






-
提出两种轻量的对齐技术——编码端的语言模型中心对齐和解码端的指令遵循对齐,实现了高效的语义对齐与最小的计算开销。
-
提出新的模态切换指令微调(MosIT)方法与高质量数据集,赋予NExT-GPT复杂的跨模态理解与生成能力。
-
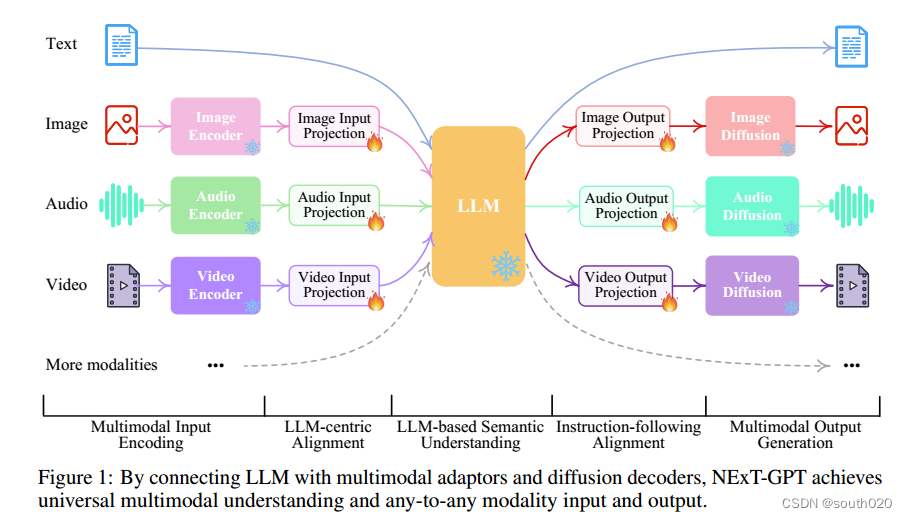
方法:通过将语言模型与多模态适配器和不同的解码器相连接,构建了一个端到端的通用任意多模态语言模型系统NExT-GPT。优势:利用现有的高性能编码器和解码器进行微调,既避免了从头开始训练的成本,又便于扩展到更多潜在的模态。此外,通过引入模态切换指令微调(MosIT)和手动策划高质量数据集,使NExT-GPT具备复杂的跨模态语义理解和内容生成能力。
1 摘要
虽然多模态大语言模型(MM-LLMs)最近取得了令人振奋的进展,但它们大多受限于只能理解输入端的多模态,而无法生成多种模态的内容。由于人类总是通过各种模式感知世界并与人交流,因此开发能够接受和提供任何模式内容的 "任意对任意 "MM-LLM 对人类级人工智能至关重要。为了填补这一空白,我们提出了一种端到端的通用任意 MM-LLM 系统 NExT-GPT。我们将 LLM 与多模态适配器和不同的扩散解码器连接起来,使 NExT-GPT 能够感知输入,并以文本、图像、视频和音频的任意组合生成输出。通过利用现有的训练有素的高性能编码器和解码器,NExT-GPT 只需对某些投影层进行少量参数(1%)的调整,这不仅有利于降低训练成本,还能方便地扩展到更多潜在模态。此外,我们还引入了模态切换指令调整(MosIT),并手动为 MosIT 策划了一个高质量的数据集,在此基础上,NEXT-GPT 被赋予了复杂的跨模态语义理解和内容生成能力。总之,我们的研究展示了构建能够模拟通用模态的统一人工智能代理的可能性,为社区中更多的类人人工智能研究铺平了道路。
2 介绍
由于 NExT-GPT 包含各种模态的编码和生成,从头开始训练系统将耗费大量成本。相反,我们利用了现有的预训练高性能编码器和解码器,如 Q-Former [43]、ImageBind [25] 和最先进的潜在扩散模型 。通过加载现成的参数,我们不仅避免了冷启动训练,还促进了更多模态的潜在增长。对于三层的特征对齐,我们只考虑对输入投影层和输出投影层进行局部微调,编码侧对齐以 LLM 为中心,解码侧对齐以指令为中心。此外,为了使我们的任意 MM-LLM 在复杂的跨模态生成和推理方面具备人类水平的能力,我们引入了模态切换指令调整(称为 Mosit),使系统具备复杂的跨模态语义理解和内容生成能力。为了解决社区中缺乏此类跨模态指令调谐数据的问题,我们手动收集并注释了一个 Mosit 数据集,该数据集由 5,000 个高模态指令样本组成。
3 相关工作
人工智能界相应地出现了各种形式的跨模态学习任务,如图像/视频字幕[99, 16, 56, 56, 27, 49]、图像/视频问题解答[94, 90, 48, 98, 3]、文本到图像/视频/语音合成[74, 30, 84, 23, 17, 51, 33]、图像到视频合成[18, 37]等,所有这些任务在过去几十年中都取得了飞速发展。研究人员提出了高效的多模态编码器,旨在构建包含各种模态的统一表征。同时,由于不同模态的特征空间各不相同,因此必须进行模态对齐学习。此外,为了生成高质量的内容,人们提出了许多性能强大的方法,如 Transformer [82, 101, 17, 24]、GANs [53, 7, 93, 110]、VAEs [81, 67]、Flow 模型 [73, 6] 以及目前最先进的扩散模型 [31, 64, 57, 22, 68]。特别是基于扩散的方法最近在大量跨模态生成任务中取得了显著的性能,如 DALL-E [66]、稳定扩散 [68]。虽然以往所有的跨模态学习都仅限于理解多模态输入,但 CoDi [78] 最近取得了突破性进展。利用扩散模型的强大功能,CoDi 具备了基因学习的能力。
4 结构
多模态编码阶段 首先,我们利用现有的成熟模型对不同模态的输入进行编码。目前有一系列针对不同模态的编码器可供选择,例如 QFormer、ViT、CLIP。在这里,我们利用的是 ImageBind ,它是一种横跨六种模式的统一高性能编码器。有了 ImageBind,我们就无需管理许多不同的模态编码器。然后,通过线性投影层,不同的输入表征被映射成类似语言的表征,这些表征可以被 LLM 理解。
LLM 理解与推理阶段 使用 LLM 作为 NExT-GPT 的核心代理。在技术上,我们采用了 Vicuna2 [12],它是基于文本的开源 LLM,在现有的 MM-LLM 中得到了广泛应用 [77, 103]。LLM 将不同模态的表征作为输入,并对输入进行语义理解和推理。它的输出包括:1)直接的文本响应;2)每种模态的信号标记,这些信号标记作为指令指示解码层是否生成多模态内容,以及如果生成则生成什么内容。
多模态生成阶段 基于Transformer的输出投影层接收来自 LLM(如有)的带有特定指令的多模态信号,并将信号标记表示映射为后续多模态解码器可以理解的表示。在技术上,我们采用了目前现成的不同模态世代的潜在条件扩散模型,即用于图像合成的稳定扩散(SD)3 [68]、用于视频合成的 Zeroscope4 [8],以及用于音频合成的 AudioLDM5 [51]。信号表示被输入到条件扩散模型的条件编码器中,用于生成内容。

表 1 总结了整个系统的配置。值得注意的是,在整个系统中,只有较低尺度参数的输入和输出投影层(与整个巨大容量框架相比)需要在接下来的学习过程中更新,其余所有编码器和解码器都被冻结。也就是说,131M(=4+33+31+31+32)/ [131M + 12.275B(=1.2+7+1.3+1.8+0.975)],只有 1%的参数需要更新。这也是我们的 MM-LLM 的主要优势之一。图 2 进一步说明了 NExT-GPT 的推理过程。给定任意模态组合的特定用户输入,相应的模态编码器和投影器将其转换为特征表示,并将其传递给 LLM6 。然后,LLM 决定生成哪些内容,即文本标记和模态信号标记。如果 LLM 确定要生成某种模态内容(语言除外),就会输出一种特殊类型的标记[40],表示激活了该模态;反之,不输出特殊标记则表示停用了该模态。在技术上,我们将"<IMGi>"(i = 0, - - - , 4)设计为图像信号标记;将"<AUDi>"(i = 0, - - - , 8)设计为音频信号标记;将"<VIDi>"(i = 0, - - - , 24)设计为视频信号标记。经过 LLM 处理后,文本响应将输出给用户;而某些激活模态的信号令牌的表示则传递给相应的扩散解码器,用于生成内容。
5 轻量级多模态对齐学习
为了弥合不同模态特征空间之间的差距,确保对不同输入的流畅语义理解,对 NExT-GPT 进行对齐学习至关重要。由于我们设计的松耦合系统主要有三层,因此只需更新编码端和解码端的两个投影层即可。
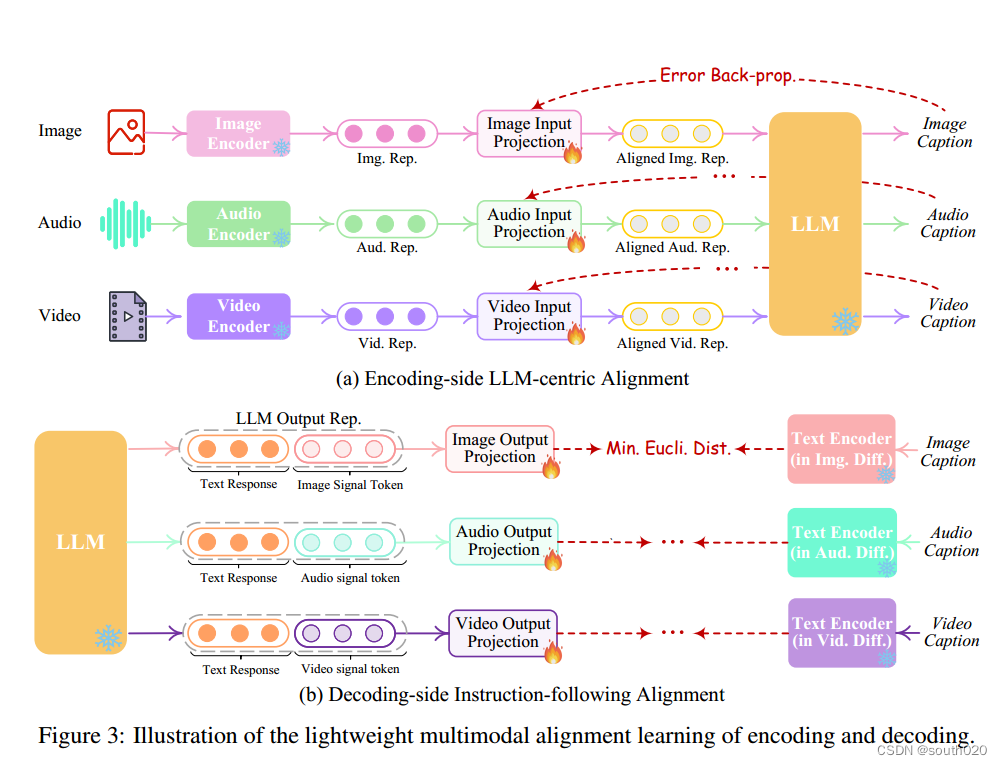
按照现有 MM-LLM 的通常做法,我们考虑将不同的输入多模态特征与文本特征空间对齐.为了完成对齐,我们从现有的语料库和基准中准备了 "‘X-caption "对("X "代表图像、音频或视频)数据。我们使用 LLM 生成每个输入模态的标题与黄金标题的对比。
在解码端,我们集成了来自外部资源的预训练条件扩散模型。我们的主要目的是将扩散模型与 LLM 的输出指令对齐。然而,在每个扩散模型和 LLM 之间执行全面的对齐过程将带来巨大的计算负担。作为替代方案,我们在此探索一种更高效的方法,即解码侧指令跟随对齐,如图 3(b) 所示。具体来说,由于各种模式的扩散模型仅以文本标记输入为条件。在我们的系统中,这种条件与来自 LLM 的模态信号标记有很大差异,这导致扩散模型在准确解释来自 LLM 的指令方面存在差距。因此,我们考虑最小化 LLM 的模态信号标记表示(在每个基于 Transformer 的项目层之后)与扩散模型的条件文本表示之间的距离。由于只使用了文本条件编码器(扩散骨干被冻结),因此学习仅仅基于纯字幕文本,即不需要任何视觉或音频资源。这也确保了训练的高度轻量化。
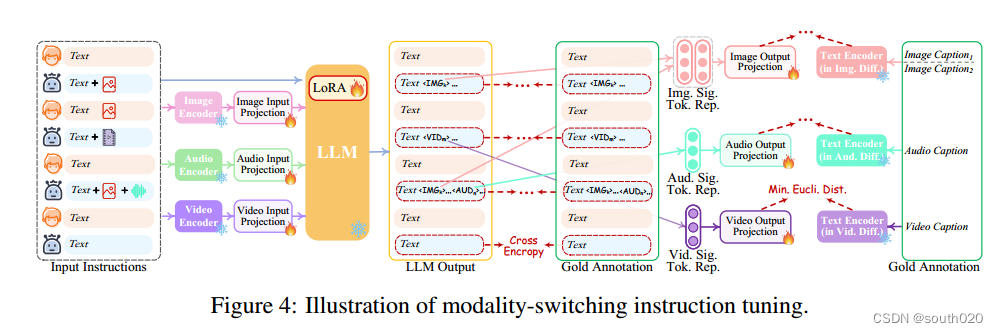
6模式切换指令协调
为了提高 LLM 的能力和可控性,有必要进一步进行指令调整(IT)。为了促进任意 MM-LLM 的发展,我们提出了一种新颖的模式切换指令调整(MosIT)。如图 4 所示,当 IT 对话样本输入系统时,LLM 会重构并生成输入的文本内容(并以多模态信号标记来表示多模态内容)。根据黄金注释和 LLM 的输出结果进行优化。除 LLM 调整外,我们还对 NExT-GPT 的解码端进行了微调。我们将输出投影编码的模态信号标记表示与扩散条件编码器编码的黄金多模态字幕表示相一致。因此,综合调整过程更接近与用户进行忠实、有效互动的目标。















 850
850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









