







前言
本算法是在LightGCN的代码上的基础实现的,LightGCN的代码和原理参考我前面几篇的博客:推荐系统笔记(六):LightGCN代码实现_甘霖那的博客-CSDN博客
由于LightGCN等传统基于图神经网络的算法有以下局限性:
(1)高度节点对表征学习的影响更大,低度(长尾)节点的推荐效果更差;
(2)表示容易受到噪声交互的影响,因为邻域聚合方案进一步扩大了观察到的边的影响。
(3)目前大多数推荐学习任务都是基于监督学习的范式,其中监督信号一般指用户和物品的交互数据。然而这些交互数据通常来说是异常稀疏的,不足以学习高质量的表征。
因此,将自监督学习(Self-supervised Learning, SSL)在用户-物品二部图上的应用,辅助推荐模型训练学习,应用self-discrimination来学习更加鲁棒的节点表征是必要的。
代码讲解
损失函数
由于SGL中的损失函数由BPR+InfoNCE+Reg三部分组成,即:
![]()
因此需要将损失函数该为如下形式:
def BPR_InfoNCE_Reg_loss(self, S, emb, emb1,emb2, init_emb):
S = np.array(S).astype('int') # [64,3]
# print("S:{}".format(S.shape))
all_user_emb, all_item_emb = torch.split(emb, [self.n_users, self.n_items])
all_user_emb0, all_item_emb0 = torch.split(init_emb, [self.n_users, self.n_items])
sub_all_user_emb1, sub_all_item_emb1 = torch.split(emb1, [self.n_users, self.n_items])
sub_all_user_emb2, sub_all_item_emb2 = torch.split(emb2, [self.n_users, self.n_items])
# print("all_user_emd:{}".format(all_user_emb.shape)) # [610,64]
# print("all_item_emd:{}".format(all_item_emb.shape)) # [9724,64]
pos_emb = all_item_emb[S[:, 1]] # [64,64]
neg_emb = all_item_emb[S[:, 2]] # [64,64]
user_emb = all_user_emb[S[:, 0]] # [64,64]
# print("pos norm",torch.norm(pos_emb).item())
# print("neg norm",torch.norm(neg_emb).item())
# print("user norm",torch.norm(user_emb).item())
# print(pos_emb.shape,neg_emb.shape,user_emb.shape)
pos_emb0 = all_item_emb0[S[:, 1]]
neg_emb0 = all_item_emb0[S[:, 2]]
user_emb0 = all_user_emb0[S[:, 0]]
user_embeddings1 = F.normalize(sub_all_user_emb1, dim=1) # [610,64]
item_embeddings1 = F.normalize(sub_all_item_emb1, dim=1) # [9724,64]
user_embeddings2 = F.normalize(sub_all_user_emb2, dim=1)
item_embeddings2 = F.normalize(sub_all_item_emb2, dim=1)
# print("user_embedding:{}".format(user_embeddings1.shape))
# print("item_embedding:{}".format(item_embeddings1.shape))
user_embs1 = user_embeddings1[S[:, 0]] # [64,64]
item_embs1 = item_embeddings1[S[:, 1]] # [64,64]
user_embs2 = user_embeddings2[S[:, 0]] # [64,64]
item_embs2 = item_embeddings2[S[:, 1]] # [64,64]
# print(user_embs1.shape,item_embs1.shape)
similar_users = torch.sum(user_embs1*user_embs2,dim=-1)
similar_items = torch.sum(item_embs1*item_embs2,dim=-1)
total_user = torch.matmul(user_embs1,
torch.transpose(user_embeddings2, 0, 1))
total_item = torch.matmul(item_embs1,
torch.transpose(item_embeddings2, 0, 1))
# BPR Loss
loss = (F.softplus(torch.sum(user_emb * neg_emb, dim=1) - torch.sum(user_emb * pos_emb, dim=1))).sum()
loss=loss
# print("begin:{}".format(loss))
# InfoNCE Loss
SGL_logits_user = total_user - similar_users[:, None]
SGL_logits_item = total_item - similar_items[:, None]
InfoLoss_user = torch.logsumexp(SGL_logits_user / self.temperature, dim=1)
InfoLoss_item = torch.logsumexp(SGL_logits_item / self.temperature, dim=1)
InfoNCE_loss = 0.005*torch.sum(InfoLoss_user + InfoLoss_item)
loss += InfoNCE_loss
# print(InfoNCE_loss)
# Reg Loss
loss += self.lamda * (
torch.norm(pos_emb0) ** 2 + torch.norm(neg_emb0) ** 2 + torch.norm(user_emb0) ** 2) / float(
len(pos_emb))
# print(loss)
return loss其中的参数emb、emb1、emb2分别是未被drop边或者点的原始图网络、和被随机drop后的网络经过forward后得到的表示编码结果。S是对一个batch的数据进行索引取出对应的数据进行训练。
而又在论文中提出了三种不同的数据增强方法:
Node Dropout(ND):图中每个节点都可能以概率 ρ 被舍弃,连带其连接的边一起舍弃。具体 s1 和 s2 如下建模:
![]()
因为需要两个图才能进行对比,因此需要构建两个不同的子图,M’和M'’分别去drop掉数据。
Edge Dropout(ED):图中每条边都可能以概率 ρ被舍弃。具体如下表示:
![]()
Random Walk (RW):上述两个操作符生成的子图在图卷积的所有层中保持一致。而这里的RW是指的每一层的M'和M''都是不同的,即层与层之间的dropout不共享:
![]()
上述操作符只有dropout和masking操作,没有增加任何模型参数。
ND:随即删除点和对应的连边
def create_ND(self,ratio,mat1):
mat = mat1
drop_user_idx = self.random_choice(self.n_users, int(self.n_users * ratio))
drop_item_idx = self.random_choice(self.n_items, int(self.n_items * ratio))
indicator_user = np.ones(self.n_users)
indicator_item = np.ones(self.n_items)
indicator_user[drop_user_idx] = 0
indicator_item[drop_item_idx] = 0
mask = diags(np.hstack((indicator_user, indicator_item)))
mat=(mask @ mat @ mask)
# print(mat)
d_mat = mat.sum(axis=1)
d_mat = np.sqrt(d_mat)
d_mat = np.array(d_mat)
d_mat = 1 / (d_mat.reshape(-1))
d_mat[np.isinf(d_mat)]=0.
d_mat = diags(d_mat)
d_mat = d_mat.tocoo()
final = (d_mat @ mat @ d_mat).tocoo()
# print(final.shape)
rows = torch.tensor(final.row)
cols = torch.tensor(final.col)
index = torch.cat([rows.reshape(1, -1), cols.reshape(1, -1)], dim=0)
return torch.sparse_coo_tensor(index, torch.tensor(final.data)).to(self.device)
传入要drop掉的比例和对应的邻接矩阵的表示,维度为(M+N,M+N),M代表用户个数,N代表物品个数。这里直接构建了两个mask矩阵,q是两个对角阵,唯独分别为M+N和N+M,对应要drop掉的用户的元素置为零,其他对角元素为,然后对应相乘即可实现随机drop掉点和边。
ED和RW:随机删除边
def create_ED_RW(self, count, ratio):
row_arr = np.zeros(2 * count, dtype=np.int32)
col_arr = np.zeros(2 * count, dtype=np.int32)
data = np.ones(2 * count, dtype=np.int32)
# 随机drop
drop_data_index = self.random_choice(count, int(count * ratio))
count = 0
for key in self.train.keys():
for value in self.train[key]:
if count in drop_data_index:
data[count]=0
row_arr[count] = int(key)
col_arr[count] = self.n_users + int(value)
count += 1
count1=count
for key in self.train.keys():
for value in self.train[key]:
if count-count1 in drop_data_index:
data[count]=0
row_arr[count] = self.n_users + int(value)
col_arr[count] = int(key)
count += 1
# print("row:{} colum:{}".format(len(row_arr),len(col_arr)))
mat = coo_matrix((data, (row_arr, col_arr)),shape=(self.n_users+self.n_items,self.n_users+self.n_items))
d_mat = mat.sum(axis=1)
d_mat = np.sqrt(d_mat)
d_mat = np.array(d_mat)
d_mat = 1 / (d_mat.reshape(-1))
d_mat[np.isinf(d_mat)] = 0.
d_mat = diags(d_mat)
d_mat = d_mat.tocoo()
final = (d_mat @ mat @ d_mat).tocoo()
# print(final.shape)
rows = torch.tensor(final.row)
cols = torch.tensor(final.col)
# print(rows.reshape(1, -1).shape,cols.reshape(1, -1).shape)
index = torch.cat([rows.reshape(1, -1), cols.reshape(1, -1)], dim=0)
return torch.sparse_coo_tensor(index, torch.tensor(final.data)).to(self.device)随即将coo_matrix的data置为零即可实现边的drop,值得注意的是RW是每一层的layer都不同,因此需要循环多次实现:
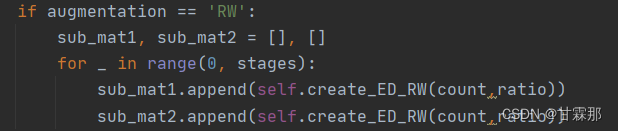
对应的在forward的步骤中也要设置多次循环传播,并且取结果平均值:
# print(emb.shape)
for i in range(stages):
if isinstance(mat, list):
# print(emb.shape,mat[i].shape)
emb = torch.sparse.mm(mat[i], emb)
emb_list.append(emb)
# print("emb norm", torch.norm(emb).item())
else:
emb = torch.sparse.mm(mat, emb)
emb_list.append(emb)
其他评估函数的不变或者变化不大,这里不再做讲解。
运行文件:train.py
from SGL import SGL
import torch
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print('device:',device)
model = SGL('Movielens/ml-latest-small/train.txt', lr = 1e-3,device = device,stages=3,augmentation='ED',ratio=0.1)
model.to(device)
model.load_test_data('Movielens/ml-latest-small/test.txt')
# model.load_test_data('yelp2018/test.txt')
# model.load_test_data('gowalla/test.txt')
model.train_model(stages=3,logger_path='ED_result.pkl')
model.evaluate(20)
model1 = SGL('Movielens/ml-latest-small/train.txt', lr = 1e-3,device = device,stages=3,augmentation='ND',ratio=0.1)
model1.to(device)
model1.load_test_data('Movielens/ml-latest-small/test.txt')
model1.train_model(stages=3,logger_path='ND_result.pkl')
model1.evaluate(20)
model1 = SGL('Movielens/ml-latest-small/train.txt', lr = 1e-3,device = device,stages=3,augmentation='ND',ratio=0.1)
model1.to(device)
model1.load_test_data('Movielens/ml-latest-small/test.txt')
model1.train_model(stages=3,logger_path='RW_result.pkl')
model1.evaluate(20)分别测试三种随机数据增强的方式的结果,并且保存到对应的pkl文件中以供数据可视化。
运行结果展示:
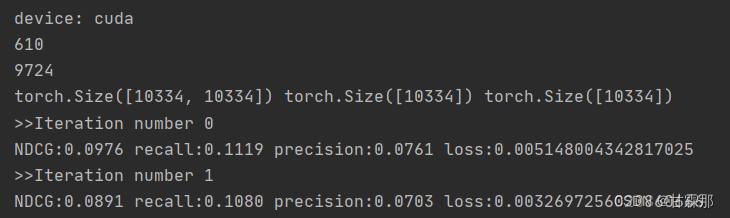

















 915
915

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









