






第五讲 用pytorch实现线性回归
B站 六二大人,参考up错错莫,并加入了自己的思考(特别鸣谢)、
PyTorch Fashion(风格)
1、prepare dataset
2、design model using Class # 目的是为了前向传播forward,即计算y hat(预测值)
3、Construct loss and optimizer (using PyTorch API) 其中,计算loss是为了进行反向传播,optimizer是为了更新梯度。
4、Training cycle (forward,backward,update)训练周期:前馈(算损失),反馈(算梯度),更新
(梯度下降算法更新梯度)
代码实现如下:
#利用pytorch提供的工具重现线性模型的训练过程
import torch
#1.prepare dataset
#x,y是矩阵,3行1列,也就是说总共有3个数据,每个数据只有1个特征
x_data=torch.tensor([[1.0],[2.0],[3.0]])
y_data=torch.tensor([[2.0],[4.0],[6.0]])
'''
我们的模型类应该继承自nn.Module,它是所有神经网络模块的基类。
必须实现成员方法__init__()和forward()
类神经网络。线性包含两个成员张量:权重和偏差
类神经网络。Linear实现了魔术方法__call__(),它启用了can类的实例
像函数一样被调用。通常forward()会被调用
'''
#2.design model using Class
class LinearModel(torch.nn.Module):
def __init__(self) : #构造函数:初始化对像
super(LinearModel,self).__init__()
#(1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的 pytorch中的自带的类
#该线性层需要学习的参数是w和b 获取w/b的方式分别是 linear.weight/linear.bias
self.linear=torch.nn.Linear(1,1)
def forward(self,x): #前馈
y_pred=self.linear(x)
return y_pred
model=LinearModel() #可调用的
#3.Construct loss and optimizer (using PyTorch API)
#criterion = torch.nn.MSELoss(size_average = False)
criterion=torch.nn.MSELoss(reduction='sum')
optimizer=torch.optim.SGD(model.parameters(),lr=0.01) #优化器,lr为学习率
#4.Training cycle (forward,backward,update)
for epoch in range(100):
y_pred=model(x_data) #forward:predict
loss=criterion(y_pred,y_data) #forward::loss
print(epoch,loss.item())
optimizer.zero_grad() #the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zero
loss.backward() #backward:autograd.自动计算梯度
optimizer.step() #update 参数,即更新w和b的值
print('w=',model.linear.weight.item())
print('b=',model.linear.bias.item())
x_test=torch.tensor([[4.0]])
y_test=model(x_test)
print('y_pred=',y_test.data)
针对代码的一些说明:
1,Module实现了魔法函数__call__(),call()里面有一条语句是要调用forward()。因此新写的类中需要重写forward()覆盖掉父类中的forward() pytorch 之 call, init,forward
2,call函数的另一个作用是可以直接在对象后面加(),例如实例化的model对象,和实例化的linear对象
3,本算法的forward体现是通过以下语句实现的:
y_pred=model(x_data)
由于魔法函数call的实现,model(x_data)将会调用model.forward(x_data)函数,model.forward(x_data)函数中的
self.linear(x)也由于魔法函数call的实现将会调用torch.nn.Linear类中的forward,至此完成封装,也就是说forward最终是在torch.nn.Linear类中实现的,具体怎么实现,可以不用关心,大概就是y= wx + b。
y_pred=self.linear(x)
代码运行结果:
0 40.3581428527832
1 18.083389282226562
2 8.165614128112793
3 3.748844623565674
4 1.7809900045394897
5 0.9033467173576355
6 0.5110559463500977
7 0.3348537087440491
8 0.2548712491989136
9 0.21774452924728394
10 0.19971825182437897
11 0.19021621346473694
12 0.1845303773880005
13 0.18056391179561615
14 0.17738395929336548
15 0.17457419633865356
16 0.17194940149784088
17 0.16942675411701202
18 0.1669686883687973
19 0.16455870866775513
20 0.16218926012516022
21 0.15985627472400665
22 0.1575579196214676
23 0.15529319643974304
24 0.15306130051612854
25 0.1508614420890808
26 0.1486935019493103
27 0.14655640721321106
28 0.14445006847381592
29 0.1423741579055786
30 0.14032785594463348
31 0.13831135630607605
32 0.13632339239120483
33 0.13436433672904968
34 0.13243329524993896
35 0.13053008913993835
36 0.12865392863750458
37 0.12680499255657196
38 0.12498261779546738
39 0.12318658083677292
40 0.12141622602939606
41 0.11967117339372635
42 0.11795137822628021
43 0.11625609546899796
44 0.11458538472652435
45 0.11293861269950867
46 0.11131551861763
47 0.10971579700708389
48 0.10813894867897034
49 0.10658474266529083
50 0.10505300760269165
51 0.10354316979646683
52 0.10205519944429398
53 0.10058861970901489
54 0.0991429015994072
55 0.0977180153131485
56 0.09631367027759552
57 0.09492950141429901
58 0.0935652107000351
59 0.09222042560577393
60 0.09089517593383789
61 0.08958873152732849
62 0.08830136060714722
63 0.08703213185071945
64 0.08578148484230042
65 0.08454860001802444
66 0.08333368599414825
67 0.08213594555854797
68 0.08095546066761017
69 0.07979203760623932
70 0.07864529639482498
71 0.07751508802175522
72 0.07640109956264496
73 0.07530303299427032
74 0.07422088831663132
75 0.07315417379140854
76 0.07210292667150497
77 0.07106667757034302
78 0.07004524767398834
79 0.06903868913650513
80 0.06804654002189636
81 0.06706841289997101
82 0.06610462814569473
83 0.06515450030565262
84 0.06421814858913422
85 0.06329526752233505
86 0.062385573983192444
87 0.0614890530705452
88 0.06060539186000824
89 0.059734322130680084
90 0.058875881135463715
91 0.058029744774103165
92 0.05719570815563202
93 0.056373849511146545
94 0.05556365102529526
95 0.054764971137046814
96 0.05397798866033554
97 0.05320228636264801
98 0.052437663078308105
99 0.051684003323316574
w= 1.8486541509628296
b= 0.34404438734054565
y_pred= tensor([[7.7387]])
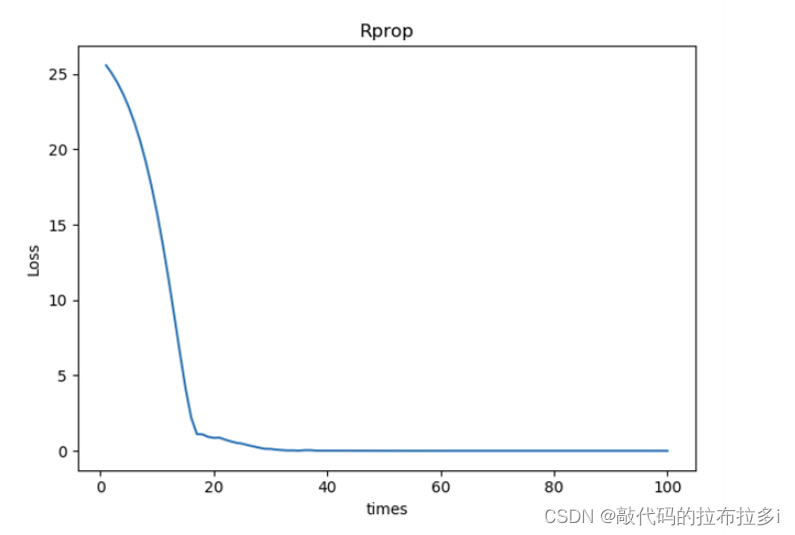
作业:不同的优化器,他们的性能在使用上有什么区别?
以下包含了Adagrad Adam adamax ASGD RMSprop Rprop SGD七种优化器的loss下降图
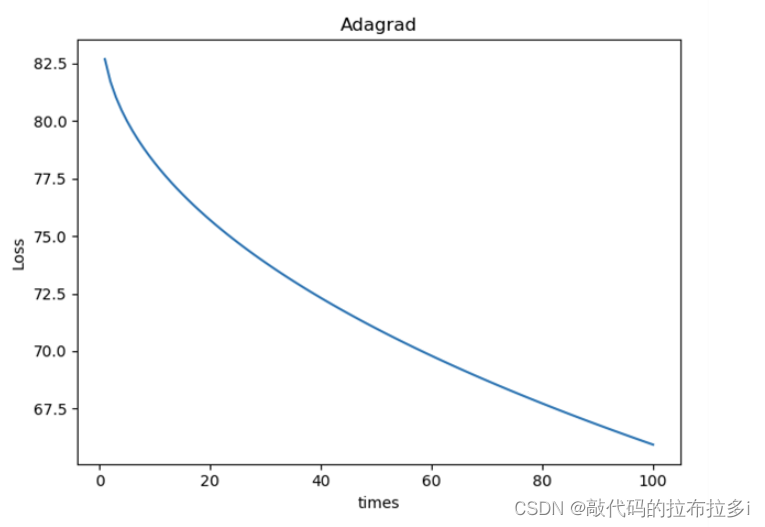

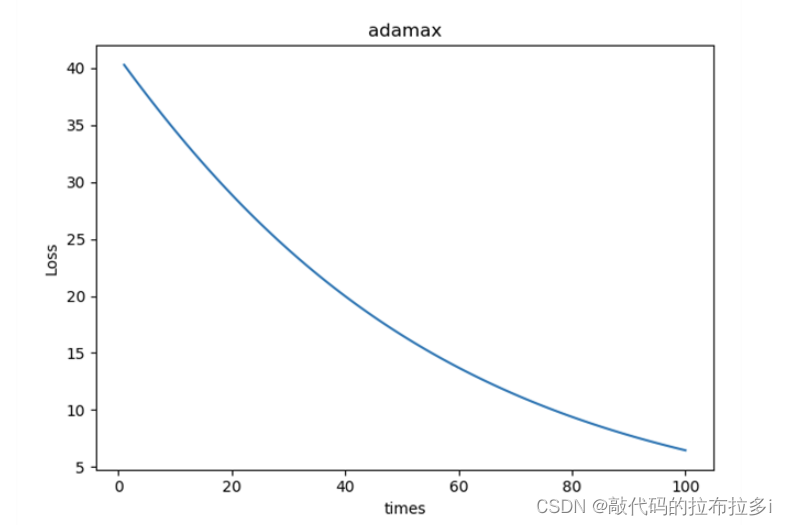
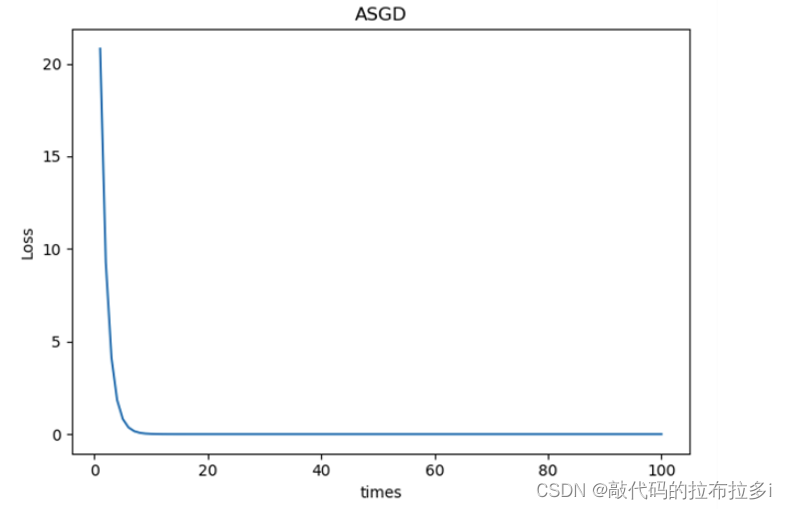
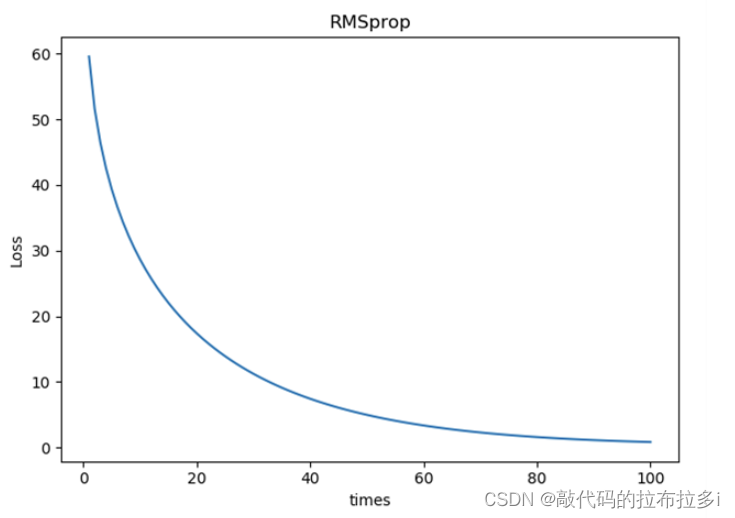
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









