







1.Point NN复现(Ubuntu18.06)
代码地址:GitHub - ZrrSkywalker/Point-NN: [CVPR 2023] Parameter is Not All You Need: Starting from Non-Parametric Networks for 3D Point Cloud Analysis![]() https://github.com/ZrrSkywalker/Point-NN 将上面的代码拷贝下来后就可以按照readMe说明来配置环境及复现其方法了。
https://github.com/ZrrSkywalker/Point-NN 将上面的代码拷贝下来后就可以按照readMe说明来配置环境及复现其方法了。
1.1环境配置
首先是配置环境,下面的指令是作者提供的,但是由于每个人的系统环境等不同,因而会有所差异,主要注意的点是在最后两个指令上(即两个pip install指令上),可以参考我配置时的设置:
第一个pip install中,观察其quirements.txt,可以发现有很多是系统自带并不需要安装的,参考自Solution: Successful Environment Setup with Modified requirements.txt · Issue #23 · ZrrSkywalker/Point-NN · GitHub![]() https://github.com/ZrrSkywalker/Point-NN/issues/23,可以将requirements.txt直接替换为以下环境。
https://github.com/ZrrSkywalker/Point-NN/issues/23,可以将requirements.txt直接替换为以下环境。
cycler
einops
h5py
matplotlib==3.4.2
pyyaml==5.4.1
scikit-learn==0.24.2
scipy
tqdm
numpy
scipy
sklearn
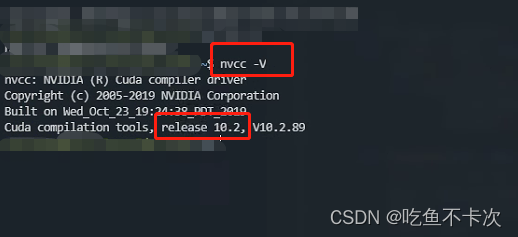
typing第二个pip install,在配置的时候只需要按照一个要求:编译pointnet2_ops_lib的时候一定要确保虚拟环境中的cuda版本和本机的cuda版本保持一致就行,以我的电脑为例,通过nvcc -V指令查看本机cuda版本为10.2,那么你必须安装cuda10.2的pytorch及torchvision版本来编译代码,编译完之后你可以用其他的cuda版本。
conda create -n pointnn python=3.7
conda activate pointnn
# Install the according versions of torch and torchvision
conda install pytorch torchvision cudatoolkit
pip install -r requirements.txt
pip install pointnet2_ops_lib/.这里配置环境其实也踩了不少坑,尤其是在编译pointnet2_ops_lib的时候,但是注意好保持cuda版本一致就基本没问题了。
1.2复现point nn
这一部分还是按照readme上的指令及步骤就行了,首先是下载对应的数据集,并将数据集放在指定的路径下,主要是有分类网络以及语义分割网络,还有point pn 即有参数的分类网络的复现,这里就不再做过多解释了,只要环境配置好了就没啥问题了。
2.Point NN解读
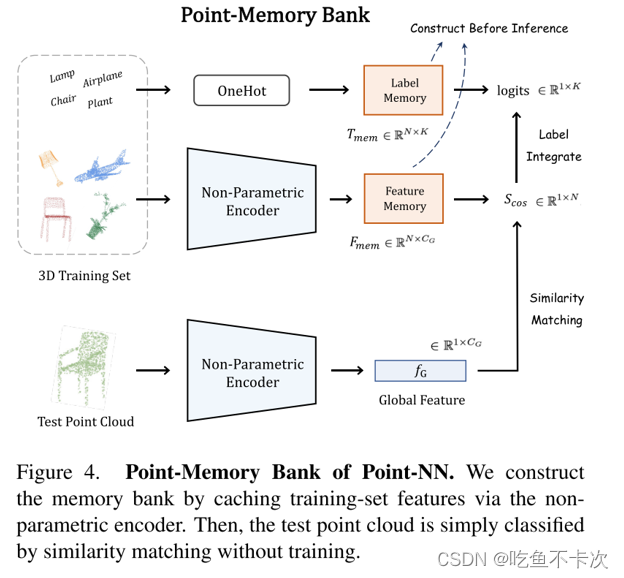
Point NN是无参数且无需训练的网络,和Pointnet++一样,共设计了点云分类、部件分割、语义分割三种网络,而这三种网络的执行流程都是一样的,可以参考文中的这张图:首先是对训练集的数据进行特征提取(Non-Parametric Encoder)构建Feature Memory Fmem,对标签进行OneHot处理得到Label Memory Tmem;然后对需要预测点云数据通过同样的特征提取网络(Non-Parametric Encoder)构建属于该点云的Feature Memory Fg;最后经过两次相似度匹配计算,第一次计算时通过Fg和Fmem进行相似度匹配得到的Sim,第二次计算是计算Sim和Tmem,得到的结果是一个类似于softmax输出的值,取最大值下标即为预测的类别。(相似度匹配其实就是两个矩阵的乘法,所谓的Feature Memory和Feature Memory也就是两个矩阵)
2.1 Point nn cls
这一节简单说明一下Point nn是如何构造点云分类网络的,还是按照前面说的顺序来介绍。
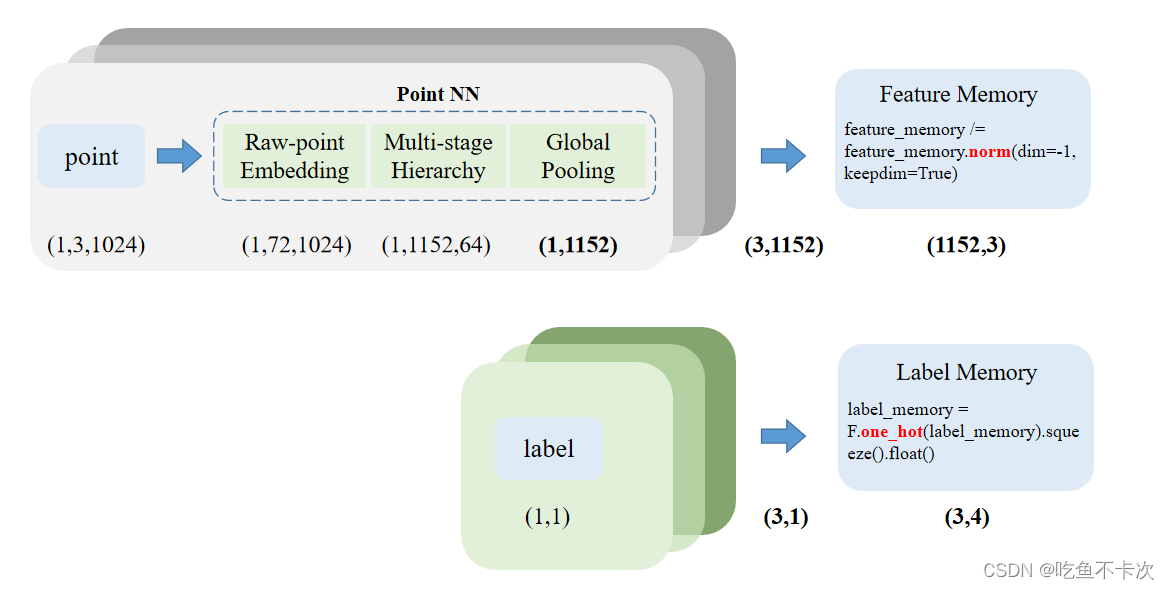
首先是对训练集的数据进行特征提取构建Fature Memory,对训练集的标签进行OneHot处理得到Label Memory。如下所示:输入一个点云point的shape为(1,3,1024),分别代表批处理大小、xyz以及点数量;经过特征提取网络后得到得到大小为(1,1152)的矩阵,这里的1152可以理解为提取得到的特征通道数由3变成了1152;假设数据集中有3个点云,那么经过特征提取后将得到大小为(3,1152)的矩阵,经过归一化处理及交换维度后得到Feature Memory的大小为(1152,3),从这里可以知道了,这个Memory的大小其实是和数据集中的数据有关的,数据越多,记忆也将越深刻。
而Label Memory的构建就比较简单了,假设我有4个类别,3个点云将得到大小为(3,4)的Label Memory。
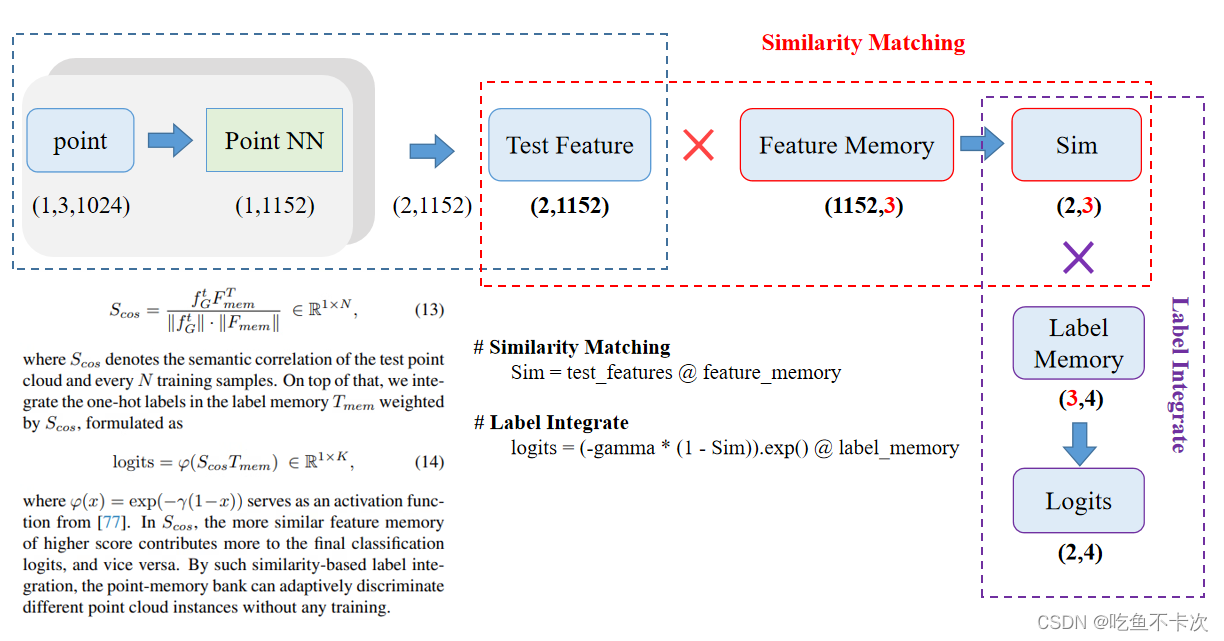
然后,对需要预测的点云经过同样的特征提取网络得到大小为(1,1152)的矩阵,如果我同时要预测两个点云(即batch size为2),那么将得到大小为(2,1152)的矩阵。
最后,是进行两次相似度匹配Similarity Matching和Label Intergrate。Similarity Matching是将预测点云经过特征提取得到矩阵和Fature Memory矩阵相乘,得到大小为(2,3)的Sim矩阵;Label Intergrate是将Sim矩阵和Label Memory矩阵相乘,得到大小为(2,4)的Logits;如果要得到每个点云的预测类别,可以对dim=1取下标最大值。(涉及到的代码和论文中的公式也在下图中)
2.2 Point nn seg
分割相比于分类来说会复杂一点点,但还是按照前面的顺序来介绍:
假设现在只有一组点云和标签,首先还是对训练集的数据进行特征提取构建Fature Memory,对训练集的标签进行OneHot处理得到Label Memory,由于是假设只有一组点云和标签,则变成为Single Fature Memory和Single Label Memory。
(1)Single Fature Memory:输入(1,3,1024)经过特征提取网络后得到(1,4464,1024)的特征向量,分别表示1个点云,4464维特征和1024个点。假设一共有4个类别,而该点云只有3个类,分别为Cls0、Cls1和Cls3这三种。那么会将1024个点按照类别进行划分成3类,并且每一类的特征维度为1164,如下图所示为Cls0-(4464,461),Cls1-(4464,330),Cls3-(4464,233),然后将这三个类分别求均值,得到3个shape为(1,4464)的向量,最后将这3个向量进行拼接得到Single Feature Memory(3,4464)。
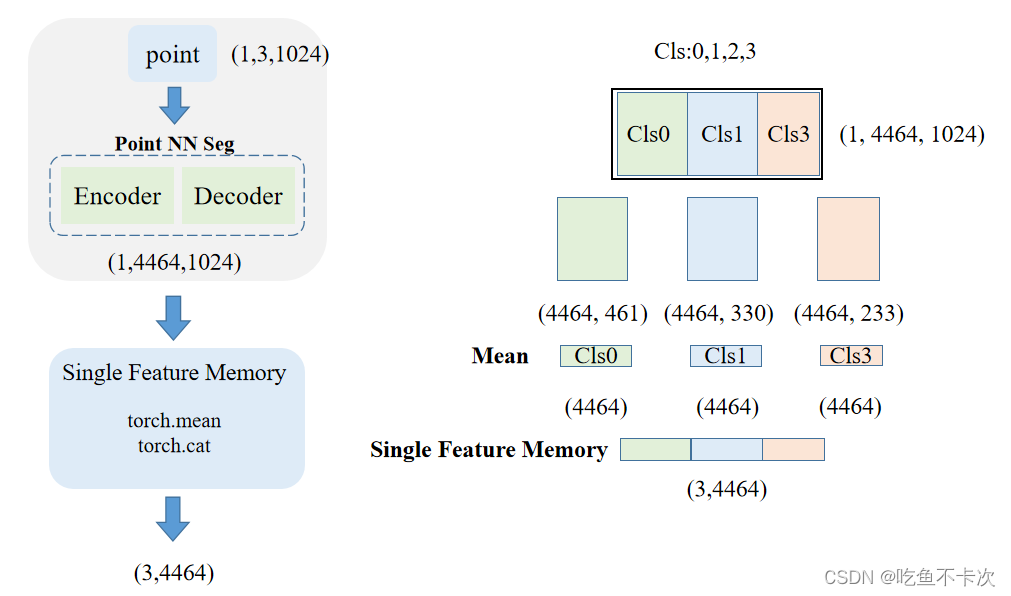
(2)而Single Label Memory则简单很多,直接按照该点云的标签取one_hot,得到shape为(3,4)的矩阵。

了解了只有一组的点云和标签如何生成Memory,那么了解多组的点云和标签生成Memory就简单很多,如下所示:
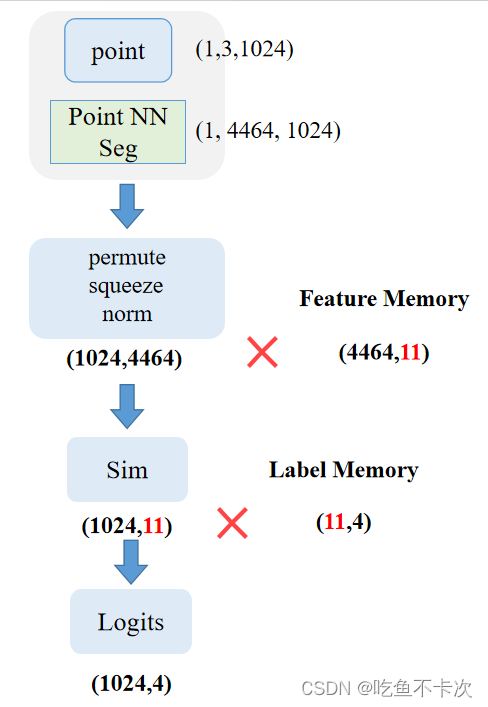
Feature Memory:假设有3个点云,其中点云1有三个类别,分别为Cls0、Cls1和Cls3,点云2和3有四个类别,分别为Cls0、Cls1、Cls2和Cls3。则这三个点云经过特征提取网络后会得到(3,4464,1024)向量,然后将这个向量按照每个点云类别进行拆分、求均值后进行拼接,得到(4464,11)的向量,这里的11是怎么来的?是通过每个点云的类别数进行相加得到的,换句话说,每个点云的类别数越多,那么Memory也就越大。
Label Memory:根据标签的类别来进行one_hot,看图就能够看懂了,这里就不多说了。

然后,对需要预测的点云经过同样的特征提取网络得到大小为(1,4464,1024)的矩阵,预测的话只支持一次预测一个点云。
最后,同样是进行两次相似度匹配,第一次是将预测点云经过特征提取得到矩阵和Fature Memory矩阵相乘,得到大小为(1024,11)的Sim矩阵;第二次是将Sim矩阵和Label Memory矩阵相乘,得到大小为(1024,4)的Logits;如果要得到每个点云的预测类别,可以对dim=1取下标最大值。
3.Point PN解读
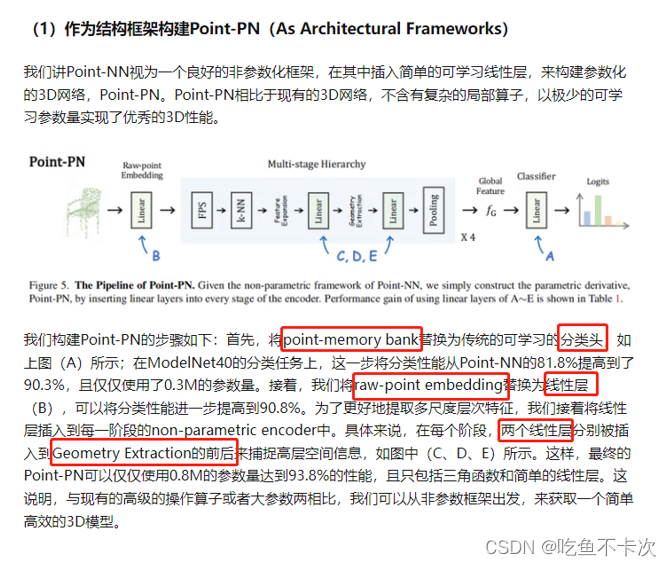
按照原论文和源码,作者也提供了可训练的分类模型,主要是使用了几个Linear线性层进行替换,而可训练的分割模型没有提供源码,但是可以自己根据分类模型再添加一个Decoder也可以实现一个基于PointNN的语义分割网络。














 1407
1407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









