






简易版流水线
- 流水线总体思想-自己感悟
将指令执行分成若干个阶段(五级流水-取值,译码,执行,访存,写回),每个阶段干自己的事(生成相应的控制信号,完成自己的工作)。由于需要“流水”,所以四个寄存器就需要发挥“中断”和“传递”的作用。不仅要把该指令的后续阶段的信号“继承”,而且还要“发扬”,因为不同的指令可能在不同的阶段会对该指令的后续阶段产生相应的信号。
IF-stage
if_stage 模块负责在每个时钟周期中取指令,计算下一条指令的地址,处理分支目标的逻辑,并将获取的指令数据传递给 ID 阶段,以支持下一阶段的指令解码和执行。
- fs_allowin 信号产生逻辑
assign fs_allowin = !fs_valid || (fs_ready_go && ds_allowin);
!fs_valid:这一部分表示如果 IF 阶段当前不是有效状态(fs_valid 为假),那么 fs_allowin 会为真。这通常在刚启动 CPU 或发生重置时,IF 阶段需要接收新的指令,因此允许接收来自 ID 阶段的取指令请求。
(fs_ready_go && ds_allowin):这一部分表示如果 IF 阶段已经准备好(fs_ready_go 为真),并且来自 ID 阶段的 ds_allowin 信号为真,那么 fs_allowin 也为真。这意味着 IF 阶段已准备好接收新的指令,且 ID 阶段要求传递指令。
ID-stage
ID 阶段模块执行指令解码、数据通路控制、数据相关性检测以及流水线控制等任务,为指令的正确执行和顺利传递到下一个阶段提供必要的支持。同时,该模块还涉及分支预测、寄存器堆访问、目的寄存器和数据冒险等方面的操作。
EXE-stage
执行阶段模块执行指令的算术逻辑操作,包括 ALU 计算、数据内存访问等,同时也涉及到数据通路的控制和流水线阶段控制。它为指令的正确执行和数据的准备传递到存储阶段提供必要的支持。此外,也有目的寄存器、数据相关性、立即数和操作数选择等方面的操作。
MEM-stage
内存阶段模块主要负责处理数据存储访问操作,包括从数据存储中读取数据,并准备将数据传递给下一个阶段。它还与目的寄存器相关,根据执行阶段的计算结果和数据存储的结果,选择传递的数据。流水线阶段控制确保数据在合适的时间被传递到下一个阶段。
WB-stage
写回阶段模块负责控制数据写回到寄存器文件的操作。这包括确定何时执行写回操作,以及将何种数据写回到寄存器文件。控制流程和数据传递在时钟的控制下执行,确保正确的数据被写回。
流水线-流起来的秘密之一
- if-stage
always @(posedge clk) begin
if (reset) begin
fs_valid <= 1'b0;
end
else if (fs_allowin) begin
fs_valid <= to_fs_valid;
end
if (reset) begin
fs_pc <= 32'hbfbffffc; //trick: to make nextpc be 0xbfc00000 during reset
end
else if (to_fs_valid && fs_allowin) begin
fs_pc <= nextpc;
end
end
- id-stage
always @(posedge clk ) begin
if (reset) begin
ds_valid <= 1'b0;
end
else if (ds_allowin) begin
ds_valid <= fs_to_ds_valid;
end
end
always @(posedge clk) begin
if (fs_to_ds_valid && ds_allowin) begin
fs_to_ds_bus_r <= fs_to_ds_bus;
end
end
- exe-stage
always @(posedge clk) begin
if (reset) begin
es_valid <= 1'b0;
end
else if (es_allowin) begin
es_valid <= ds_to_es_valid;
end
if (ds_to_es_valid && es_allowin) begin
ds_to_es_bus_r <= ds_to_es_bus;
end
- mem-stage
always @(posedge clk) begin
if (reset) begin
ms_valid <= 1'b0;
end
else if (ms_allowin) begin
ms_valid <= es_to_ms_valid;
end
if (es_to_ms_valid && ms_allowin) begin
es_to_ms_bus_r = es_to_ms_bus;
end
end
- wb-stage
always @(posedge clk) begin
if (reset) begin
ws_valid <= 1'b0;
end
else if (ws_allowin) begin
ws_valid <= ms_to_ws_valid;
end
if (ms_to_ws_valid && ws_allowin) begin
ms_to_ws_bus_r <= ms_to_ws_bus;
end
end
处理寄存器写后读相关引发的流水线冲突
产生由寄存器写后读数据相关所引发的流水线冲突的场景是:产生结果的指令尚未讲结果写回到寄存器堆中,而需要这个结果的指令已经在译码阶段了,此刻他从通用寄存器堆中独处的数值是旧值而非新值。
一种直观的解决思路是:让需要结果的指令在译码流水级一直等待,直到产生结果的指令将结果写回到通用寄存器堆,才可以进入到下一级的执行流水线。
- 设计思路
关键点在于控制译码流水级指令前进还是阻塞的条件如何生成:判断处于流水线不同阶段的指令是否存在会引发冲突的“写后读”相关。具体描述为:处于译码流水级的指令具有来自非0号寄存器的源操作数,那么如果这些源操作数中任何一个的寄存器号与当前时刻处于执行级、访存级和写回级的指令的目的操作数的寄存器号相同,则表明处于译码级的指令与处于后面三个级别的指令存在“写后读”相关关系。有一个隐含的细节容易被初学者忽视,那就是一定要保证被比较的两个寄存器号都是有效的。
- 参与比较的指令到底有没有寄存器的源操作数或是寄存器的目的操作数。ADDIU只有rs。JAL没有寄存器的源操作数,BNE,BEQ,JR没有寄存器的目的操作数。
- 如果指令的定义确实有寄存器的源操作数或者目的操作数,但是寄存器号为0,也不用比较,MIPS架构下0号寄存器的值永远为0.
- 用来进行比较的流水级上到底有没有指令,如果没有指令,那么这一级的寄存器号,指令类型等信息都是无效的。
如何判断条件成立的时候,把这条指令阻塞在译码流水级。只需要堆译码流水级的 ready_go 信号进行调整。
- 特殊情况
Load-to-Branch 即第i条指令是Load,第i+1条指令是转移(分支或跳转)指令,转移指令至少有一个源寄存器与Load指令的目的寄存器相同,也就是存在写后读。在这种情况下,成为转移计算未完成。
此时由译码级送到取指级的转移信息(br_bus)参与生成的nextPC就是不正确的,所以应该在译码级送到取指级的br_bus上新增一个控制信号br_stall,用来表示转移计算未完成。另外,要为pre-IF新增一个ready_go,当br_stall为1时,组合逻辑ready_go信号置为0,进而to_fs_valid为0;IF级看到to_fs_valid为0,当IF级的allowin为1时,时序逻辑会置IF-valid为0。另外,nextPC是送到指令RAM的地址端口的,当转移计算未完成时,建议应该控制指令RAM的读使能为0.
前递技术
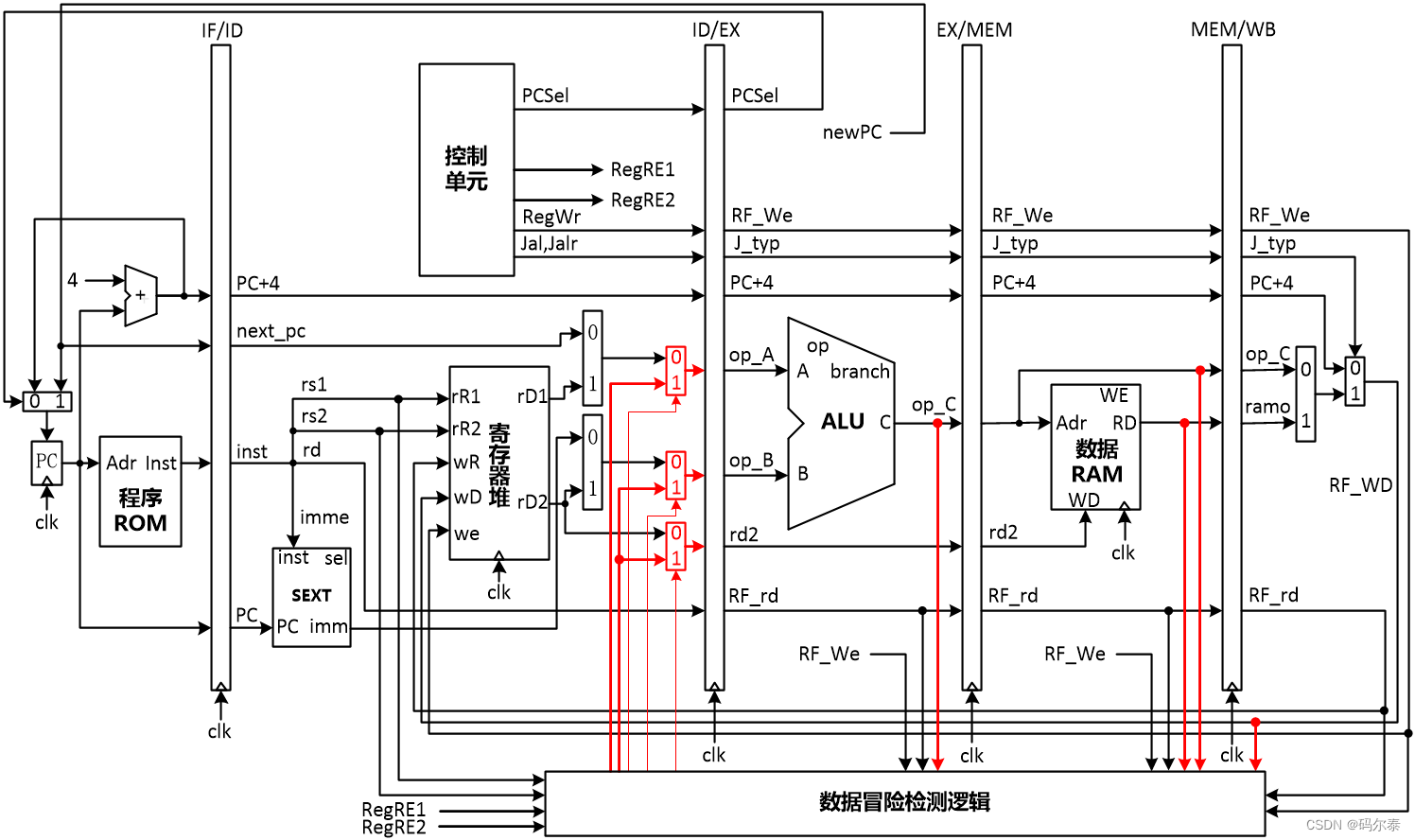
贴一张不是特别合适的图,但应该能够表达含义了。
在考虑前递路径设计时,ADDU指令代表了那些在执行级就能产生结果的指令。但是LW指令不属于这一类指令,它直到访存级才能生成结果。不过分析之后会发现,LW指令完全可以复用那些为了前递ADDU类指令结果而在访存级和写回级增加的前递路径。因为前递路径知识把结果送出器,有寄存器号和数值这两个信息就够了,与产生结果的指令的功能没有关系。
有两种可行的设计方案:
- 起点位于执行级ALU的结果输出处,终点位于译码级寄存器堆独处结果生成逻辑处
- 起点位于访存级流水线缓存中存放ALU结果的触发器的Q端口输出处,终点位于执行级ALU输入数据生成逻辑处。
这里选择方案一更好一点。访存级结果的前递路径起点就是数据RAM返回结果和访存级缓存所保存的ALU结果经过二选一之后的结果输出处。另一种情况,为了解决控制相关引发的流水线冲突,我们将所有转移指令的处理都放到了译码级,在目前实现的转移指令中,BEQ、BNE、JR三条指令都有寄存器源操作数。如果他们和前面的指令存在写后读的相关关系,那么除非前递路径的终点实在译码级,否则他们必须阻塞自己直到写到寄存器堆中。
- 调整译码级产生寄存器读结果的逻辑。从空间上看,译码级指令的寄存器源操作数1的数值可以来自通用寄存器堆读端口1的输出,也可以来自执行级、访存级和写回级三处前递来的结果。同样,译码级指令的寄存器源操作数2的数值,可以来自通用寄存器堆读端口2的输出,也可以来自执行级、访存级、写回级三处前递来的结果。所以我们需要添加两个“四选一”不见,而且是两个具有选择优先权的“四选一”部件。选择哪个传递结果,不仅要看源操作数的寄存器号,与前递来的结果的寄存器号是否一致,还要考虑不同流水级之间的优先级关系。
mips 19条指令 + 阻塞 + 前递结构大意图(部分不完整)

SOC结构
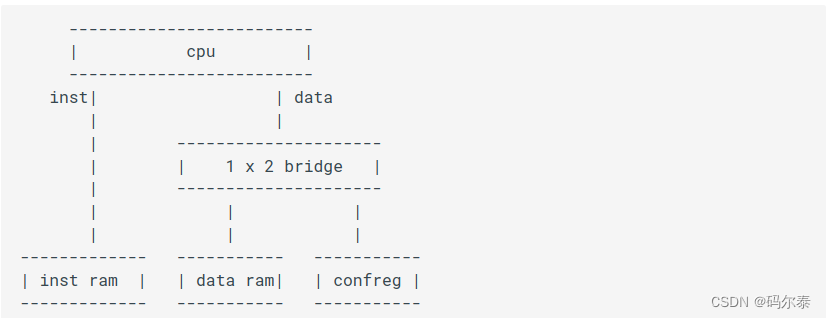
控制外设
LoongArch 访问外设的方法是MMIO,也就是将外设寄存器直接映射到地址空间上,CPU通过ld/st指令进行操作。CPU访问外设的数据通路是:
- 流水线想数据类SRAM 总线发起访存请求(CPU 内部逻辑)
- 访存请求到达1 x 2 bridge 上,转换桥进行仲裁,将请求送到与 confreg 相连的总线上
- confreg 请求,内部进行处理,改变输出端口的电平(confreg.v)
- 通过约束文件将输出端口绑定到芯片引脚上,从而控制具体的外设。
再来看软件部分。我们需要使用ld/st指令来操作外设,因此,需要知道访问的地址以及读写数据的含义。


















 806
806

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











