







目录

虽然最近多模态大型语言模型(MM-LLM)取得了令人兴奋的进步,但它们大多受到仅输入端多模态理解的限制,而无法以多种模态生成内容。由于我们人类总是通过各种方式感知世界并与人们交流,因此开发能够以任何方式接受和输出内容的任意 MM-LLM 对于人类水平的人工智能至关重要。因此,本论文提出了一个端到端通用的任意 MM-LLM 系统 NExT-GPT。论文将 LLM 与多模态适配器和不同的扩散解码器连接起来,使 NExT-GPT 能够感知输入并以文本、图像、视频和音频的任意组合生成输出。通过利用现有训练有素的高性能编码器和解码器,NExT-GPT仅使用某些投影层的少量参数(1%)进行调整,这不仅有利于低成本训练,而且便于方便地扩展到更多潜在的方式。此外,论文引入了模态切换指令调整(MosIT),并为 MosIT 手动策划了高质量的数据集,在此基础上 NExT-GPT 被赋予了复杂的跨模态语义理解和内容生成的能力。总的来说,论文为构建一个能够对通用模式进行建模的统一人工智能代理提供了可能性。
1. Introduction
最近,人工智能生成内容(AIGC)取得了前所未有的进步,例如用于文本生成的 ChatGPT 和用于视觉生成的扩散模型。其中,大型语言模型(LLM)的兴起尤为引人注目,例如 Flan-T5、Vicuna 、LLaMA 和 Alpaca ,展示了它们强大的人类水平的语言推理和计算能力。决策能力,照亮通用人工智能(AGI)的道路。我们的世界本质上是多模态的,人类通过不同的感觉器官来感知世界,获取不同的模态信息,例如语言、图像、视频和声音,这些信息往往是相互补充和协同的。凭借这种直觉,纯粹基于文本的LLM最近被赋予了视觉、视频、音频等其他模态理解和感知能力。
一个值得注意的方法是使用适配器将其他模式中的预训练编码器与文本LLM对齐。这一努力导致了多模式LLM(MM-LLM)的快速发展,例如 BLIP-2、Flamingo、MiniGPT-4、Video-LLaMA、LLaVA、 PandaGPT,SpeechGPT。然而,这些努力大多关注输入端的多模态内容理解,缺乏比文本更多种模态输出内容的能力。真正的人类认知和交流不可避免地需要任何信息模式之间的无缝转换。这使得任意对任意 MM-LLM 的探索对于实现真正的 AGI 至关重要,即接受任何模态的输入并以任何模态的适当形式提供响应。最近,CoDi在实现同时处理和生成任意模态组合的能力方面取得了长足的进步,但它缺乏以LLM为核心的推理和决策能力,并且也仅限于简单的配对内容生成。 Visual-ChatGPT 和 HuggingGPT 试图将 LLM 与外部工具结合起来,以实现近似“任意到任意”的多模态理解和生成。不幸的是,由于完整的管道架构,这些系统面临着严峻的挑战。首先,不同模块之间的信息传递完全基于LLM产生的离散文本,其中级联过程不可避免地引入噪声并传播错误。更关键的是,整个系统仅利用现有的预训练工具进行推理,缺乏错误传播方面的整体端到端训练,内容理解和多模态生成的能力可能非常有限,特别是在解释复杂和隐含的用户指令时。因此迫切需要构建任意模式的端到端 MM-LLM。
为了实现这一目标,论文推出了 NExT-GPT,这是一种任意对任意的 MM-LLM,旨在以四种模式的任意组合无缝处理输入和输出:文本、图像、视频和音频。如图 1 所示,NExT-GPT 包含三层。首先利用现有的编码器以各种模式对输入进行编码,这些表示通过投影层投影成LLM可以理解的类似语言的表示。其次利用现有的开源LLM作为核心来处理输入信息以进行语义理解和推理。 LLM 不仅直接生成文本标记,还生成独特的“模态信号”标记,这些标记充当指示解码层是否相应输出模态内容以及输出什么模态内容的指令。第三,产生的带有特定指令的多模态信号,经过投影后,路由到不同的编码器,最终生成相应模态的内容。由于 NExT-GPT 包含各种模式的编码和生成,因此从头开始训练系统将需要大量成本。本文利用现有的预训练的高性能编码器和解码器,例如 Q-Former、ImageBind 和最先进的潜在扩散模型。通过加载现成的参数,不仅避免了冷启动训练,而且还促进了更多模式的潜在增长。对于跨三层的特征对齐,论文考虑仅在本地微调输入投影和输出投影层,采用编码端以LLM为中心的对齐和解码端指令跟随对齐,其中最小的计算开销确保更高的效率。此外,为了使任意 MM-LLM 在复杂的跨模态生成和推理方面具有人类水平的能力,论文引入了模态切换指令调整(称为 Mosit),为系统配备了复杂的跨模态语义理解和内容生成。为了解决社区中缺乏此类跨模式指令调整数据的问题,论文手动收集并注释了由 5,000 个高质量样本组成的 Mosit 数据集。论文采用LoRA技术在MosIT数据上微调整个NExT-GPT系统,更新投影层和某些LLM参数。
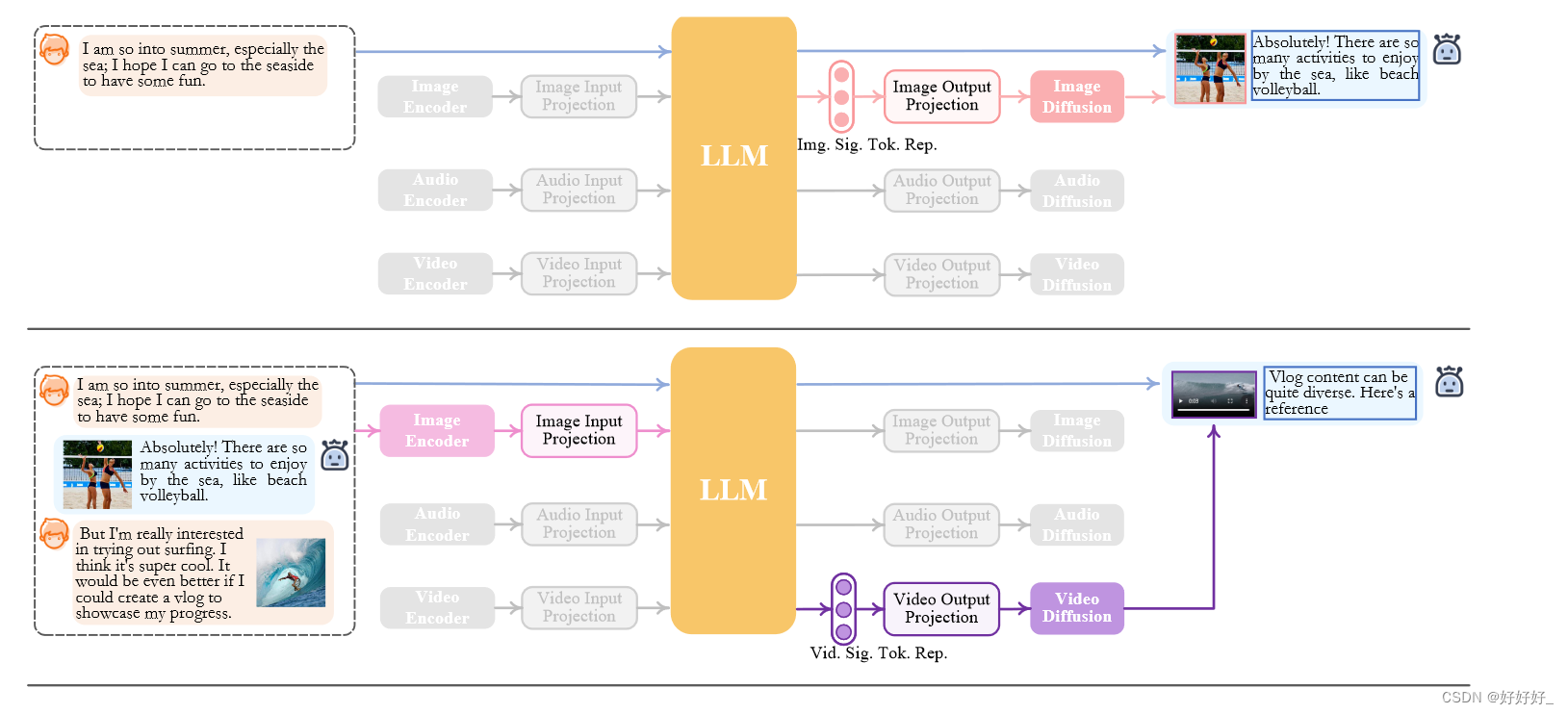
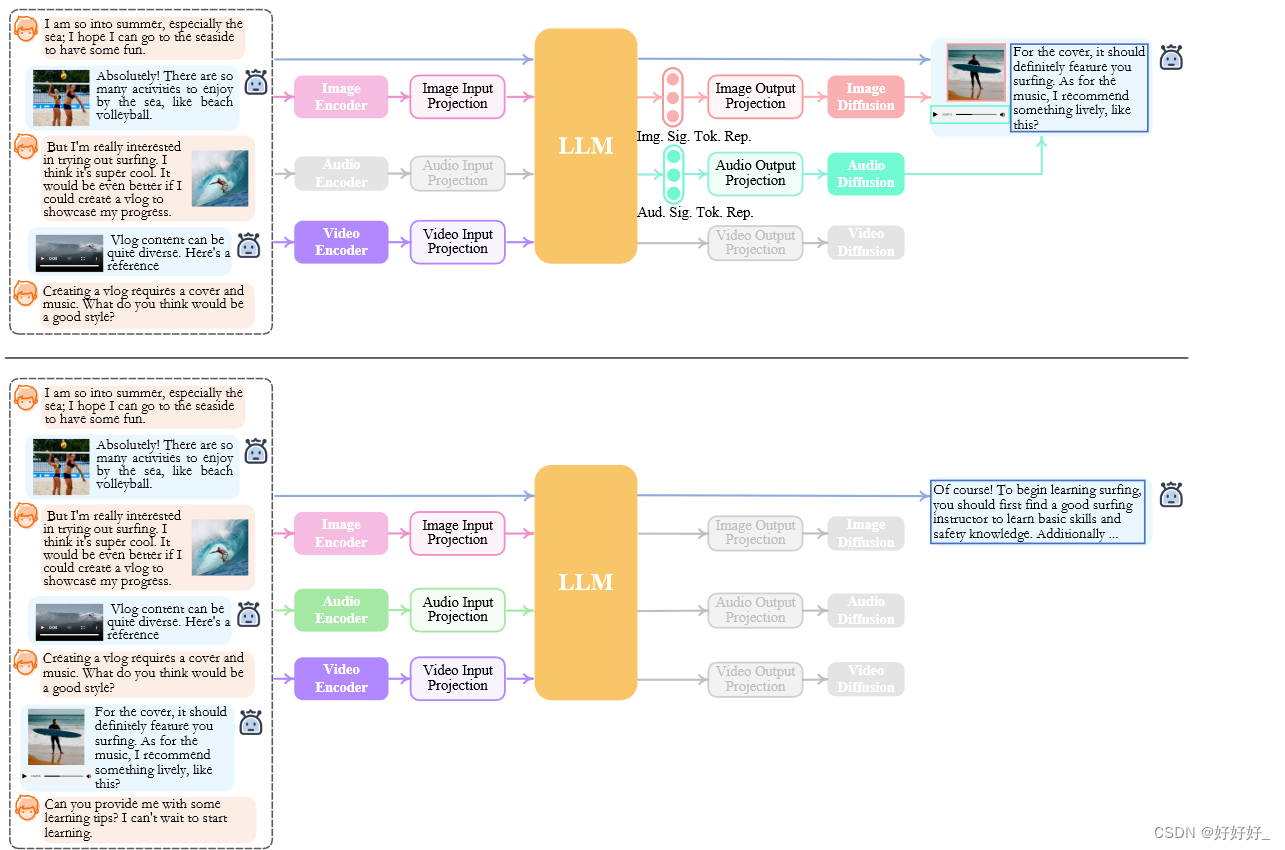
图2 NExT-GPT的推理过程,灰色模块表示已经停用
2. Related work
3. Overall Architecture

4. Lightweight Multimodal Alignment Learning
为了弥合不同模态特征空间之间的差距,并确保不同输入的流畅语义理解,有必要对 NExT-GPT 进行对齐学习。由于论文设计的松耦合系统主要有三层,因此只需要更新编码侧和解码侧的两个投影层
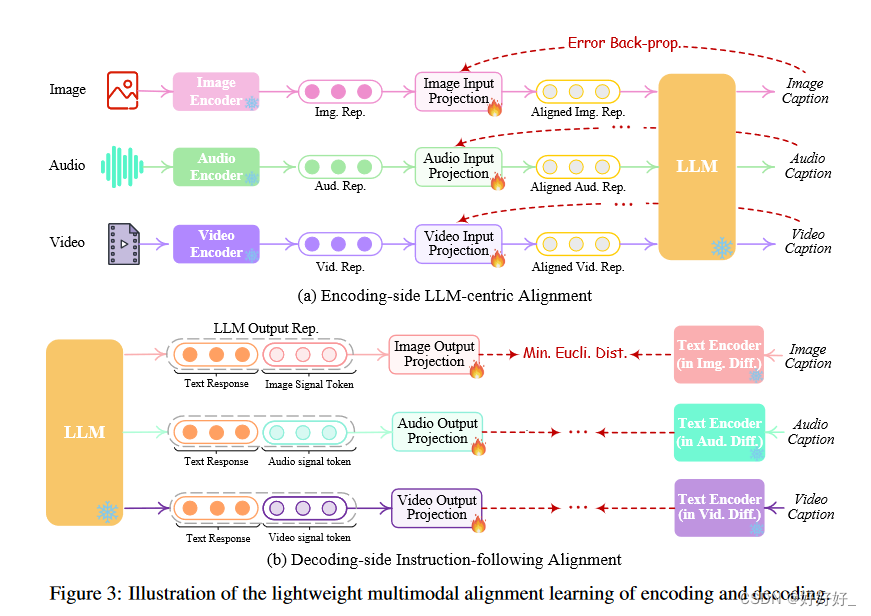
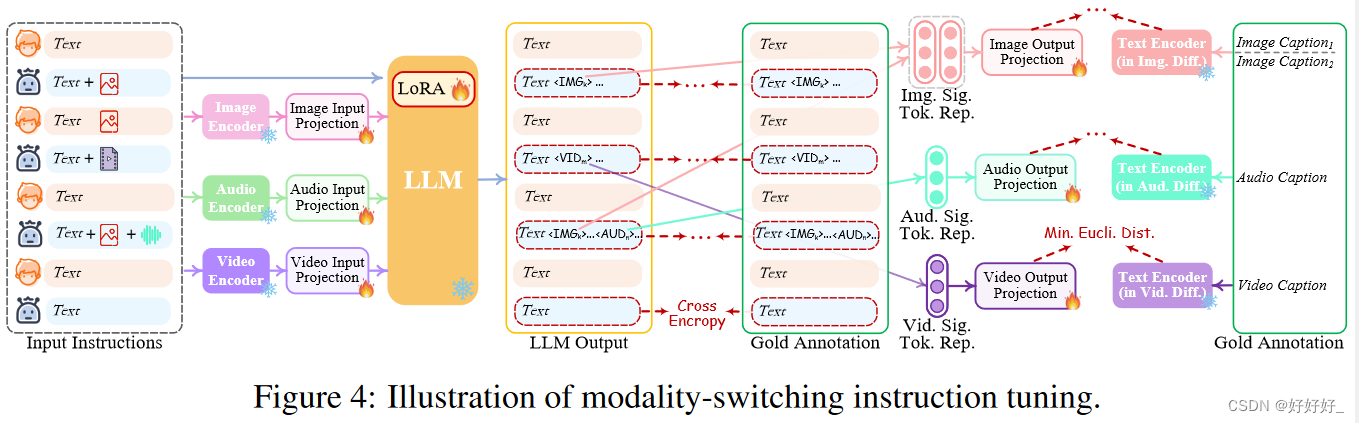
5. Modality-switching Instruction Tuning
尽管编码和解码端都与 LLM 保持一致,但距离使整个系统能够忠实地遵循和理解用户的指令并生成所需的多模态输出的目标仍然存在差距。为了解决这个问题,有必要使用进一步的指令调整(IT)增强LLM的能力和可控性。 IT 涉及使用“(输入,输出)”对 对整体 MM-LLM 进行额外训练,其中“输入”代表用户的指令,“输出”表示符合给定指令的所需模型输出。论文使利用 LoRA 使 NExT-GPT 中的一小部分参数能够在 IT 阶段与两层投影同时更新。除了LLM调优之外,论文还对NExT-GPT的解码端进行了微调。论文将输出投影编码的模态信号标记表示与扩散条件编码器编码的黄金多模态标题表示对齐。
6. Experiments
7. 结论
论文提出了一种端到端通用的任意多模式大语言模型(MM-LLM)。通过将 LLM 与多模式适配器和不同的扩散解码器连接,NExT-GPT 能够感知输入并生成文本、图像、视频和音频的任意组合的输出。利用现有训练有素的高性能编码器和解码器,训练 NExT-GPT 仅需要某些投影层的少量参数(1%),这不仅有利于低成本,而且有利于方便地扩展到未来更多潜在的模式。为了使NExT-GPT 具有复杂的跨模态语义理解和内容生成功能,论文引入了模态切换指令调整(MosIT),并为 MosIT 手动策划了高质量的数据集。
局限性和未来的工作
作为未来的工作,至少有以下四个途径可以探索。
- 模态和任务扩展:由于资源限制,目前NExT-GPT的系统支持四种模态的输入和输出:语言、图像、视频和音频。接下来,可以扩展它以适应更多的模式(例如,网页、3D视觉、热图、表格和图形)和任务(例如,对象检测、分割、接地和跟踪),扩大系统的适用性,使其变得更强大。普遍的。
- LLM 变体:目前,论文已经实施了 LLM 的 7B Vicuna 版本。下一个计划涉及整合各种LLM类型和规模,让从业者可以根据自己的具体要求选择最合适的一种。
- 多模式生成策略:虽然NExT-GPT系统擅长跨模式生成内容,但生成输出的质量有时会受到扩散模型能力的限制。探索基于检索的方法的集成来补充生成过程是非常有前途的,有可能提高整个系统的性能。
- MosIT 数据集扩展:目前,论文的 IT 数据集还有扩展的空间。论文打算显着增加注释数据量,确保更全面、更多样化的指令集,以进一步增强 MM-LLM 有效理解和遵循用户提示的能力。















 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









