







 本文详细回顾了人工智能生成内容(AIGC)背景下,扩散模型在视频生成、编辑和理解中的应用,涵盖了DDPM、SGM和ScoreSDE等技术。文章还讨论了挑战和未来发展趋势,如数据集规模、训练效率和评估方法的改进。
本文详细回顾了人工智能生成内容(AIGC)背景下,扩散模型在视频生成、编辑和理解中的应用,涵盖了DDPM、SGM和ScoreSDE等技术。文章还讨论了挑战和未来发展趋势,如数据集规模、训练效率和评估方法的改进。
Abstract
人工智能生成内容(AIGC)浪潮在计算机视觉领域取得了巨大成功,其中扩散模型在这一成就中发挥了至关重要的作用。由于其令人印象深刻的生成能力,扩散模型正在逐渐取代基于 GAN 和自回归 Transformer 的方法,不仅在图像生成和编辑方面,而且在视频相关研究领域也展现出卓越的性能。然而,现有的调查主要集中在图像生成背景下的扩散模型,很少对其在视频领域的应用进行最新回顾。因此,本文对 AIGC 时代的视频扩散模型进行了全面回顾。具体来说,论文首先简要介绍扩散模型的基础知识和演变。随后概述了视频领域扩散模型的研究,将工作分为三个关键领域:视频生成、视频编辑和其他视频理解任务。最后,论文讨论了该领域研究面临的挑战,并概述了未来潜在的发展趋势。
这项工作的目标是通过对扩散模式的方法、实验设置、基准数据集和其他视频应用进行全面回顾来填补空白
Preliminary
本节首先介绍扩散模型的相关知识,然后回顾相关的研究领域。最后介绍了常用的数据集和评估指标。
目前关于扩散模型的研究主要基于三种主要公式:去噪扩散概率模型(DDPM),基于分数的生成模型(SGM)和随机微分方程(Score SDE)
DDPM:


SGM
关键思想是使用不同级别的噪声扰乱数据,并通过训练单个条件分数网络同时估计与所有噪声级别相对应的分数。样本是通过使用基于分数的采样方法以降低噪声水平链接分数函数来生成的。在 SGM 的制定中,训练和采样是完全解耦的。

score SDEs

- 文本转视频生成旨在根据文本描述自动生成相应的视频。这通常涉及理解文本描述中的场景、对象和动作,并将它们翻译成一系列连贯的视觉帧,从而产生具有逻辑和视觉一致性的视频
- 无条件视频生成是一项生成建模任务,其目标是生成从随机噪声或固定初始状态开始的连续且视觉上连贯的视频序列,不依赖于特定的输入条件。与条件视频生成不同,无条件视频生成不需要任何外部指导或先验信息
- 文本引导视频编辑是一种使用文本描述来指导视频内容编辑过程的技术。在此任务中,提供自然语言描述作为输入,描述要应用于视频的所需更改或修改。然后,系统分析文本输入,提取相关信息,例如对象、动作或场景,并使用这些信息来指导编辑过程。
Datasets

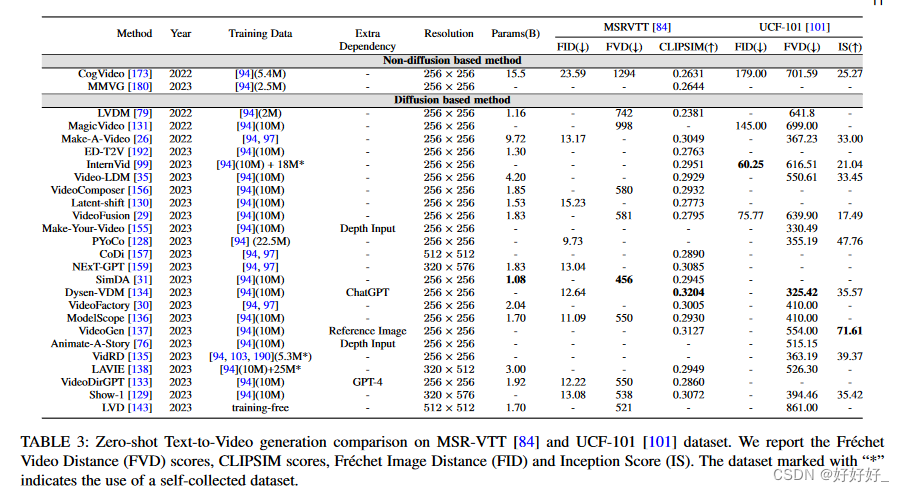
Metrics - 图像级指标。视频由一系列图像帧组成,因此图像级评估指标可以对生成的视频帧的质量提供一定程度的了解。常用的图像级度量包括Fr ́ echet Inception Distance (FID) 、峰值信噪比(PSNR) 、结构相似性指数(SSIM) 和CLIPSIM 。
- 视频级指标。尽管图像级评估指标代表了生成的视频帧的质量,但它们主要关注单个帧,而忽略了视频的时间一致性。视频级指标将为视频生成提供更全面的评估。 Fr ́ echet Video Distance (FVD) 是基于 FID ] 的视频质量评估指标。内核视频距离 (KVD) 也基于 I3D 特征,但它的不同之处在于利用基于内核的方法最大平均差异 (MMD) 来评估生成视频的质量。 Video IS(Inception Score)使用3D-Convnets(C3D)提取的特征计算生成视频的Inception分数,这通常应用于UCF-101 的评估中。高质量视频的特征是低熵概率,表示为 P (y|x),而多样性是通过检查所有视频的边缘分布来评估的,该边缘分布应表现出高水平的熵。帧一致性 CLIP 分数 常用于视频编辑任务来衡量编辑视频的一致性。其计算涉及计算已编辑视频的所有帧的 CLIP 图像嵌入,并报告所有视频帧对之间的平均余弦相似度。
视频生成
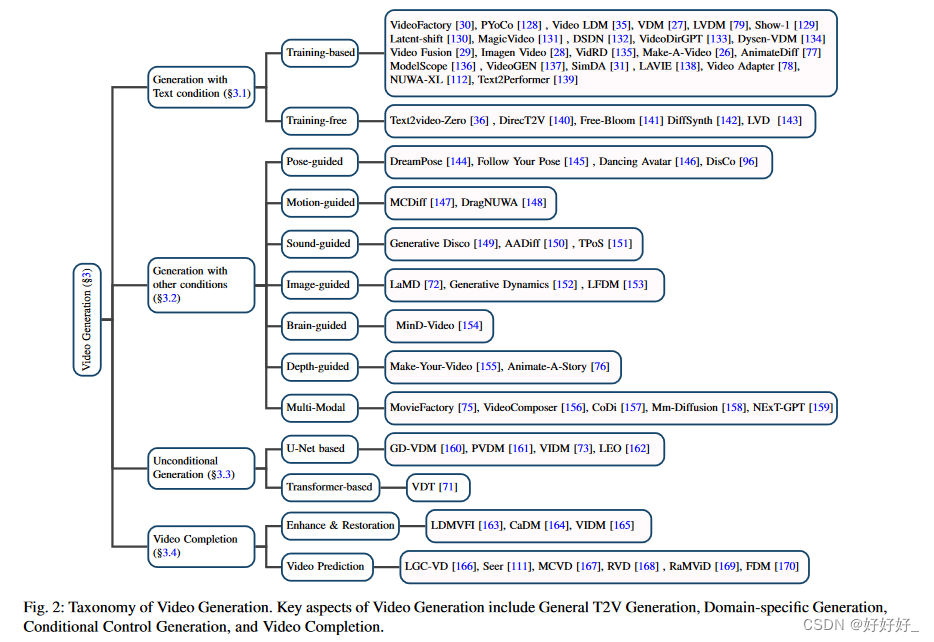
本节将视频生成分为四组:一般文本到视频(T2V)生成(第 3.1 节)、具有其他条件的视频生成(第 3.2 节)、无条件视频生成(第 3.3 节)和视频完成(第 3.4 节)。最后,论文总结了实验设置和评估指标,并在3.5中对各种模型进行了全面比较。

视频编辑
视频编辑任务应满足以下标准:(1)保真度:每一帧在内容上应与原始视频的相应帧一致; (2)对齐:输出视频应与输入控制信息对齐; (3)质量:生成的视频应该是时间一致的并且是高质量的。虽然预先训练的图像扩散模型可以通过单独处理帧来用于视频编辑,但帧之间缺乏语义一致性使得逐帧编辑视频变得不可行,从而使视频编辑成为一项具有挑战性的任务。本节将视频编辑分为三类:文本引导视频编辑(第 4.1 节)、模态引导视频编辑(第 4.2 节)和特定领域视频编辑(第 4.3 节)。

视频理解
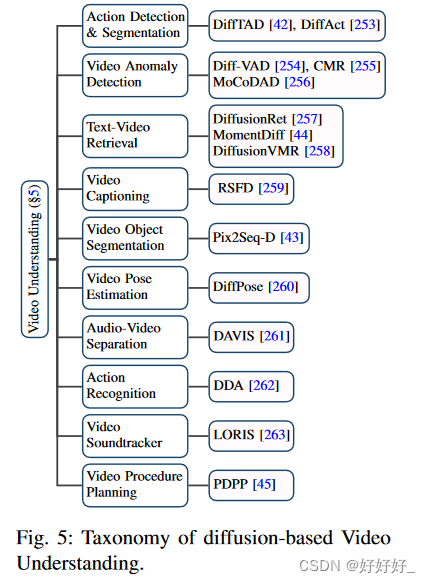
除了在生成任务(例如视频生成和编辑)中的应用之外,扩散模型还在基本视频理解任务中进行了探索,例如视频时间分割、视频异常检测、文本视频检索等,本节将介绍。视频理解的分类细节如下图 所示
挑战和未来趋势
尽管基于扩散的方法在视频生成、编辑和理解方面取得了重大进展,但仍然存在某些值得探索的开放问题。本节总结了当前的挑战和未来潜在的方向。
- 收集大规模视频文本数据集:文本到图像合成的巨大成就主要源于数十亿高质量(文本、图像)对的可用性。然而,文本转视频 (T2V) 任务常用的数据集规模相对较小,收集同样广泛的视频内容数据集是一项相当具有挑战性的工作。例如,WebVid 数据集仅包含 1000 万个实例,并且其视觉质量有限、分辨率低至 360P,并且由于水印伪影的存在而进一步加剧了这一缺陷。尽管人们正在努力探索获取数据集的新方法,但仍然迫切需要改进数据集规模、注释准确性和视频质量。
- 高效的训练和推理: 与 T2V 模型相关的繁重训练成本带来了重大挑战,某些任务需要使用数百个 GPU。尽管 SimDA 等方法努力减少训练费用,但数据集的规模和时间复杂性仍然是一个关键问题。因此,探索更有效的模型训练和减少推理时间的策略是未来研究的宝贵途径。
- 基准和评估方法: 尽管存在开放域视频生成的基准和评估方法,但它们的范围相对有限。由于文本到视频(T2V)生成中生成的视频缺乏基本事实,Fr ́ echet Video Distance (FVD) 和 Inception Score (IS) 等现有指标主要强调生成的视频分布和真实的视频分布之间的差异。这使得建立一个准确反映视频生成质量的综合评估指标具有挑战性。目前,人们相当依赖用户AB测试和主观评分,这是劳动密集型的,并且由于主观性而可能存在偏差。未来构建更加量身定制的评估基准和指标也是一个有意义的研究途径。
- 模型无能 虽然现有方法显示出显着的进步,但由于模型无能,仍然存在许多限制。例如,视频编辑方法在某些情况下经常会遇到时间一致性失败的情况,例如用动物替换人物。此外对于4.1中讨论的大多数方法对象替换仅限于产生相似属性的输出。为了追求高保真度,当前许多基于 T2I 的模型都利用原始视频中的关键帧。然而,由于现成的图像生成模型的固有局限性,在保持结构和时间一致性的同时注入额外的对象仍然没有得到解决。进一步的研究和改进对于解决这些局限性至关重要















 5121
5121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









