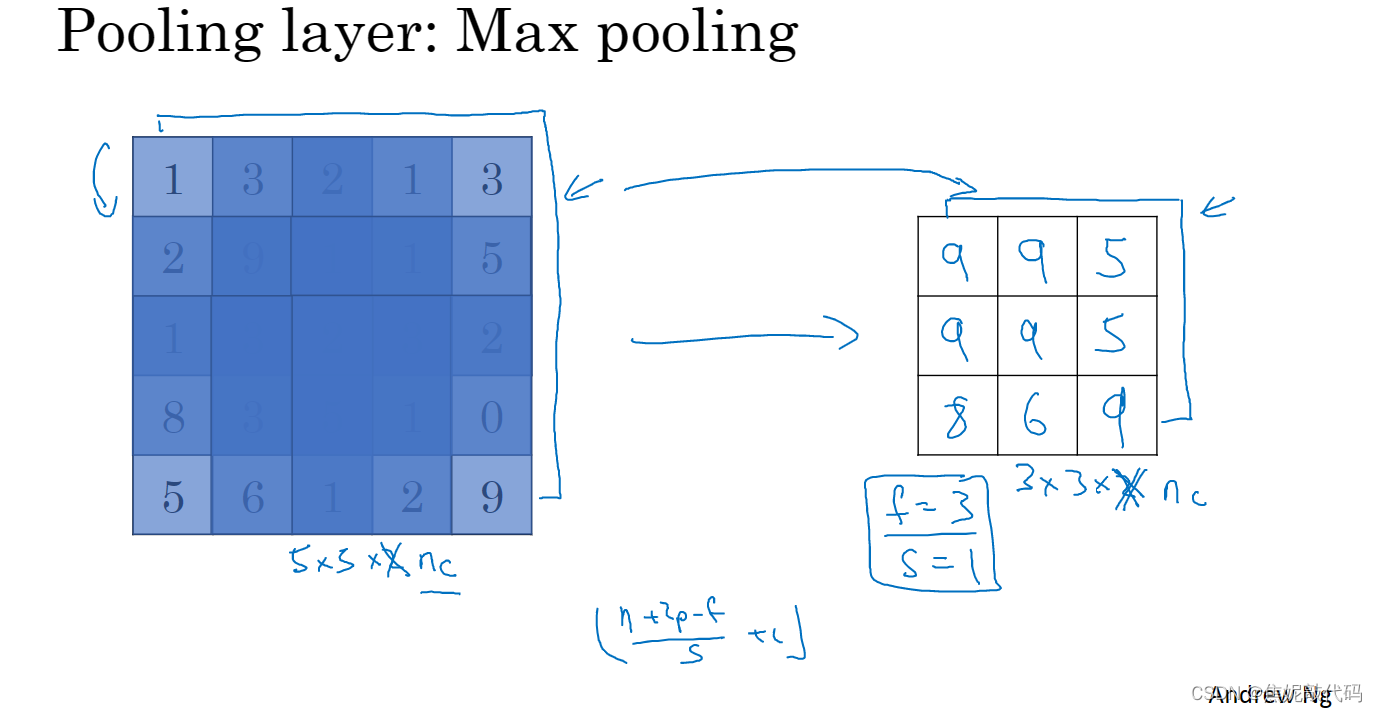
对于三维来说,输入是5x5x2 那么输出是3x3x2,计算最大池化的方法就是分别对每个信道执行刚刚的计算过程,最终输出的通道不会发生改变。如果输入是5x5xnc(信道数量),输出就是3x3xnc(信道数量)。
平均池化选取的不是每个过滤器的最大值而是平均值
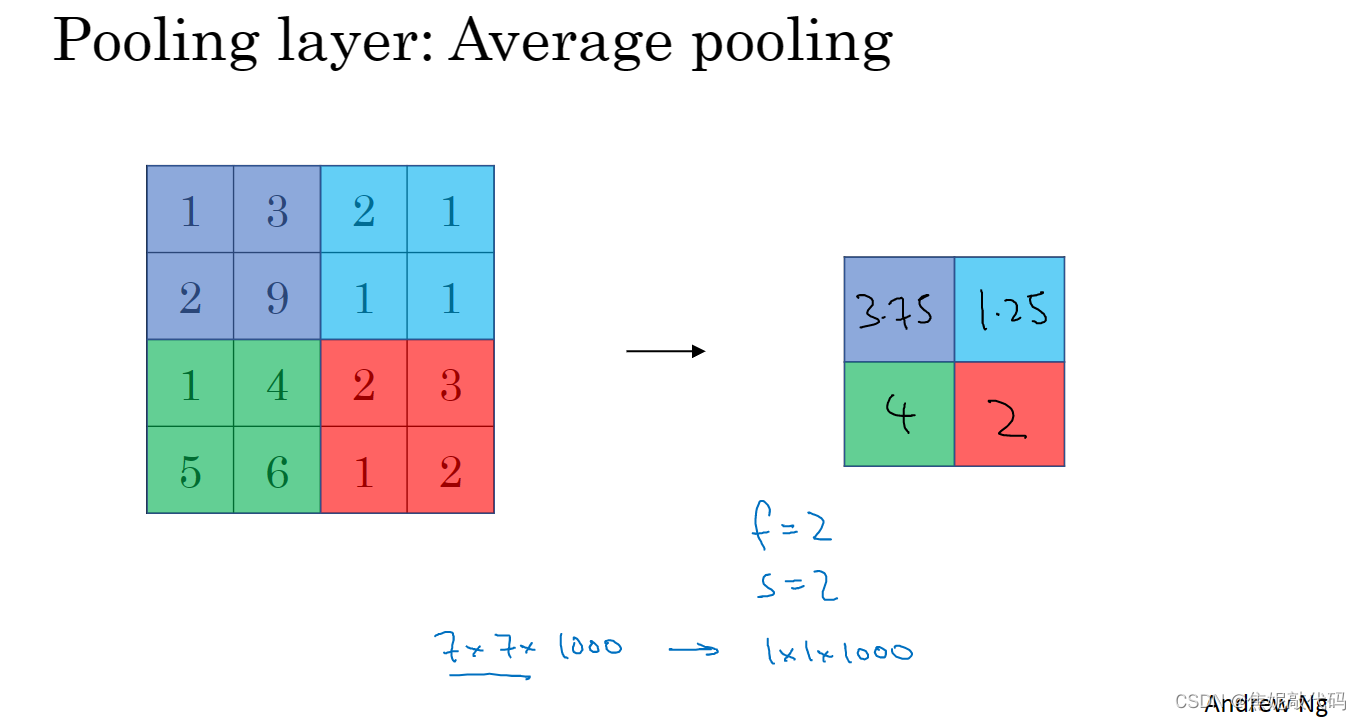
池化的超级参数包括过滤器大小f和步幅s,常用的参数值为f=2 s=2。池化过程中没有需要学习的参数。

卷积神经网络示例
卷积有两种分类,这与所谓层的划分存在一致性。一类卷积是一个卷积层和一个池化层一起作为一层,另一类卷积是把卷积层作为一层、而池化层单独作为一层。人们在计算神经网络有多少层时,通常只是统计具有权重和参数的层,因为池化层没有权重和参数,只有一些超级参数,这里我们把CONV1和POOL1共同作为一个卷积并标记为Layer1。
在卷积神经网络中,随着层数的增加,高度和宽度都会减小,而信道数量会增加。
在神经网络中,另一种常见模式就是一个或多个卷积层后面跟随一个池化层,然后一个或多个卷积层后面再跟一个池化层,然后是几个全连接层,最后是一个softmax。
和只用全连接层相比,卷积层的两个主要优势在于参数共享和稀疏连接。
比如,我们构建一个神经网络其中一层含有3072个单元,下一层含有4074个单元,两层中的每个神经元彼此相连,然后计算权重矩阵,它等于3072x4704约等于1400万,所以要训练的参数很多。我们再看看这个卷积层的参数数量,每个过滤器都是5x5,一个过滤器有25个参数再加上偏差参数,那么每个过滤器就有26个参数,一共有6个过滤器,所以参数共计156个。

卷积网络映射这么少参数有两个原因,一是参数共享,特征检测如垂直边缘检测如果适用于图片的某个区域那么它也可能适用于图片的其它区域,也就是说如果你用一个3x3的过滤器检测垂直边缘,那么图片的左上角区域以及旁边的各个区域都可以使用这个3x3的过滤器,每个特征检测器以及输出都可以在输入图片的不同区域中使用同样的参数以便提取垂直边缘或其它特征。它不仅适用于边缘特征这样的低阶特征,同样适用于高阶特征例如提取脸上的眼睛。
卷积网络减少参数的第二种方法是使用稀疏连接,这个0是通过3x3的卷积计算得到的,它只依赖于这个3x3的输入单元格,右边这个输出单元仅与36个输入特征中的9个相连接,而且其它像素值都不会对输出产生任何影响。
神经网络可以通过这两种机制减少参数,以便于我们用更小的训练集来训练它,从而预防过度拟合。
卷积神经网络善于捕捉平移不变,通过观察可以发现向右移动两个像素 图片中的猫依然清晰可见,因为神经网络的卷积结构,即使移动几个像素,这张图片依然具有非常相似的特征,应该属于同样的输出标记。
实际上,我们用同一个过滤器生成各层中图片的所有像素值,希望网络通过自动学习变得更加健壮,以便更好地取得所期望的平移不变属性。
所以训练神经网络你要做的就是使用梯度下降法,或其它算法例如含冲量的梯度下降,含RMSProp或其它因子的梯度下降来优化神经网络中的所有参数以减少代价函数J的值。
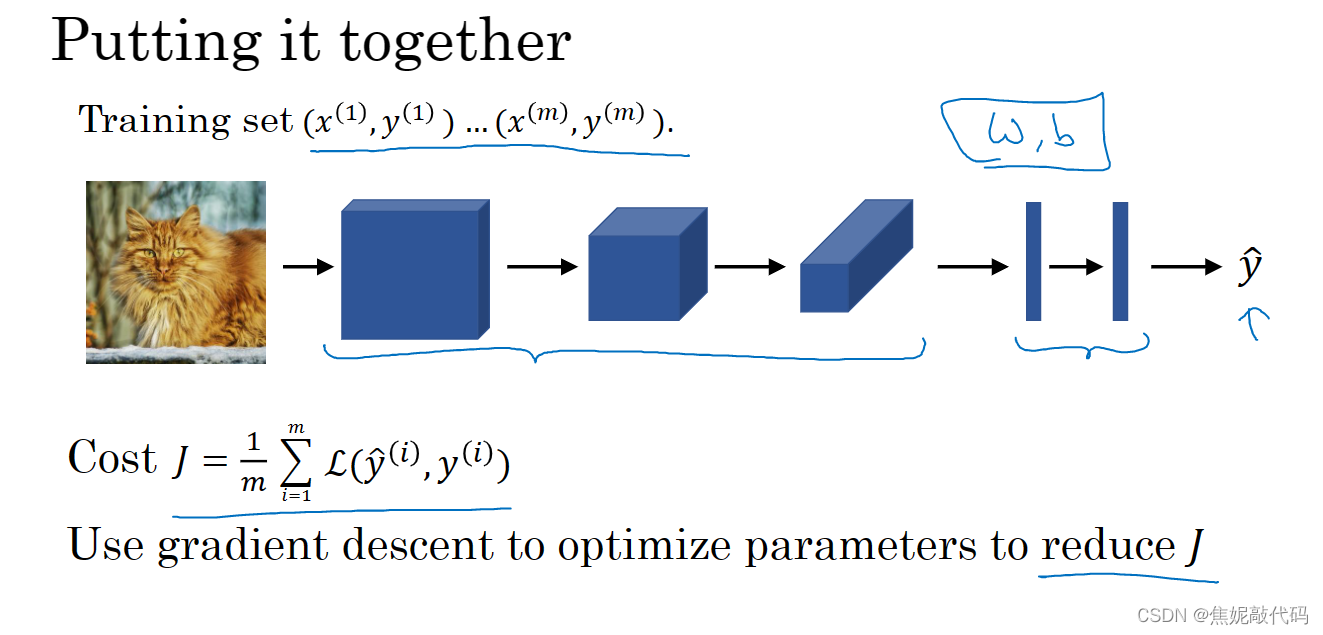
2. 深度卷积网络
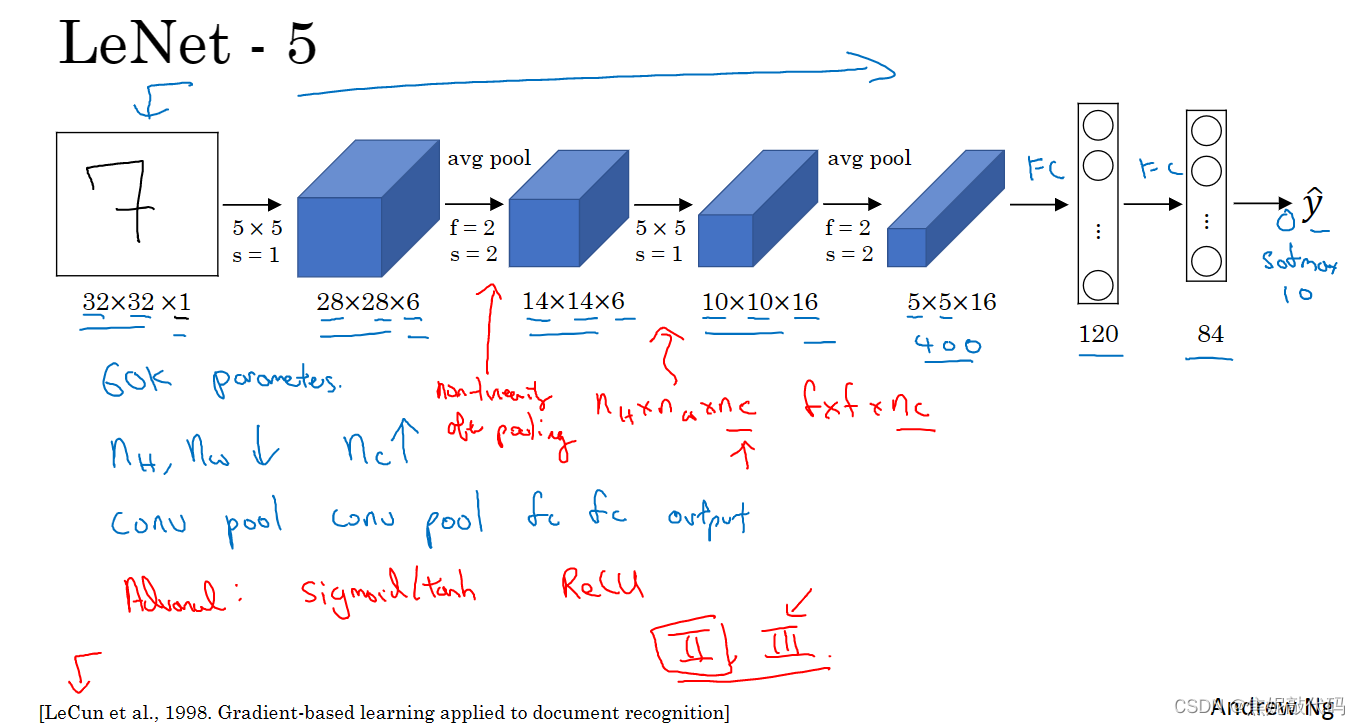
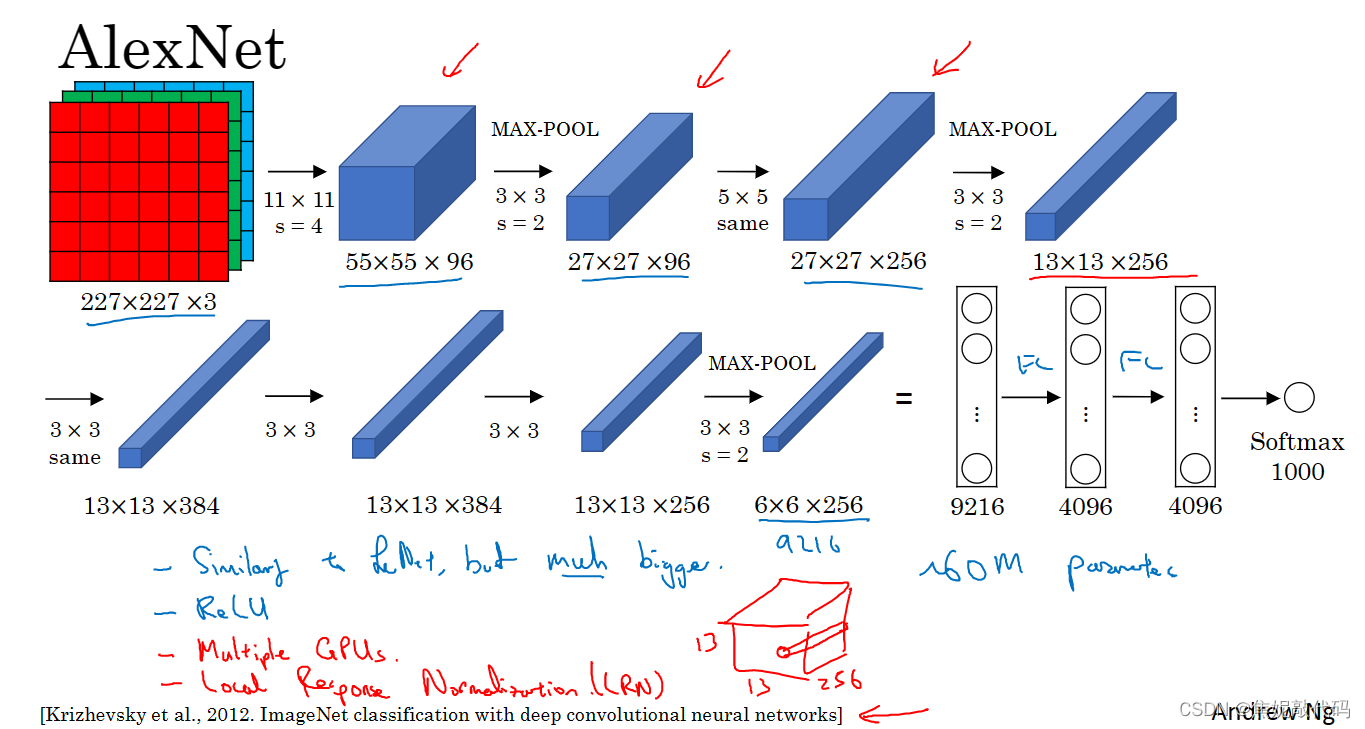
经典网络
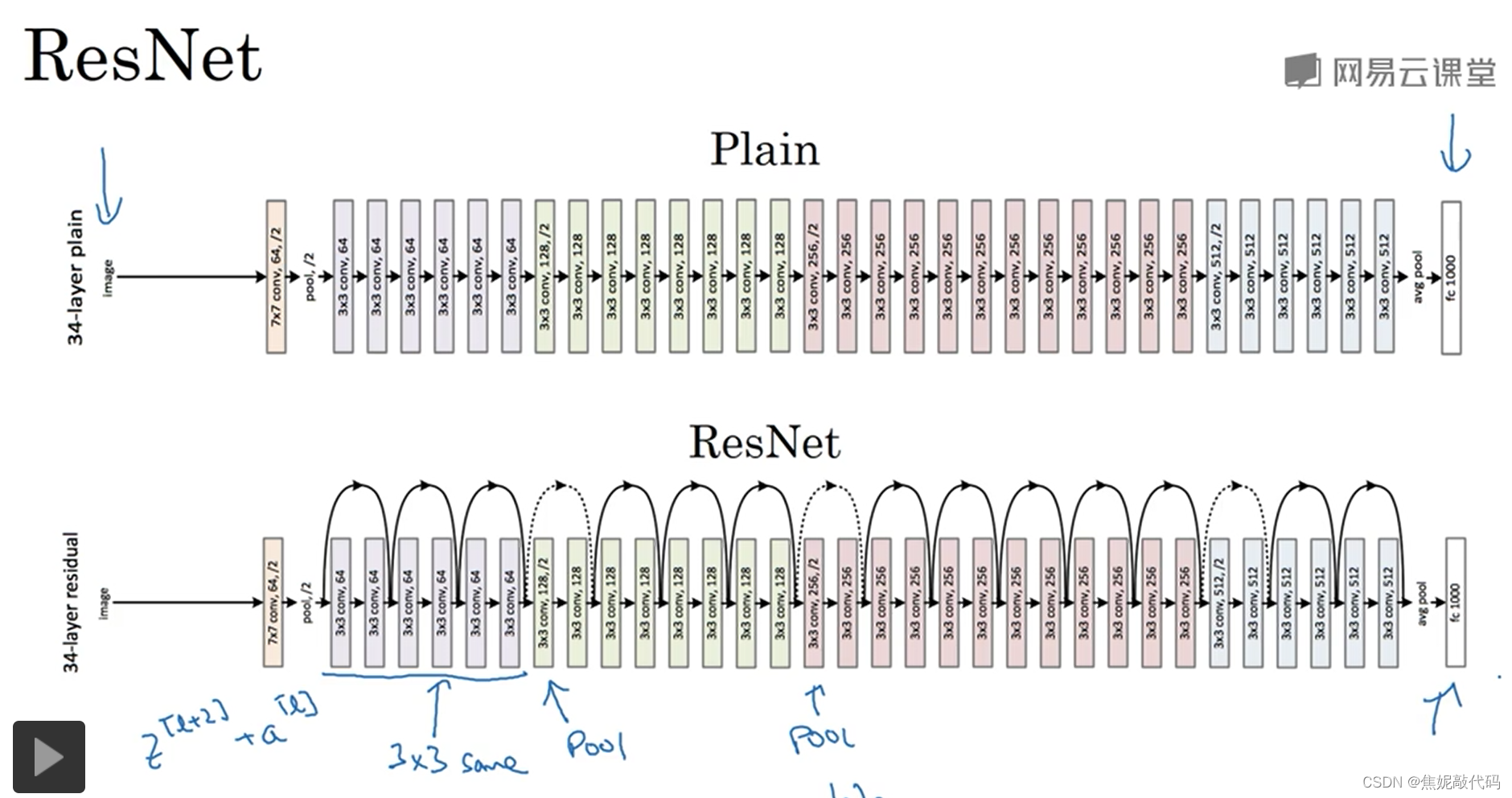
残差网络
非常非常深的网络是很难训练的,因为存在梯度消失和梯度爆炸问题。
跳远连接可从某一网络层获取激活,然后迅速反馈给另外一层甚至是神经网络的更深层。我们可以利用跳远连接构建能够训练深度网络的ResNets。
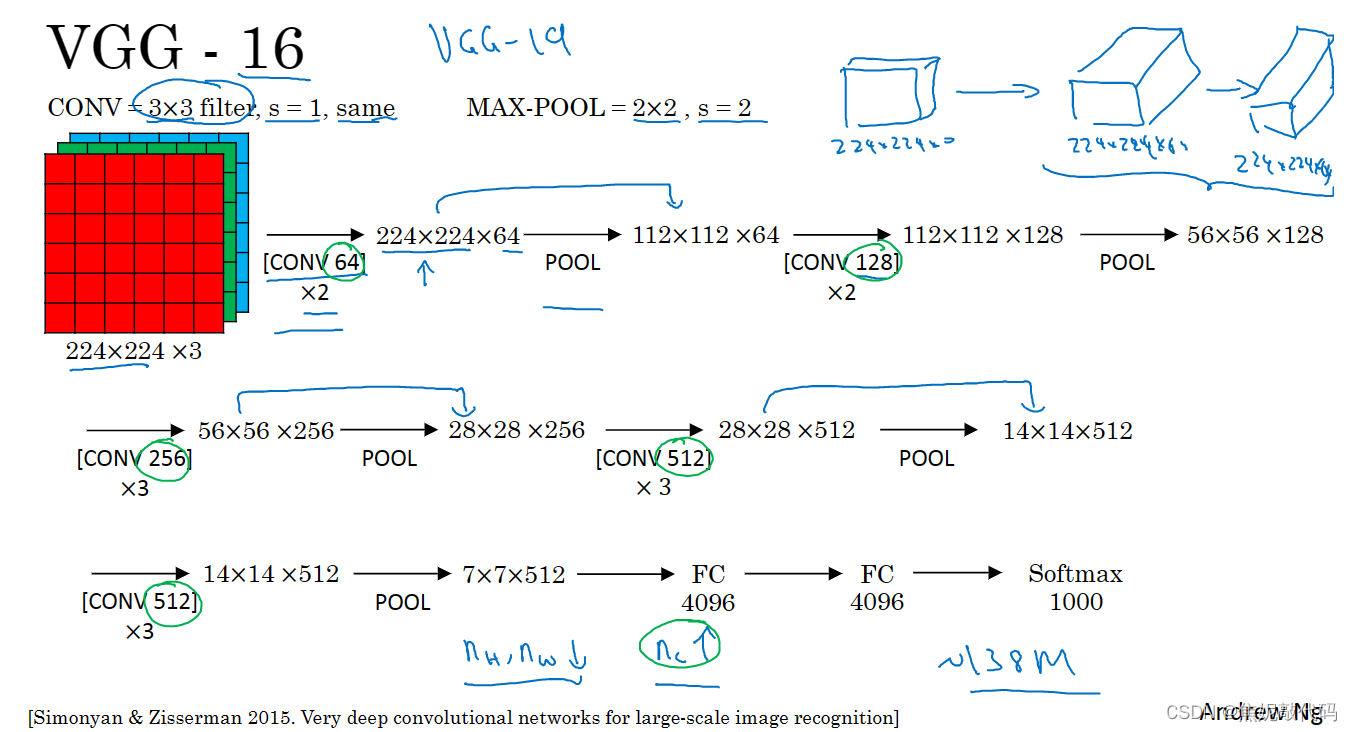
ResNets是由残差块构建的
这是一个两层神经网络在L层进行激活得到a[l+1] 再次进行激活之后得到a[l+2]。计算过程是从a[l]开始,首先进行线性激活,根据这个等式 通过a[l]算出z[l+1],然后通过ReLU非线性激活得到a[l+1],接着再次进行线性激活和ReLU非线性激活,得到的结果a[l+2]。换句话说,信息流从a[l]到a[l+2]需要经过以上所有步骤。在残差网络中有一点变化,我们将a[l]直接向后拷贝到神经网络的深层,在ReLU非线性激活前加上a[l],这是一条捷径即a[l]的信息直接到达神经网络的深层,不再沿着主路径传递,那么a[l+2]最终要加上这个a[l]产生的一个残差块(a[l]插入的时机是在线性激活之后 ReLU激活之前)。
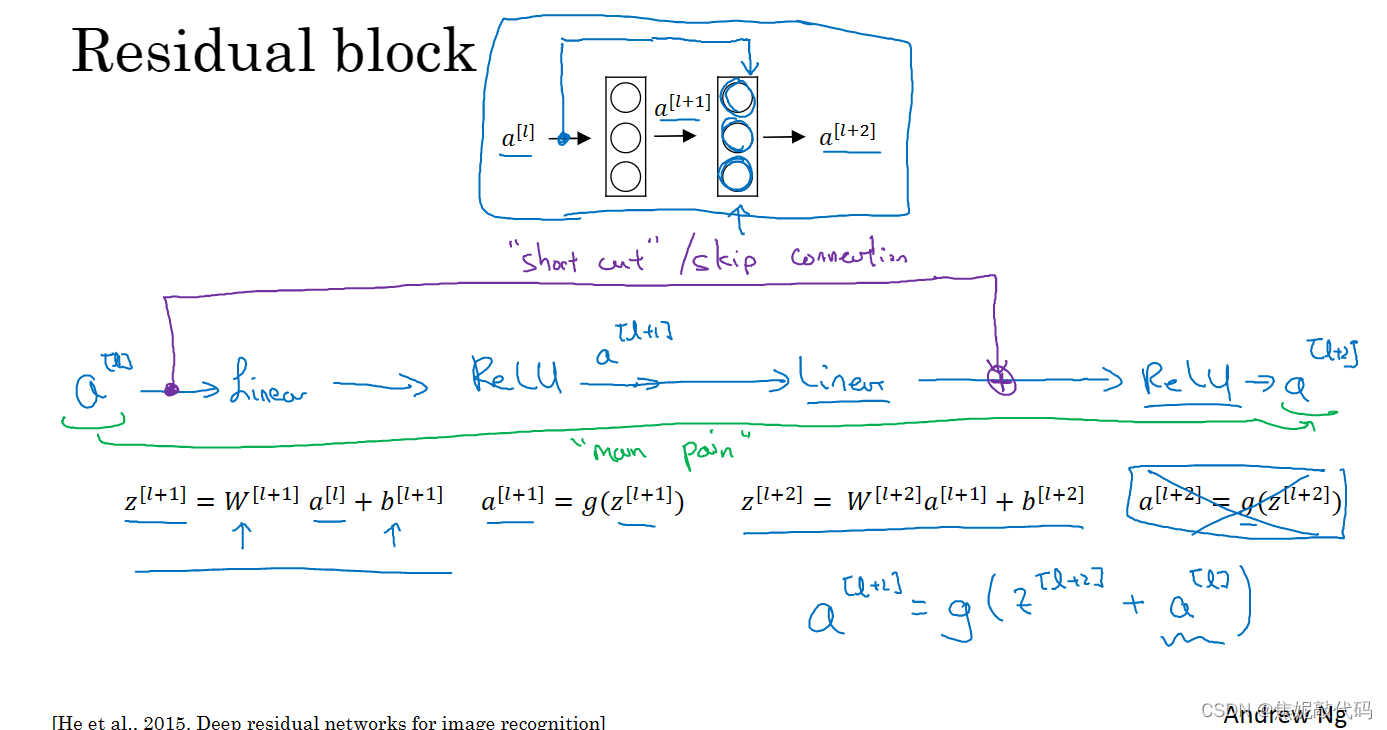
研究人员发现发现使用残差块能够训练更深的神经网络。所以构建一个ResNet网络就是通过将很多这样的残差块堆积在一起形成一个深度神经网络。
把它变成ResNet的方法是加上所有的跳远连接,每两层增加一个捷径,构成一个残差块,5个残差块连接在一起构成一个残差网络。
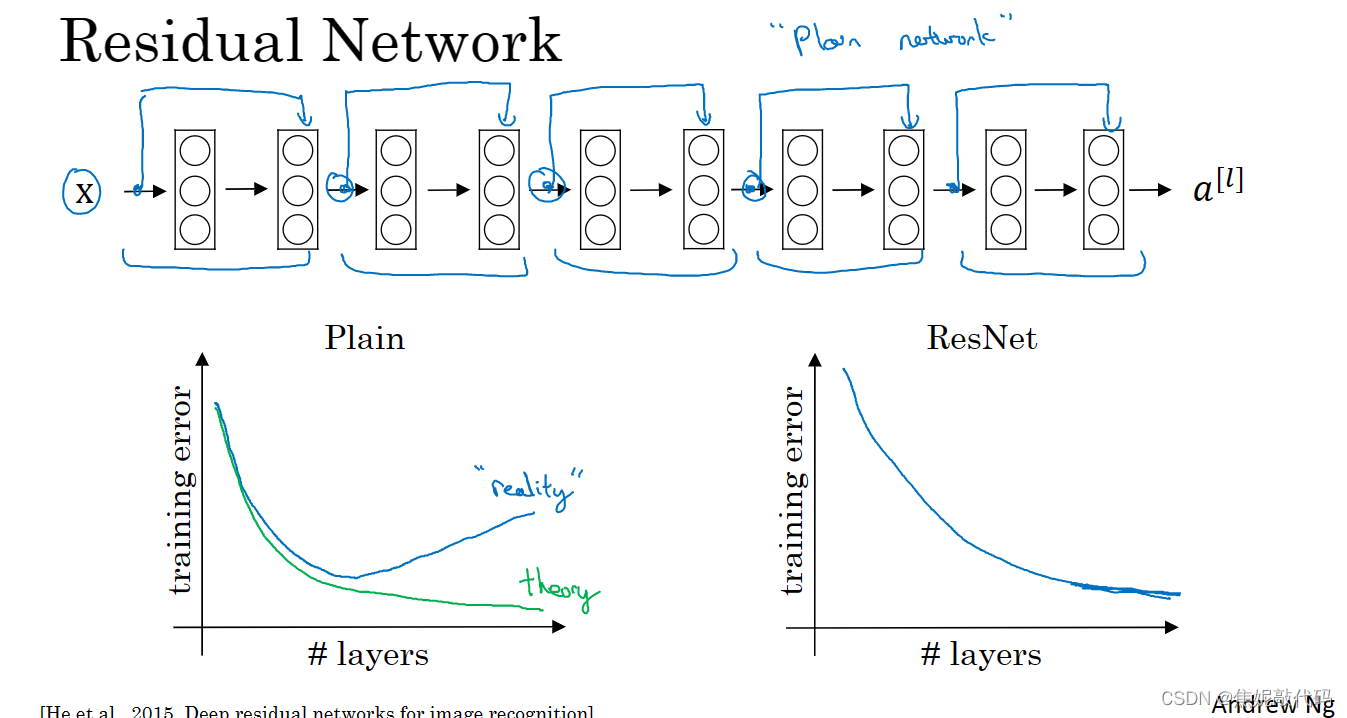
残差网络为什么有用
一般来说,一个网络深度越深它在训练集上训练网络的效率会有所减弱。在训练ResNet网络时并不完全如此。
残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,你能确定网络性能不会受到影响,很多时候甚至可以提高效率或者说至少不会降低网络效率,因此创建类似残差网络可以提升网络性能。
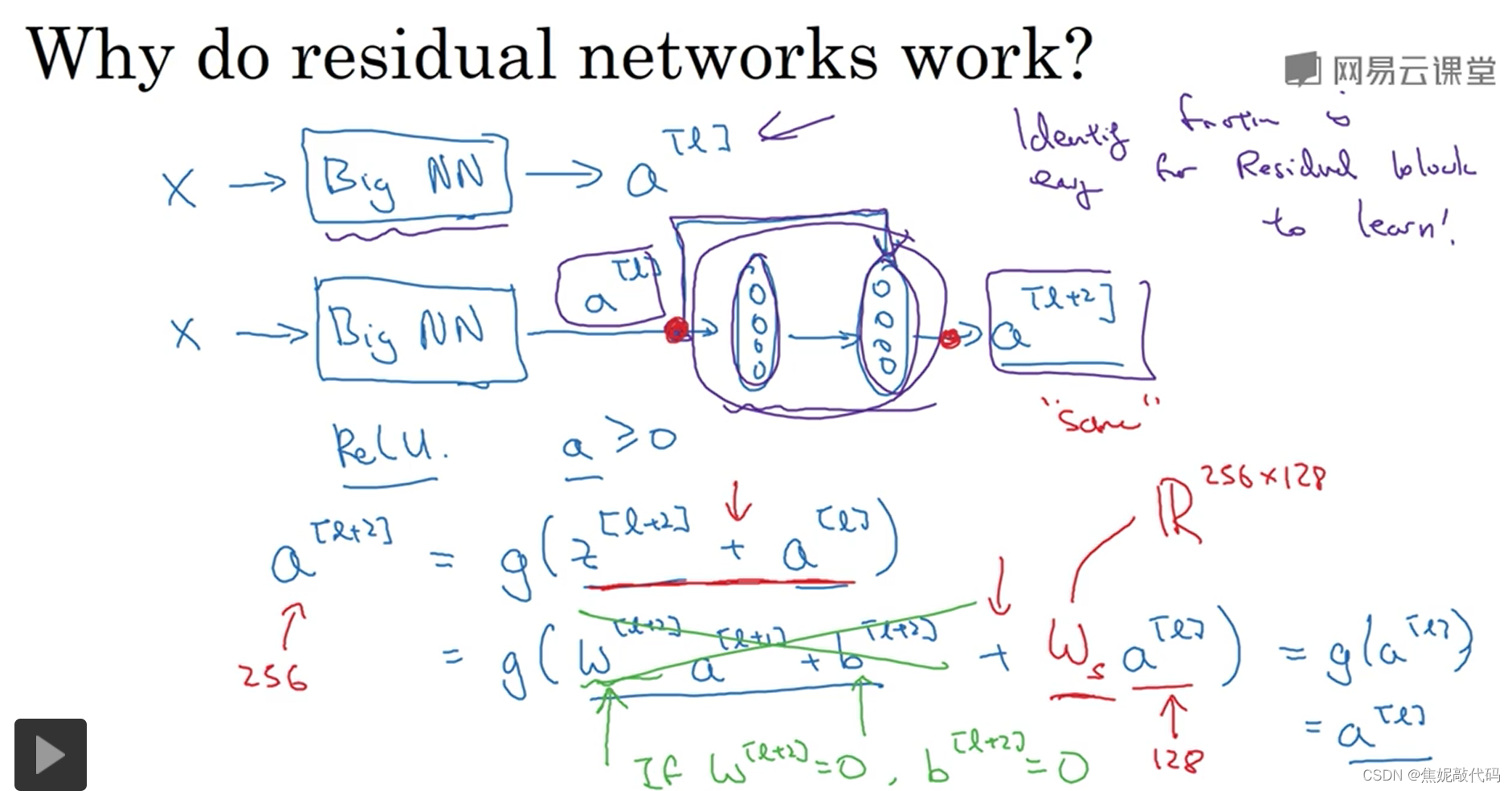
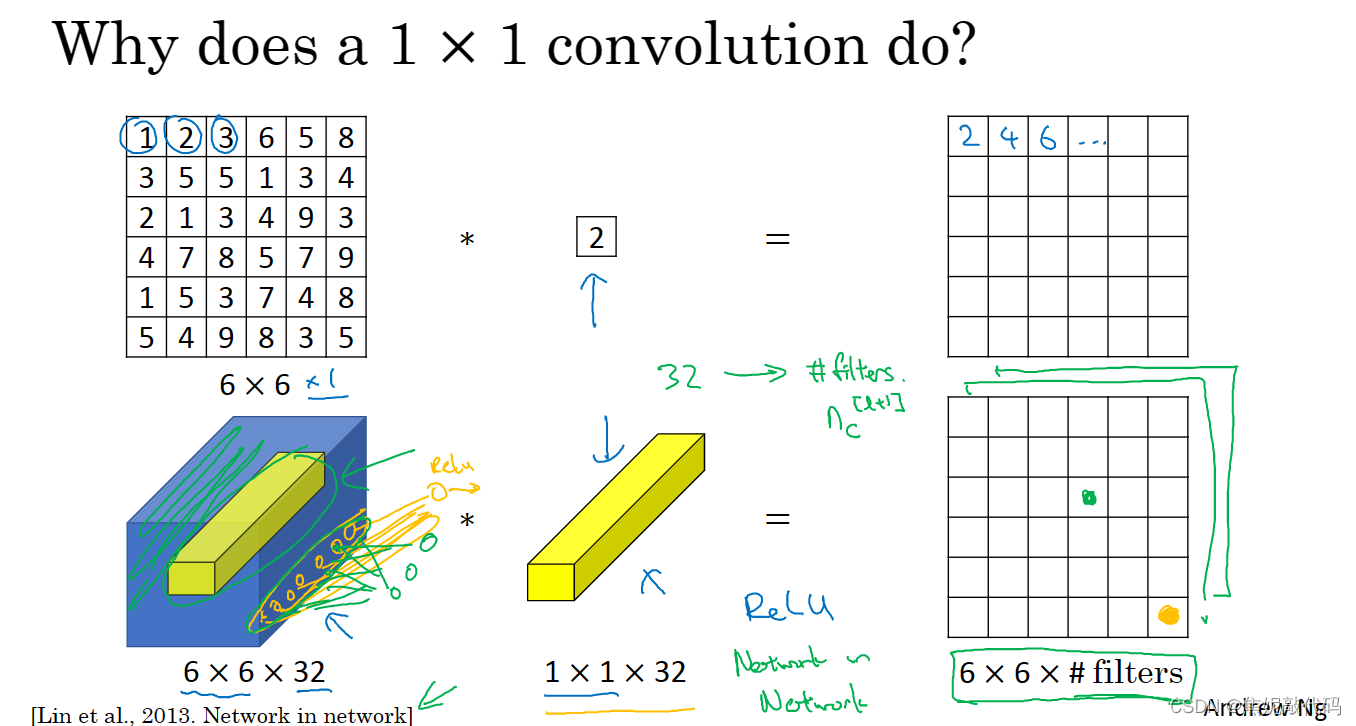
1 x 1 卷积
1x1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素智能乘积,然后应用ReLU非线性函数。
我们以其中一个单元格为例,它是这个输入层上的某个切片,用这32个数字乘以这个输入层上1x1的切片得到一个实数。这个1x1x32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字乘以相同高度和宽度上某个切片上的32个数字,这32个数字具有不同信道,乘以32个权重 然后应用ReLU非线性函数,在这里输出相应的结果。
一般来说,如果过滤器不止一个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6x6x过滤器数量。
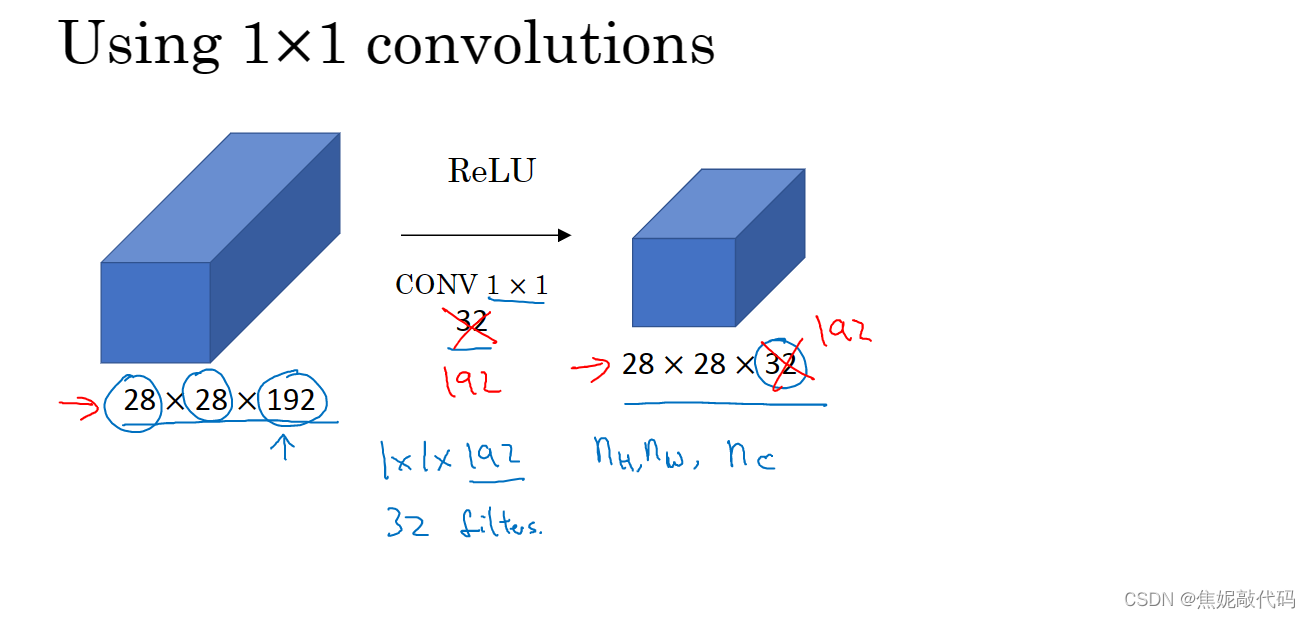
如果信道数量很大,我们可以通过1 x 1 卷积压缩其通道量。
谷歌Inception 网络介绍
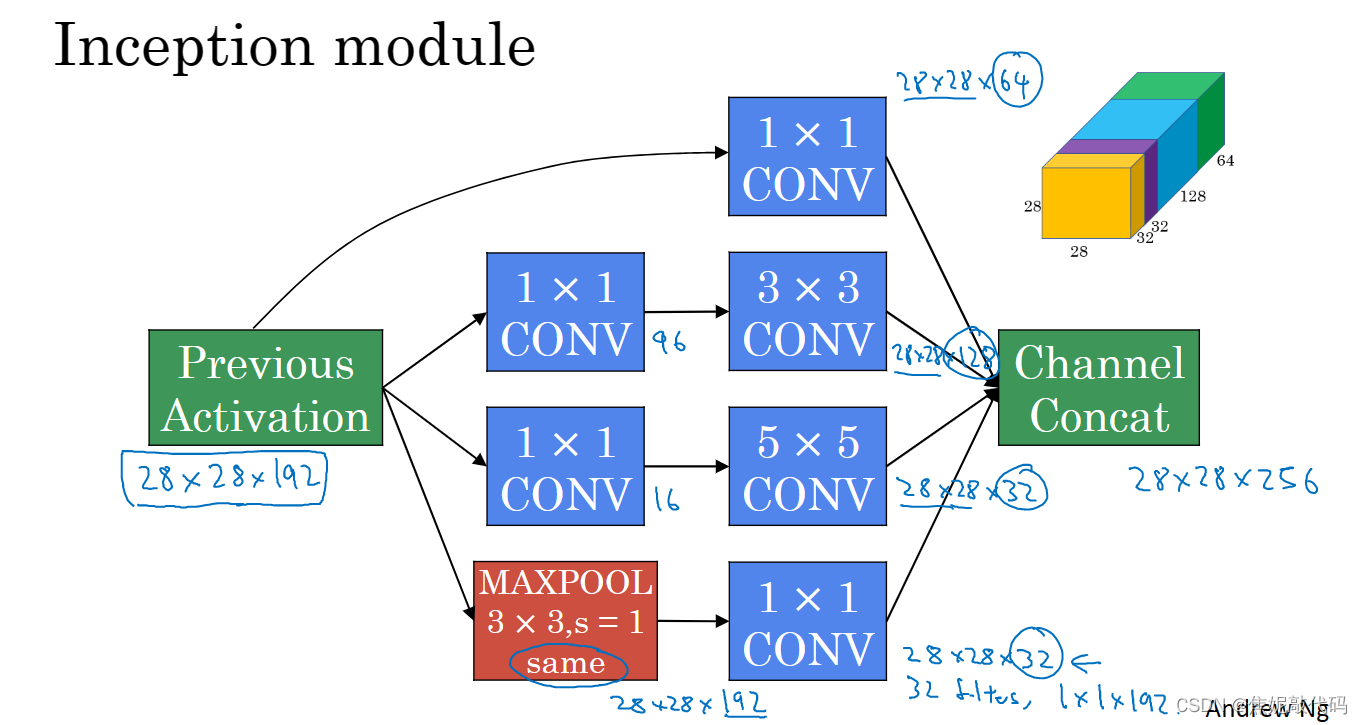
这是28x28x192维度的输入层,Inception网络或Inception层的作用就是代替人工来确定卷积层中的过滤器类型或者确定是否需要创建卷积层或池化层。
基本思想是Inception网络不需要人为决定使用哪个过滤器或是否需要池化,而是由网络自行确定这些参数,你可以给网络添加这些参数的所有可能值然后把这些输出连接起来,让网络自己学习它需要什么样的参数,采用哪些过滤器组合。
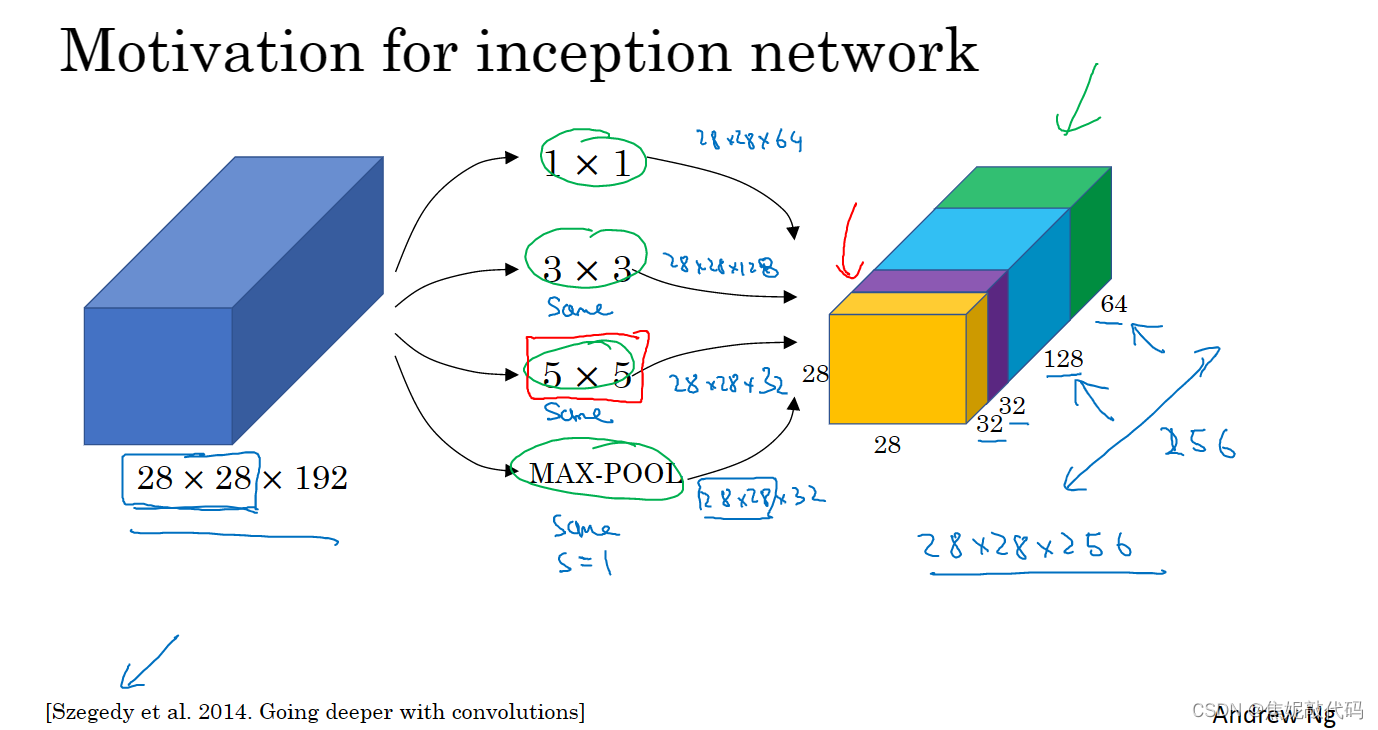
我所描述的Incetption层有一个问题就是计算代成本
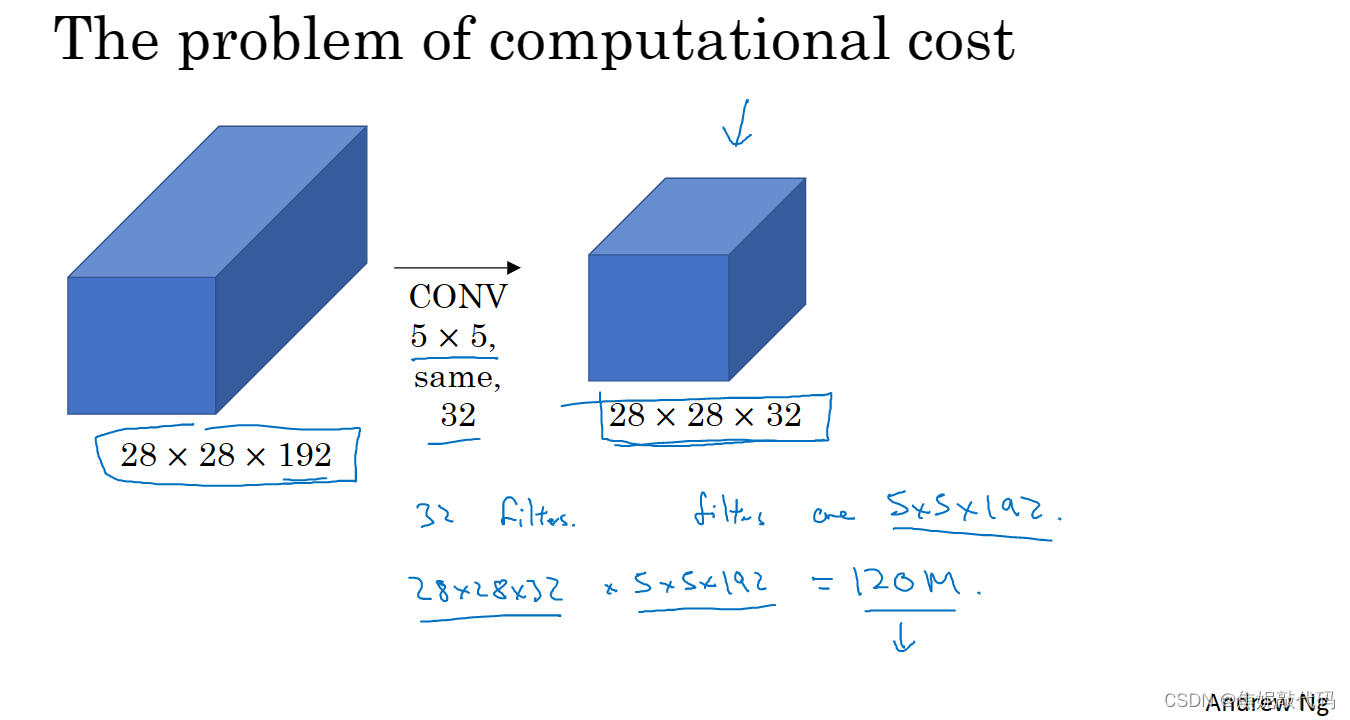
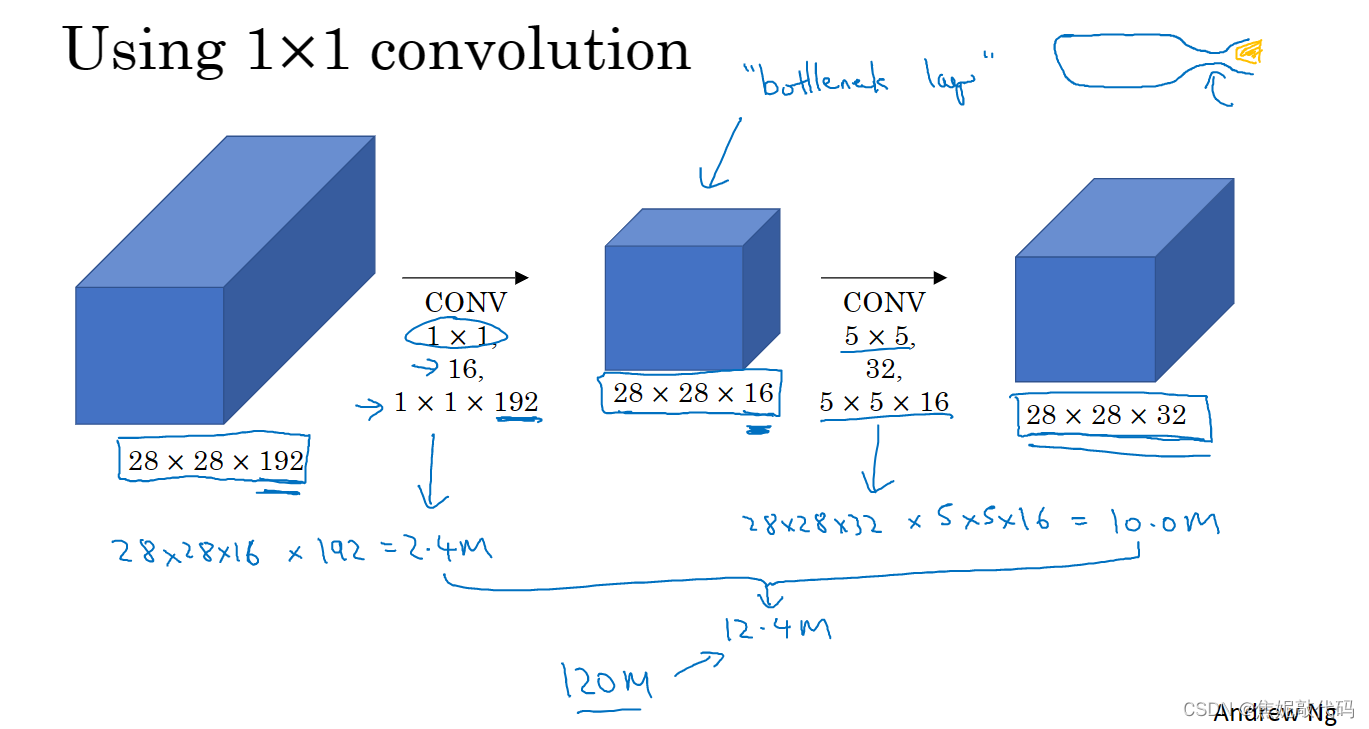
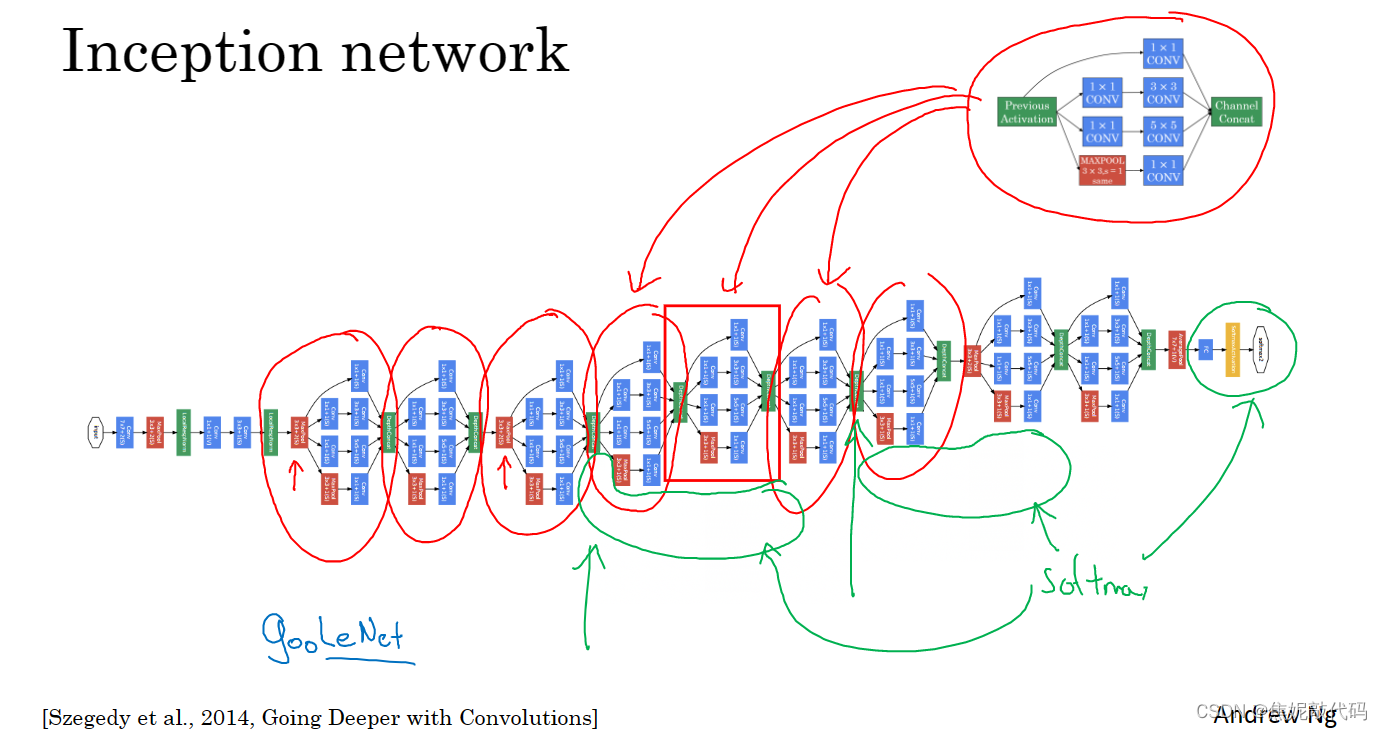
Inception 网络
迁移学习
通过使用其他人预训练的权重,你很可能得到很好的性能,即使只有一个小的数据集。
如果你有一个更大的数据集,那么不要单单训练一个softmax单元,而是考虑训练中等大小的网络,包含你最终要用的网络的后面几层。如果你有大量数据,你应该做的就是用开源的网络和它的权重,把整个的当做初始化,然后训练整个网络
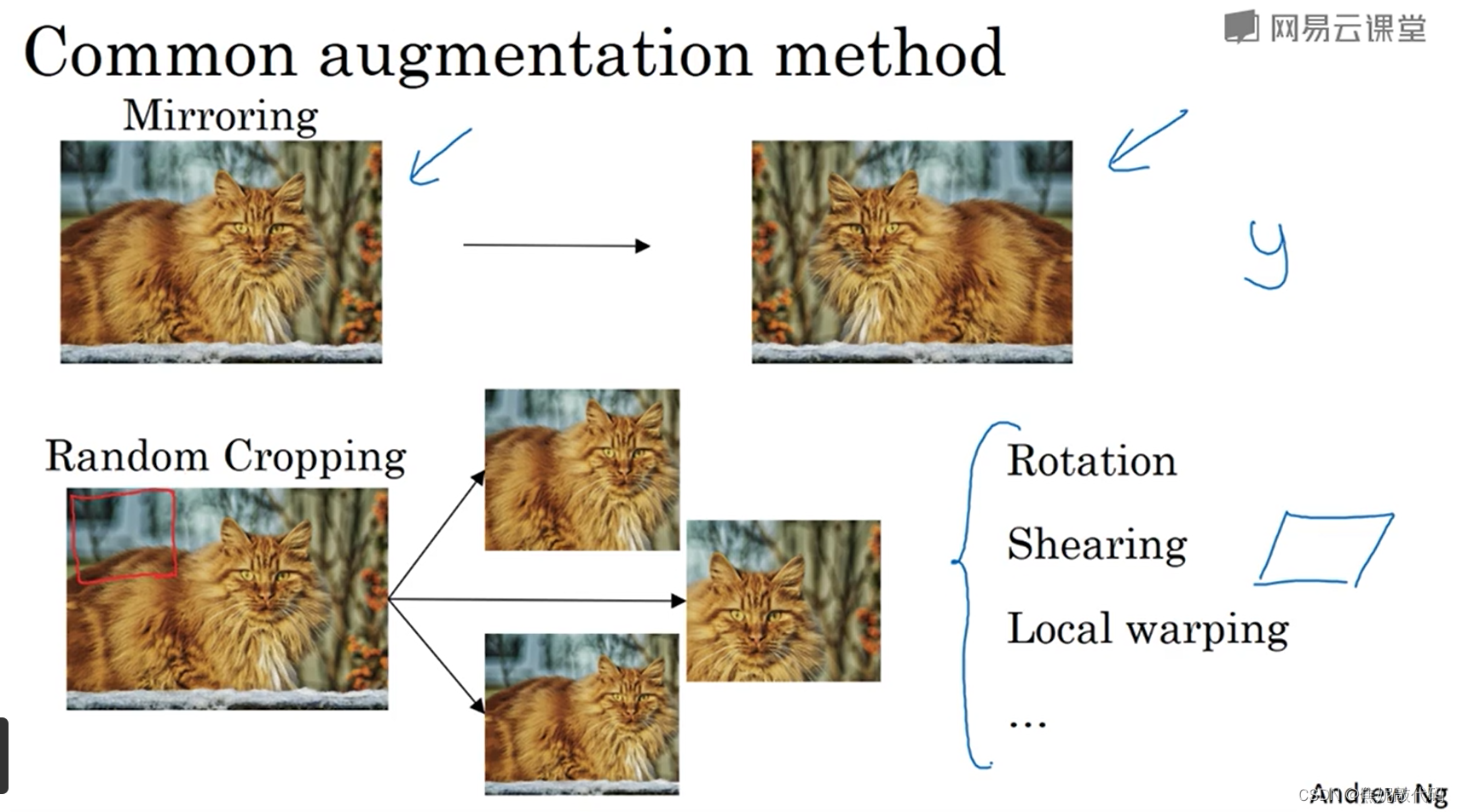
数据扩充(数据增强)
最简单的数据增强方法就是垂直镜像对称。如果镜像操作保留了图像中想识别的物体,这是一个很实用的数据增强技巧。
另一个经常使用的技巧是随机裁剪,给定一个数据集然后开始随机修剪,随机裁剪并不是一个完美的数据增强方法。
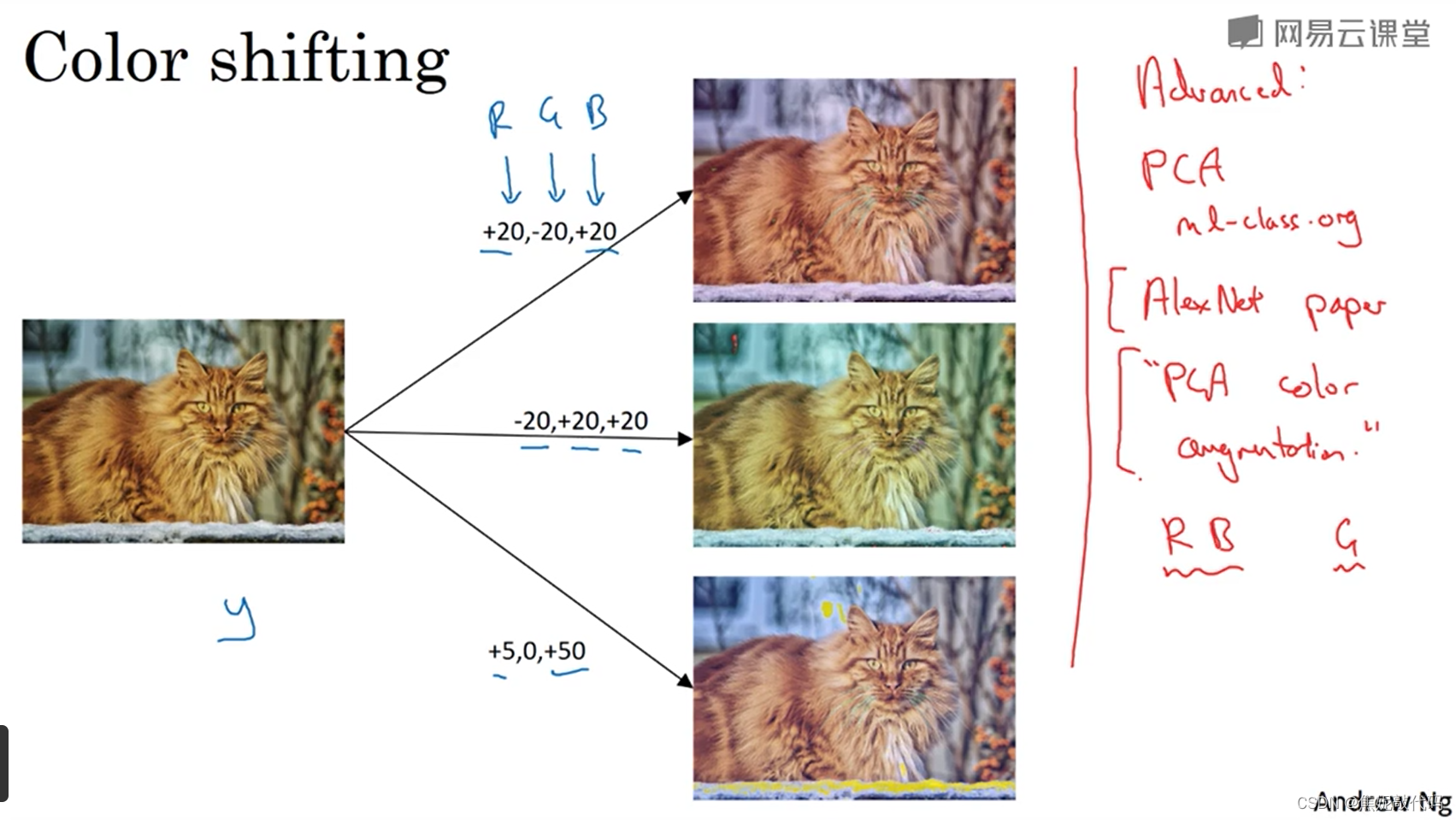
此外,经常使用的一种方法是色彩转换。有比如这样一张图片,然后给R、G和B三通道加上不同的失真值。
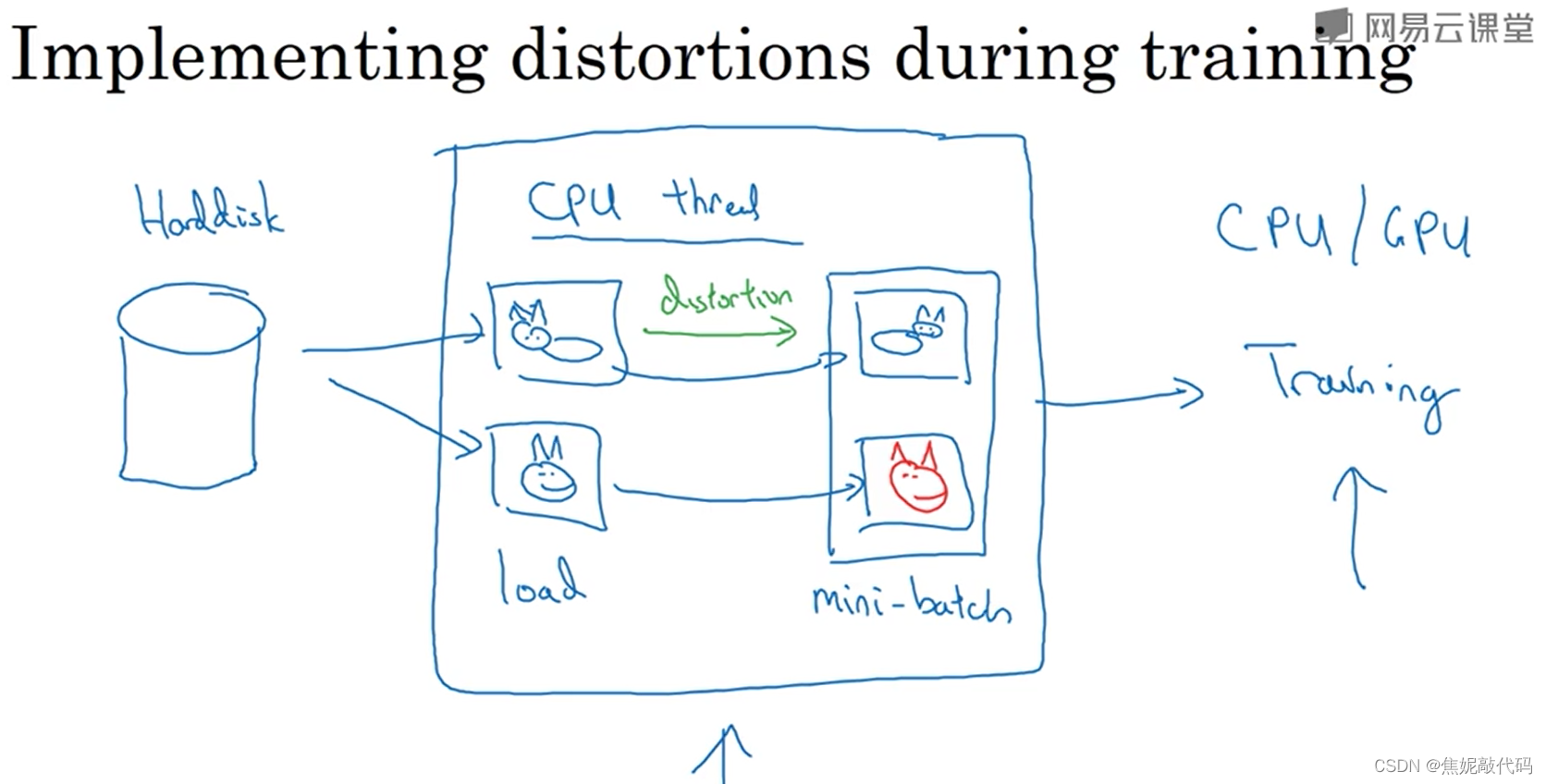
3. 目标检测
目标定位
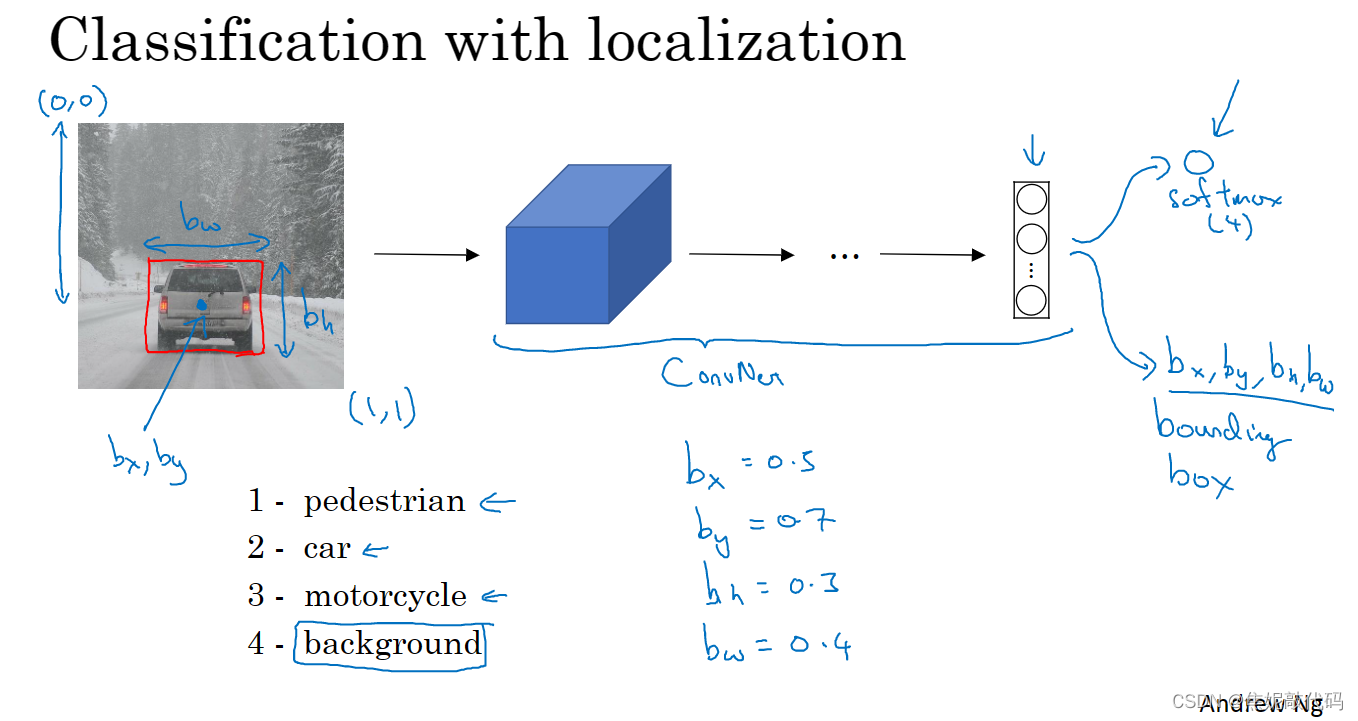
定位分类问题意味着我们不仅要用算法判断图片中是不是一辆汽车,还要在图片中标记出它的位置用边框或红色方框把汽车圈起来。其中“定位”的意思是判断汽车在图片中的具体位置。
在对象检测问题中 图片可以含有多个对象,甚至单张图片中会有多个不同分类的对象。

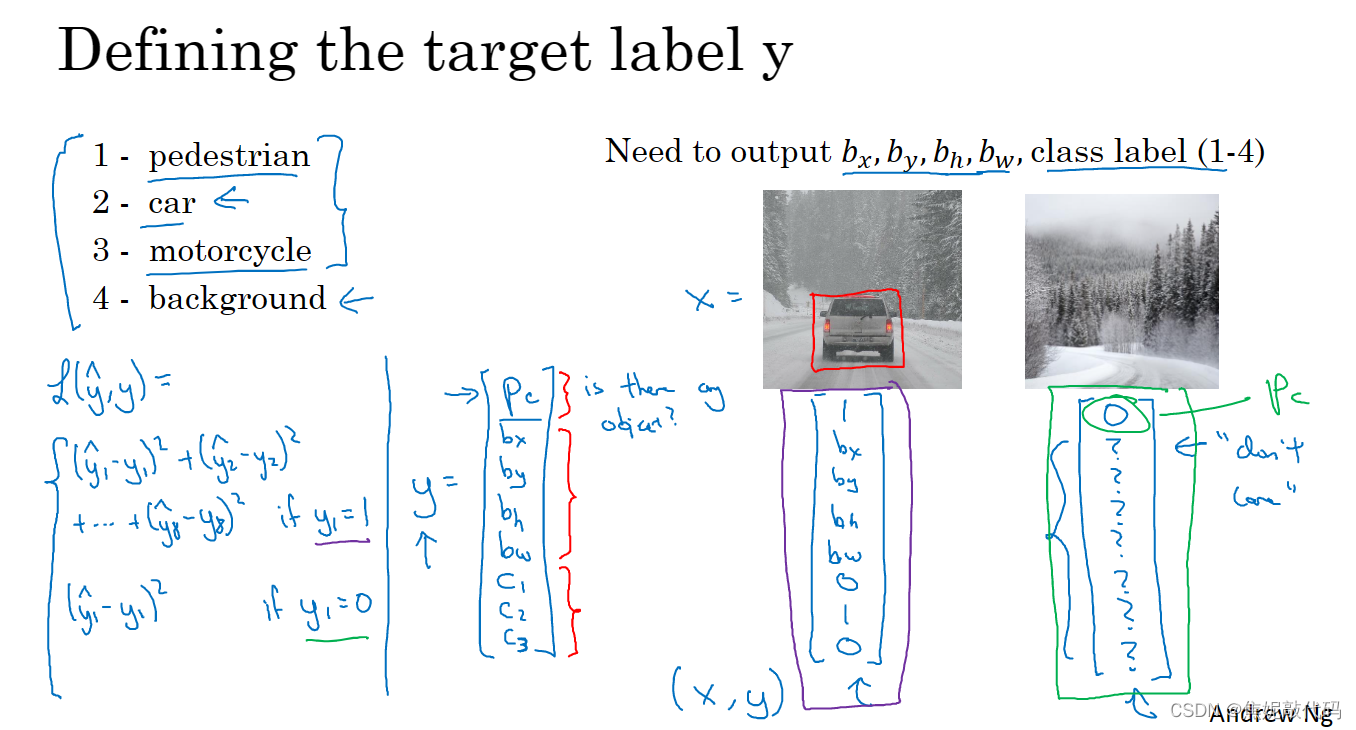
如果你还想定位图片中汽车的位置,我们可以让神经网络多输出几个单元输出一个边界框,具体说就是让神经网络再多输出4个数字标记为bx、by、bh和bw,这四个数字是被检测对象的边界框的参数化表示。
图片左上角的坐标为(0,0),右下角标记为(1,1),要想确定边界框的具体位置需要指定红色方框的中心点(bx,by),边界框的高度为bh,宽度为bw。因此训练集不仅包含神经网络要预测的对象分类标签,还包含表示边界框的这四个数字,接着采用监督学习算法输出一个分类标签,还有这四个参数值,从而给出被检测对象的边界框位置。
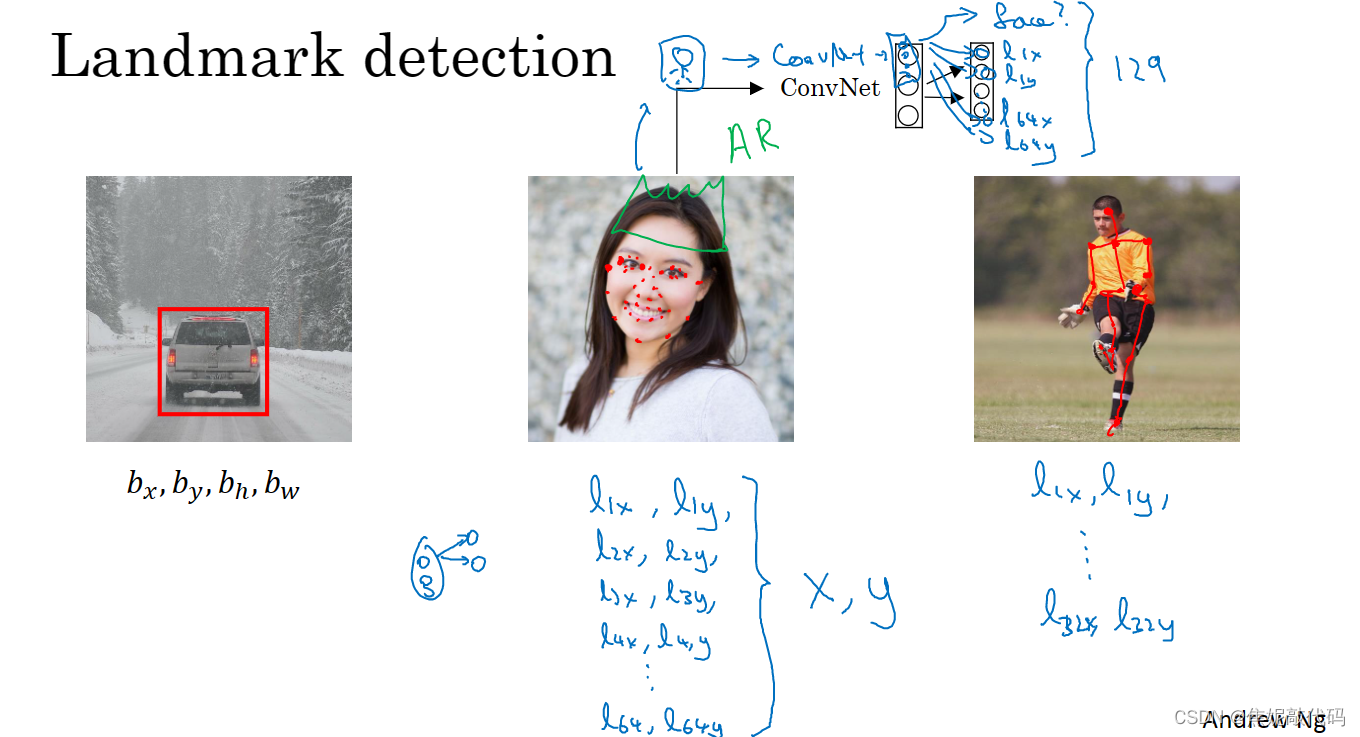
特征点检测
目标检测
滑动窗口目标检测算法以固定步幅滑动窗口,遍历图像的每个区域,把这些剪切后的小图像输入卷积网络,对每个位置按0或1进行分类。其缺点是计算成本,因为你在图片中剪切出太多小方块,卷积网络要一个个地处理。

卷积的滑动窗口实现
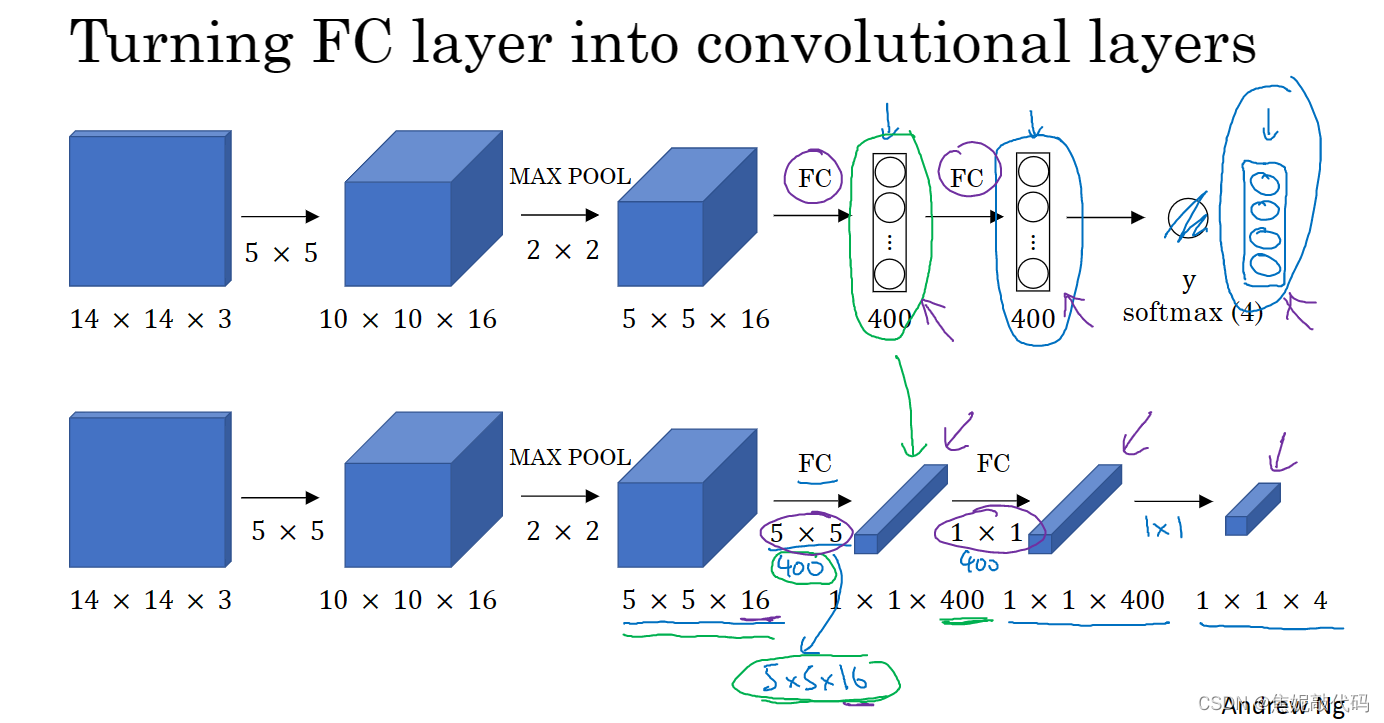

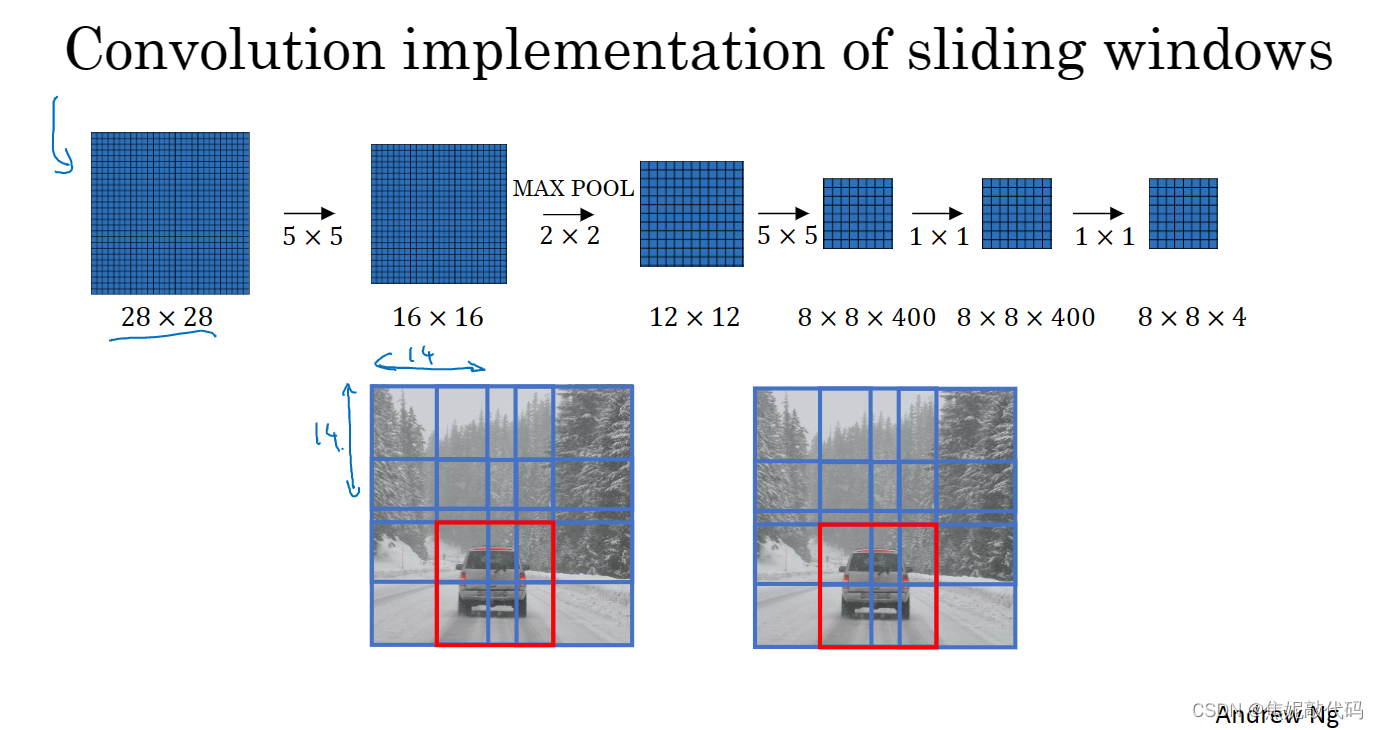
















 724
724











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











