







对比学习定义
一种无监督的图像/文本的表示学习。
Motivation:人类往往是通过对比来学习区分事物的。模型无需学习到过于具体的细节(图像:像素级别;文本:词语级别),只需要学习到足以区分对象的高层次的特征。

与之前的有监督方法/无监督方法的区别:

自然语言处理领域的对比学习
NLP领域的对比学习主要是借鉴自CV,主要在data augmentation方面有所不同。
2020 年的 Moco 和 SimCLR 等,掀起了对比学习在 CV 领域的热潮,2021 年的 SimCSE,则让 NLP 也乘上了对比学习的东风。
如何去理解对比学习,它和度量学习的差别是什么?
对比学习的思想是去拉近相似的样本,推开不相似的样本,而目标是要从样本中学习到一个好的语义表示空间。
度量学习和对比学习的思想是一样的,都是去拉近相似的样本,推开不相似的样本。但是对比学习是无监督或者自监督学习方法,而度量学习一般为有监督学习方法。而且对比学习在 loss 设计时,为单正例多负例的形式,因为是无监督,数据是充足的,也就可以找到无穷的负例,但如何构造有效正例才是重点。
对比学习中一般选择一个 batch 中的所有其他样本作为负例,那如果负例中有很相似的样本怎么办?
在无监督无标注的情况下,这样的伪负例,其实是不可避免的,首先可以想到的方式是去扩大语料库,去加大 batch size,以降低 batch 训练中采样到伪负例的概率,减少它的影响。
另外,神经网络是有一定容错能力的,像伪标签方法就是一个很好的印证,但前提是错误标签数据或伪负例占较小的比例。
infoNCE loss 如何去理解,和 CE loss 有什么区别?
infoNCE loss 全称 info Noise Contrastive Estimation loss,对于一个 batch 中的样本 i,它的 loss 为:
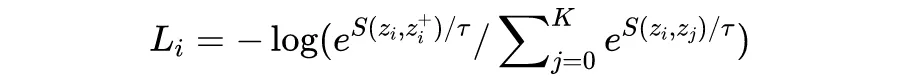
要注意的是,log 里面的分母叠加项是包括了分子项的。分子是正例对的相似度,分母是正例对+所有负例对的相似度,最小化 infoNCE loss,就是去最大化分子的同时最小化分母,也就是最大化正例对的相似度,最小化负例对的相似度。
上面公式直接看可能没那么清晰,可以把负号放进去,分子分母倒过来化简一下就会很明了了。
CE loss,Cross Entropy loss,在输入 p 是 softmax 的输出时:
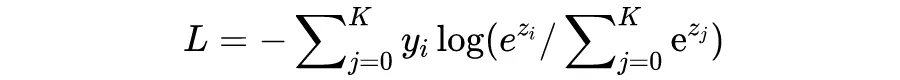
在分类场景下,真实标签 y 一般为 one-hot 的形式,因此,CE loss 可以简化成(i 位置对应标签 1):
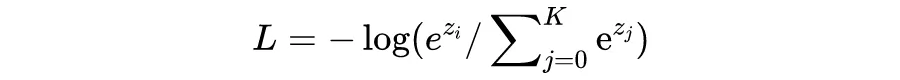
看的出来,info NCE loss 和在一定条件下简化后的 CE loss 是非常相似的,但有一个区别要注意的是:
infoNCE loss 中的 K 是 batch 的大小,是可变的,是第 i 个样本要和 batch 中的每个样本计算相似度,而 batch 里的每一个样本都会如此计算,因此上面公式只是样本 i 的 loss。
CE loss 中的 K 是分类类别数的大小,任务确定时是不变的,i 位置对应标签为 1 的位置。不过实际上,infoNCE loss 就是直接可以用 CE loss 去计算的。
注:
1)info NCE loss 不同的实现方式下,它的计算方式和 K 的含义可能会有差异;
2)info NCE loss 是基于 NCE loss 的
对比学习的本质是通过对比去学习事物的本质
学习非实
描述中的一句作为正例,按照对比学习来看,需要数据增强进行数据扩充,而数据集中天然的另外四句话就是正例的数据增强
















 4507
4507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











