







一、重要性采样
1.1 重要性采样
如果我们能从p中采样,那么可以用MC来估计
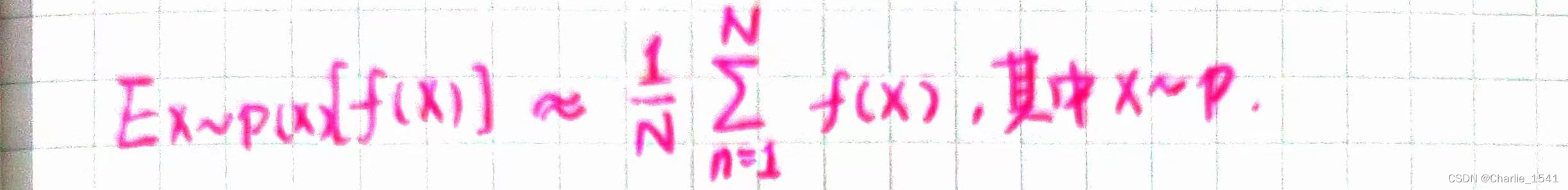
如果不能直接从p中采样,但是可以从q中采样,则可以用重要性估计:

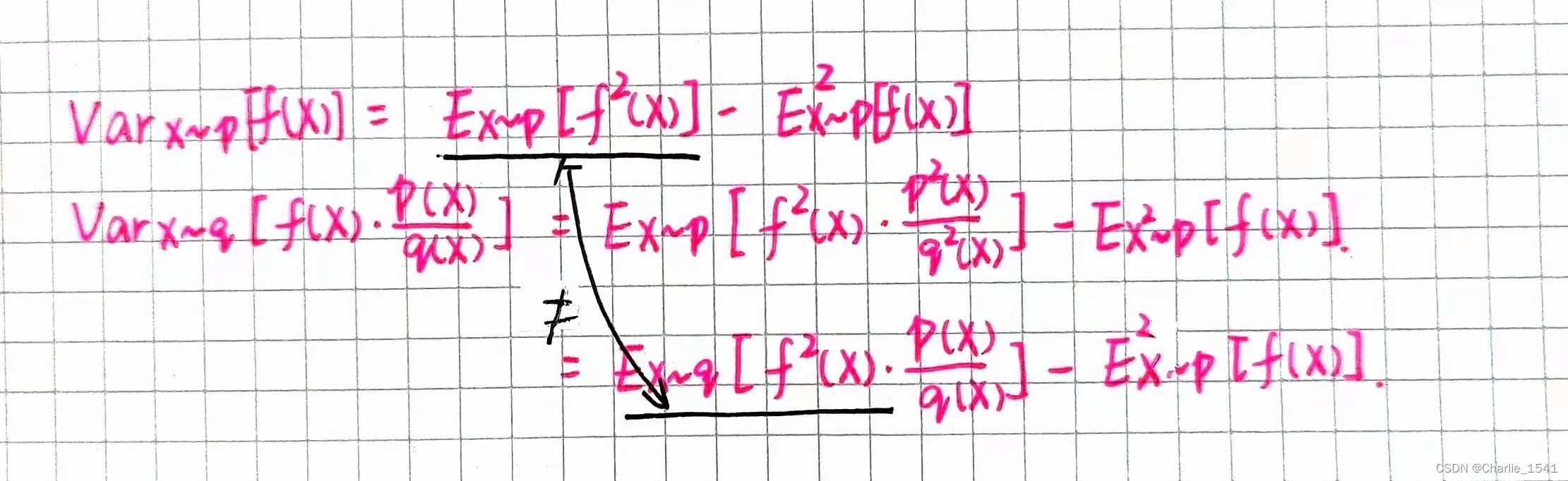
但需要注意,两者不能相距太远。因为虽然它们期望一样,方差却不一样。区别在第一项
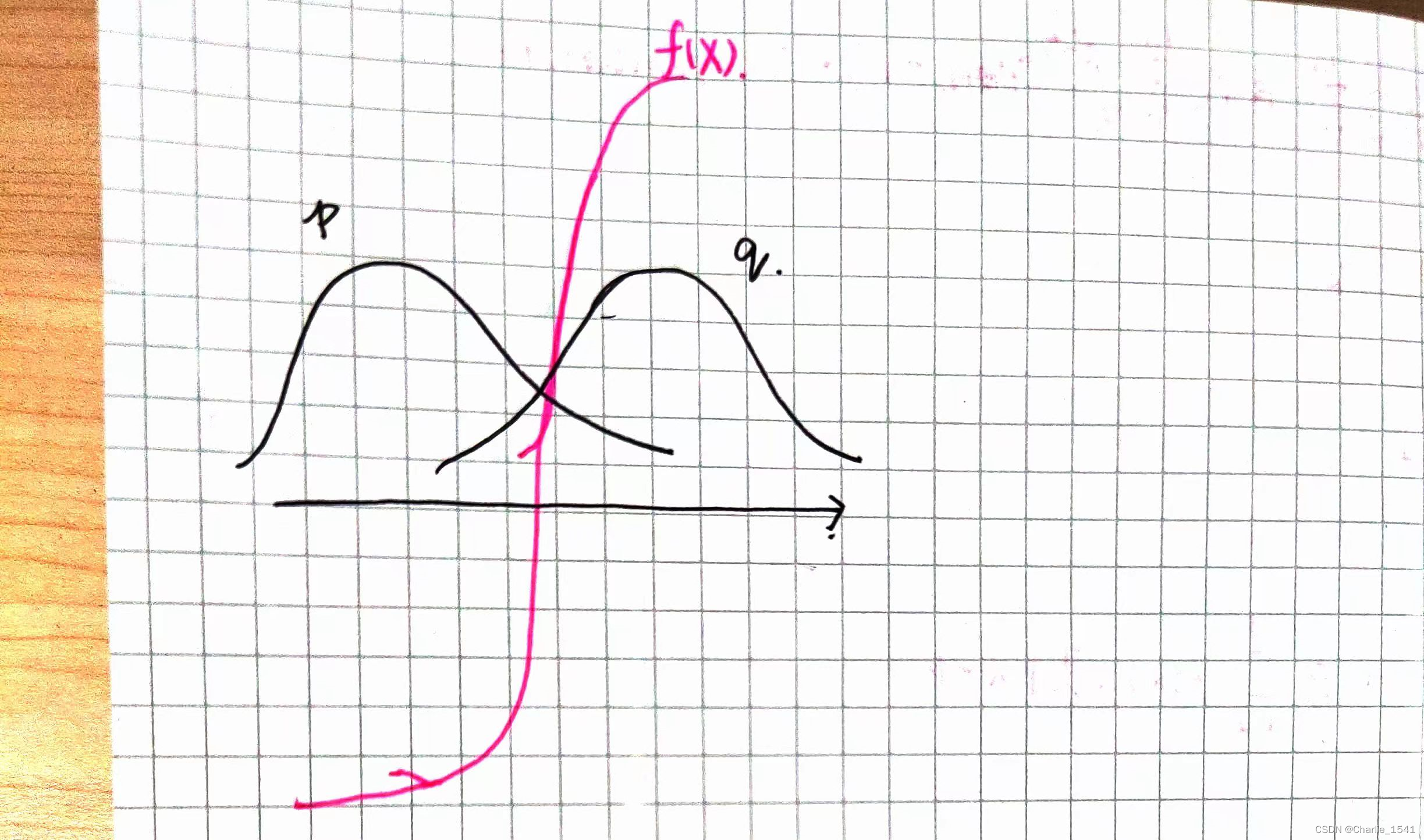
因此,重要性采样的一个缺点是:必须样本充足,否则可能引起巨大的问题。例如下图中,如果对p采样,f(x)的均值显然是负数。如果对q采样,样本很少的情况下,只会采样到f(x)>0的情况,那么估计的期望就是正数。但如果样本足够多,即使采到左边一两个点,也会因为权重很大而把估计值拉回到负数。
1.2 使用重要性采样将同策略变成异策略
上一章讲的策略梯度是同策略方法,如果改成异策略方法:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2918
2918











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









