







1.论文介绍
LeSAM: Adapt Segment Anything Model for medical lesion segmentation
LeSAM:适用于医学病变分割的任意分割模型
2024年发表于 JBHI
Paper 无code
2.摘要
Segment Anything Model,SAM是自然图像分割领域的一个基础性模型,取得了令人印象深刻的成果。然而,对于医学图像分割,它的性能仍然是次优的,特别是在描绘不规则形状和低对比度的病变时。这可以归因于医学图像和自然图像之间的显著域差距,而SAM最初是在自然图像上进行训练的。本文提出了一种专门为病变分割量身定做的SAM算法,称为LeSAM。LeSAM首先通过一个高效的自适应模块学习医学特定领域的知识,并将其与从预先训练的SAM获得的一般知识相结合。随后,我们利用这些合并的知识,使用作为轻量级U型网络设计实现的改进的掩模解码器来生成病变掩模。这种修改可以更好地描绘病变边界,同时便于培训。
Keywords:SAM, U型解码器,自适应编码器模块
3.Introduction
病变分割在医学图像分析中起着至关重要的作用,有助于精确定位和量化病变区域,以便及早发现和治疗疾病。然而,由于医学图像的复杂性和多样性,准确的病变分割仍然具有很大的挑战性。在本文中,通过简单而有效的策略提出了一种通用的病变分割模型–LeSAM。首先,在原始SAM编码器的每个转换模块中使用两个适配器模块来顺序地合并和提炼特定于任务的知识。此外,我们采用渐进式学习方法来促进适配器模块的训练,而不依赖于大规模的注释医疗数据。其次,受U型网络通过渐进上采样和捷径操作集成多分辨率特征的成功启发,我们将原有的掩码解码器修改为U型模块,并从头开始训练。
4.模型结构详解

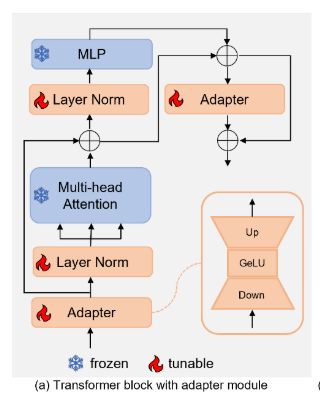
如图所示,LeSAM包括三个模块:修改的图像编码器、提示编码器和修改的掩码解码器。为了能够提取潜在的医学特定特征,可调适配器模块被结合到原始图像编码器的每个变换器块中;提示编码器以框模式保持其原始结构,其中提供边界框以指示目标在每个输入图像中的位置;掩模解码器被修改为U形结构,以增强模糊和不规则病变边界的描绘。此外,冻结了原始图像编码器的参数,同时保持提示编码器和掩码解码器都是可调的。
医用专用图像编码器:
由于自然图像和医学图像之间存在领域鸿沟,原始图像编码者很难获取潜在的医学特定知识。因此,在原始图像编码器的每个变换器块中都加入了适配器模块,以有效地弥合这一差距。改装的transformer块的具体架构如图所示,每个transformer块中都集成了两个适配器,其中每个适配器依次包括下投影线性层、Gelu激活层和上投影线性层。第一个适配器位于变压器块的开始处,以引入医学特定知识,然后将其与预先训练的SAM学习的一般知识相结合。另一个适配器被放置在块的末尾,以优化集成的跨域知识和提炼图像特征。
在image-encoder的每一个transformer块中有两个adapter,一个在开头,接收传入的特征;一个在块结尾,融合中间特征和最终特征再处理。每个adapter包含一个特征降维的线性层,GeLU激活层和一个特征扩展的线性层。
特定于任务的掩码解码器:
由于病变典型的不规则形状和与周围组织的低对比度,原始的SAM掩模解码器在准确描绘病变边界方面的性能不佳。因此开发了一种特定于任务的掩码解码器来增强边缘描绘能力,以实现精确的病变分割。如模型图所示,将特定任务的掩码解码器设计为U型结构。保留了自注意块和双向交叉注意块(提示到图像嵌入,反之亦然)来生成掩码嵌入(带有提示信息的图像嵌入)和IOU分数。随后,没有对掩码嵌入进行上采样来生成输出掩码,而是通过改进的U型解码器来传播它们。
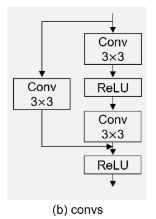
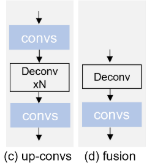
考虑到图像编码器的图像嵌入具有64×64(如果image size是1024×1024则是64)的分辨率,对这三个中间图像嵌入分别使用“卷积”和“上卷积”,以获得不同分辨率和通道的新图像嵌入。具体地说,如下图所示,“卷积”包括卷积和用于重新编码图像嵌入的短连接,“上卷积”通过在两个“卷积”块之间加入一个或两个反卷积层而建立在“卷积”之上。每个反卷积层执行图像嵌入的两倍上采样。随后,从掩模嵌入和等维图像嵌入开始,逐步融合和传播这些级联表示,直到它们的分辨率与输入图像的分辨率匹配。如下图所示,融合过程依次由反卷积操作和随后的“卷积”块组成。反卷积被用来提高级联嵌入的分辨率,而卷积用于对它们进行进一步编码。最后,利用嵌入来生成预测掩码。在模型图底部直观地展示了掩码解码器的中间特征图。前三个特征图以从左到右的方式描述不同级别的特征,从低级特征(如边缘和局部特征)到高级特征(如形状和全局特征)。最后三个映射表示解码的特征,第一个解码的特征映射展示了提示信息的并入,将模型的注意力引导到感兴趣的区域,促进了语义知识的获取。这种获得的语义知识随后通过两个融合阶段进行提炼,最终产生预测的掩码。重要的是要注意,功能映射具有不同的分辨率。
原来的decoder输出在自注意力和交叉注意力的时候就停止,不膨胀了输入U型decoder中。本文取了image-encoder的三个中间张量,先用卷积,再反卷积上采样,最后卷积。与原decoder的输出cat,与Unet解码器相同,使用反卷积上采样再卷积融合,再cat再处理(就是模型图下方的操作)。对于卷积操作:本文采用了卷积和短连接。
短连接是残差连接,就是一个卷积激活再卷积,一个直接一个卷积后与那个加和,再relu激活。
渐进式训练策略:
本文还通过t-SNE算法对比了自然图像和医学图像的特征,发现两者之间虽然有一些共享特征,但总体上差异显著。这提示在直接训练模型进行医学图像分割时可能会遇到困难,因此需要考虑专门的训练策略来应对这些挑战。
本文采用渐进式学习策略,将模型从自然图像分割逐步训练到医学病变分割。整个训练过程包括自我监督预训阶段和监督学习阶段。为了实现从自然图像到医学图像的领域自适应,首先使用廉价的无标签医学数据进行适配器模块的初步训练。这些数据通过MAE(Masked Autoencoder)方法进行自监督学习。在这个阶段,解码器是MAE的解码器,使用均方误差(MSE)来重建部分掩盖的图像嵌入:
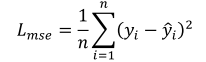
其中𝑦𝑖和𝑦̂𝑖分别表示原始图像和重建图像。在MAE之后,丢弃简单的解码器,并且使用特定于任务的数据集来使用骰子损失和交叉熵损失之和来训练适配器和其他可调组件,其公式如下:
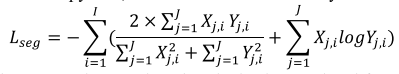
说明
这个模型的创新在于:
- 基于SAM,image-encoder增加adapter;
- decoder保留一部分,从encoder里抽取三层特征,做一个u型结构,使用卷积和反卷积处理;
- 训练采用渐进式,包括自监督和全监督,后者采用模型结构。















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









