







本文内容整理自西安交通大学软件学院田丽华老师的课件,仅供学习使用,请勿转载
操作系统系列笔记汇总:操作系统笔记及思维导图汇总附复习建议_Qlz的博客-CSDN博客
文章目录
文章目录
思维导图
Basic Concepts
OS三级调度
- 高级(Long-term)调度——作业调度
- 决定把外存输入井上处于作业后备队列上的哪些作业调入内存,并为它们创建进程、分配必要的资源,然后再将新创建的进程排在就绪队列上,准备执行。
- 外存->等待队列
- 低级(Short-term)调度——进程调度
- 决定就绪队列中哪个进程将获得处理机,然后由分派程序执行把处理机分配给该进程的操作。
- CPU下一个执行哪个进程
- 中级(Medium-term)调度——对换
- 从内存中将处于阻塞状态的进程切换到外存的交换区,呆其阻塞状态结束重新进入等待队列

- 通过多道程序设计得到CPU的最高利用率
- CPU–I/O Burst Cycle – Process execution consists of a cycle of CPU execution and I/O wait.
CPU-I/O脉冲周期 - 进程的执行包括进程在CPU上执行和等待I/O - 进程的执行以CPU脉冲开始,其后跟着I/O脉冲.进程的执行就是在这两个状态之间进行转换.
- CPU burst distribution
CPU脉冲的分布,- 在系统中,存在许多短CPU脉冲,只有少量的长CPU脉冲
- 比如:I/O型作业具有许多短CPU脉冲,而CPU型作业则会有几个长CPU脉冲,这个分布规律对CPU调度算法的选择是非常重要的.
CPU Scheduler
-
当CPU空闲时,OS就选择内存中的某个就绪进程,并给其分配CPU

CPU调度可能发生在以下情况下
- Switches from running to waiting state(从运行转到等待).
- Switches from running to ready state(从运行转到就绪).
- Switches from waiting to ready(从等待转到就绪).
- Terminates(终止运行).
- Scheduling under 1 and 4 is nonpreemptive (发生在1、4两种情况下的调度称为非抢占式调度).
- All other scheduling is preemptive (其他情况下发生的调度称为抢占式调度).
CPU Scheduling Scheme
- 非抢占方式(nonpreemptive)
- 把处理机分配给某进程后,便让其一直执行,直到该进程完成或发生某事件而被阻塞时,才把处理机分配给其它进程,不允许其他进程抢占已经分配出去的处理机。
- 优点:实现简单、系统开销小,适用于大多数批处理系统环境
- 缺点:难以满足紧急任务的要求,不适用于实时、分时系统要求
- 抢占方式(Preemptive mode)
- 允许调度程序根据某个原则,去停止某个正在执行的进程,将处理机重新分配给另一个进程。
- 抢占的原则
- 时间片原则:各进程按时间片运行,当一个时间片用完后,便仃止该进程的执行而重新进行调度。这个原则适用于分时系统。
- 优先权原则:通常对一些重要的和紧急的进程赋予较高的优先权。当这种进程进入就绪队列时,如果其优先权比正在执行的进程优先权高,便仃止正在执行的进程,将处理机分配给优先权高的进程,使之执行
- 短作业优先原则:当新到达的作业比正在执行的作业明显短时,将暂停当前长作业的执行,将处理机分配给新到的短作业,使之执行。
Dispatcher
- 分派程序负责将对CPU的控制权转交给短调度选择的进程,包括
- switching context(切换上下文)
- switching to user mode(切换到用户态)
- jumping to the proper location in the user program to restart that program(跳转到用户程序的适当位置并重新运行之)
- Dispatch latency – time it takes for the dispatcher to stop one process and start another running(分派延迟 – 分派程序终止一个进程的运行并启动另一个进程运行所花的时间)
Scheduling Criteria(调度准则)
- CPU utilization – keep the CPU as busy as possible(CPU利用率 – 使CPU尽可能的忙碌)
- Throughput – the number of processes that complete their execution per time unit(吞吐量 – 单位时间内运行完的进程数)
- Turnaround time – the interval from submission to completion (周转时间 – 进程从提交到运行结束的全部时间 )
- Waiting time – amount of time a process has been waiting in the ready queue(等待时间 – 进程在就绪队列中等待调度的时间片总和 )
- Response time – amount of time it takes from when a request was submitted until the first response is produced, not output (for time-sharing environment)(响应时间 – 从进程提出请求到首次被响应的时间段[在分时系统环境下不是输出完结果的时间] )
调度算法影响的是等待时间,而不能影响进程真正使用CPU的时间和I/O时间
Scheduling Algorithms
FCFS Scheduling
- 先来先服务First-Come-First-Served:
- 最简单的调度算法
- 可用于作业或进程调度
- 算法的原则是按照作业到达后备作业队列(或进程进入就绪队列)的先后次序来选择作业(或进程)
- FCFS算法属于非抢占方式:一旦一个进程占有处理机,它就一直运行下去,直到该进程完成或者因等待某事件而不能继续运行时才释放处理机。
- FCFS算法易于实现,表面上很公平,实际上有利于长作业,不利于短作业;有利于CPU繁忙型,不利于I/O繁忙型。

SJF Scheduling
- Associate with each process the length of its next CPU burst. Use these lengths to schedule the process with the shortest time.(关联到每个进程下次运行的CPU脉冲长度,调度最短的进程)
- Two schemes
- nonpreemptive – once CPU given to the process it cannot be preempted until completes its CPU burst(非抢占式调度 – 一旦进程拥有CPU,它的使用权限只能在该CPU 脉冲结束后让出).
- Preemptive – if a new process arrives with CPU burst length less than remaining time of current executing process, preempt. This scheme is know as the Shortest-Remaining-Time-First (SRTF).(抢占式调度 – 发生在有比当前进程剩余时间片更短的进程到达时,也称为最短剩余时间优先调度)
- SJF is optimal – gives minimum average waiting time for a given set of processes.(SJF是最优的 – 对一组指定的进程而言,它给出了最短的平均等待时间)

- 采用SJF有利于系统减少平均周转时间,提高系统吞吐量。
- 一般情况下SJF调度算法比FCFS调度算法的效率要高一些, 但实现相对要困难些。
- 如果作业的到来顺序及运行时间不合适,会出现饥饿现象
Priority Scheduling
- A priority number (integer) is associated with each process(每个进程都有自己的优先数[整数])
- The CPU is allocated to the process with the highest priority (smallest integer = highest priority)(CPU分配给最高优先级的进程,假定最小的整数对应最高的优先级).
- Preemptive(抢占式)
- Nonpreemptive (非抢占式)
- SJF is a priority scheduling where priority is the predicted next CPU burst time(SJF是以下一次CPU脉冲长度为优先数的优先级调度).
确定优先级
- 静态优先权在进程创建时确定,且在整个生命期中保持不变。
- 进程类型,通常系统进程的优先权高于一般用户进程的优先权。在用户进程中,I/O繁忙的进程应优先于CPU繁忙的进程,以保证CPU和I/O设备之间的并行操作。
- 进程对资源的需求,如进程执行时间及内存需要少的进程应赋予较高的优先权;
- 根据用户要求,由用户的紧迫程度及用户所付费用的多少来确定进程的优先权。
- 在分时系统中,前台进程应优先于后台进程
- 问题:
- 饥饿 – 低优先级的可能永远得不到运行
- 解决
- 老化 – 视进程等待时间的延长提高其优先数
- 动态优先权是指进程的优先权可以随进程的推进而改变,以便获得更好的调度性能
- 改变优先权的因素
- 进程的等待时间
- 已使用处理机的时间
- 资源使用情况
- 改变优先权的因素
Round Robin (RR)
每个进程将得到小单位的CPU时间[时间片],通常为10-100毫 秒。时间片用完后,该进程将被抢占并插入就绪队列末尾

- If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in chunks of at most q time units at once. No process waits more than (n-1)q time units 假定就绪队列中有n个进程、时间量为q, 则每个进程每次得到1/n的CPU时间、长度不超过q单位的成块CPU时间,没有任何一个进程的等待时间会超过(n-1) q单位
Multilevel Queue
- 按进程的属性来分类,如进程的类型、优先权、占用内存的多少,每类进程组成一个就绪队列,每个进程固定地处于某一个队列,如
- Ready queue is partitioned into separate queues(就绪队列分为):
- foreground (interactive)(前台)[交互式]
- background (batch) (后台) [批处理]
- Each queue has its own scheduling algorithm每个队列有自己的调度算法)
- foreground – RR
- background – FCFS
- Scheduling must be done between the queues(调度须在队列间进行).
- Ready queue is partitioned into separate queues(就绪队列分为):
- Fixed priority scheduling; i.e., serve all from foreground then from background. Possibility of starvation(固定优先级调度,即前台运行完后再运行后台。有可能产生饥饿).
- Time slice – each queue gets a certain amount of CPU time which it can schedule amongst its processes; e.g.,80% to foreground in RR 20% to background in FCFS (给定时间片调度,即每个队列得到一定的CPU时间,进程在给定时间内执行;如,80%的时间执行前台的RR调度,20%的时间执行后台的FCFS调度)
Multilevel Queue Scheduling
-
存在多个就绪队列,具有不同的优先级,各自按时间片轮转法调度
-
允许进程在队列之间移动
-
各个就绪队列中时间片的大小各不相同,优先级越高的队列时间片越小。
-
当一个进程执行完一个完整的时间片后被抢占处理器,被抢占的进程优先级降低一级而进入下级就绪队列,如此继续,直至降到进程的基本优先级。而一个进
程从阻塞态变为就绪态时要提高优先级
-
最后会将I/O型和交互式进程留在较高优先级队列


Multilevel Feedback Queue
- 进程能在不同的队列间移动;可实现老化
- 多级反馈队列调度程序由以下参数定义
- number of queues(队列数)
- scheduling algorithms for each queue(每一队列的调度算法)
- method used to determine when to upgrade a process(决定进程升级的方法)
- method used to determine when to demote a process(决定进程降级的方法)
- method used to determine which queue a process will enter when that process needs service(决定需要服务的进程将进入哪个队列的方法)

Example
- Three queues:
- Q0 – time quantum 8 milliseconds
- Q1 – time quantum 16 milliseconds
- Q2 – FCFS
- Scheduling
- A new job enters queue Q0 which is served FCFS. When it gains CPU, job receives 8 milliseconds. If it does not finish in 8 milliseconds, job is moved to queue Q1(新的作业进入FCFS的Q0队列,它得到CPU时能使用8毫秒,如果它不能在8毫秒内完成,将移动到队列Q1 ) .
- At Q1 job is again served FCFS and receives 16 additional milliseconds. If it still does not complete, it is preempted and moved to queue Q2(作业在Q1仍将作为FCFS调度,能使用附加的16毫秒,如果它还不能完成,将被抢占,移至队列Q2 ) .
Highest Response Ratio Next (HRRN)
高响应比优先 (作业)调度算法
-
SJF中长作业运行得不到保证,引入动态优先权
-
高响应比优先调度算法—基于优先权算法
- 在每次选择作业投入运行时,先计算后备作业队列中每个作业的响应比RP,然后选择其值最大的作业投入运行。
-
RP值定义为:
RP=(已等待时间+要求运行时间)/要求运行时间=1+已等待时间/要求运行时间 -
HRRN算法实际上是FCFS算法和SJF算法的折衷
-
优点:
- 等待时间相同,则SJF;
- 要求的服务时间相同,则FCFS;
- 长作业的优先级随着等待时间的增加而提高,不会出现得不到响应的情况。
-
缺点:
- 作业调度程序要统计作业的等待时间,作浮点运算(这是系统程序最忌讳的)浪费大量的计算时间。
Example




Multiple-Processor Scheduling
-
多个CPU可用时,CPU调度将更为复杂
-
Homogeneous processors within a multiprocessor
多处理器内的同类处理器
-
Load sharing (负载共享)—设置一个公共的就绪队列
-
Symmetric Multiprocessing (SMP) – each processor makes its own scheduling decisions
对称多处理器 – 每个处理器决定自己的调度方案。每个CPU自己到公共就绪队列去取进程来执行。这需保证多个CPU对公共就绪队列的互斥访问
-
Asymmetric multiprocessing – only one processor accesses the system data structures, alleviating the need for data sharing.
非对称多处理器 – 仅一个处理器能处理系统数据结构,这就减轻了对数据的共享需求
进程CPU间迁移
- 当进程从一个CPU迁移到另外一个CPU时,其CACHE的内容也必须随之更新–代价很高
- 多数SMP系统不支持进程在不同CPU间迁移,而是试图使进程一直在同一个CPU上运行-- Processor affinity
- Processor affinity – process has affinity for processor on which it is currently running
- soft affinity:试图使进程一直在同一个CPU上运行,但不保证
- hard affinity:不允许进程在不同CPU间迁移
Real-Time Scheduling
-
实时调度是为了完成实时处理任务而分配计算机处理器的调度方法。
-
实时处理任务要求计算机在用户允许的时限范围内给出响应信号。
-
实时处理任务可分为
-
硬实时任务(hard real-time task)
-
Hard real-time systems – required to complete a critical task within a guaranteed amount of time.
硬实时系统 – 用于实现要求在给定的时间内执行完紧急进程的场合
-
这种进程在提交时会明确指出需在什么时间内完成
-
resource reservation系统则会通过资源预留以保证这个任务的及时完成,或者在资源不能保证的情况下拒绝执行
-
硬实时系统通常由实现紧急任务的具有特殊目的软件组成,而不一定具备现代OS和计算机的完整功能
-
-
软实时任务(soft real-time task)
-
Soft real-time computing – requires that critical processes receive priority over less fortunate ones.
软实时计算 – 要求紧急进程得到比其他进程更高的优先级)
-
-
对OS的调度程序及其他相关方面提出了要求.首先,系统要实现基于优先级的调度,实时进程须具有最高优先级,且不能随着时间的推移降低优先级; 其次,调度延迟必须很小.
Dispatch Latency
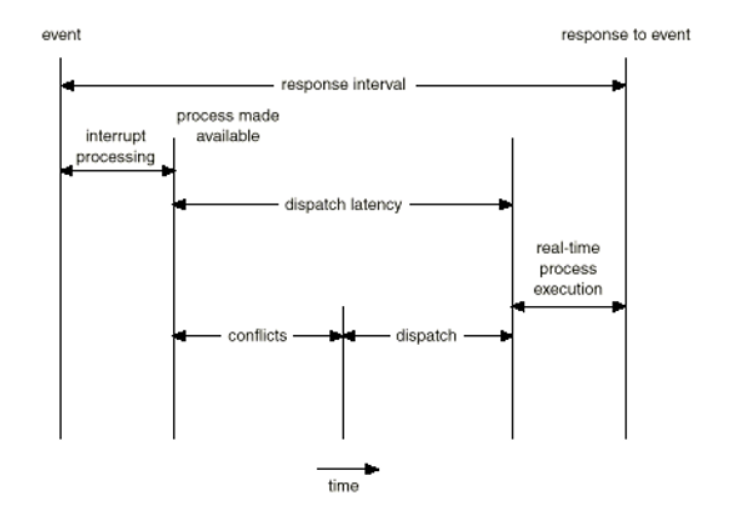
-
To keep dispatch latency low ,we need to allow system calls to be preemptible.为降低分派延迟,需要允许系统调用被抢占
- One is to insert preemption points in long-duration system calls.一种方法是在长系统调用中插入抢占点
- Another method for dealing with preemption is to make the entire kernel preemptible. All kernel data structures must be protected through the use of various synchronization mechanisms.另一种方法是使得整个内核可被抢占,但所有内核数据结构必须通过各种同步机制加以保护
-
Priority inversion :the higher-priority process needs to read or modify kernel data that are currently being accessed by another.
如果较高优先级进程需读或修改正在被另一个低优先级进程所访问的内核数据,高优先级进程需要等待低优先级进程的完成.这种现象称为优先级倒置
-
Priority-inheritance protocol :all the processes that are accessing resources that the high-priority process needs inherit the high priority until they are done with the resource in question. when they are finished, their priority reverts to its original value
优先级继承:(正在访问高优先级进程所需资源的)低优先级进程继承高优先级,直到相关资源处理完毕,它们的优先级再返回原来的值.
Operating System Examples
Thread Scheduling
-
User-level threads are managed by a thread library,to run on a cpu, user-level threads are mapped to an associated kernel-level thread by a lightweight process(lwp).用户级线程要运行的话,需通过LWP映射到某个内核级线程
-
Local Scheduling – How the threads library decides which thread to put onto an available LWP.
局部调度– 线程库怎样决定将哪个线程列入有效的轻量级线程
-
Global Scheduling – How the kernel decides which kernel thread to run next.
全局调度 – 内核怎样决定下一个运行的内核线程
具体例子PPT上有
- Solaris scheduling
- Windows XP scheduling
- Linux scheduling
Algorithm Evaluation
-
CPU调度算法很多,如何选择适当的算法?
- 首先定义一个标准 (根据要实现的系统所追求的目标,如CPU利用率\系统吞吐量\平均周转时间\响应时间等)
- 然后根据标准来选择适当的算法
- 采用相应的模型来评价算法
-
Deterministic modeling (确定模型法) – takes a particular predetermined workload and defines the performance of each algorithm for that workload
确定模型法 – 精确预定作业量,并定义该作业量在每个算法上执行的情况
- 确定模型法主要用于描述调度算法和提供例子,它要求有准确的输入数据,如进程的数目、到达时间、预定执行时间等。在某些情况下,可以用确定模型法来选择调度算法
-
Queueing models(等待队列模型) queueing-network analysis
- 计算机系统可描述为服务器网络,每个服务器都有一个进程队列.
- CPU是具有就绪进程队列的服务器,而I/O系统具有设备队列,知道了到达率和服务率,就可以计算使用率\平均队列长度\平均等待时间等
- 设n为平均队列长度,W为队列的平均等待时间, λ为新进程到达队列的平均到达率.存在如下公式.如果系统处于稳定状态,那么离开队列的进程数量必定等于到达进程的数量.
-
Simulations (建模) 是一种更准确的方法。通过编程给计算机系统建模。用软件数据结构表示计算机的主要部件,有一个变量来表示时钟,随着这个变量的值的增加,仿真器修改系统的状态来反映外设、进程和调度程序的活动。当这个仿真器运行时,指明算法性能的统计数据会被收集并打印。
-
Implementation(实现):完全准确的方法。编写一个调度算法,把它放到真实的OS中去运行,来看它是如何工作的。
















 3997
3997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











