







1. 关于重要性采样
1.1 重要性采样是什么,能解决什么问题
假设我们有一个函数
f
(
x
)
f(x)
f(x),要计算从分布
p
p
p 采样
x
x
x,再把
x
x
x 代入
f
f
f ,得到
f
(
x
)
f(x)
f(x)。我们该怎么计算
f
(
x
)
f(x)
f(x) 的期望值呢?假设我们不能对分布
p
p
p 做积分,但可以从分布
p
p
p 采样一些数据
x
i
x^i
xi。把
x
i
x^i
xi 代入
f
(
x
)
f(x)
f(x),取它的平均值,就可以近似
f
(
x
)
f(x)
f(x) 的期望值。

假设我们不能从分布
p
p
p 采样数据,只能从另外一个分布
q
q
q 采样数据
x
x
x,
q
q
q 可以是任何分布。如果我们从
q
q
q 采样
x
i
x^i
xi,
 因为是从
q
q
q 采样数据,所以我们从
q
q
q 采样出来的每一笔数据,都需要乘一个重要性权重(importance weight)
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x) 来修正这两个分布的差异。
因为是从
q
q
q 采样数据,所以我们从
q
q
q 采样出来的每一笔数据,都需要乘一个重要性权重(importance weight)
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x) 来修正这两个分布的差异。
所以重要性采样能解决什么问题?就是虽然
x
∼
p
x \sim p
x∼p,但是可以从另一个分布q中采样,来计算
E
[
f
(
x
)
]
E[f(x)]
E[f(x)],但是要乘以一个重要性权重
p
(
x
)
q
(
x
)
\frac{p(x)}{q(x)}
q(x)p(x)。
1.2 重要性采样的缺陷
虽然期望
E
x
∼
p
[
f
(
x
)
]
E_{x\sim p}[f(x)]
Ex∼p[f(x)]与
E
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
E_{x\sim q}[f(x)\frac{p(x)}{q(x)}]
Ex∼q[f(x)q(x)p(x)]是一样的,但是方差
V
a
r
x
∼
p
[
f
(
x
)
]
Var_{x\sim p}[f(x)]
Varx∼p[f(x)]与
V
a
r
x
∼
q
[
f
(
x
)
p
(
x
)
q
(
x
)
]
Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]
Varx∼q[f(x)q(x)p(x)]是不一样的。这个解释在磨菇书easyRL中的解释非常好,本文多次借鉴了其中的一些解释:磨菇书easyRL

从上面一段话中我们要学习到两点:
(1)方差的差异程度是由
p
(
x
)
p(x)
p(x)和
q
(
x
)
q(x)
q(x)的差异程度来决定的,
p
(
x
)
p(x)
p(x)和
q
(
x
)
q(x)
q(x)的差异越大,方差差异也越大。
(2)方差的不同使得在采样次数相对比较少的时候估计出来的期望相差很大。
2.PPO算法
2.1 PPO算法要解决的两个问题
PPO是策略梯度算法。在策略梯度算法理论部分(基于策略的深度强化学习:理论部分)我们得到代价函数的梯度如下:
![]() 在AC算法中,
R
(
τ
)
R(\tau)
R(τ)使用优势函数代替,有时函数可以度量动作的好坏。
在AC算法中,
R
(
τ
)
R(\tau)
R(τ)使用优势函数代替,有时函数可以度量动作的好坏。
 而AC算法和A2C算法的优势函数计算是不太一样的:
而AC算法和A2C算法的优势函数计算是不太一样的:
 相对于A2C算法,PPO主要想解决两个问题:
相对于A2C算法,PPO主要想解决两个问题:
(1)问题一:通过重要性采样提高数据的训练效率:也就是交互一次,训练多次。
A2C算法的actor网络与环境交互之后得到的数据只能用来训练actor网络一次
也即是下面的节奏:
交互
→
更新
a
c
t
o
r
网络
→
交互
→
更新
a
c
t
o
r
网络
→
.
.
.
交互 \rightarrow 更新actor网络\rightarrow交互\rightarrow更新actor网络\rightarrow...
交互→更新actor网络→交互→更新actor网络→...
上面的节奏交互一次只能训练一次。需要寻找方法交互一次可训练多次。这个方法就是重要性采样。
(2)问题二:限制
p
θ
(
a
∣
s
)
p_{\theta}(a|s)
pθ(a∣s)与
p
θ
′
(
a
∣
s
)
p_{\theta'}(a|s)
pθ′(a∣s)的差异,不能让其差异过大。
如果把新的策略网络的参数写作
θ
\theta
θ,老的策略网络的参数写作
θ
′
\theta'
θ′。在通过老的策略网络
θ
′
\theta'
θ′与环境交互获得数据之后,可以多次对
θ
\theta
θ进行更新。每进行一次更新就会使得
θ
′
\theta'
θ′与
θ
\theta
θ产生差异。多次更新就会差异越来越大,从而使得
p
θ
(
a
∣
s
)
p_{\theta}(a|s)
pθ(a∣s)与
p
θ
′
(
a
∣
s
)
p_{\theta'}(a|s)
pθ′(a∣s)差异越来越大。但是差异越来越大是不好的。
重要性采样虽然是无偏的。但是方差却不一样。
p
θ
(
a
∣
s
)
p_{\theta}(a|s)
pθ(a∣s)与
p
θ
′
(
a
∣
s
)
p_{\theta'}(a|s)
pθ′(a∣s)分布相差越大,方差也就越大,这对算法的收敛性会引起不好的效果,所以我们必须限制一下
p
θ
(
a
∣
s
)
p_{\theta}(a|s)
pθ(a∣s)与
p
θ
′
(
a
∣
s
)
p_{\theta'}(a|s)
pθ′(a∣s)的差异,不能让其差异过大。这就是PPO/PPO2算法做的事情。
2.2 针对问题1:引入重要性采样
先做几个定义:在上一篇文章基于策略的强化学习:Actor-Critic算法中,提到A2C算法的loss函数是:
l o s s A 2 C = 1 N ∑ n = 1 N ∑ t = 1 T n ( t a r g e t T D − v ^ t ) l o g p θ ( a t n ∣ s t n ) = 1 N ∑ n = 1 N ∑ t = 1 T n A ^ t ω l o g p θ ( a t n ∣ s t n ) loss_{A2C}=\frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n}(target_{TD}-\widehat{v}_t)logp_\theta (a_{t}^{n}|s{_{t}^{n}})=\frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n}\widehat{A}_t^\omega logp_\theta (a_{t}^{n}|s{_{t}^{n}}) lossA2C=N1n=1∑Nt=1∑Tn(targetTD−v t)logpθ(atn∣stn)=N1n=1∑Nt=1∑TnA tωlogpθ(atn∣stn)
四元组
(
s
t
,
a
t
,
r
t
,
s
t
+
1
)
(s_t,a_t,r_t,s_{t+1})
(st,at,rt,st+1)
我们定义:
t
a
r
g
e
t
T
D
−
v
^
t
=
A
^
t
ω
target_{TD}-\widehat{v}_t=\widehat{A}_t^\omega
targetTD−v
t=A
tω
其中
v
^
t
=
c
r
i
t
i
c
(
s
t
)
\widehat{v}_t=critic(s_t)
v
t=critic(st),
v
^
t
+
1
=
c
r
i
t
i
c
(
s
t
+
1
)
\widehat{v}_{t+1}=critic(s_{t+1})
v
t+1=critic(st+1),
t
a
r
g
e
t
T
D
=
r
t
+
γ
v
^
t
+
1
target_{TD}=r_t+\gamma \widehat{v}_{t+1}
targetTD=rt+γv
t+1
A2C算法的loss函数的梯度:
∇
l
o
s
s
A
2
C
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
^
t
ω
∇
l
o
g
p
θ
(
a
t
n
∣
s
t
n
)
\nabla loss_{A2C}=\frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n}\widehat{A}_t^\omega\nabla logp_\theta (a_{t}^{n}|s{_{t}^{n}})
∇lossA2C=N1n=1∑Nt=1∑TnA
tω∇logpθ(atn∣stn)
这是要计算 ∇ l o g p θ ( a t n ∣ s t n ) \nabla logp_\theta (a_{t}^{n}|s{_{t}^{n}}) ∇logpθ(atn∣stn)的期望,其中 a t n ∣ s t n a_{t}^{n}|s{_{t}^{n}} atn∣stn是一个条件概率,分布是参数为 θ \theta θ的策略网络,也就是我们最终想要得到的网络。假设参数更新后的策略网络参数为 θ \theta θ,老的策略网络参数为 θ ′ \theta' θ′,那么从老的策略网络采样动作,更新新策略网络的话,在计算梯度的时候需要引入重要性采样: p θ ( a t n ∣ s t n ) p θ ′ ( a t n ∣ s t n ) \frac{p_\theta (a_{t}^{n}|s{_{t}^{n}})}{p_{\theta'} (a_{t}^{n}|s{_{t}^{n}})} pθ′(atn∣stn)pθ(atn∣stn),所以上式变成:
∇ l o s s P P O = 1 N ∑ n = 1 N ∑ t = 1 T n p θ ( a t n ∣ s t n ) p θ ′ ( a t n ∣ s t n ) A ^ t ω ∇ l o g p θ ( a t n ∣ s t n ) \nabla loss_{PPO}=\frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n}\frac{p_\theta (a_{t}^{n}|s{_{t}^{n}})}{p_{\theta'} (a_{t}^{n}|s{_{t}^{n}})}\widehat{A}_t^\omega\nabla logp_\theta (a_{t}^{n}|s{_{t}^{n}}) ∇lossPPO=N1n=1∑Nt=1∑Tnpθ′(atn∣stn)pθ(atn∣stn)A tω∇logpθ(atn∣stn)
这样一来,loss就变成了:
l o s s P P O = 1 N ∑ n = 1 N ∑ t = 1 T n p θ ( a t n ∣ s t n ) p θ ′ ( a t n ∣ s t n ) A ^ t ω loss_{PPO}=\frac{1}{N}\sum_{n=1}^{N}\sum_{t=1}^{T_n}\frac{p_\theta (a_{t}^{n}|s{_{t}^{n}})}{p_{\theta'} (a_{t}^{n}|s{_{t}^{n}})}\widehat{A}_t^\omega lossPPO=N1n=1∑Nt=1∑Tnpθ′(atn∣stn)pθ(atn∣stn)A tω
这是因为:
∇ p θ ( a t n ∣ s t n ) = p θ ( a t n ∣ s t n ) ∇ l o g p θ ( a t n ∣ s t n ) \nabla p_\theta (a_{t}^{n}|s{_{t}^{n}})=p_\theta (a_{t}^{n}|s{_{t}^{n}})\nabla logp_\theta (a_{t}^{n}|s{_{t}^{n}}) ∇pθ(atn∣stn)=pθ(atn∣stn)∇logpθ(atn∣stn)
2.3 针对问题2:引入KL距离或者clip函数
针对问题2有两种解决方案(主要是针对loss函数的改进):
2.3.1 KL penalty:KL散度做penalty
一种是DeepMind公司

显然KL距离可以度量两个分布的距离,显然,loss函数的第二项就想让
p
θ
(
a
∣
s
)
p_{\theta}(a|s)
pθ(a∣s)与
p
θ
′
(
a
∣
s
)
p_{\theta'}(a|s)
pθ′(a∣s)的分布差异不要太大。
2.3.2 Clip剪裁:限制策略梯度更新的幅度
另一种是OpenAI公司

2.3.3 对Clip剪裁的解释
一般来讲第二种使用起来更方便一些,更好去定义。本部分主要是来解释第二种。
首先其中的
r
t
(
θ
)
=
p
θ
(
a
t
∣
s
t
)
p
θ
′
(
a
t
∣
s
t
)
r_t(\theta)=\frac{p_\theta (a_{t}|s{_{t}})}{p_{\theta'} (a_{t}|s{_{t}})}
rt(θ)=pθ′(at∣st)pθ(at∣st)
或者写成:
r
t
(
θ
)
=
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
r_t(\theta)=\frac{\pi_\theta (a_{t}|s{_{t}})}{\pi_{\theta_{old}} (a_{t}|s{_{t}})}
rt(θ)=πθold(at∣st)πθ(at∣st)
其中的 A ^ t \widehat{A}_t A t就是前文的 A ^ t ω \widehat{A}_t^\omega A tω,前文的写法是为了凸显参数的不同。
现在想要达到的效果是:
1)当
A
^
t
\widehat{A}_t
A
t大于0的时候说明这个动作是好的,梯度下降会增加这个动作的出现概率,使得
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
\frac{\pi_\theta (a_{t}|s{_{t}})}{\pi_{\theta_{old}} (a_{t}|s{_{t}})}
πθold(at∣st)πθ(at∣st)大于1。但是当
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
\frac{\pi_\theta (a_{t}|s{_{t}})}{\pi_{\theta_{old}} (a_{t}|s{_{t}})}
πθold(at∣st)πθ(at∣st)大于1到某个程度的时候需要让其停止参数更新
2)当
A
^
t
\widehat{A}_t
A
t小于于0的时候说明这个动作是坏的,梯度下降会减小这个动作的出现概率,使得
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
\frac{\pi_\theta (a_{t}|s{_{t}})}{\pi_{\theta_{old}} (a_{t}|s{_{t}})}
πθold(at∣st)πθ(at∣st)小于1。但是当
π
θ
(
a
t
∣
s
t
)
π
θ
o
l
d
(
a
t
∣
s
t
)
\frac{\pi_\theta (a_{t}|s{_{t}})}{\pi_{\theta_{old}} (a_{t}|s{_{t}})}
πθold(at∣st)πθ(at∣st)小于1到某个程度的时候需要让其停止参数更新
这就是“熔断机制”。
验证一下上面的clip版本的loss是否实现了“熔断机制”吧(取
ϵ
=
0.2
\epsilon =0.2
ϵ=0.2):
1)
A
^
t
\widehat{A}_t
A
t大于0:
r
r
r大于1.2之后,min操作就会取右边的值;此时loss中就只剩常量了,不产生任何梯度;而
r
r
r无论多小都还是会产生梯度
2)
A
^
t
\widehat{A}_t
A
t小于0:
r
r
r小于0.8之后,min操作就会取右边的值,此时loss中就只剩常量了,不产生任何梯度;而
r
r
r无论多大都还是会产生梯度
所以总结就是,PPO算法是对A2C算法的基础上加入了:
- 重要性采样(为了可以提高数据效率,一次交互多次训练)
- 熔断机制(为了不让多次训练导致的新老策略网络的差异太大,导致策略分布差异很大,进而导致训练不稳定)
3 PPO-clip训练过程
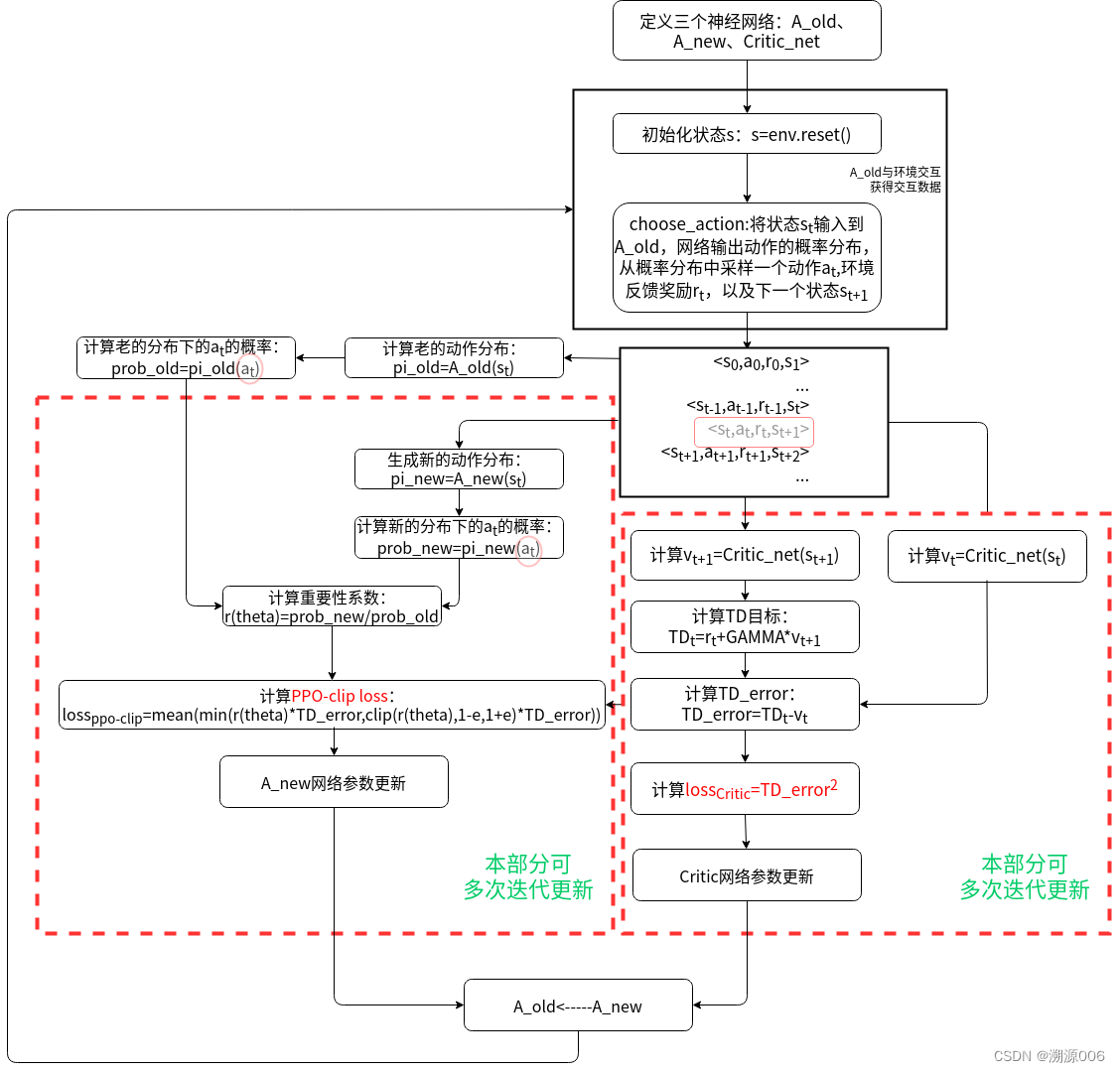 首先注意,上面的图不是正规的流程图,只是突出了数据的走向。两个粉红色圆圈所标注的动作必须是同一个动作。上面定义了三个网络是为了便于理解,实际上定义两个网络就可以。下面的图就用了两个网络,与上面流程等价:
首先注意,上面的图不是正规的流程图,只是突出了数据的走向。两个粉红色圆圈所标注的动作必须是同一个动作。上面定义了三个网络是为了便于理解,实际上定义两个网络就可以。下面的图就用了两个网络,与上面流程等价:
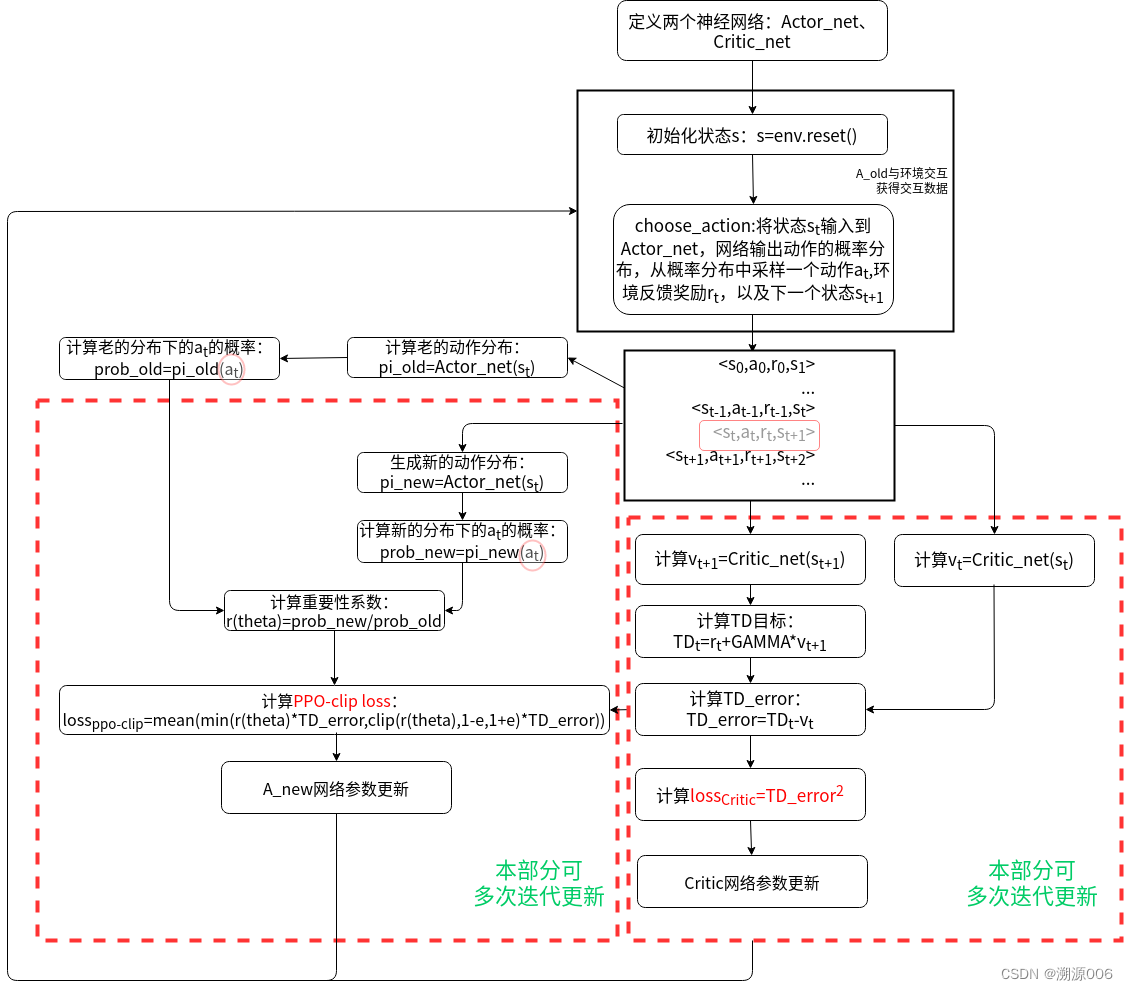
4 PPO-clip pytorch代码
参考链接:https://zhuanlan.zhihu.com/p/538486008
#开发者:Bright Fang
#开发时间:2022/6/28 23:02
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gym
from matplotlib import pyplot as plt
import os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
class MyWrapper(gym.Wrapper):
def __init__(self):
env = gym.make('Pendulum-v1', render_mode='human')
super().__init__(env)
self.env = env
self.step_n = 0
def reset(self):
state, _ = self.env.reset()
self.step_n = 0
return state
def step(self, action):
state, reward, done, _, info = self.env.step(action)
#一局游戏最多走N步
self.step_n += 1
if self.step_n >= 200:
done = True
return state, reward, done, info
# env = gym.make('Pendulum-v1').unwrapped
env = MyWrapper()
env.reset()
'''Pendulum环境状态特征是三个,杆子的sin(角度)、cos(角度)、角速度,(状态是无限多个,因为连续),动作值是力矩,限定在[-2,2]之间的任意的小数,所以是连续的(动作也是无限个)'''
state_number=env.observation_space.shape[0]
action_number=env.action_space.shape[0]
max_action = env.action_space.high[0]
min_action = env.action_space.low[0]
torch.manual_seed(0)#如果你觉得定了随机种子不能表达代码的泛化能力,你可以把这两行注释掉
# env.seed(0)
RENDER=False
EP_MAX = 1000
EP_LEN = 200
GAMMA = 0.9
A_LR = 0.0001
C_LR = 0.0003
BATCH = 128
A_UPDATE_STEPS = 10
C_UPDATE_STEPS = 10
METHOD = [
dict(name='kl_pen', kl_target=0.01, lam=0.5), # KL penalty
dict(name='clip', epsilon=0.2), # Clipped surrogate objective, find this is better
][1] # choose the method for optimization
Switch=0
'''由于PPO也是基于A-C框架,所以我把PPO的编写分为两部分,PPO的第一部分 Actor'''
'''PPO的第一步 编写A-C框架的网络,先编写actor部分的actor网络,actor的网络有新与老两个网络'''
class ActorNet(nn.Module):
def __init__(self,inp,outp):
super(ActorNet, self).__init__()
self.in_to_y1=nn.Linear(inp,100)
self.in_to_y1.weight.data.normal_(0,0.1)
self.out=nn.Linear(100,outp)
self.out.weight.data.normal_(0,0.1)
self.std_out = nn.Linear(100, outp)
self.std_out.weight.data.normal_(0, 0.1)
'''生成均值与标准差,PPO必须这样做,一定要生成分布(所以需要mean与std),不然后续学习策略里的公式写不了,DDPG是可以不用生成概率分布的'''
def forward(self,inputstate):
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
mean=max_action*torch.tanh(self.out(inputstate))#输出概率分布的均值mean
std=F.softplus(self.std_out(inputstate))#softplus激活函数的值域>0
return mean,std
'''再编写critic部分的critic网络,PPO的critic部分与AC算法的critic部分是一样,PPO不一样的地方只在actor部分'''
class CriticNet(nn.Module):
def __init__(self,input,output):
super(CriticNet, self).__init__()
self.in_to_y1=nn.Linear(input,100)
self.in_to_y1.weight.data.normal_(0,0.1)
self.out=nn.Linear(100,output)
self.out.weight.data.normal_(0,0.1)
def forward(self,inputstate):
inputstate=self.in_to_y1(inputstate)
inputstate=F.relu(inputstate)
Q=self.out(inputstate)
return Q
class Actor():
def __init__(self):
self.old_pi,self.new_pi=ActorNet(state_number,action_number),ActorNet(state_number,action_number)#这只是均值mean
self.optimizer=torch.optim.Adam(self.new_pi.parameters(),lr=A_LR,eps=1e-5)
'''第二步 编写根据状态选择动作的函数'''
def choose_action(self,s):
inputstate = torch.FloatTensor(s)
mean,std=self.old_pi(inputstate)
dist = torch.distributions.Normal(mean, std)
action=dist.sample()
action=torch.clamp(action,min_action,max_action)
action_logprob=dist.log_prob(action)
return action.detach().numpy(),action_logprob.detach().numpy()
'''第四步 actor网络有两个策略(更新old策略)————————把new策略的参数赋给old策略'''
def update_oldpi(self):
self.old_pi.load_state_dict(self.new_pi.state_dict())
'''第六步 编写actor网络的学习函数,采用PPO2,即OpenAI推出的clip形式公式'''
def learn(self,bs,ba,adv,bap):
bs = torch.FloatTensor(bs)
ba = torch.FloatTensor(ba)
adv = torch.FloatTensor(adv)
bap = torch.FloatTensor(bap)
for _ in range(A_UPDATE_STEPS):
mean, std = self.new_pi(bs)
dist_new=torch.distributions.Normal(mean, std)
action_new_logprob=dist_new.log_prob(ba)#######!!!!这个很关键,计算的还是原来的动作的概率!!!
ratio=torch.exp(action_new_logprob - bap.detach())
surr1 = ratio * adv
surr2 = torch.clamp(ratio, 1 - METHOD['epsilon'], 1 + METHOD['epsilon']) * adv
loss = -torch.min(surr1, surr2)
loss=loss.mean()
self.optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(self.new_pi.parameters(), 0.5)
self.optimizer.step()
class Critic():
def __init__(self):
self.critic_v=CriticNet(state_number,1)#改网络输入状态,生成一个Q值
self.optimizer = torch.optim.Adam(self.critic_v.parameters(), lr=C_LR,eps=1e-5)
self.lossfunc = nn.MSELoss()
'''第三步 编写评定动作价值的函数'''
def get_v(self,s):
inputstate = torch.FloatTensor(s)
return self.critic_v(inputstate)
'''第五步 计算优势——————advantage,后面发现第五步计算出来的adv可以与第七步合为一体,所以这里的代码注释了,但是,计算优势依然算是可以单独拎出来的一个步骤'''
# def get_adv(self,bs,br):
# reality_v=torch.FloatTensor(br)
# v=self.get_v(bs)
# adv=(reality_v-v).detach()
# return adv
'''第七步 编写actor-critic的critic部分的learn函数,td-error的计算代码(V现实减去V估计就是td-error)'''
def learn(self,bs,br):
bs = torch.FloatTensor(bs)
reality_v = torch.FloatTensor(br)
for _ in range(C_UPDATE_STEPS):
v=self.get_v(bs)
td_e = self.lossfunc(reality_v, v)
self.optimizer.zero_grad()
td_e.backward()
nn.utils.clip_grad_norm_(self.critic_v.parameters(), 0.5)
self.optimizer.step()
return (reality_v-v).detach()
if Switch==0:
print('PPO2训练中...')
actor=Actor()
critic=Critic()
all_ep_r = []
for episode in range(EP_MAX):
observation = env.reset() #环境重置
buffer_s, buffer_a, buffer_r,buffer_a_logp = [], [], [],[]
reward_totle=0
for timestep in range(EP_LEN):
if RENDER:
env.render()
action,action_logprob=actor.choose_action(observation)
observation_, reward, done, info = env.step(action)
buffer_s.append(observation)
buffer_a.append(action)
buffer_r.append((reward+8)/8) # normalize reward, find to be useful
buffer_a_logp.append(action_logprob)
observation=observation_
reward_totle+=reward
reward = (reward - reward.mean()) / (reward.std() + 1e-5)
#PPO 更新
if (timestep+1) % BATCH == 0 or timestep == EP_LEN-1:
v_observation_ = critic.get_v(observation_)
discounted_r = []
for reward in buffer_r[::-1]:
v_observation_ = reward + GAMMA * v_observation_
discounted_r.append(v_observation_.detach().numpy())
discounted_r.reverse()
bs, ba, br,bap = np.vstack(buffer_s), np.vstack(buffer_a), np.array(discounted_r),np.vstack(buffer_a_logp)
buffer_s, buffer_a, buffer_r,buffer_a_logp = [], [], [],[]
advantage=critic.learn(bs,br)#critic部分更新
actor.learn(bs,ba,advantage,bap)#actor部分更新
actor.update_oldpi() # pi-new的参数赋给pi-old
# critic.learn(bs,br)
if episode == 0:
all_ep_r.append(reward_totle)
else:
all_ep_r.append(all_ep_r[-1] * 0.9 + reward_totle * 0.1)
print("\rEp: {} |rewards: {}".format(episode, reward_totle), end="")
#保存神经网络参数
if episode % 50 == 0 and episode > 100:#保存神经网络参数
save_data = {'net': actor.old_pi.state_dict(), 'opt': actor.optimizer.state_dict(), 'i': episode}
torch.save(save_data, "E:\PPO2_model_actor.pth")
save_data = {'net': critic.critic_v.state_dict(), 'opt': critic.optimizer.state_dict(), 'i': episode}
torch.save(save_data, "E:\PPO2_model_critic.pth")
env.close()
plt.plot(np.arange(len(all_ep_r)), all_ep_r)
plt.xlabel('Episode')
plt.ylabel('Moving averaged episode reward')
plt.show()
else:
print('PPO2测试中...')
aa=Actor()
cc=Critic()
checkpoint_aa = torch.load("E:\PPO2_model_actor.pth")
aa.old_pi.load_state_dict(checkpoint_aa['net'])
checkpoint_cc = torch.load("E:\PPO2_model_critic.pth")
cc.critic_v.load_state_dict(checkpoint_cc['net'])
for j in range(10):
state = env.reset()
total_rewards = 0
for timestep in range(EP_LEN):
env.render()
action, action_logprob = aa.choose_action(state)
new_state, reward, done, info = env.step(action) # 执行动作
total_rewards += reward
state = new_state
print("Score:", total_rewards)
env.close()
5 PPO stable-baselines3代码
import gym
from stable_baselines3.common.evaluation import evaluate_policy
from stable_baselines3 import PPO
from stable_baselines3.common.env_util import make_vec_env
#定义环境
class MyWrapper(gym.Wrapper):
def __init__(self):
env = gym.make('LunarLander-v2',
continuous=True,
render_mode='rgb_array')
super().__init__(env)
self.env = env
self.step_n = 0
def reset(self):
state, _ = self.env.reset()
self.step_n = 0
return state
def step(self, action):
state, reward, done, _, info = self.env.step(action)
self.step_n += 1
if self.step_n >= 400:
done = True
return state, reward, done, info
class MyWrapper2(gym.Wrapper):
def __init__(self):
env = gym.make('LunarLander-v2',
continuous=True,
render_mode='human')
super().__init__(env)
self.env = env
self.step_n = 0
def reset(self):
state, _ = self.env.reset()
self.step_n = 0
return state
def step(self, action):
state, reward, done, _, info = self.env.step(action)
self.step_n += 1
if self.step_n >= 400:
done = True
return state, reward, done, info
env = MyWrapper()
env.reset()
#认识游戏环境
def test_env():
print('env.observation_space=', env.observation_space)
print('env.action_space=', env.action_space)
state = env.reset()
action = env.action_space.sample()
next_state, reward, done, info = env.step(action)
print('state=', state)
print('action=', action)
print('next_state=', next_state)
print('reward=', reward)
print('done=', done)
print('info=', info)
test_env()
#初始化模型
model = PPO(
policy='MlpPolicy',
env=make_vec_env(MyWrapper, n_envs=8), #使用N个环境同时训练
learning_rate=1e-3,
n_steps=1024, #运行N步后执行更新,buffer_size=n_steps*环境数量
batch_size=64, #采样数据量
n_epochs=16, #每次采样后训练的次数
gamma=0.99,
verbose=0)
#训练
model.learn(100000, progress_bar=True)
#保存模型
model.save('save/2.PPO.Lunar Lander Continuous')
#加载模型
model = PPO.load('save/2.PPO.Lunar Lander Continuous')
evaluate_policy(model, env, n_eval_episodes=20, deterministic=False)
# from IPython import display
# import random
def test():
env2 = MyWrapper2()
for ii in range(10):
state = env2.reset()
reward_sum = []
over = False
while not over:
action, _ = model.predict(state)
state, reward, over, _ = env2.step(action)
reward_sum.append(reward)
# if len(reward_sum) % 5 == 0:
# display.clear_output(wait=True)
# show()
print(sum(reward_sum), len(reward_sum))
env2.close()
test()
参考:
https://blog.csdn.net/ningmengzhihe/article/details/131459848
https://zhuanlan.zhihu.com/p/643751150
https://zhuanlan.zhihu.com/p/538486008

















 1748
1748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









