







 本文通过Python实现数据预处理、特征工程、模型构建(逻辑回归与随机森林),展示了如何运用数据可视化技术(如盒图、柱状图)分析不同因素对违约的影响,包括城市级别、文化程度、三要素验证等,并评估模型性能,如AUC-ROC曲线。
本文通过Python实现数据预处理、特征工程、模型构建(逻辑回归与随机森林),展示了如何运用数据可视化技术(如盒图、柱状图)分析不同因素对违约的影响,包括城市级别、文化程度、三要素验证等,并评估模型性能,如AUC-ROC曲线。
3.2
import pymysql
connection = pymysql.connect(host='traindba.cookdata.cn',port=3306,user='raa_user',password='bigdata123',db='risk_assessment_analysis',charset='utf8mb4',cursorclass=pymysql.cursors.DictCursor)
try:
with connection.cursor() as cursor:
sql = "select * from all_data"
cursor.execute(sql)
all_data = cursor.fetchall()
finally:
connection.close()
# 查看数据前两个元素
print(all_data[:2])
3.3
import pandas as pd
#将列表转换为DataFrame
data =pd.DataFrame(all_data)
print(data[:100])
4.2
import pandas as pd
# 使用head()函数查看数据前五行
data_5 = data.head()
print(data_5)
4.4
import pandas as pd
# 使用describe()函数查看数据整体的基本统计信息
data_des = data.describe(include='all')
print(data_des)
4.5
import pandas as pd
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(8,6))
# 绘制柱状图,查看违约关系的取值分布情况
data['Default'].value_counts(dropna=False).plot(kind='bar',rot=40)
# 在柱形上方显示计数
counts = data['Default'].value_counts(dropna=False).values
for index, item in zip([0,1,2], counts):
plt.text(index, item, item, ha="center", va= "bottom", fontsize=12)
# 设置柱形名称
plt.xticks([0,1,2],['未违约','违约','NaN'])
# 设置x、y轴标签
plt.xlabel("是否违约")
plt.ylabel("客户数量")
# 设置标题以及字体大小
plt.title("违约与未违约数量分布图",size=13)
# 设置中文显示
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
plt.show()
4.6
import seaborn as sns
import matplotlib.pyplot as plt
fig,[ax1,ax2] = plt.subplots(1,2,figsize=(16,6))
# 对CityId列的类别设定顺序
data['CityId'] = data['CityId'].astype('category')
data['CityId'] = data['CityId'].cat.set_categories(['一线城市', '二线城市', '其它'],ordered=True)
# 绘制柱状图,查看不同城市级别在不同是否违约的取值分布情况
sns.countplot(x='CityId',hue='Default',data=data,ax=ax1)
# 将具体的计数值显示在柱形上方
counts=data['Default'].groupby(data['CityId']).value_counts().values
count1 = counts[[0, 2, 4]]
count2 = counts[[1, 3, 5]]
for index, item1, item2 in zip([0,1,2], count1, count2):
ax1.text(index-0.2, item1 + 0.05, '%.0f' % item1, ha="center", va= "bottom",fontsize=12)
ax1.text(index+0.2, item2 + 0.05, '%.0f' % item2, ha="center", va= "bottom",fontsize=12)
# 绘制柱状图查看违约率分布
cityid_rate = data.groupby('CityId')['Default'].sum() / data.groupby('CityId')['Default'].count()
sns.barplot(x=[0,1,2],y=cityid_rate,ax=ax2)
# 将具体的计数值显示在柱形上方
for index, item in zip([0,1,2], cityid_rate):
ax2.text(index, item, '%.3f' % item, ha="center", va= "bottom",fontsize=12)
#设置柱形名称
ax1.set_xticklabels(['一线城市','二线城市','其它'])
ax2.set_xticklabels(['一线城市','二线城市','其它'])
# 设置图例名称
ax1.legend(['未违约','违约'])
# 设置标题以及字体大小
ax1.set_title("不同城市级别下不同违约情况数量分布柱状图",size=13)
ax2.set_title("不同城市级别违约率分布柱状图",size=13)
# 设置x,y轴标签
ax1.set_xlabel("CityId")
ax1.set_ylabel("客户人数")
ax2.set_xlabel("CityId")
ax2.set_ylabel("违约率")
#显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
plt.show()
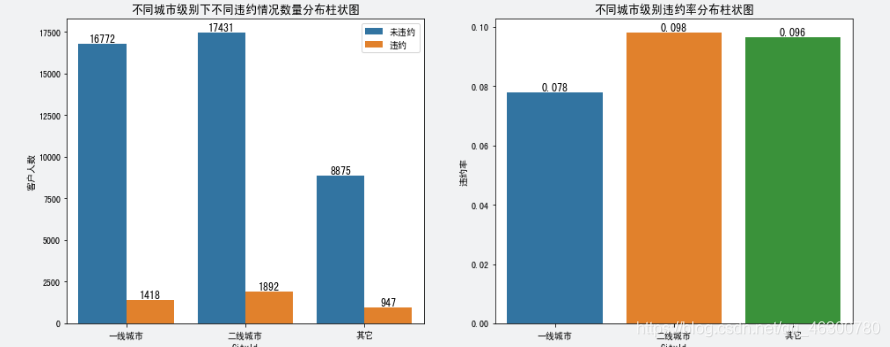
4.7
import seaborn as sns
import matplotlib.pyplot as plt
fig,[ax1,ax2] = plt.subplots(1,2,figsize=(16,6))
# 对education列的类别设定顺序
data['education'] = data['education'].astype('category')
data['education'] = data['education'].cat.set_categories(['小学', '初中', '高中', '本科以上'],ordered=True)
# 绘制柱状图,查看不同文化程度(education)在不同是否违约(Default)的取值分布情况
sns.countplot(x='education', hue='Default', data=data, ax=ax1)
# 将具体的计数值显示在柱形上方
counts=data['Default'].groupby(data['education']).value_counts().values
count1 = counts[[0, 2, 4,6]]
count2 = counts[[1, 3, 5,7]]
for index, item1, item2 in zip([0,1,2,3], count1, count2):
ax1.text(index-0.2, item1 + 0.05, '%.0f' % item1, ha="center", va= "bottom",fontsize=12)
ax1.text(index+0.2, item2 + 0.05, '%.0f' % item2, ha="center", va= "bottom",fontsize=12)
# 绘制柱状图查看违约率分布
education_rate = data.groupby('education')['Default'].sum() / data.groupby('education')['Default'].count()
sns.barplot(x=[0,1,2,3],y=education_rate.values,ax=ax2)
# 将具体的计数值显示在柱形上方
for index, item in zip([0,1,2,3], education_rate):
ax2.text(index, item, '%.2f' % item, ha="center", va= "bottom",fontsize=12)
# 设置柱形名称
ax1.set_xticklabels(['小学', '初中', '高中','本科以上'])
ax2.set_xticklabels(['小学', '初中', '高中','本科以上'])
# 设置图例名称
ax1.legend(['未违约','违约'])
# 设置标题以及字体大小
ax1.set_title("不同文化程度下不同违约情况数量分布柱状图",size=13)
ax2.set_title("不同文化程度下违约率分布柱状图",size=13)
# 设置x,y轴标签
ax1.set_xlabel("education")
ax1.set_ylabel("客户人数")
ax2.set_xlabel("education")
ax2.set_ylabel("违约率")
#显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
plt.show()
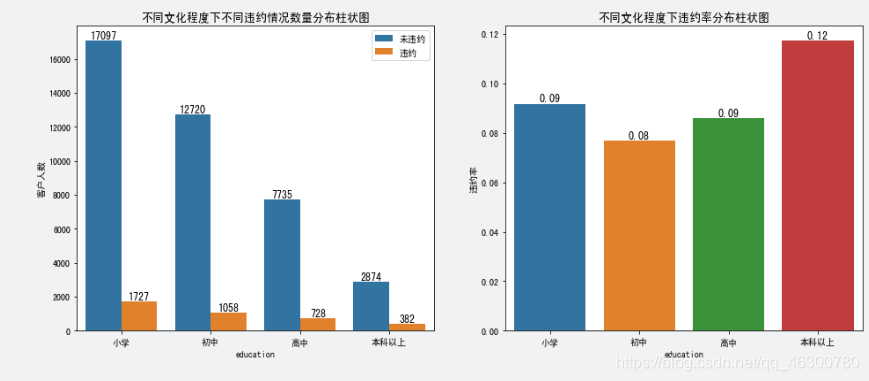
4.8
import seaborn as sns
import matplotlib.pyplot as plt
fig,[ax1,ax2] = plt.subplots(1,2,figsize=(16,6))
# 对threeVerify列的类别设定顺序
data['threeVerify'] = data['threeVerify'].astype('category')
data['threeVerify'] = data['threeVerify'].cat.set_categories(['一致','不一致'],ordered=True)
# 绘制柱状图,查看不同三要素验证情况(threeVerify)在不同是否违约(Default)的取值分布情况
sns.countplot(x='threeVerify', hue='Default', data=data, ax=ax1)
# 将具体的计数值显示在柱形上方
counts=data['Default'].groupby(data['threeVerify']).value_counts().values
count1 = counts[[0, 2]]
count2 = counts[[1, 3]]
for index, item1, item2 in zip([0,1,2,3], count1, count2):
ax1.text(index-0.2, item1 + 0.05, '%.0f' % item1, ha="center", va= "bottom",fontsize=12)
ax1.text(index+0.2, item2 + 0.05, '%.0f' % item2, ha="center", va= "bottom",fontsize=12)
# 绘制柱状图查看违约率分布
threeVerify_rate = data.groupby('threeVerify')['Default'].sum() / data.groupby('threeVerify')['Default'].count()
sns.barplot(x=[0,1],y=threeVerify_rate.values,ax=ax2)
# 将具体的计数值显示在柱形上方
for index, item in zip([0,1], threeVerify_rate):
ax2.text(index, item, '%.2f' % item, ha="center", va= "bottom",fontsize=12)
# 设置柱形名称
ax1.set_xticklabels(['一致', '不一致'])
ax2.set_xticklabels(['一致', '不一致'])
# 设置图例名称
ax1.legend(['未违约','违约'])
# 设置标题以及字体大小
ax1.set_title("不同三要素验证下不同违约情况数量分布柱状图",size=13)
ax2.set_title("不同三要素验证下违约率分布柱状图",size=13)
# 设置x,y轴标签
ax1.set_xlabel("threeVerify")
ax1.set_ylabel("客户人数")
ax2.set_xlabel("threeVerify")
ax2.set_ylabel("违约率")
#显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
plt.show()
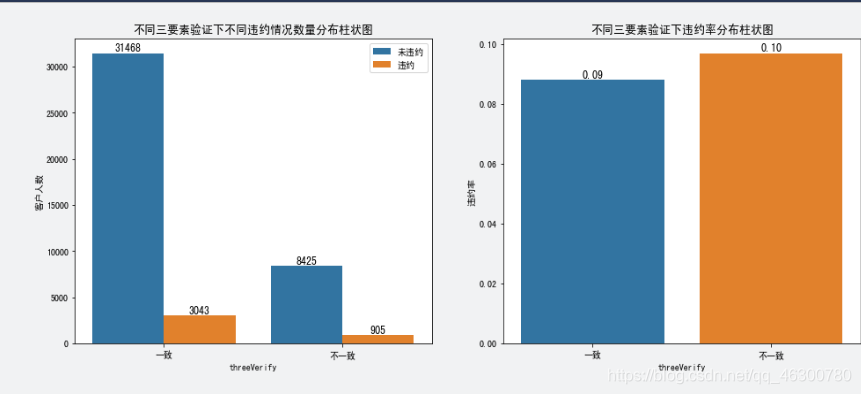
4.9
import seaborn as sns
import matplotlib.pyplot as plt
fig,[ax1,ax2] = plt.subplots(1,2,figsize=(16,6))
# 对maritalStatus列的类别设定顺序
data['maritalStatus'] = data['maritalStatus'].astype('category')
data['maritalStatus'] = data['maritalStatus'].cat.set_categories(['未婚','已婚'],ordered=True)
# 绘制柱状图,查看不同婚姻状况在不同违约情况的取值分布
sns.countplot(x='maritalStatus', hue='Default', data=data, ax=ax1)
# 将具体的计数值显示在柱形上方
counts=data['Default'].groupby(data['maritalStatus']).value_counts().values
count1 = counts[[0, 2]]
count2 = counts[[1, 3]]
for index, item1, item2 in zip([0,1,2,3], count1, count2):
ax1.text(index-0.2, item1 + 0.05, '%.0f' % item1, ha="center", va= "bottom",fontsize=12)
ax1.text(index+0.2, item2 + 0.05, '%.0f' % item2, ha="center", va= "bottom",fontsize=12)
# 绘制柱状图查看违约率分布
maritalStatus_rate = data.groupby('maritalStatus')['Default'].sum() / data.groupby('maritalStatus')['Default'].count()
sns.barplot(x=[0,1],y=maritalStatus_rate.values,ax=ax2)
# 将具体的计数值显示在柱形上方
for index, item in zip([0,1], maritalStatus_rate):
ax2.text(index, item, '%.2f' % item, ha="center", va= "bottom",fontsize=12)
# 设置柱形名称
ax1.set_xticklabels(['未婚', '已婚'])
ax2.set_xticklabels(['未婚', '已婚'])
# 设置图例名称
ax1.legend(['未违约','违约'])
# 设置标题以及字体大小
ax1.set_title("不同婚姻状况下不同违约情况数量分布柱状图",size=13)
ax2.set_title("不同婚姻状况下违约率分布柱状图",size=13)
# 设置x,y轴标签
ax1.set_xlabel("maritalStatus")
ax1.set_ylabel("客户人数")
ax2.set_xlabel("maritalStatus")
ax2.set_ylabel("违约率")
#显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
plt.show()
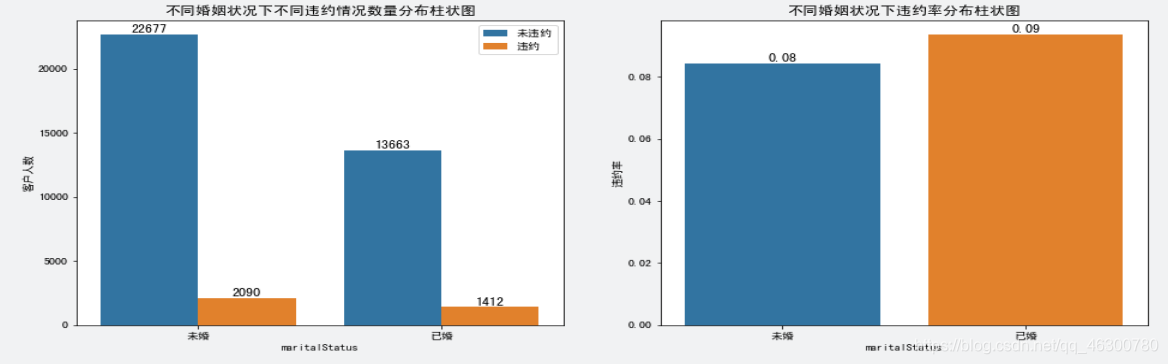
4.10
import seaborn as sns
import matplotlib.pyplot as plt
fig,[ax1,ax2] = plt.subplots(1,2,figsize=(16,6))
# 对netLength列的类别设定顺序
data['netLength'] = data['netLength'].astype('category')
data['netLength'] = data['netLength'].cat.set_categories(['0-6个月','6-12个月','12-24个月','24个月以上','无效'],ordered=True)
# 绘制柱状图,查看不同在网时长在不同违约情况的取值分布
sns.countplot(x='netLength', hue='Default', data=data, ax=ax1)
# 将具体的计数值显示在柱形上方
counts=data['Default'].groupby(data['netLength']).value_counts().values
count1 = counts[[0,2,4,6,8]]
count2 = counts[[1,3,5,7,9]]
# 将具体的计数值显示在柱形上方
for index, item1, item2 in zip([0,1,2,3,4], count1, count2):
ax1.text(index-0.2, item1 + 0.05, '%.0f' % item1, ha="center", va= "bottom",fontsize=12)
ax1.text(index+0.2, item2 + 0.05, '%.0f' % item2, ha="center", va= "bottom",fontsize=12)
# 绘制柱状图查看违约率分布
netLength_rate = data.groupby('netLength')['Default'].sum() / data.groupby('netLength')['Default'].count()
sns.barplot(x=[0,1,2,3,4],y=netLength_rate.values,ax=ax2)
# 将具体的计数值显示在柱形上方
for index, item in zip([0,1,2,3,4], netLength_rate):
ax2.text(index, item, '%.2f' % item, ha="center", va= "bottom",fontsize=12)
# 设置柱形名称
ax1.set_xticklabels(['0-6个月', '6-12个月','12-24个月','24个月以上','无效'])
ax2.set_xticklabels(['0-6个月', '6-12个月','12-24个月','24个月以上','无效'])
# 设置图例名称
ax1.legend(['未违约','违约'])
# 设置标题以及字体大小
ax1.set_title("不同在网时长下不同违约情况数量分布柱状图",size=13)
ax2.set_title("不同在网时长下违约率分布柱状图",size=13)
# 设置x,y轴标签
ax1.set_xlabel("netLength")
ax1.set_ylabel("客户人数")
ax2.set_xlabel("netLength")
ax2.set_ylabel("违约率")
#显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
plt.show()
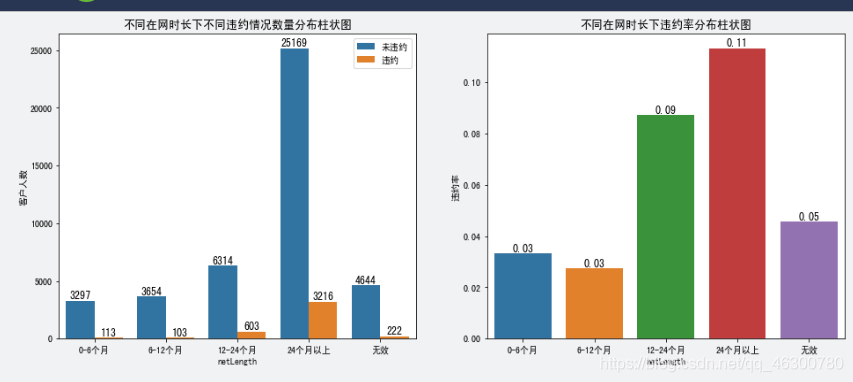
4.11
import seaborn as sns
import matplotlib.pyplot as plt
# 建立画布ax1和ax2,及设置图像大小,设置subplots()函数中参数为(1,2)表示两画图呈一行两列
fig, [ax1,ax2] = plt.subplots(1, 2, figsize=(16, 5))
# 在画布ax1中画出总消费金额的核密度图
sns.kdeplot(data["transTotalAmt"],shade=True,ax=ax1)
# 在画布ax2中画出总消费笔数和总消费金额的回归关系图
sns.regplot(x=data["transTotalCnt"],y=data["transTotalAmt"],data=data,ax=ax2)

笔记:
astype() 改变np.array中所有数据元素的数据类型。
hue分组 ax=ax1放在图1上
类表标签
无法画图的顺序和数组的顺序是否一样
count 分别为两组列表 count1 2 蓝色 橙色
inde-0.2 :会造成数据的重叠,+0.05 :往上抬一点 %: 保留多少小数 ,位置:水平居中 垂直:底部对齐
每一组sum值的和/count()个数 :比例
4.12
import seaborn as sns
import matplotlib.pyplot as plt
# 建立画布ax1和ax2,及设置图像大小,设置subplots()函数中参数为(1,2)表示一行两列
fig,[ax1,ax2] = plt.subplots(1,2,figsize=(16,6))
# 在画布ax1中绘制年龄的直方图,颜色为红色
sns.distplot(a=data["age"],color='r',kde=True,ax=ax1)
# 在画布ax2中绘制开卡时长的直方图,颜色为默认值
sns.distplot(a=data["card_age"],kde=True,ax=ax2)
# 在画布ax1、ax2中设置标题
ax1.set_title("年龄分布")
ax2.set_title("开卡时长分布")
# 显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
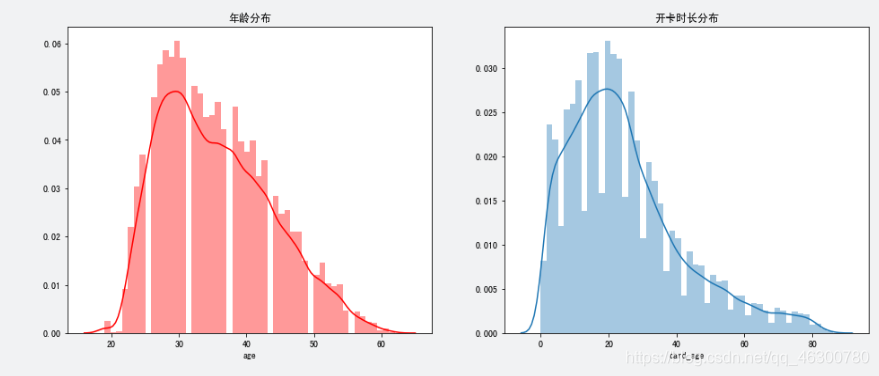
4.13
import seaborn as sns
import matplotlib.pyplot as plt
# 建立画布ax1和ax2,及设置图像大小,设置subplots()函数中参数为(1,2)表示两画图呈一行两列
fig, [ax1,ax2] = plt.subplots(1, 2, figsize=(16, 5))
# 在画布ax1中画出总取现金额的核密度图
sns.kdeplot(data["cashTotalAmt"],shade=True,ax=ax1)
# 在画布ax2中画出总取现笔数和总取现金额的回归关系图
sns.regplot(x=data["cashTotalCnt"],y=data["cashTotalAmt"],ax=ax2)
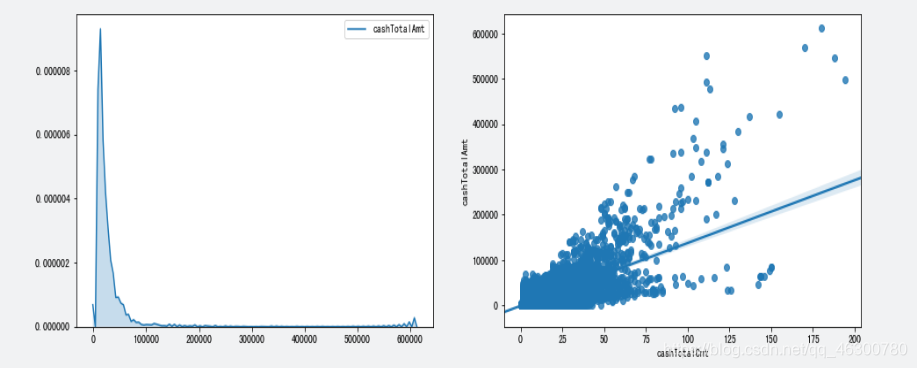
4.14
import seaborn as sns
import matplotlib.pyplot as plt
# 建立画布ax1和ax2,及设置图像大小,设置subplots()函数中参数为(1,2)表示两画图呈一行两列
fig, [ax1,ax2] = plt.subplots(1, 2, figsize=(16, 5))
# 在画布ax1中画出网上消费金额的核密度估计曲线
sns.kdeplot(data["onlineTransAmt"],shade=True,ax=ax1)
# 在画布ax2中画出网上消费笔数和网上消费金额的回归关系图
sns.regplot(x=data["onlineTransCnt"],y=data["onlineTransAmt"],ax=ax2)
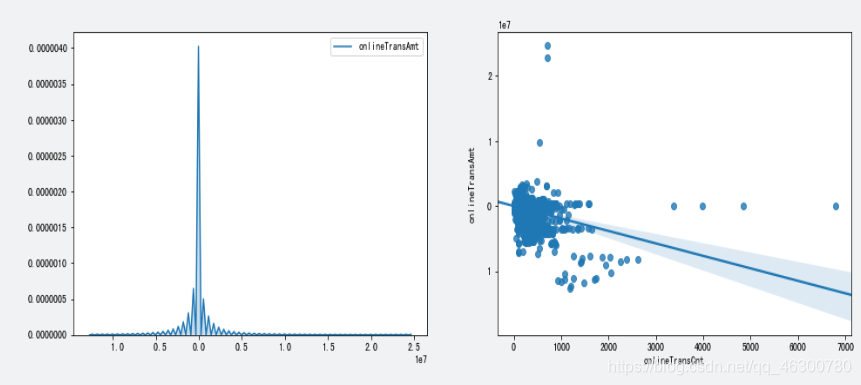
4.15
# 计算特征缺失值个数
na_counts = data.isnull().sum()
# 将na_counts取大于0的部分进行降序排序
missing_value = na_counts[na_counts > 0].sort_values(axis=0,ascending=False)
# 查看存在缺失值的特征
print(missing_value)
4.16
import pandas as pd
# 缺失值处理
data.dropna(subset=["Default"],inplace=True)
filling_columns = ['sex','maritalStatus','threeVerify','idVerify','education']
for column in filling_columns:
data[column].fillna('未知',inplace=True)
# 查看存在缺失值的特征
na_counts = data.isnull().sum()
missing_value = na_counts[na_counts > 0].sort_values(ascending = False)
print(missing_value)
4.17
import pandas as pd
#查看每个列分类情况
for i in data.columns:
print(data[i].value_counts())
# 异常值处理
data['isCrime'] = data['isCrime'].replace(2,0)
# 查看处理后的数据情况
print(data['isCrime'].value_counts())
4.18
# 所有连续型特征列名已保存在continuous_columns中
continuous_columns = ['age','cashTotalAmt','cashTotalCnt','monthCardLargeAmt','onlineTransAmt','onlineTransCnt','publicPayAmt','publicPayCnt','transTotalAmt','transTotalCnt','transCnt_non_null_months','transAmt_mean','transAmt_non_null_months','cashCnt_mean','cashCnt_non_null_months','cashAmt_mean','cashAmt_non_null_months','card_age']
# 查看数据各连续型特征的最小值
data_con_min = data[continuous_columns].min()
print(data_con_min)
4.19
# 从原始数据中筛选出网上消费金额小于0时,网上消费金额和网上消费笔数这两列
online_trans = data[data["onlineTransAmt"]<0][["onlineTransAmt","onlineTransCnt"]]
print(online_trans)
4.20
# 将网上消费笔数为0时的网上消费金额皆修改为0
data.loc[data['onlineTransCnt'] == 0,'onlineTransAmt'] = 0# 查看修正后网上消费笔数为0时,网上消费金额与网上消费笔数
online_after = data[data["onlineTransCnt"] == 0 ][["onlineTransAmt","onlineTransCnt"]]
print(online_after)
4.21
import seaborn as sns
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
# 绘制盒图查看网上消费金额数据分布
sns.boxplot(data["onlineTransAmt"],orient="v",ax=ax)
plt.title('onlineTransAmt distribution')
4.22
# 筛选出网上消费金额在2千万以下的数据样本,更新data
data =data[data["onlineTransAmt"]<2.0e+07]
print(data.head())
4.23
# 从原始数据中筛选出公共事业缴费金额小于0时,公共事业缴费笔数和公共事业缴费金额这两列
public_pay = data[data["publicPayAmt"]<0][["publicPayCnt","publicPayAmt"]]
print(public_pay)
4.24
# 将公共事业缴费笔数为0时的公共事业缴费金额皆修改为0(直接在原始数据上进行修改)
data.loc[data["publicPayCnt"]==0,"publicPayAmt"]=0
# 查看修正后的,公共事业缴费笔数为0时的公共事业缴费金额与公共事业缴费笔数
public_after = data[data["publicPayCnt"] == 0][["publicPayAmt","publicPayCnt"]]
print(public_after)
4.25
import seaborn as sns
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
# 绘制盒图查看公共事业缴费金额数据分布。
sns.boxplot(data["publicPayAmt"],orient="v",ax=ax)
plt.title('publicPayAmt distribution')
4.26
# 筛选出公共事业缴费金额小于-400万的样本数据
public_pay = data[data["publicPayAmt"]<-4.0e+06]
print(public_pay[['publicPayCnt','publicPayAmt']])
4.27
# 从原始数据中筛选出总消费笔数等于0时,总消费笔数,总消费金额这两列
transTotal =data[data["transTotalCnt"]==0][["transTotalCnt","transTotalAmt"]]
print(transTotal)
4.28
import seaborn as sns
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
# 绘制盒图,查看总消费金额数据分布。
sns.boxplot(data["transTotalAmt"],orient="v",ax=ax)
plt.title('transTotalAmt distribution')
4.29
# 筛选出总消费金额大于1000万的样本数据
transTotal = data[data["transTotalAmt"]>1.0e+07]
print(transTotal[['transTotalAmt','transTotalCnt','onlineTransAmt','onlineTransCnt','monthCardLargeAmt']])
4.30
# 筛选出总取现笔数为0时,总取现笔数,总取现金额这两列
cashTotal = data[data["cashTotalCnt"]==0][["cashTotalCnt","cashTotalAmt"]]
print(cashTotal)
4.31
import seaborn as sns
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
# 绘制盒图,查看总取现金额数据分布。
sns.boxplot(data["cashTotalAmt"],orient="v",ax=ax)
plt.title('cashTotalAmt distribution')
4.32
# 筛选出总取现金额大于50万的样本数据。
cashTotal = data[data["cashTotalAmt"]>5.0e+05]
print(cashTotal)
4.33
import seaborn as sns
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
# 绘制盒图,查看月最大消费金额数据分布
sns.boxplot(data["monthCardLargeAmt"],orient="v",ax=ax)
plt.title('monthCardLargeAmt distribution')
4.34
# 筛选出月最大消费金额大于200万的数据
monthCard = data[data["monthCardLargeAmt"]>2.0e+06]
print(monthCard)
4.35
import seaborn as sns
import matplotlib.pyplot as plt
fig,ax = plt.subplots(figsize=(8,6))
# 绘制盒图,查看总消费笔数数据分布
sns.boxplot(data["transTotalCnt"],orient="v",ax=ax)
plt.title('transTotalCnt distribution')
4.36
# 从data中筛选总消费笔数小于6000的值,赋值给data
data =data[data["transTotalCnt"]<6.0e+03]
print(data.head())
4.37
import numpy as np
import pandas as pd
data["maritalStatus"] = data["maritalStatus"].map({"未知":0,"未婚":1,"已婚":2})
data['education']=data['education'].map({"未知":0,"小学":1,"初中":2,"高中":3,"本科以上":4})
data['idVerify']=data['idVerify'].map({"未知":0,"一致":1,"不一致":2})
data['threeVerify']=data['threeVerify'].map({"未知":0,"一致":1,"不一致":2})
data["netLength"] = data["netLength"].map({"无效":0,"0-6个月":1,"6-12个月":2,"12-24个月":3,"24个月以上":4})
data["sex"] =data["sex"].map({"未知":0,"男":1,"女":2})
#data["CityId"] = data['CityId'].map({"一线城市":1,"二线城市":2,"其他":3})
data["CityId"] = data['CityId'].map({"一线城市":1,"二线城市":2,"其它":3})
print(data.head())
4.38
import numpy as np
import pandas as pd
data = pd.get_dummies(data=data,columns=['maritalStatus','education','idVerify','threeVerify','Han','netLength','sex','CityId'])
print(data.columns)
坑:通过loc 既要赋值又要筛选
5.2
# 计算客户年消费总额。
trans_total =data["transCnt_mean"]*data["transAmt_mean"]
# 将计算结果保留到小数点后六位。
trans_total =round(trans_total,6)
# 将结果加在data数据集中的最后一列,并将此列命名为trans_total。
data['trans_total'] =trans_total
print(data['trans_total'].head(20))
5.3
# 计算客户年取现总额。
total_withdraw =data["cashCnt_mean"]*data["cashAmt_mean"]
# 将计算结果保留到小数点后六位。
total_withdraw =round(total_withdraw ,6)
# 将结果加在data数据集的最后一列,并将此列命名为total_withdraw。
data['total_withdraw'] =total_withdraw
print(data['total_withdraw'].head(20))
5.4
import numpy as np
# 计算客户的平均每笔取现金额。
avg_per_withdraw =data["cashTotalAmt"]/data["cashTotalCnt"]
# 将所有的inf和NaN变为0。
where_are_nan = np.isnan(avg_per_withdraw)
where_are_inf = np.isinf(avg_per_withdraw)
avg_per_withdraw[where_are_nan] = 0
avg_per_withdraw[where_are_inf] = 0
# 将计算结果保留到小数点后六位。
avg_per_withdraw =round(avg_per_withdraw,6)
# 将结果加在data数据集的最后一列,并将此列命名为avg_per_withdraw。
data['avg_per_withdraw'] =avg_per_withdraw
print(data['avg_per_withdraw'].head(20))
5.5
import numpy as np
# 请计算客户的网上平均每笔消费额。
avg_per_online_spend =data["onlineTransAmt"]/data["onlineTransCnt"]
# 将所有的inf和NaN变为0。
where_are_nan = np.isnan(avg_per_online_spend)
where_are_inf = np.isinf(avg_per_online_spend)
avg_per_online_spend[where_are_nan] = 0
avg_per_online_spend[where_are_inf] = 0
# 将计算结果保留到小数点后六位。
avg_per_online_spend =round(avg_per_online_spend,6)
# 将结果加在data数据集的最后一列,并将此列命名为avg_per_online_spend。
data['avg_per_online_spend'] =avg_per_online_spend
print(data['avg_per_online_spend'].head(20))
5.6
import numpy as np
# 请计算客户的公共事业平均每笔缴费额。
avg_per_public_spend =data["publicPayAmt"]/data["publicPayCnt"]
# 将所有的inf和NaN变为0。
where_are_nan = np.isnan(avg_per_public_spend)
where_are_inf = np.isinf(avg_per_public_spend)
avg_per_public_spend[where_are_nan] = 0
avg_per_public_spend[where_are_inf] = 0
# 将计算结果保留到小数点后六位。
avg_per_public_spend =round(avg_per_public_spend,6)
# 将结果加在data数据集的最后一列,并将此列命名为avg_per_public_spend。
data['avg_per_public_spend'] =avg_per_public_spend
print(data['avg_per_public_spend'].head(20))
5.7
#请计算客户的不良记录分数。
bad_record =data["inCourt"]+data["isDue"]+data["isCrime"]+data["isBlackList"]
#将计算结果加在data数据集的最后一列,并将此列命名为bad_record。
data['bad_record'] =bad_record
print(data['bad_record'].head(20))
6.3
from sklearn.model_selection import train_test_split
# 筛选data中的Default列的值,赋予变量y
y = data['Default'].values
# 筛选除去Default列的其他列的值,赋予变量x
x = data.drop(['Default'], axis=1).values
# 使用train_test_split方法,将x,y划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=33,stratify=y)
# 查看划分后的x_train与x_test的长度
len_x_train = len(x_train)
len_x_test = len(x_test)
print('x_train length: %d, x_test length: %d'%(len_x_train,len_x_test))
# 查看分层采样后的训练集中违约客户人数的占比
train_ratio = y_train.sum()/len(y_train)
print(train_ratio)
# 查看分层采样后的测试集中违约客户人数的占比
test_ratio = y_test.sum()/len(y_test)
print(test_ratio)
6.4
from sklearn.linear_model import LogisticRegression
# 调用模型,新建模型对象
lr = LogisticRegression()
# 带入训练集x_train, y_train进行训练
lr.fit(x_train,y_train)
# 对训练好的lr模型调用predict方法,带入测试集x_test进行预测
y_predict = lr.predict(x_test)
# 查看模型预测结果
print(y_predict[:10])
print(len(y_predict))
6.5
from sklearn.metrics import roc_auc_score
y_predict_proba = lr.predict_proba(x_test)
# 查看概率估计前十行
print(y_predict_proba[:10])
# 取目标分数为正类(1)的概率估计
y_predict = y_predict_proba[:,1]
# 利用roc_auc_score查看模型效果
test_auc =roc_auc_score(y_test,y_predict)
print('逻辑回归模型 test_auc:',test_auc)
6.6
from sklearn.metrics import roc_auc_score
from sklearn.linear_model import LogisticRegression
# 建立一个LogisticRegression对象,命名为lr
lr =LogisticRegression(penalty='l1',C=0.6,class_weight='balanced')
# 对lr对象调用fit方法,带入训练集x_train, y_train进行训练
lr.fit(x_train,y_train)
# 对训练好的lr模型调用predict_proba方法
y_predict = lr.predict_proba(x_test)[:,1]
# 调用roc_auc_score方法
test_auc = roc_auc_score(y_test,y_predict)
print('逻辑回归模型test auc:')
print(test_auc)
6.7
continuous_columns = ['age','cashTotalAmt','cashTotalCnt','monthCardLargeAmt','onlineTransAmt','onlineTransCnt','publicPayAmt','publicPayCnt','transTotalAmt','transTotalCnt','transCnt_non_null_months','transAmt_mean','transAmt_non_null_months','cashCnt_mean','cashCnt_non_null_months','cashAmt_mean','cashAmt_non_null_months','card_age', 'trans_total','total_withdraw', 'avg_per_withdraw','avg_per_online_spend', 'avg_per_public_spend', 'bad_record','transCnt_mean','noTransWeekPre']
# 对data中所有连续型的列进行Z-score标准化
data[continuous_columns]=data[continuous_columns].apply(lambda x:(x-x.mean())/x.std())
# 查看标准化后的数据的均值和标准差,以cashAmt_mean为例
print('cashAmt_mean标准化后的均值:',data['cashAmt_mean'].mean())
print('cashAmt_mean标准化后的标准差:',data['cashAmt_mean'].std())
# 查看标准化后对模型的效果提升
y = data['Default'].values
x = data.drop(['Default'], axis=1).values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state = 33,stratify=y)
from sklearn.metrics import roc_auc_score
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression(penalty='l1',C=0.6,class_weight='balanced')
lr.fit(x_train, y_train)
# 查看模型预测结果
y_predict = lr.predict_proba(x_test)[:,1]
auc_score =roc_auc_score(y_test,y_predict)
print('score:',auc_score)
6.8
continuous_columns = ['age','cashTotalAmt','cashTotalCnt','monthCardLargeAmt','onlineTransAmt','onlineTransCnt','publicPayAmt','publicPayCnt','transTotalAmt','transTotalCnt','transCnt_non_null_months','transAmt_mean','transAmt_non_null_months','cashCnt_mean','cashCnt_non_null_months','cashAmt_mean','cashAmt_non_null_months','card_age', 'trans_total','total_withdraw', 'avg_per_withdraw','avg_per_online_spend', 'avg_per_public_spend', 'bad_record','transCnt_mean','noTransWeekPre']
# 对data中数值连续型的列进行等频离散化,将每一列都离散为5个组。
data[continuous_columns] = data[continuous_columns].apply(lambda x :pd.qcut(x,5,duplicates='drop'))
# 查看离散化后的数据
print(data.head())
# 查看离散化后对模型的效果提升
# 先对各离散组进行One-Hot处理
data=pd.get_dummies(data)
y = data['Default'].values
x = data.drop(['Default'], axis=1).values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,random_state = 33,stratify=y)
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
lr = LogisticRegression(penalty='l1',C=0.6,class_weight='balanced')
lr.fit(x_train, y_train)
# 查看模型预测结果
y_predict = lr.predict_proba(x_test)[:,1]
score_auc = roc_auc_score(y_test,y_predict)
print('score:',score_auc)
6.9
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
rf_clf = RandomForestClassifier ()
rf_clf.fit(x_train,y_train)
y_predict = rf_clf.predict_proba(x_test)[:,1]
# 查看模型效果
test_auc = roc_auc_score(y_test,y_predict)
print ("AUC Score (Test): %f" % test_auc)
6.10
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
# 尝试设置参数n_estimators
rf_clf1 = RandomForestClassifier(n_estimators=100)
rf_clf1.fit(x_train, y_train)
y_predict1 = rf_clf1.predict_proba(x_test)[:,1]
# 查看模型效果
test_auc = roc_auc_score(y_test,y_predict1)
print ("AUC Score (Test): %f" % test_auc)
6.11
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
# 定义存储AUC分数的数组
scores_train=[]
scores_test=[]
# 定义存储n_estimators取值的数组
estimators=[]
# 设置n_estimators在100-210中每隔20取一个数值
for i in range(100,210,20):
estimators.append(i)
rf = RandomForestClassifier(n_estimators=i, random_state=12)
rf.fit(x_train,y_train)
y_predict = rf.predict_proba(x_test)[:,1]
scores_test.append(roc_auc_score(y_test,y_predict))
# 查看我们使用的n_estimators取值
print("estimators =", estimators)
# 查看以上模型中在测试集最好的评分
print("best_scores_test =",max(scores_test))
# 画出n_estimators与AUC的图形
fig,ax = plt.subplots()
# 设置x y坐标名称
ax.set_xlabel('estimators')
ax.set_ylabel('AUC分数')
plt.plot(estimators,scores_test, label='测试集')
#显示汉语标注
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']=['sans-serif']
# 设置图例
plt.legend(loc="lower right")
plt.show()
6.12
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
rf = RandomForestClassifier()
# 设置需要调试的参数
tuned_parameters = {
'n_estimators':[180,190],
'criterion':['entropy','gini'],
'min_samples_split':[2,3],
'max_depth':[8,10]
}
# 调用网格搜索函数
rf_clf = GridSearchCV(rf,tuned_parameters,cv=5,n_jobs=12,scoring='roc_auc')
rf_clf.fit(x_train, y_train)
y_predict = rf_clf.predict_proba(x_test)[:,1]
test_auc = roc_auc_score(y_test,y_predict)
print ('随机森林模型test AUC:')
print (test_auc)
7.2
#用metrics.roc_curve()求出 fpr, tpr, threshold
fpr, tpr, threshold = metrics.roc_curve(y_test,y_predict_best)
#用metrics.auc求出roc_auc的值
roc_auc = metrics.auc(fpr,tpr)
#将图片大小设为8:6
fig,ax = plt.subplots(figsize=(8,6))
#将plt.plot里的内容填写完整
plt.plot(fpr,tpr, label = 'AUC = %0.2f' % roc_auc)
#将图例显示在右下方
plt.legend(loc = 'lower right')
#画出一条红色对角虚线
plt.plot([0, 1], [0, 1],'r--')
#设置横纵坐标轴范围
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.01])
#设置横纵名称以及图形名称
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.title('Receiver Operating Characteristic Curve')
plt.show()
7.3
#用metrics.roc_curve()求出 fpr, tpr, threshold
fpr, tpr, threshold =metrics.roc_curve(y_test,y_predict_best)
#用metrics.auc求出roc_auc的值
roc_auc = metrics.auc(fpr,tpr)
#将图片大小设为8:6
fig,ax = plt.subplots(figsize=(8,6))
#将plt.plot里的内容填写完整
plt.plot(fpr, tpr, label = 'AUC = %0.2f' % roc_auc)
#将图例显示在右下方
plt.legend(loc = 'lower right')
#画出一条红色对角虚线
plt.plot([0, 1], [0, 1],'r--')
#设置横纵坐标轴范围
plt.xlim([-0.01, 1.01])
plt.ylim([-0.01, 1.01])
#设置横纵名称以及图形名称
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.title('Receiver Operating Characteristic Curve')
plt.show()
7.4
#用metric.roc_curve()求出 fpr, tpr, threshold
fpr, tpr, threshold = metrics.roc_curve(y_test, y_predict_best)
#求出KS值和相应的阈值
ks = max(abs(tpr-fpr))
thre = threshold[abs(tpr-fpr).argmax()]
ks = round(ks*100, 2)
thre = round(thre, 2)
print('KS值:', ks, '%', '阈值:', thre)
#将图片大小设为8:6
fig = plt.figure(figsize=(8,6))
#将plt.plot里的内容填写完整
plt.plot(threshold[::-1],tpr[::-1], lw=1, alpha=1,label='真正率TPR')
plt.plot(threshold[::-1], fpr[::-1], lw=1, alpha=1,label='假正率FPR')
#画出KS值的直线
ks_tpr = tpr[abs(tpr-fpr).argmax()]
ks_fpr = fpr[abs(tpr-fpr).argmax()]
x1 = [thre, thre]
x2 = [ks_fpr, ks_tpr]
plt.plot(x1, x2)
#设置横纵名称以及图例
plt.xlabel('阈值')
plt.ylabel('真正率TPR/假正率FPR')
plt.title('KS曲线', fontsize=15)
plt.legend(loc="upper right")
plt.grid(axis='x')
# 在图上标注ks值
plt.annotate('KS值', xy=(0.18, 0.45), xytext=(0.25, 0.43),
fontsize=20,arrowprops=dict(facecolor='green', shrink=0.01))
7.5
#用metric.roc_curve()求出 fpr, tpr, threshold
fpr, tpr, threshold = metrics.roc_curve(y_test, y_predict_best)
#求出KS值和相应的阈值
ks =max(abs(tpr-fpr))
thre = threshold[abs(tpr-fpr).argmax()]
ks = round(ks*100, 2)
thre = round(thre, 2)
print('KS值:', ks, '%', '阈值:', thre)
#将图片大小设为8:6
fig = plt.figure(figsize=(8,6))
#将plt.plot里的内容填写完整
plt.plot(threshold[::-1], tpr[::-1], lw=1, alpha=1,label='真正率TPR')
plt.plot(threshold[::-1], fpr[::-1], lw=1, alpha=1,label='假正率FPR')
#画出KS值的直线
ks_tpr = tpr[abs(tpr-fpr).argmax()]
ks_fpr = fpr[abs(tpr-fpr).argmax()]
x1 = [thre, thre]
x2 = [ks_fpr, ks_tpr]
plt.plot(x1, x2)
7.6
## 训练集预测概率
y_train_probs = lr.predict_proba(x_train)[:,1]
## 测试集预测概率
y_test_probs = lr.predict_proba(x_test)[:,1]
def psi(y_train_probs, y_test_probs):
## 设定每组的分点
bins = np.arange(0, 1.1, 0.1)
## 将训练集预测概率分组
y_train_probs_cut = pd.cut(y_train_probs, bins=bins, labels=False)
## 计算预期占比
expect_prop = (pd.Series(y_train_probs_cut).value_counts()/len(y_train_probs)).sort_index()
## 将测试集预测概率分组
y_test_probs_cut = pd.cut(y_test_probs, bins=bins, labels=False)
## 计算实际占比
actual_prop = (pd.Series(y_test_probs_cut).value_counts()/len(y_test_probs)).sort_index()
## 计算PSI
psi = ((actual_prop - expect_prop)*np.log(actual_prop/expect_prop)).sum()
return psi, expect_prop, actual_prop
## 运行函数得到psi、预期占比和实际占比
psi, expect_prop, actual_prop = psi(y_train_probs, y_test_probs)
print('psi=',psi)
## 创建(12, 8)的绘图框
fig = plt.figure(figsize=(12, 8))
## 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
## 绘制条形图
plt.bar(expect_prop.index + 0.2, expect_prop, width=0.4, label='预期占比')
plt.bar(actual_prop.index - 0.2, actual_prop, width=0.4, label='实际占比')
plt.legend()
## 设置轴标签
plt.xlabel('概率分组', fontsize=12)
plt.ylabel('样本占比', fontsize=12)
## 设置轴刻度
plt.xticks([0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
['0-0.1', '0.1-0.2', '0.2-0.3', '0.3-0.4', '0.4-0.5', '0.5-0.6', '0.6-0.7', '0.7-0.8', '0.8-0.9', '0.9-1'])
## 设置图标题
plt.title('预期占比与实际占比对比条形图', fontsize=15)
## 在图上添加文字
for index, item1, item2 in zip(range(10), expect_prop.values, actual_prop.values):
plt.text(index+0.2, item1 + 0.01, '%.3f' % item1, ha="center", va= "bottom",fontsize=10)
plt.text(index-0.2, item2 + 0.01, '%.3f' % item2, ha="center", va= "bottom",fontsize=10)
7.7
## 训练集预测概率
y_train_probs = rf.predict_proba(x_train)[:,1]
## 测试集预测概率
y_test_probs = rf.predict_proba(x_test)[:,1]
def psi(y_train_probs, y_test_probs):
## 设定每组的分点
bins = np.arange(0, 1.1, 0.1)
## 将训练集预测概率分组
y_train_probs_cut = pd.cut(y_train_probs, bins=bins, labels=False)
## 计算预期占比
expect_prop = (pd.Series(y_train_probs_cut).value_counts()/len(y_train_probs)).sort_index()
## 将测试集预测概率分组
y_test_probs_cut = pd.cut(y_test_probs, bins=bins, labels=False)
## 计算实际占比
actual_prop = (pd.Series(y_test_probs_cut).value_counts()/len(y_test_probs)).sort_index()
## 计算PSI
psi = ((actual_prop-expect_prop)*np.log(actual_prop/expect_prop)).sum()
return psi, expect_prop, actual_prop
## 运行函数得到psi、预期占比和实际占比
psi, expect_prop, actual_prop = psi(y_train_probs,y_test_probs)
print('psi=', round(psi, 3))
## 创建(12, 8)的绘图框
fig = plt.figure(figsize=(12, 8))
## 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
## 绘制条形图
plt.bar(expect_prop.index + 0.2, expect_prop, width=0.4, label='预期占比')
plt.bar(actual_prop.index - 0.2, actual_prop, width=0.4, label='实际占比')
plt.legend()
## 设置轴标签
plt.xlabel('概率分组', fontsize=12)
plt.ylabel('样本占比', fontsize=12)
## 设置轴刻度
plt.xticks([0, 1, 2, 3, 4, 5, 6, 7, 8, 9],
['0-0.1', '0.1-0.2', '0.2-0.3', '0.3-0.4', '0.4-0.5', '0.5-0.6', '0.6-0.7', '0.7-0.8', '0.8-0.9', '0.9-1'])
## 设置图标题
plt.title('预期占比与实际占比对比条形图', fontsize=15)
## 在图上添加文字
for index, item1, item2 in zip(range(10), expect_prop.values, actual_prop.values):
plt.text(index+0.2, item1 + 0.01, '%.3f' % item1, ha="center", va= "bottom",fontsize=10)
plt.text(index-0.2, item2 + 0.01, '%.3f' % item2, ha="center", va= "bottom",fontsize=10)
7.8
from sklearn.linear_model import LogisticRegression
lr_clf = LogisticRegression(penalty='l1',C = 0.6, random_state=55)
lr_clf.fit(x_train, y_train)
# 查看逻辑回归各项指标系数
coefficient = lr_clf.coef_
# 取出指标系数,并对其求绝对值
importance = abs(coefficient)
# 通过图形的方式直观展现前八名的重要指标
index=data.drop('Default', axis=1).columns
feature_importance = pd.DataFrame(importance.T, index=index).sort_values(by=0, ascending=True)
# # 查看指标重要度
print(feature_importance)
# 水平条形图绘制
feature_importance.tail(8).plot(kind='barh', title='Feature Importances', figsize=(8, 6), legend=False)
plt.show()
7.9
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators = 150, criterion = 'entropy', max_depth = 5, min_samples_split = 2, random_state=12)
rf.fit(x_train, y_train)
# 查看随机森林各项指标系数
importance = rf.feature_importances_
# 通过图形的方式直观展现前八名的重要指标
index=data.drop('Default', axis=1).columns
feature_importance = pd.DataFrame(importance.T, index=index).sort_values(by=0, ascending=True)
# # 查看指标重要度
print(feature_importance)
# 水平条形图绘制
feature_importance.tail(8).plot(kind='barh', title='Feature Importances', figsize=(8, 6), legend=False)
plt.show()
1.离散型字段:CityId、education、idVerify、inCourt、maritialStatus、netLength、threeVerify、isDue、isCrime、isBlackList、Han、sex
连续型字段:cashTotalAmt、cashTotalCnt、monthCardLareAmt、noTransWeekPe、onlineTransAmt、onlineTransCnt、publicPayAmt、publicPayCnt、transTotalAmt、transTotalCnt、transCnt_mean、transCnt_non_null_months、cashAmt_mean、cashAmt_non_null_months、age、card_age
2.
会产生影响。本项目数据中未违约客户多与违约客户,类别样本比例不均衡,从而会导致比例大的样本也就是过拟合,会大大降低模型的泛化能力、使得准确率过高,从而影响风控模型的构建,所在进行模型构建之前我们应该观察其比例是否均衡。
3.
由绘制的图形可以看到,
城市级别(Cityld)与是否违约(Default)间的关系:二线城市的违约人数和违约率较一线城市和其他城市要高;
文化程度(education)与是否违约(Default)间的关系:文化程度为“小学”的违约人数最多,“本科以上"的违约人数最少;:化程度为“初中”的违约率最低,“本科以上"违约率相对较高;
三要素验证(threeVerify)与是否违约(Default)间的关系:数据中三要素一致的客户相对较多,三要素不一致的客户违约率相对三要素一致的客户违约率高一些;
婚姻状况(maritalStatus)与是否违约(Default)的关系:数据中未婚客户相对已婚客户的违约率低一些。
不同在网时长与是否违约(Default)的关系:数据中在网时长在24个月以上时,贷款人数最多,同时违约占比也相对较高。
4.
从直方图中可以看到,年龄和开卡时长的分布都属于偏态分布。客户年龄主要分布在25-45岁之间,客户开卡时长主要分布在0-30小时之间。
5.
可知上述的6个字段中分别存在缺失值的问题,进行了缺失值、异常值处理,Default的缺失率小可直接删除就行,对sex 、 maritalStatus 、 threeVerify 、 idVerify和 education字段,缺失数据有些大,直接删除对数据有很大的影响,所以需要进行缺失值填补。可以将缺失值定义为,未知。因此以婚姻状况为例,取值存在三种情况:未婚、已婚、未知。
6.
对于上述连续型特种中的异常值,网上消费金额,先对其进行检测,会出现网上消费笔数为0但消费金额为负数的情况,因此我们需要进一步处理,将消费笔数为0的消费金额修正为0;
通过绘制的盒图,检测到了网上消费金额中有部分值特别大,大于2.0e+07,远高于其他客户消费金额,同时网上消费笔数达到713和714笔,远高于其它客户消费笔数。,由此推断这两个可能是某机构客户,且由于和其它个人客户数据差别较大,我们选择将其删除;以及其他公式事业金额为负值的我们都将他修正为0,但是对于某些变量的某些值我们还是应该综合考虑进行保存的。
7.
网上消费笔数为0但消费金额为负数,不符合逻辑,需要将其修正为0.
8.
公共事业缴费笔数为0,但是部分公共事业缴费金额却为-0.000364、-0.000241等负数,是不符合逻辑的情况,所以应该将这些公共事业缴费金额均修正为0。
9.
1.分层:对预测特征Default的取值分布进行了分析,采用分层采样的划分,保证从违约客户和未违约客户中抽取了同样比例的训练集和测试集;
2.随机划分:设计random_state:随机种子,因为划分过程是随机的,为了进行可重复的训练,需要固定一个random state ,结果重现。
3.合并:最后我们将训练集带入算法中进行模型训练。
10.
可从上图的ROC曲线发现,当正负样本的分布发生变化时,其形状能够基本保持不变,因此其面积AUC值,可以说是极度适用于不平衡样本的建模评估了。AUC越大,模型分类效果越好。
11.
随机森林模型。通过ROC_AUC评估模型准确性、KS评估模型准确性、PIS评估稳定性这几种性能指标的评估,发现随机森林的模型更适合作为风控项目的最终模型。
12.
项目目的:解决了什么样的实际问题?
解决了银行通过分析客户的个人基本信息、消费与偿还能力等指标,利用有监督学习等方法建立个人信用风险评估模型,预测申请贷款的客户是否有违约风险,提供有效信息给决策者,帮助其决定是否向贷款申请人放贷,从而在减少运营成本的前提下,降低坏账风险,对银行预测扩展个人信贷业务有着影响。
项目流程:项目的总体执行流程是怎样的?
数据探索与分析–>建立信用指标体系–>构建客户风险评估模型–>模型预测及分析
数据处理方法:对项目数据进行了怎样的处理?
数据探索和分析、查看数据的基本情况、数据的特征分析、特征变量的特征分布、对连续值、离散值进行数据分析,之后查看缺失值、异常值并对其进行处理,通过盒图绘制对数据进行分析,数字编码等等。
风控模型构建方法:使用哪些方法构建风控模型?
随机森林、逻辑回归
效果分析:使用哪些方法对风控模型的效果进行了分析和评估?
ROC_AUC评估模型准确性、KS评估模型准确性、PIS评估模型稳定性
初步结论:通过本项目,得到了哪些初步的结论?
通过随机森林、逻辑回归两个模型的综合考虑,对客户信用评估影响最大的因素分别是:年无消费周数占比、年消费金额均值、年取现金额均值、网上消费笔数、网上消费金额、总消费金额等。在指标体系中多与客户的"消费能力"与"偿债能力"有关。
通过本实训项目,你的成绩如何?在项目过程中遇到了哪些问题?
解锁通关并完成了所有的练习;遇到了一些知识点的模糊记忆以及该练习有什么作用等等,但通过实训的练习都逐步解决了。
你是如何解决这些问题的?经过本次综合实训,你的最大收获是什么?
通过这次实验让我对如何对模型预测与分析的过程有了更深的了解,解决了以前学习过程中模糊的过程思路和概念理解,通过这一例的银行的实训,了解到了该模型可以在实际应用中是如何进行评估预测、评估等等;不仅是这个案例,还有其他实际应用等等,也让我对模型预测分析有了整理思路,更感兴趣了。

















 1114
1114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









