






这篇文章基于 “Neural Networks for Topology Optimization” 论文复现代码
https://github.com/williamhunter/topy
https://github.com/ISosnovik/top 已经生成完全数据集
环境:Windows11、pycharm、tensorflow1.15
keras2.3.1
1、从下载代码:链接:https://github.com/ISosnovik/nn4topopt
2、解压打开文件夹
3、根据readme中顺序运行prepare_data.py文件
3.1注意需要添加参数变量或者使用命令运行
3.1.1添加参数变量
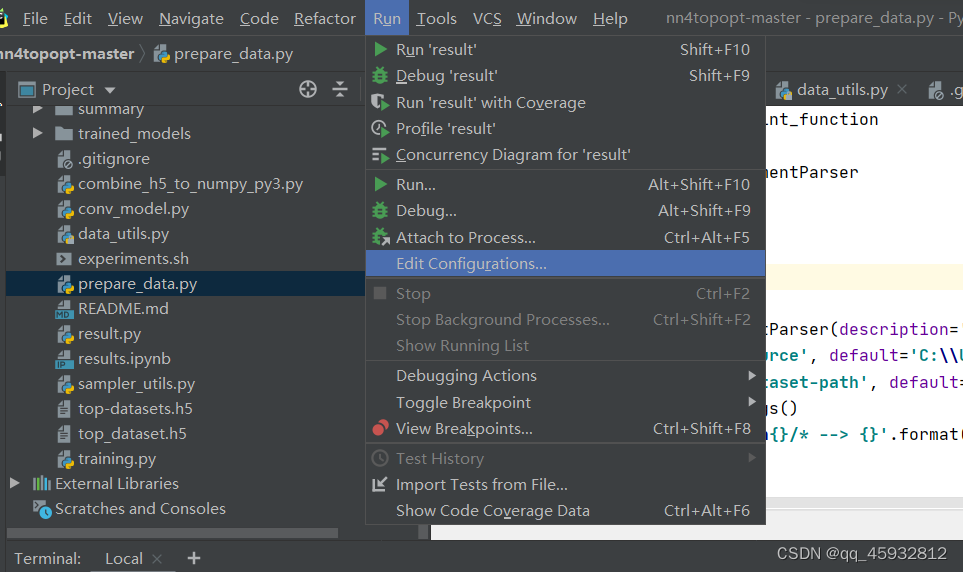
在pycharm中,点击run、其次找到 Edit Configurations
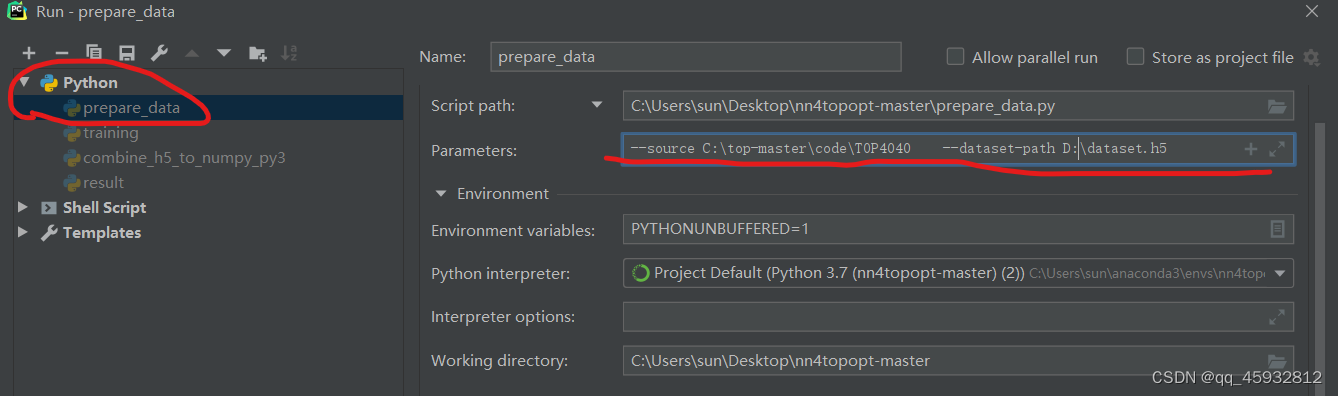
在图中左侧找到对应名称的文件,然后再按照右侧划线的格式输入对应的文件地址。
3.1.2使用命令输入:按照官网的命令格式
> python prepare_data.py --source SOURCE_FOLDER --dataset-path WHERE_TO_SAVE
输入即可
3.2windows运行时,还是会报错PressionError
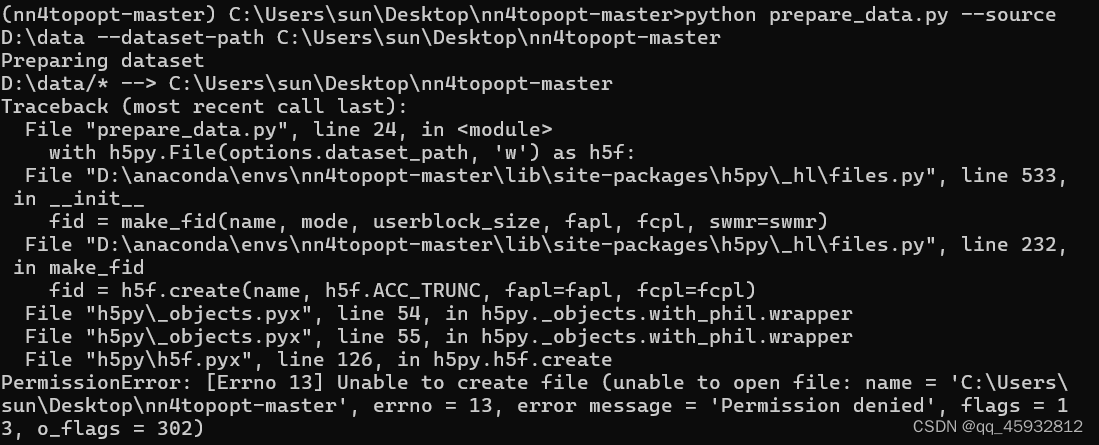
这里需要修改一下代码,修改成下面这样的代码。
from __future__ import print_function
import os
from argparse import ArgumentParser
import h5py
import numpy as np
import argparse
parser = ArgumentParser()
parser = argparse.ArgumentParser(description='Description of your program')
parser.add_argument('--source', default='C:\\Users\\sun\\Desktop\\topPro\\top-master\\code\\TOP4040', type=str, help='location of .npz files')
parser.add_argument('--dataset-path', default='D:\\nn4topopt-master\\data_007.hdf5', type=str, help='path of .h5 dataset')
options = parser.parse_args()
print('Preparing dataset\n{}/* --> {}'.format(options.source, options.dataset_path))入代码片
4、运行training
4.1同样需要和上面3.1.1一样,添加参数,步骤如下图所示
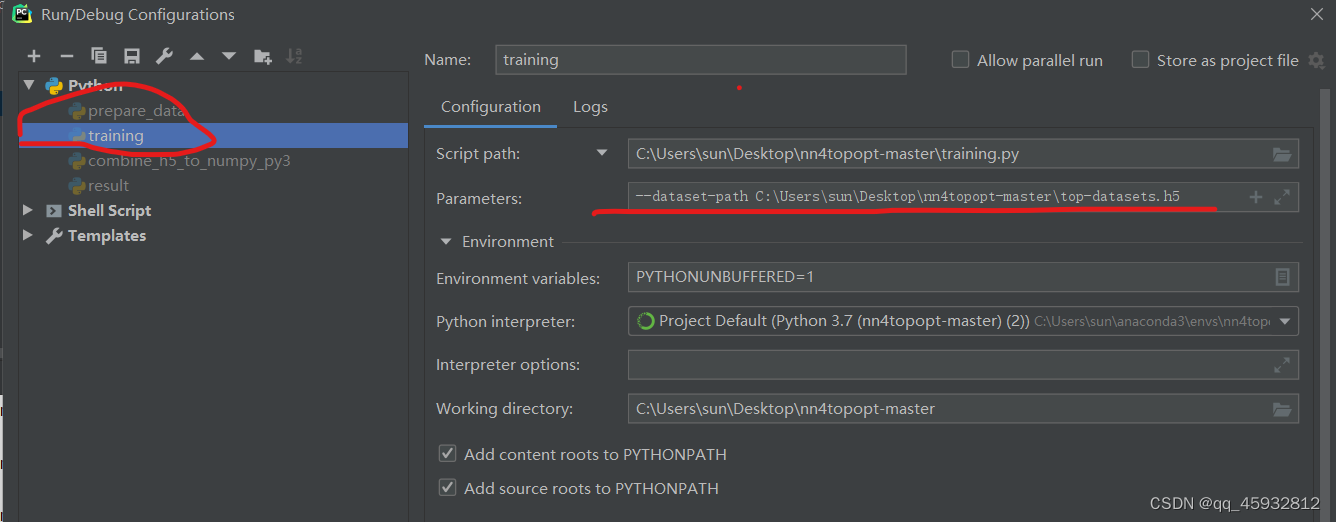
4.2运行时还会报错TypeError,如下图:
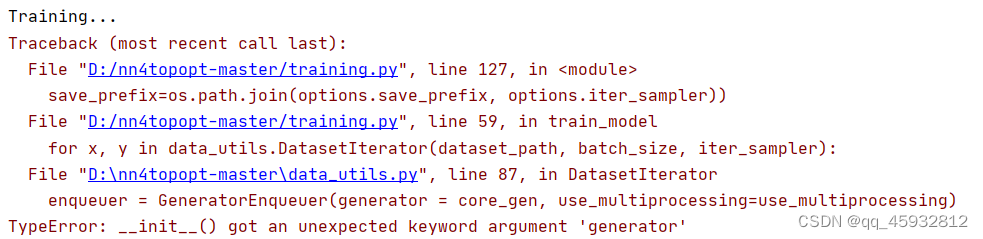
需要修改报错所示的generator,将它修改成scquence。
5、运行experiments.sh文件
5.1 安装Git bash(这里最好在官网下载并按照教程走一遍)
5.2 将安装好的文件.\Git\bin添加到环境变量中
5.3在pycharm中配置bash命令,过程如下
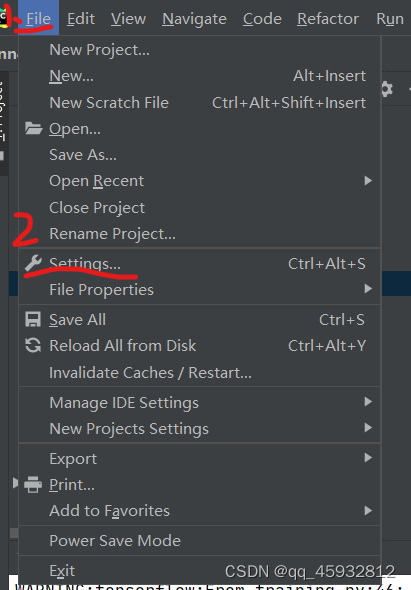
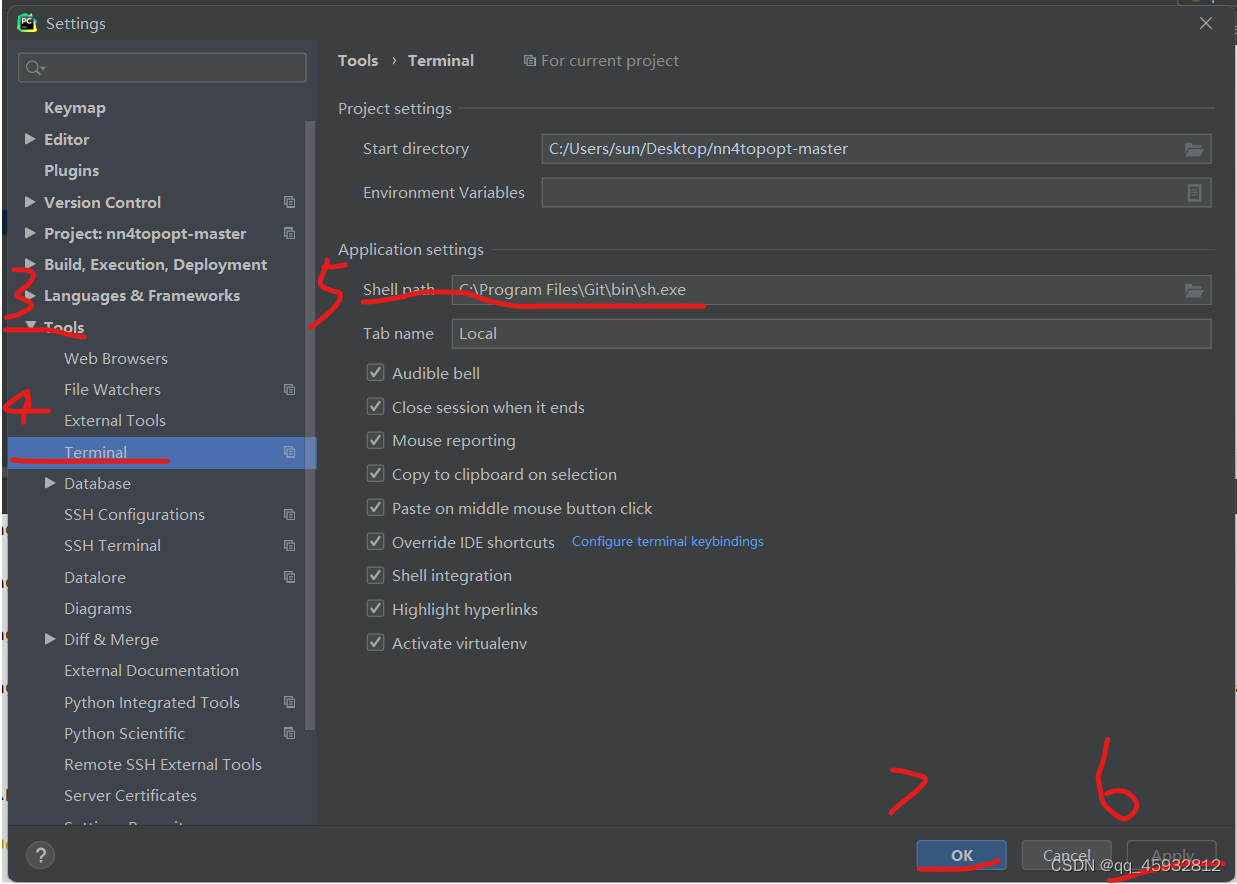
配置好了之后,点击左下角的终端
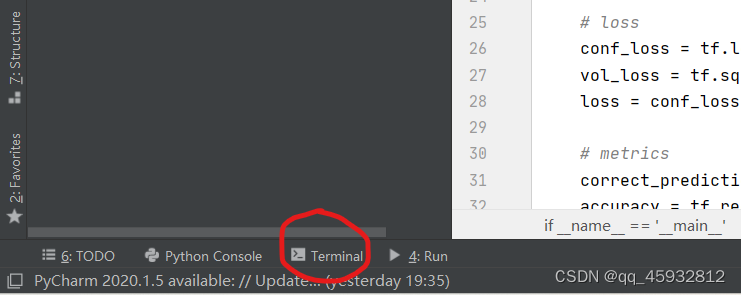
就会出现下图一样的彩色,就说明成功了
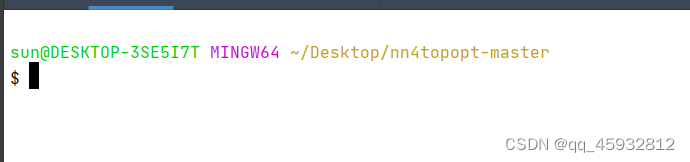
5.4在终端输入命令
bash experiments.sh
就好了
6、最终得到结果可以直接将results.ipython的代码复制过来,变成.py文件用pycharm运行。也可以用jupyter notebook。
如果用 jupyter 的话需要配置环境
6.1
首先,打开anaconda prompt
6.2 依次输入下面的命令
conda activate nn4topopt-master(anaconda中你需要使用的环境的名称)
conda install ipython
conda install jupyter
conda install ipykernel
ipython kernelspec install-self --user
6.3在开始查看,如图所示就说明成功了
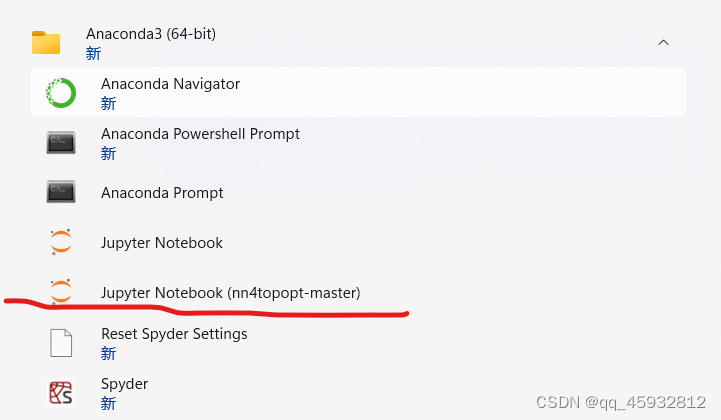
版权所有,禁止转载















 5541
5541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









