







文章目录
一、线性回归算法
1、简介:
线性回归算法的目的是为了找到一条直线最好的拟合样本特征和样本标记拟合之间的关系

2、思路:
不直接做减法 是因为预测值与真值有正有负 可能会抵消
不用绝对值 是因为可能会出现不可导的情况
因此这里采用平方


最优化损失函数 是使损失函数尽可能小(损失函数是预测值与真值之间的差值)
最优化效用函数 是使效用函数尽可能大(效用函数是指拟合程度)
在这里:注意 a和b是未知数,x和y是已知的,因为是监督学习。
3、参数机器学习一种最常见的解决思路

二、最小二乘法
1、概述
最小二乘法(又称最小平方法)是一种数学优化技术。它通过最小化误差(真实目标对象与拟合目标对象的差)的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。
2、最小二乘法的具体推导:
求损失函数的最小值,即需要先求导,让其导数为0
1、先对b求导:
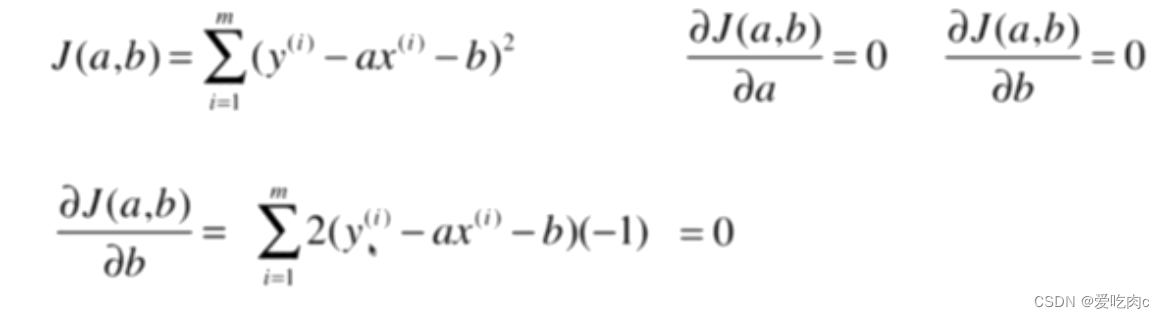
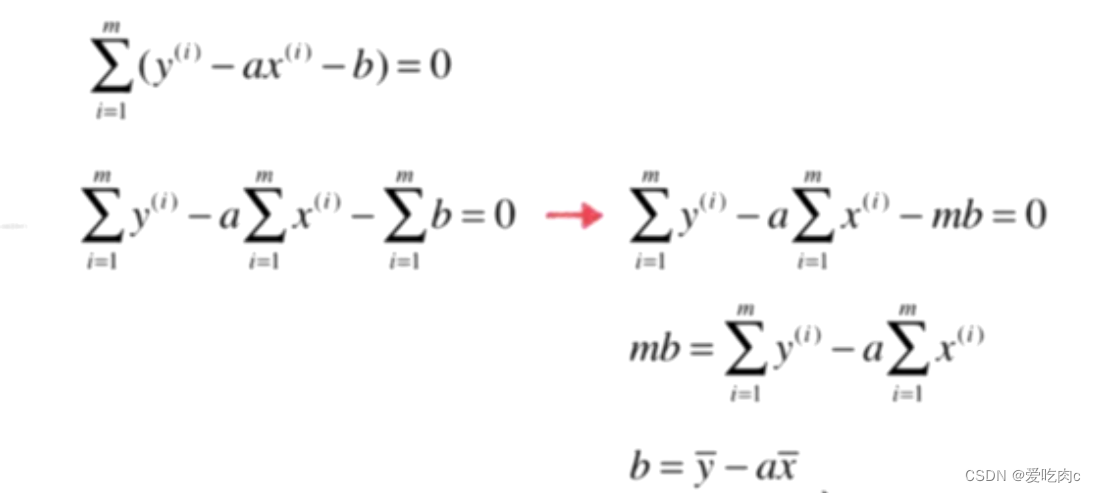
2、对a求导
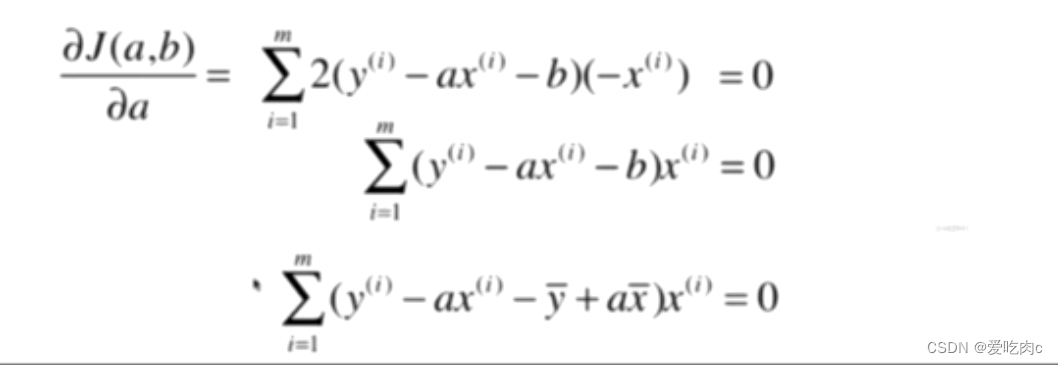
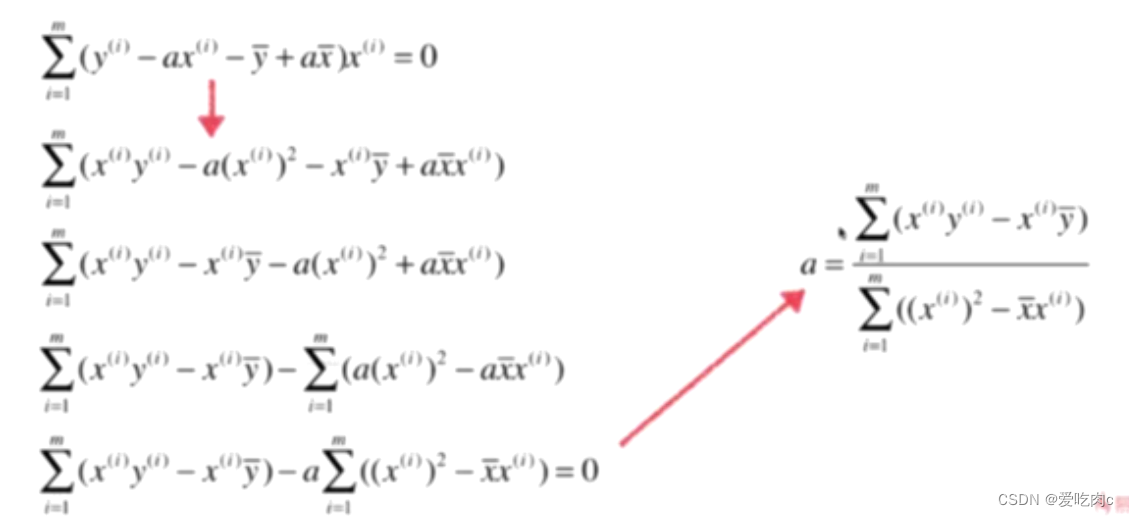
3、对a进行变换
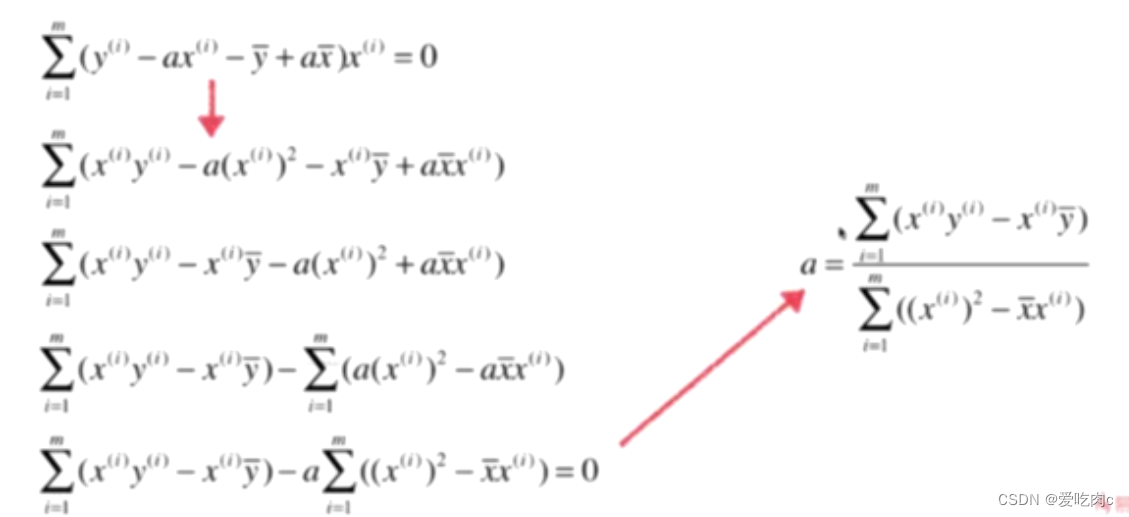
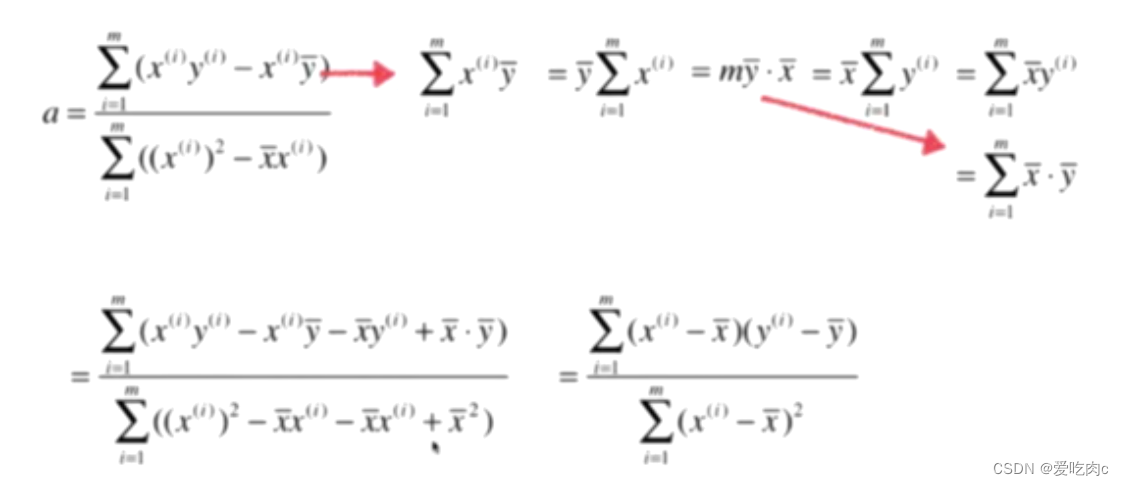
看似复杂度觉得差不多,但是在具体实现时,下边的会简单很多!!
3、最小二乘法的代码实现:
# 时间:2022/11/15 6:47
# cky
import numpy as np
class SimpleLinearRegression1:
def __init__(self):
self.a_=None
self.b_=None
def fit(self,x_train,y_train):
assert x_train.ndim==1,\
"SimpleLinearRegression only can solve signle feature training data"
assert len(x_train)==len(y_train),\
"the size of x_train must be equal the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x_i, y_i in zip(x_train, y_train):
num += (x_i - x_mean) * (y_i - y_mean)
d += (x_i - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self,x_predict):
"""给定代预测结果集 x_predict 是一个数组,返回表示x_predict的结果向量"""
assert x_predict.ndim==1, \
"SimpleLinearRegression only can solve signle feature training data"
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict"
return np.array([self._predict(x_i) for x_i in x_predict])
def _predict(self,x):
return self.a_*x+self.b_
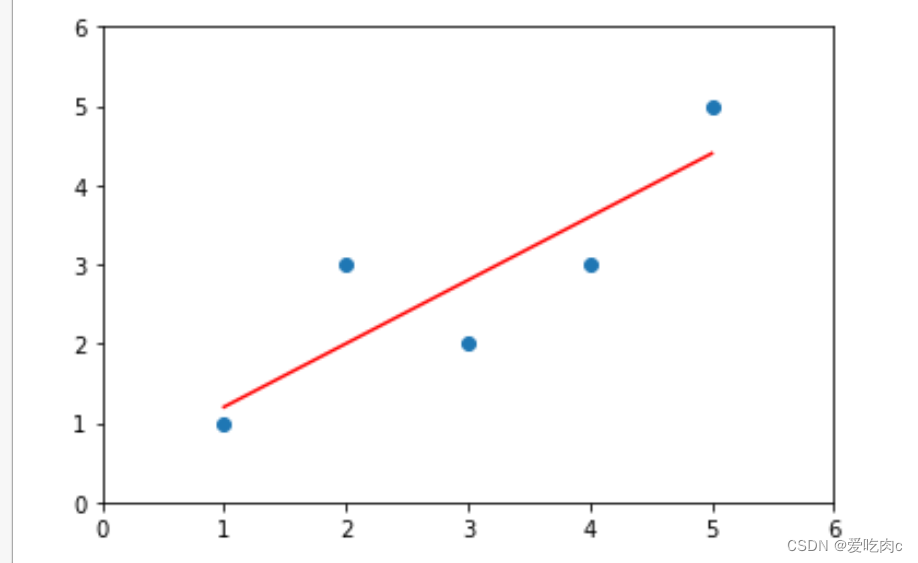
运用该自己实现的最小二乘法来实现线性回归
import numpy as np
import matplotlib.pyplot as plt
x=np.array([1,3,2,4,5])
y=np.array([1,2,3,5,4])
from SimpleLinearRegression1 import SimpleLinearRegression1
sip=SimpleLinearRegression1()
sip.fit(x,y)
sip.predict(np.array([x_predict]))
y_hat=sip.predict(x)
plt.scatter(x,y)
plt.plot(x,y_hat,color="red")
plt.axis([0,6,0,6])
plt.show()
4 、向量化以及实现
在上边我们实现最小二乘法是用for循环来求a和b
我们知道在numpy中使用向量比使用for循环效率高的多
这也就是上边我们提及的为什么要转换a的形式
转换a的形式之后 我们可以将a用向量化的方法来实现
分子和分母都可以看成两个向量相乘再相加的形式,即numpy中的点乘 dot
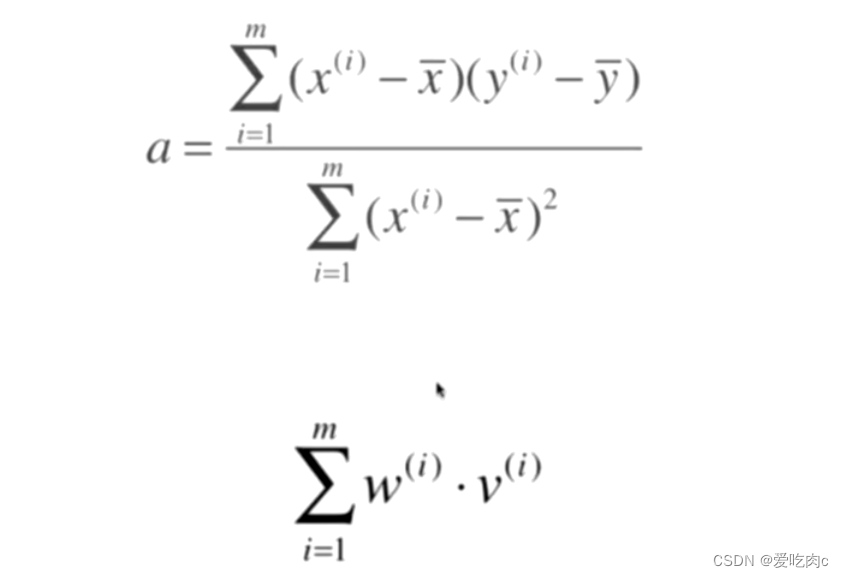
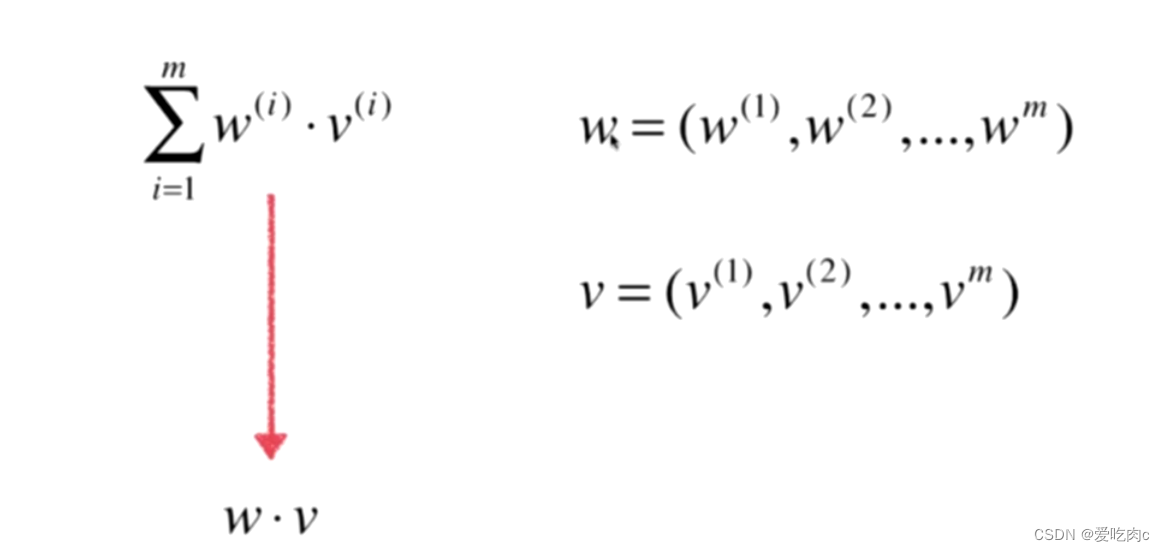
注意这里是点乘 dot方法 而不是使用乘号 使用乘号 得到的仍然是一个向量 是对应向量相乘的结果
而向量的点乘得到的是一个数
# 时间:2022/11/15 9:46
# cky
import numpy as np
class SimpleLinearRegression2:
def __init__(self):
self.a_=None
self.b_=None
def fit(self,x_train,y_train):
assert x_train.ndim==1,\
"SimpleLinearRegression only can solve signle feature training data"
assert len(x_train)==len(y_train),\
"the size of x_train must be equal the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = (x_train-x_mean).dot(y_train-y_mean) #只是在这里做了修改
d = (x_train-x_mean).dot(x_train-x_mean) #以及这里
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self,x_predict):
"""给定代预测结果集 x_predict 是一个数组,返回表示x_predict的结果向量"""
assert x_predict.ndim==1, \
"SimpleLinearRegression only can solve signle feature training data"
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict"
return np.array([self._predict(x_i) for x_i in x_predict])
def _predict(self,x):
return self.a_*x+self.b_
Ⅰ向量化和for循环 效率对比

reg1是for实现 reg2 是向量化实现 可以发现差了大约50倍
















 2895
2895











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









