







TensorRT工作流程
官方给出的步骤:
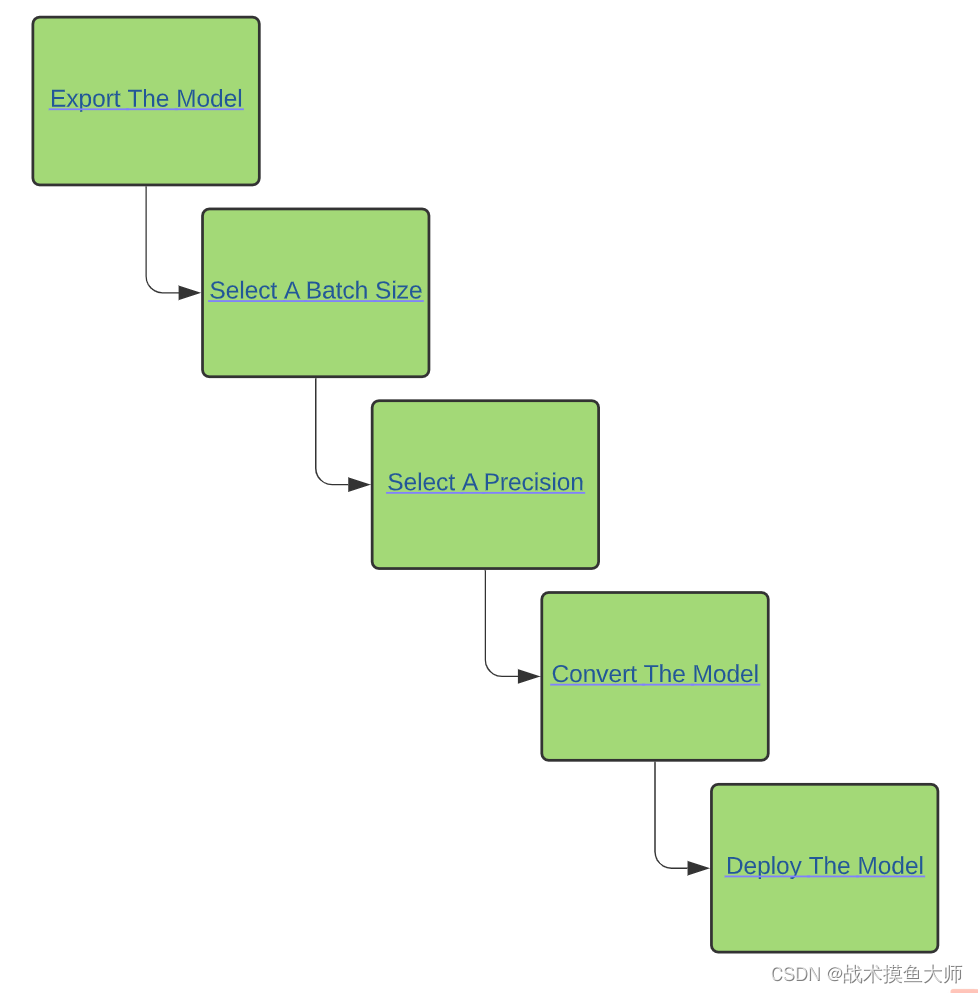
总结下来可以分为两大部分:
- 模型生成:将onnx经过一系列优化,生成tensorrt的engine模型
- 选择batchsize,选择精度precision,模型转换
- 模型推理:使用python或者C++进行推理
入门Demo
生成trt模型:
trtexec --onnx=yolov5s.onnx --saveEngine=yolov5s.trt
# trtexec是TensorRT自带的工具,如果运行显示is no command,把TensorRT安装路径下的bin文件夹加入到path中然后source一下就行了。
然后就坐等输出模型,我们可以根据log信息看一下tensorRT都干了什么:
=== Model Options ===
=== Build Options ===
Precision: FP32
=== System Options ===
=== Inference Options ===
=== Reporting Options ===
# 这几部分是一些选项设置,不用看,目前只需要看精度这一项
=== Device Information ===
# 设备信息
[TRT] CUDA lazy loading is not enabled.
# 这里提到了CUDA lazy loading,这个是CUDA11.8新增的延时加载功能。
# 初始化时不加载kernel,只有用相应的kernel才会加载,是CUDA层面的特性。
# 这个特性会导致第一次推理比较慢,因为第一次推理要加载用到的kernel函数
# 我们后面会先更几篇番外初步速成一下cuda,后面用到cuda的地方会很多
Start parsing network model.
[03/11/2024-22:37:43] [I] [TRT] ----------------------------------------------------------------
[03/11/2024-22:37:43] [I] [TRT] Input filename: yolov5s.onnx
[03/11/2024-22:37:43] [I] [TRT] ONNX IR version: 0.0.8
[03/11/2024-22:37:43] [I] [TRT] Opset version: 17
[03/11/2024-22:37:43] [I] [TRT] Producer name: pytorch
[03/11/2024-22:37:43] [I] [TRT] Producer version: 2.2.1
[03/11/2024-22:37:43] [I] [TRT] Domain:
[03/11/2024-22:37:43] [I] [TRT] Model version: 0
[03/11/2024-22:37:43] [I] [TRT] Doc string:
[03/11/2024-22:37:43] [I] [TRT] ----------------------------------------------------------------
# 解析模型
[TRT] onnx2trt_utils.cpp:374: Your ONNX model has been generated with INT64 weights, while TensorRT does not natively support INT64. Attempting to cast down to INT32.
# 提醒我们的模型时INT64的,会被压缩到INT32
[TRT] Graph optimization time: 0.021841 seconds.
# 进行图优化
[TRT] [GraphReduction] The approximate region cut reduction algorithm is called.
# 进行图简化/图规约
Using random values for input images
[03/11/2024-22:39:14] [I] Input binding for images with dimensions 1x3x640x640 is created.
[03/11/2024-22:39:14] [I] Output binding for output0 with dimensions 1x25200x85 is created.
[03/11/2024-22:39:14] [I] Starting inference
# 会进行一次推理,tracing数据流过的算子以及时间
得到模型后开始进行部署:
import tensorrt as trt
import numpy as np
import pycuda.driver as cuda
import pycuda.autoinit
N_CLASSES = 80 # yolov5 class label number
BATCH_SIZE=1
PRECISION= np.float32
dummy_input_batch = np.zeros((BATCH_SIZE,3,640,640),dtype=PRECISION)
f = open("yolov5s.trt", "rb")
runtime = trt.Runtime(trt.Logger(trt.Logger.WARNING))
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
output = np.empty(N_CLASSES, dtype = PRECISION) # Need to set both input and output precisions to FP16 to fully enable FP16
d_input = cuda.mem_alloc(1 * dummy_input_batch.nbytes)
d_output = cuda.mem_alloc(1 * output.nbytes)
bindings = [int(d_input), int(d_output)]
stream = cuda.Stream()
def predict(batch): # result gets copied into output
# Transfer input data to device
cuda.memcpy_htod_async(d_input, batch, stream)
# Execute model
context.execute_async_v2(bindings, stream.handle, None)
# Transfer predictions back
cuda.memcpy_dtoh_async(output, d_output, stream)
# Syncronize threads
stream.synchronize()
return output
pred = predict(dummy_input_batch)
print(pred.shape)
今天blog的主题是跑通tensorRT的整个流程,yolov5的后处理比较麻烦,这不是今天blog的主题,所以没有写,后面有空补上。
如果感觉有帮助,点赞收藏+关注!thanks!















 1931
1931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









