







文章目录
2025/04/02更新:我感觉之前写得太垃圾了,特地来重写一下,之前被我的文章坑到的兄弟姐妹们不好意思。
首先,安装Anaconda和Pytorch以及其他的东西的教程可以看这篇博客:【安装】Python3|Windows下安装Anaconda、pytorch,以及修改pip默认安装路径_anaconda pip修改安装的包路径-CSDN博客,当且仅当你遇到版本不对劲的时候再回来看本篇博客。
Cuda版本查看
1 最高的Cuda版本
首先,运行指令,查看自己的显卡支持的最高的CUDA版本号:
nvidia-smi -i 0
2 查看当前活跃的Cuda版本
运行以下指令:
nvcc -V
会显示当前活跃的一个Cuda版本,例如:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Wed Nov 22 10:08:41 2023
Cuda compilation tools, release 12.4, V12.4.131

3 查看当前安装的所有Cuda版本
Linux
运行指令,通过包管理器查看:
dpkg -l | grep cuda-toolkit
输出示意(有什么版本就会显示什么版本的):
ii nvidia-cuda-toolkit 12.0.140~12.0.1-4build4 amd64 NVIDIA CUDA development toolkit
ii nvidia-cuda-toolkit-doc 12.0.1-4build4 all NVIDIA CUDA and OpenCL documentation
Windows
在 Windows 系统下,通过安装目录直接查看:
CUDA Toolkit 默认安装在以下路径:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA
打开此目录,每个子文件夹对应一个已安装的 CUDA 版本(例如 v11.7, v12.2 等)。
示例: 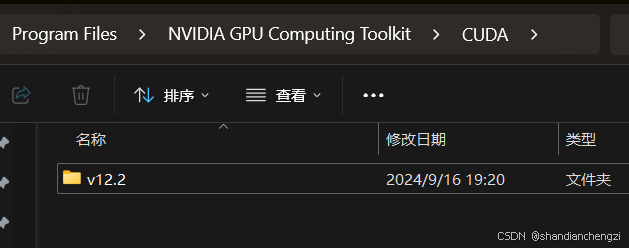
PyTorch安装指令构造
方式一 官网安装选项组合
直接点开官网,看安装选项中有没有你自己的CUDA版本,例如下图:

如果有就可以直接用它给出的指令,如果没有就继续往下看。
方式二 查看所有可安装的版本
打开官网的所有版本,检查是不是有符合你的Cuda版本的。如果有的话可以考虑装那个版本的。
例如如果你的CUDA是11.1,那么你搜索cu111,会发现torch 1.9.0+cu111存在。就可以用如下指令下载pytorch:
pip --default-timeout=1000 install torch==1.9.0+cu111 torchvision==0.10.0+cu111 torchaudio==0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
如果你发现你的CUDA还是没有对应的版本,比如CUDA 11.2 没有任何的torch版本,因为PyTorch没有专门针对CUDA 11.2发行的版本。那就继续往下看。
方式三 安装其他版本CUDA,再用方式一二
1 安装其他版本
首先你需要注意自己安装的版本再高也不能高过Nvidia-smi显示的那个,其他就没什么注意的了,哪个能用就装哪个吧。不需要卸载原本的,让卸载的博客都不太正常……
官网上下载和Pytorch匹配的版本:https://developer.nvidia.com/cuda-toolkit-archive
按照自己的需求选一下,比如我现在要下的版本是Windows Cuda 11.8:

根据下载的指示去下载就可以了,Windows是按Download按钮就行。
这里我只演示Windows的操作:
- 第一步会让选解压目录,随便解压一下,不用管到底解压到哪个目录了因为安装完会自动删掉的:
- 弹出选项问是否安装驱动,一直点同意或下一步就好了:
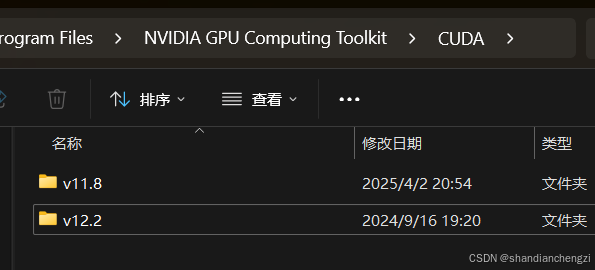
安装完成之后你就可以看到文件夹下多了一个v11.8了!
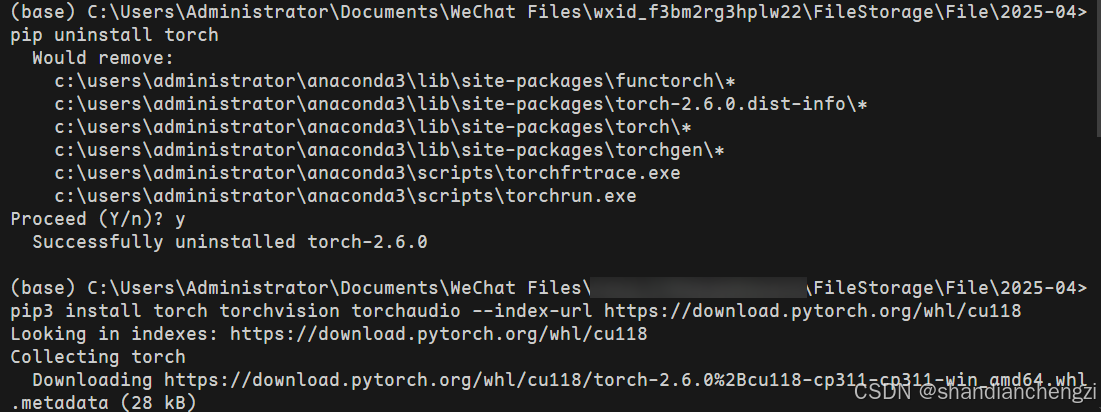
2 安装PyTorch
参考方式一、二去构造相应的安装指令了,记得先把之前不小心装的cpu版本卸载掉。
3 切换Cuda版本
你装完之后运行nvcc -V大概率还是会显示之前的版本,但是不要紧,你要的是代码里面版本正确,而且我也不想把系统的nvcc改掉。
这里提供一个在代码里测试并切换cuda版本的方案。
以下是完整的python测试代码:
import os
import sys
import subprocess
# 设置目标 CUDA 版本路径(根据你的实际安装路径修改)
cuda_path = r"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8" # Windows 示例
# cuda_path = "/usr/local/cuda-11.8" # Linux 示例
# -------------------------------------------------------------------
# 1. 添加 CUDA 相关路径到环境变量(临时生效,仅限当前脚本)
# -------------------------------------------------------------------
def add_cuda_to_path():
# Windows 路径格式
if sys.platform == "win32":
cuda_bin = os.path.join(cuda_path, "bin")
cuda_lib = os.path.join(cuda_path, "lib", "x64")
os.environ["PATH"] = f"{cuda_bin};{os.environ['PATH']}"
os.environ["CUDA_PATH"] = cuda_path
os.environ["LD_LIBRARY_PATH"] = f"{cuda_lib};{os.environ.get('LD_LIBRARY_PATH', '')}"
# Linux 路径格式
else:
cuda_bin = os.path.join(cuda_path, "bin")
cuda_lib = os.path.join(cuda_path, "lib64")
os.environ["PATH"] = f"{cuda_bin}:{os.environ['PATH']}"
os.environ["LD_LIBRARY_PATH"] = f"{cuda_lib}:{os.environ.get('LD_LIBRARY_PATH', '')}"
# -------------------------------------------------------------------
# 2. 验证 PyTorch CUDA 版本
# -------------------------------------------------------------------
def check_pytorch_cuda():
try:
import torch
print("\n[PyTorch 验证]")
print(f"Python 版本: {sys.version}")
print(f"PyTorch 版本: {torch.__version__}")
print(f"CUDA 可用性: {torch.cuda.is_available()}")
print(f"GPU 设备数量: {torch.cuda.device_count()}")
if torch.cuda.is_available():
print(f"PyTorch 使用的 CUDA 版本: {torch.version.cuda}")
print(f"当前 GPU 设备: {torch.cuda.get_device_name(0)}")
else:
print("警告: CUDA 不可用,请检查驱动和PyTorch安装!")
except ImportError:
print("错误: PyTorch 未安装!")
except Exception as e:
print(f"PyTorch 验证异常: {str(e)}")
# -------------------------------------------------------------------
# 3. 验证系统 CUDA 环境
# -------------------------------------------------------------------
def check_system_cuda():
print("\n[系统环境验证]")
try:
# 检查 nvcc 版本
nvcc_output = subprocess.check_output(["nvcc", "--version"], stderr=subprocess.STDOUT)
print(nvcc_output.decode().strip())
except FileNotFoundError:
print("错误: nvcc 未找到,请检查 CUDA 是否安装或路径是否正确!")
except Exception as e:
print(f"系统 CUDA 检查异常: {str(e)}")
# 检查环境变量
print(f"\n当前 PATH 中的 CUDA 路径: {'CUDA路径存在' if cuda_path in os.environ['PATH'] else '未找到目标CUDA路径'}")
# -------------------------------------------------------------------
# 执行验证
# -------------------------------------------------------------------
if __name__ == "__main__":
add_cuda_to_path()
check_pytorch_cuda()
check_system_cuda()
调用add_cuda_to_path这个函数就可以保证cuda版本完全正确了~
进一步验证GPU是否在代码中被使用
我做了前面的那些验证之后查看nvidia-smi还是感觉GPU没有怎么被占用,所以写了个更加复杂的看看能不能做到显著占用:
import torch
import time
import numpy as np
def gpu_stress_test(device='cuda', matrix_size=10000, num_iter=100, warmup=10):
# 检查 CUDA 是否可用
if not torch.cuda.is_available():
print("错误: CUDA 不可用,请检查 GPU 驱动和 PyTorch 安装!")
return False
# 获取 GPU 设备信息
print("\n=== GPU 信息 ===")
print(f"当前 GPU: {torch.cuda.get_device_name(0)}")
print(f"CUDA 版本: {torch.version.cuda}")
print(f"PyTorch CUDA 支持: {torch.backends.cudnn.version()}\n")
# 初始化大型矩阵(显存占用约 2*8*matrix_size^2 字节)
print(f"创建 {matrix_size}x{matrix_size} 浮点矩阵...")
try:
a = torch.randn(matrix_size, matrix_size, device=device)
b = torch.randn(matrix_size, matrix_size, device=device)
except RuntimeError as e:
print(f"显存不足!错误信息: {str(e)}")
return False
# 预热阶段(让 GPU 达到稳定状态)
print("开始 GPU 预热...")
for _ in range(warmup):
c = torch.matmul(a, b)
torch.cuda.synchronize() # 等待所有计算完成
# 性能测试
print(f"\n开始 {num_iter} 次矩阵乘法压力测试...")
times = []
mem_usage = []
util_usage = []
for i in range(num_iter):
start_time = time.time()
# 执行矩阵乘法
c = torch.matmul(a, b)
# 等待计算完成
torch.cuda.synchronize()
# 记录时间
elapsed = time.time() - start_time
times.append(elapsed)
# 记录显存使用
mem_usage.append(torch.cuda.memory_allocated() / 1024**3) # 转换为 GB
# 记录 GPU 利用率(需要安装 nvidia-ml-py)
try:
from pynvml import nvmlInit, nvmlDeviceGetUtilizationRates
nvmlInit()
handle = torch.cuda.get_device_properties(0).pciBusId
util = nvmlDeviceGetUtilizationRates(handle).gpu
util_usage.append(util)
except:
pass
# 打印进度
if (i+1) % 10 == 0:
print(f"已完成 {i+1}/{num_iter} 次迭代")
# 打印统计信息
print("\n=== 测试结果 ===")
print(f"平均每次计算耗时: {np.mean(times)*1000:.2f} ms")
print(f"最大显存占用: {max(mem_usage):.2f} GB")
if util_usage:
print(f"平均 GPU 利用率: {np.mean(util_usage):.1f}%")
# 验证结果正确性
try:
a_cpu = a.cpu()
b_cpu = b.cpu()
c_cpu = torch.matmul(a_cpu, b_cpu)
diff = torch.abs(c.cpu() - c_cpu).max().item()
print(f"\n数值验证误差: {diff:.6f} (应接近 0)")
except:
pass
return True
if __name__ == "__main__":
# 执行测试(可调整参数)
test_result = gpu_stress_test(
device='cuda',
matrix_size=15000, # 增大此值会提高显存占用(如果显存不足请减小)
num_iter=50,
warmup=5
)
# 最终结论
if test_result:
print("\n测试完成,如果出现以下情况需要排查:")
print("1. 显存占用未达到 GPU 总容量(表示未充分利用)")
print("2. GPU 利用率长期低于 90%")
print("3. 数值误差显著大于 1e-5")
print("4. 出现 CUDA 错误或崩溃")
else:
print("\n测试未完成,请检查上述错误信息")
随便运行了一下,占用确实多,说明GPU没坏:
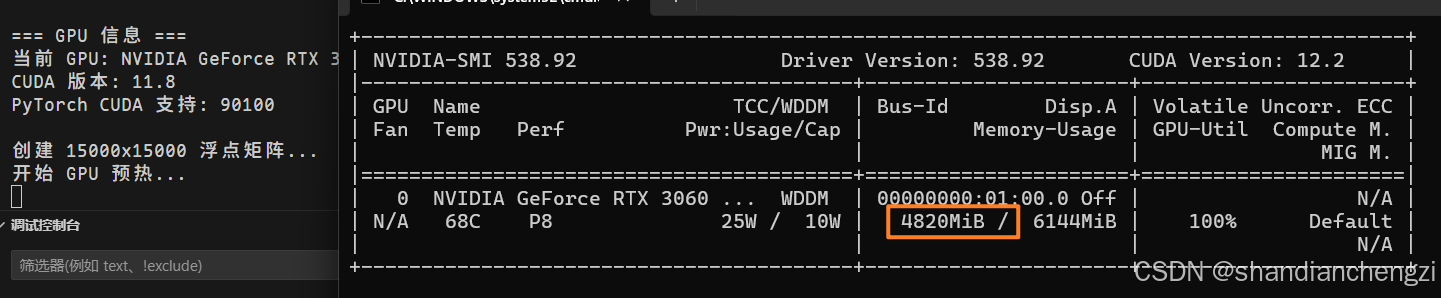
那就说明要是占用不高就只能是代码有问题了。
本账号所有文章均为原创,欢迎转载,请注明文章出处:https://shandianchengzi.blog.csdn.net/article/details/124873505。百度和各类采集站皆不可信,搜索请谨慎鉴别。技术类文章一般都有时效性,本人习惯不定期对自己的博文进行修正和更新,因此请访问出处以查看本文的最新版本。


















 9632
9632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











