










SSD(Single Shot MultiBox Detector)是一种用于目标检测的深度学习模型,特点是能够在单次前向传递中同时预测多个边界框及其类概率,因此具备优良的速度和精度。SSD 把目标检测视为一个回归问题,通过在不同尺度下的特征图上进行预测来实现多尺度检测。
一、SSD 的主要特点
1. 单次推理:SSD 在一个前向传递中同时生成多个检测结果,速度较快,适合实时应用。
2. 多尺度检测:结合了不同尺度的特征图,使其可以检测不同尺寸的目标。
3. Anchor Boxes:SSD 使用预设的不同长宽比和尺寸的锚框(Anchor Boxes),进行边界框的预测。
4. 卷积层基础:SSD 基于卷积神经网络(通常使用 VGG16 或 MobileNet 作为主干网络)提取特征。
二、SSD 的结构
SSD 的基本结构通常包括以下几个部分:
特征提取网络(如 VGG16):用于提取图像的特征。
多个卷积层:用于在不同尺度上生成预测。
预测层:为每个锚框预测类标签和边界框的偏移。
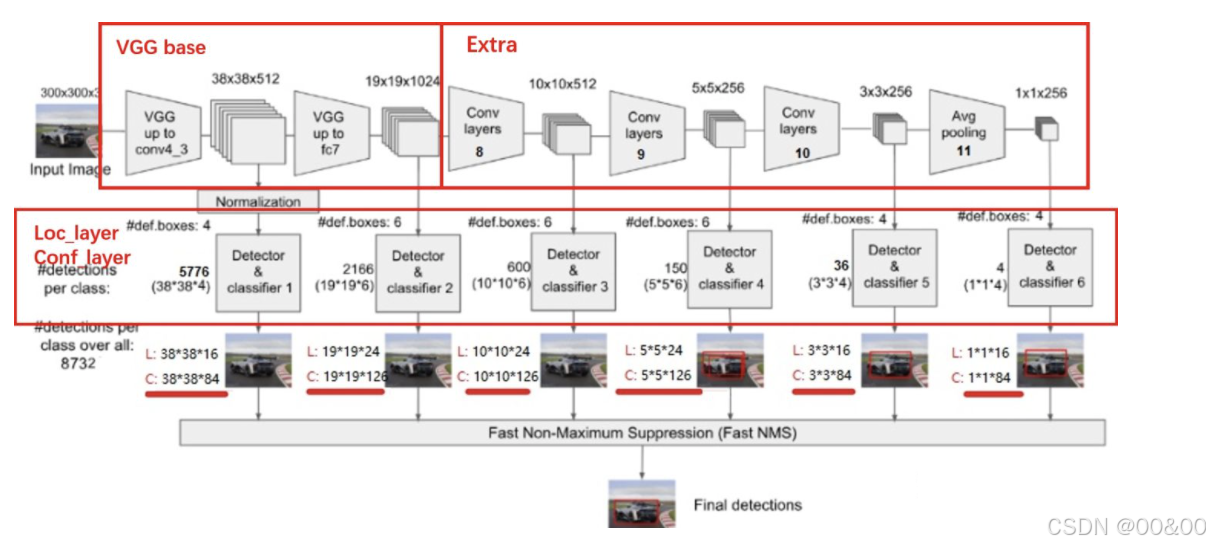
三、SSD 示例代码
下面是一个简化的 SSD 模型实现,使用 PyTorch 框架。这个示例展示了模型结构的基本组成,以及如何进行训练和推理。
1. SSD 示例代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义 SSD 模型结构
class SSD(nn.Module):
def __init__(self, num_classes):
super(SSD, self).__init__()
self.num_classes = num_classes
# 使用 VGG16 作为特征提取网络
self.vgg = self._create_vgg()
# 检测头
self.extras = self._create_extras()
self.localization = nn.Conv2d(512, 4 * 8732, kernel_size=3, padding=1) # 8732是 SSD 在 VGG 计算的锚框总数
self.softmax = nn.Conv2d(512, num_classes * 8732, kernel_size=3, padding=1)
def _create_vgg(self):
layers = []
layers.append(nn.Conv2d(3, 64, kernel_size=3, padding=1))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
# 添加更多的卷积层和池化层以形成 VGG16 网络...
layers.append(nn.Flatten())
return nn.Sequential(*layers)
def _create_extras(self):
layers = []
# 添加额外的卷积层作为特征尺度扩展...
return nn.Sequential(*layers)
def forward(self, x):
features = self.vgg(x)
loc = self.localization(features)
conf = self.softmax(features)
return loc, conf
# 数据加载
def get_data_loader(batch_size):
transform = transforms.Compose([
transforms.Resize((300, 300)),
transforms.ToTensor(),
])
dataset = datasets.FakeData(transform=transform, size=1000) # 使用 FakeData 作为占位符
data_loader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
return data_loader
# 自定义损失函数(简化)
def compute_loss(loc_preds, conf_preds, loc_targets, conf_targets):
loc_loss = nn.MSELoss()(loc_preds, loc_targets) # 使用 MSE 作为占位符
conf_loss = nn.CrossEntropyLoss()(conf_preds, conf_targets)
return loc_loss + conf_loss
# 训练模型
def train(model, data_loader, num_epochs, learning_rate):
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(num_epochs):
epoch_loss = 0
for images, _ in data_loader:
optimizer.zero_grad()
loc_preds, conf_preds = model(images)
loc_targets = torch.zeros_like(loc_preds) # 替换为真实标签
conf_targets = torch.zeros_like(conf_preds) # 替换为真实标签
loss = compute_loss(loc_preds, conf_preds, loc_targets, conf_targets)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
print(f"Epoch [{epoch + 1}/{num_epochs}] Loss: {epoch_loss / len(data_loader):.4f}")
# 测试模型
def test(model, data_loader):
model.eval()
with torch.no_grad():
for images, _ in data_loader:
loc_preds, conf_preds = model(images)
print("Location predictions shape:", loc_preds.shape)
print("Confidence predictions shape:", conf_preds.shape)
# 示例用法
if __name__ == "__main__":
num_classes = 20 # 假设有 20 类
model = SSD(num_classes)
# 获取数据加载器
data_loader = get_data_loader(batch_size=16)
# 训练模型
num_epochs = 10
learning_rate = 0.001
train(model, data_loader, num_epochs, learning_rate)
# 测试模型
test(model, data_loader)2. 代码说明
SSD 类:定义了 SSD 模型的基本结构,包括特征提取网络(简化的 VGG)和检测头。
数据准备:这里使用 `FakeData` 作为示例数据集。在实际使用时,需加载真实数据集,并进行必要的预处理。
损失计算:定义了一个简单的损失计算函数,包括位置和置信度的损失,实际中应根据具体需求进行优化。
训练函数:实现了模型的训练循环,通过调用损失计算函数更新模型权重。
测试函数**:在测试期间输出位置和置信度的预测结果形状,以检查模型输出。
3. 注意事项
以上代码为 SSD 的简化展示,实际实现需考虑更多参数、数据增强、锚框生成和目标标签等细节。
实际使用 SSD 时,建议深入理解其论文中的细节,并查看现有的实现库,如显著的 PyTorch 实现。可以参考 [TensorFlow Object Detection API](https://github.com/tensorflow/models/tree/master/research/object_detection) 或其他开源实现,以便于学术研究和商业应用。


















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











