







以下参考论文SSD: Single Shot MultiBox Detector
SSD:
SSD只需要一个输入图像和参考标准即可
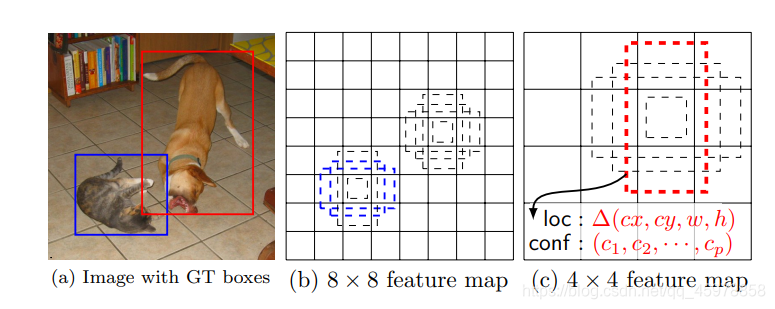
我们在特征地图中每个位置上评估了几个不同比例的默认框(8 × 8和4 × 4)
对于每个默认框,我们预测所有对象类别的形状偏移量和置信度((c1, c2,···,cp))
在训练时,我们首先将这些默认框与参考标准进行匹配
例如,我们将两个默认的盒子分别与猫和狗进行了匹配
模型损失是一个在定位损失(如L1)和置信度损失(如Softmax)之间的加权和
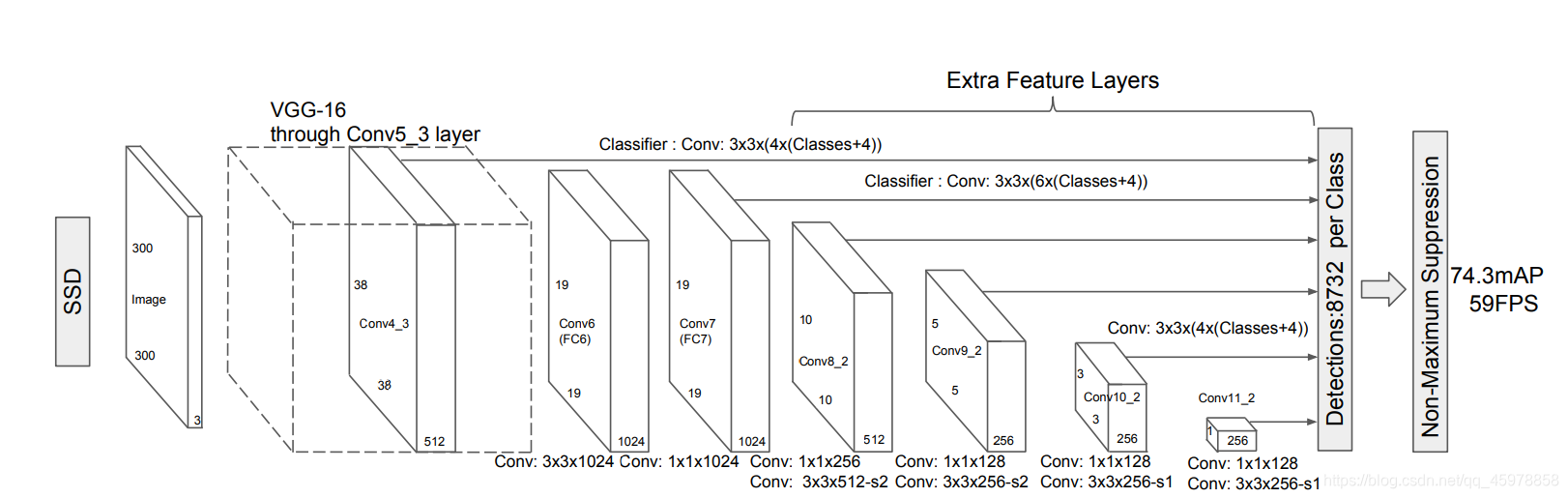
SSD方法基于前馈卷积网络,生成一个固定大小的包围盒集合,并为这些盒中存在的对象类实例评分,然后根据非极大值抑制(Non-Maximum Suppression),以产生最终检测。
PS:非极大值抑制(Non-Maximum Suppression),目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
Multi-scale feature maps for detection(多尺度特征图检测)
我们在截断的基础网络的末端添加了卷积特征层。这些层的大小逐渐减少,并允许在多个尺度上预测探测。对于每个特征层,预测检测的卷积模型是不同的
Convolutional predictors for detection(用于检测的卷积预测器)
每一个添加的特征层(或可选的来自基础网络的现有特征层)都可以使用一组卷积过滤器产生一组固定的检测预测。这些都显示在SSD网络架构之上。对于大小为m × n、有p个通道的特征层,预测潜在检测参数的基本元素是一个3 × 3 × p的小核,它产生一个类别得分,或相对于默认框坐标的形状偏移。在每个m × n的位置应用核,它产生一个输出值。
我们的SSD模型在基础网络的末端添加了几个特征层,这些特征层可以预测不同规模、宽高比和相关置信度的默认框的偏移量。在VOC2007测试中,300 × 300输入尺寸的SSD在准确性上显著优于其448 × 448YOLO对应版本,同时也提高了速度
Default boxes and aspect ratios(默认框和宽高比)
对于网络顶部的多个特征图,我们将一组默认的边界框与每个特征图单元关联起来。默认的盒子以一种卷积的方式平铺特征图,这样每个盒子相对于它相应的单元格的位置是固定的。在每个特征映射单元格中,我们预测相对于单元格中默认框形状的偏移量,以及在每个框中存在类实例的每个类得分。具体来说,对于给定位置k之外的每个方框,我们计算c类得分和相对于初始默认方框形状的4个偏移量。这将导致在特征图的每个位置周围应用的(c + 4)k个滤波器,会生成m × n特征图的(c + 4)kmn输出。
Training:
训练SSD和训练使用区域建议的典型检测器之间的关键区别是,参考信息需要分配到检测器输出的固定集合中的特定输出。
Matching strategy(匹配策略)
在训练期间,我们需要确定哪些默认框和参考目标有联系,并相应地训练网络。对于每个参考目标,我们从默认框中选择,这些默认框会根据位置、宽高比和比例变化。我们首先将每个参考目标匹配到具有最佳jaccard overlap的默认box(如MultiBox[7])。与MultiBox不同的是,我们将默认框匹配到所有具有大于阈值(0.5)的jaccard overlap的参考目标。这简化了学习问题,允许网络预测多个重叠默认框的高分,而不是只选择最大重叠的那个。
jaccard overlap:

Training objective
总体目标损失函数为定位损失(loc)和置信度损失(conf)的加权和:
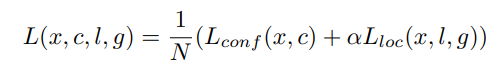
设 x i j p x^p_{ij} xijp={
0 , 1 0,1 0,1}是匹配类别p的第i个默认框和第j个参考目标框的指示符。所以 ∑ i x i j p \sum_ix_{ij}^p ∑ixij
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8561
8561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











