






这周日去接机,所以前几天要好好学习。
1.tile是什么

意思是:F(m, r),举例F(2, 3),即要求输入4*4,卷积核3*3,输出2*2,可以将原输入的大图片,切割为4*4的输入图片,成为tile,这些tile重叠部分为r-1,即2,此时没有多算一点,可以直接把卷积后的输出拼接起来即可
2.可以在哪些方向做出创新
但是直接应用 Winograd 卷积存在很多挑战。首先,基本的 Winograd卷积适用范围有限,仅可在单位步长、小卷积核的二维卷积上应用,在大卷积核上应用则会有数值不稳定的情况[3] 。其次,由于线性变换 和逆线性变换的复杂性,快速卷积算子在特定平台上的优化难以实现,比如利用并行性和数据局部性[4] 。此外,Winograd 卷积与以剪枝和量化为代表的网络压缩技术难以直接结合,因此不易在算力不足和有能耗限制的平台上部署实现[5] 。针对这些问题,研究者做了大量的工作,但至今还未有公开的文章对相关工作进行系统性的总结。
Winograd 卷积的一般化
主要分为四个方向,分别是支持任意维度、支持任意切片大小、支持任意常规卷积、支持特殊卷积。

Winograd卷积的拓展
对 Winograd卷积的拓展可以从两个角度入手:一是使用不同的变换,将运算映射到不同的域;二是采用不同的变换矩阵生成多项式。
剪枝和利用稀疏性
在 Winograd 卷积上直接应用剪枝是有困难的,因为稀疏的卷积核在变换到 Winograd 域 后又会变回稠密矩阵,这违背了剪枝的初衷。
低精度与量化
数值稳定性
其中分解方法已经大量使用于研究中,而选择变换矩阵的方法由于无需修改 Winograd 卷积算法本 身也具备直接应用的可行性。而超线性变换会突破现有 Winograd 卷积实现的架构,在数学上论证该方法优越性之前距离实际应用还有一定的距离。
Winograd卷积的实现、优化与应用
在算法本身的优化方面,数学方法仍然是突破 Winograd 卷积局限性的根本方法,由于其内在的最小乘法次数属性,有望在未来的研究中基本取代现有的基于一般矩阵乘的卷积。现已有从数学角度解决数值稳定 性的方法,但由于引入了新的计算机制或额外的步骤,在各平台上还没有高效的实现,对硬件友好优化方法的研究可能会是后续研究的重点方向。
在实现与应用方面,FPGA平台上可以轻松为 Winograd卷积 定制软硬件协同的实现,但现有 FPGA 实现对数值稳定性的关注太少。FPGA 实现具备很高的灵活性,可参照相关优化方法率先部署更快更精确的 Winograd 卷积。由于 Winograd 卷积数据流的内在复杂性,在 CPU、GPU 这类通用计算平台上,如何利用好算力和内存层级还有待进一步研究。
此外,在非常规平台的 实现明显滞后于理论,比如基于内存的计算平台、开源RISC-V框架上的实现还局限于小卷积核,下一步可以尝试在这类平台上实现更一般化的Winograd卷积。
0616
搞定了领英
搞定了gpt:wetab
搞定了魔法:warp
0701
开始每天三小时学习
第一小时:补python基础
注释:##,多行注释:alt+3,取消注释:alt+4
学到了如何同时输出字符串和数字:print("年薪", 10)
疑问:在IDLE中,format函数不起作用。
第二个小时:实战
Python只运行一部分代码方法:框选需要运行代码-右键-单击Execute Selection in Python Console(但不是很会用)0702:会用了:),要加上import torch就可以运行了
熟悉了一下神经网络训练验证测试过程。
0702
开始每天三小时学习
第一小时:补python基础
a = [x*2 for x in range(100) if x%9==0]
第二个小时:实战
f-string是format的另一种形式:当使用 f-string 来显示变量时,你只需要在一组大括号 {} 内指定变量的名字。而在运行时,所有的变量名都会被替换成它们各自的值。
language = "Python"
school = "freeCodeCamp"
print(f"I'm learning {language} from {school}.")为什么输出矩阵是1.,为啥会有个小数点
怎么调用gpu:安装cuda版本的torch就可以了
三种计算张量矩阵乘法
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(y1)
torch.matmul(tensor, tensor.T, out=y3)
print(f"y1为 \n {y1} \n y2为 \n {y2} \ny3为 \n {y3}")三种计算逐元素矩阵乘法
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)0703
开始每天三小时学习
第一小时:补python基础。37课--42课
注释:##,多行注释:alt+3,取消注释:alt+4
学到了如何同时输出字符串和数字:print("年薪", 10)
疑问:在IDLE中,format函数不起作用。
经典列表嵌套循环
a = [
["高小一", 17, 30000, "北京"],
["高小二", 18, 20000, "上海"],
["高小三", 19, 10000, "深圳"],
]
for m in range(3):
for n in range(4):
print(a[m][n],end="\t")
print("\n")
##print()
第二个小时:实战
python figure。figsize用法:居然真的是控制图形界面大小的。
torch.randint(low=0, high, size, \*, generator=None, out=None, dtype=None, layout=torch.strided, device =None, requires_grad=False)torch.randint生成low到high-1范围内的整数,填充到张量中,形状由size(元组)——定义输出张量形状的元组 定义。
sample_idx = torch.randint(len(training_data), size=(1,)).item() torch数据类型的item()方法得到【只有一个元素的张量】里边的【元素值】
plt.imshow(img.squeeze(), cmap="gray")用法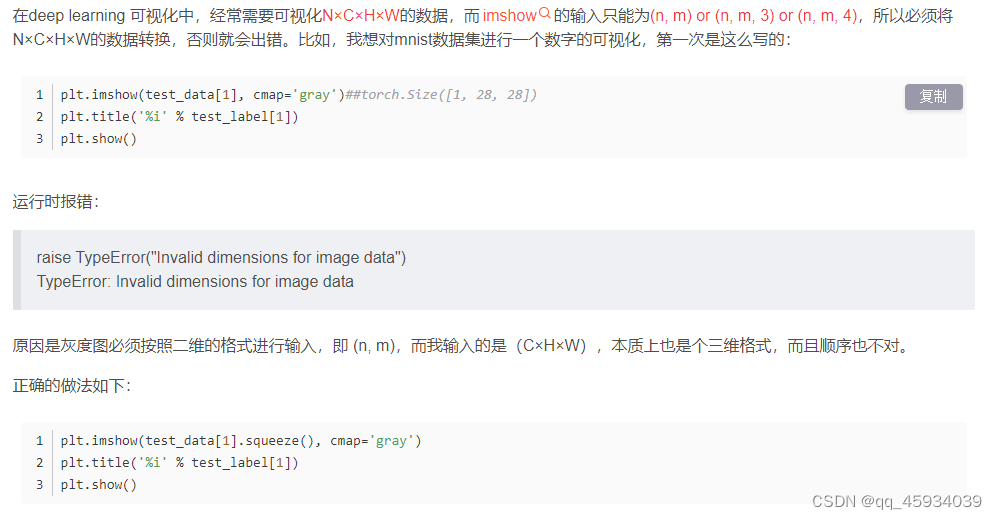
本质是用squeeze进行了维度转换
matplotlib.pyplot.imshow()函数的使用-CSDN博客
0704
开始每天三小时学习
第一小时:补python基础。43课--47课
元组 a = (),元组的括号可以省略
列表 a = []
字典 a = {}
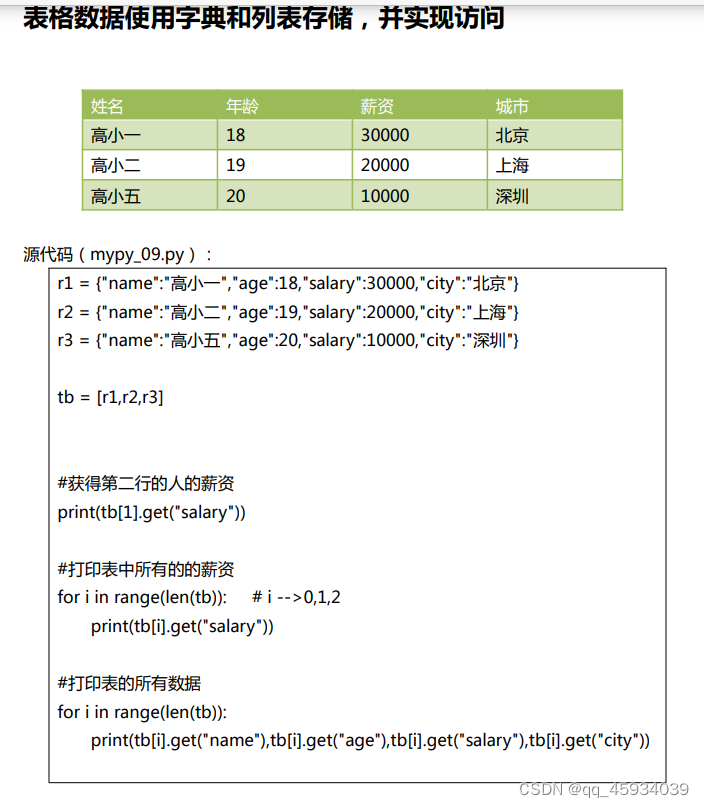
r1 = {"name":"高小一","age":18,"salary":30000,"city":"北京"}
r2 = {"name":"高小二","age":19,"salary":40000,"city":"北京"}
r3 = {"name":"高小三","age":20,"salary":50000,"city":"北京"}
tb = [r1,r2,r3]
print(tb[1])
print(tb[1].get("salary"))
for i in range(len(tb)):
print(tb[i].get("salary"))
for i in range(len(tb)):
print(tb[i].get("name"),tb[i].get("age"),tb[i].get("salary"))第二个小时:实战
如何自定义数据集:自定义 Dataset 类必须实现三个函数:__init__、__len__和__getitem__
使用dataloader:
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")next(iter(train_dataloader))

然后打印batch和label的尺寸
提取第一个batch的第一张img,用squeeze去掉一维后打印出来。
0705
开始每天三小时学习
第一小时:补python基础。48课--50课
字典和集合的基本知识,集合底层是字典实现,集合的所有元素都是字典中的“键对象”
第二个小时:实战
数据处理transforms:
target_transform=Lambda(lambda y: torch.zeros(10, dtype=torch.float).scatter_(0, torch.tensor(y), value=1))
y到底是什么:
pytorch中的 scatter_()函数使用和详解_pytorch scatter-CSDN博客
y = y.scatter(dim,index,src)#三维
#则结果为:
y[ index[i][j][k] ] [j][k] = src[i][j][k] # if dim == 0
y[i] [ index[i][j][k] ] [k] = src[i][j][k] # if dim == 1
y[i][j] [ index[i][j][k] ] = src[i][j][k] # if dim == 2
y = y.scatter(dim,index,src)#二维
#则:
y [ index[i][j] ] [j] = src[i][j] #if dim==0
y[i] [ index[i][j] ] = src[i][j] #if dim==1 y会自动接受数据集的标签或索引。one-hot编码
原文:calls scatter_ which assigns a value=1 on the index as given by the label y.
调用 scatter_ ,它在标签 y 给出的索引上分配 value=1。
scatter_()函数

import torch
a = torch.arange(10).reshape(2,5).float()
b = torch.zeros(3, 5))
b_= b.scatter(dim=0, index=torch.LongTensor([[1, 2, 1, 1, 2], [2, 0, 2, 1, 0]]),src=a)
print(b_)
# tensor([[0, 6, 0, 0, 9],
# [0, 0, 2, 8, 0],
# [5, 1, 7, 0, 4]])

import torchvision.transforms as transforms
# 创建一个预处理流水线
transform = transforms.Compose([
transforms.Resize((32, 32)), # 调整图像尺寸
transforms.ToTensor(), # 将像素从[0, 255]转换到[0, 1]
transforms.Normalize((0.5,), (0.5,)) # 归一化到均值0.5和标准差0.5
])0706
开始每天三小时学习
第一小时:补python基础。51课--54课
在pycharm新建项目时,解释器使用virtualenv和conda的区别:
在PyCharm中新建项目时,选择使用virtualenv和conda作为环境管理工具,它们有以下区别:
-
虚拟环境(virtualenv): 是Python的一种轻量级环境管理方案,它允许你在单一系统上为每个项目创建独立的Python运行环境。当你在PyCharm中使用virtualenv时,会创建一个新的文件夹包含该项目的特定依赖,这使得不同的项目可以避免版本冲突。安装新库时只针对当前虚拟环境。
-
conda: 由 Continuum Analytics 开发,主要用于数据科学和机器学习领域,它创建的是完整的孤立环境,包括所有库、依赖和系统配置。Conda不仅处理Python包,还能管理R、Julia等其他语言环境,以及系统级别的软件。它的优势在于能够更好地管理科学计算所需的复杂依赖。
使用场景:
- 如果项目对依赖管理和隔离要求不高,仅关注Python本身,virtualenv是一个不错的选择。
- 对于数据科学项目,特别是需要处理大量第三方库和跨平台兼容性的情况,推荐使用conda,因为它能提供更全面的包管理。
如何在PyCharm中选择:
- PyCharm支持直接集成这两个工具,在"Settings"(Mac/Linux)或"Preferences"(Windows)-> “Project” -> “Interpreter” 下,可以选择对应的环境管理器,然后添加或激活已有的虚拟环境或conda环境。
学习了选择结构
print("分数是{0},等级是{1}".format(score,grade))
print(f"分数是{grade},等级是{score}")
f.String应用
第二个小时:实战
构建神经网络
nn.Sequential()是PyTorch(深度学习库)中的一个模块,它是Sequential模型容器,用于组合多个神经网络层(例如线性层、卷积层等)。















 1421
1421

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









