







线性回归与基础优化算法
1.线性回归理论部分
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。
在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域中的大多数任务通常都与预测(prediction)有关。
当我们想预测一个数值时,就会涉及到回归问题。
常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、
预测需求(零售销量等)。
但不是所有的预测都是回归问题。
在后面的章节中,我们将介绍分类问题。分类问题的目标是预测数据属于一组类别中的哪一个。
1.1 线性回归的基本元素
线性回归(linear regression)可以追溯到19世纪初,它在回归的各种标准工具中最简单而且最流行。
线性回归基于几个简单的假设:
首先,假设自变量
x
\mathbf{x}
x和因变量
y
y
y之间的关系是线性的,即
y
y
y可以表示为
x
\mathbf{x}
x中元素的加权和,这里通常允许包含观测值的一些噪声;
其次,我们假设任何噪声都比较正常,如噪声遵循正态分布。
为了解释线性回归,我们举一个实际的例子:
我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。
为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。
这个数据集包括了房屋的销售价格、面积和房龄。
在机器学习的术语中,该数据集称为训练数据集(training data set)
或训练集(training set)。
每行数据(比如一次房屋交易相对应的数据)称为样本(sample),
也可以称为数据点(data point)或数据样本(data instance)。
我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。
预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
通常,我们使用
n
n
n来表示数据集中的样本数。
对索引为
i
i
i的样本,其输入表示为
x
(
i
)
=
[
x
1
(
i
)
,
x
2
(
i
)
]
⊤
\mathbf{x}^{(i)} = [x_1^{(i)}, x_2^{(i)}]^\top
x(i)=[x1(i),x2(i)]⊤,其对应的标签是
y
(
i
)
y^{(i)}
y(i)。
1.1.1 线性模型
线性假设是指目标(房屋价格)可以表示为特征(面积和房龄)的加权和,如下面的式子:
p r i c e = w a r e a ⋅ a r e a + w a g e ⋅ a g e + b . \mathrm{price} = w_{\mathrm{area}} \cdot \mathrm{area} + w_{\mathrm{age}} \cdot \mathrm{age} + b. price=warea⋅area+wage⋅age+b.
w
a
r
e
a
w_{\mathrm{area}}
warea和
w
a
g
e
w_{\mathrm{age}}
wage称为权重(weight),权重决定了每个特征对我们预测值的影响。
b
b
b称为偏置(bias)、偏移量(offset)或截距(intercept)。
偏置是指当所有特征都取值为0时,预测值应该为多少。
即使现实中不会有任何房子的面积是0或房龄正好是0年,我们仍然需要偏置项。
如果没有偏置项,我们模型的表达能力将受到限制。
严格来说,是输入特征的一个仿射变换(affine transformation)。
仿射变换的特点是通过加权和对特征进行线性变换(linear transformation),并通过偏置项来进行平移(translation)。
给定一个数据集,我们的目标是寻找模型的权重
w
\mathbf{w}
w和偏置
b
b
b,使得根据模型做出的预测大体符合数据里的真实价格。
输出的预测值由输入特征通过线性模型的仿射变换决定,仿射变换由所选权重和偏置确定。
而在机器学习领域,我们通常使用的是高维数据集,建模时采用线性代数表示法会比较方便。
当我们的输入包含
d
d
d个特征时,我们将预测结果
y
^
\hat{y}
y^(通常使用“尖角”符号表示
y
y
y的估计值)表示为:
y ^ = w 1 x 1 + . . . + w d x d + b . \hat{y} = w_1 x_1 + ... + w_d x_d + b. y^=w1x1+...+wdxd+b.
将所有特征放到向量 x ∈ R d \mathbf{x} \in \mathbb{R}^d x∈Rd中,并将所有权重放到向量 w ∈ R d \mathbf{w} \in \mathbb{R}^d w∈Rd中,我们可以用点积形式来简洁地表达模型:
y
^
=
w
⊤
x
+
b
.
\hat{y} = \mathbf{w}^\top \mathbf{x} + b.
y^=w⊤x+b.
向量
x
\mathbf{x}
x对应于单个数据样本的特征。
用符号表示的矩阵
X
∈
R
n
×
d
\mathbf{X} \in \mathbb{R}^{n \times d}
X∈Rn×d
可以很方便地引用我们整个数据集的
n
n
n个样本。
其中,
X
\mathbf{X}
X的每一行是一个样本,每一列是一种特征。
对于特征集合
X
\mathbf{X}
X,预测值
y
^
∈
R
n
\hat{\mathbf{y}} \in \mathbb{R}^n
y^∈Rn
可以通过矩阵-向量乘法表示为:
y ^ = X w + b {\hat{\mathbf{y}}} = \mathbf{X} \mathbf{w} + b y^=Xw+b
这个过程中的求和将使用广播机制。
给定训练数据特征
X
\mathbf{X}
X和对应的已知标签
y
\mathbf{y}
y,线性回归的目标是找到一组权重向量
w
\mathbf{w}
w和偏置
b
b
b
当给定从
X
\mathbf{X}
X的同分布中取样的新样本特征时,这组权重向量和偏置能够使得新样本预测标签的误差尽可能小。
虽然我们相信给定
x
\mathbf{x}
x预测
y
y
y的最佳模型会是线性的,但我们很难找到一个有
n
n
n个样本的真实数据集,其中对于所有的
1
≤
i
≤
n
1 \leq i \leq n
1≤i≤n,
y
(
i
)
y^{(i)}
y(i)完全等于
w
⊤
x
(
i
)
+
b
\mathbf{w}^\top \mathbf{x}^{(i)}+b
w⊤x(i)+b。
无论我们使用什么手段来观察特征
X
\mathbf{X}
X和标签
y
\mathbf{y}
y,
都可能会出现少量的观测误差。
因此,即使确信特征与标签的潜在关系是线性的,我们也会加入一个噪声项来考虑观测误差带来的影响。
在开始寻找最好的模型参数(model parameters)
w
\mathbf{w}
w和
b
b
b之前,
我们还需要两个东西:
(1)一种模型质量的度量方式;
(2)一种能够更新模型以提高模型预测质量的方法。
1.1.2 损失函数
在我们开始考虑如何用模型拟合(fit)数据之前,我们需要确定一个拟合程度的度量。
损失函数(loss function)能够量化目标的实际值与预测值之间的差距。
通常我们会选择非负数作为损失,且数值越小表示损失越小,完美预测时的损失为0。
回归问题中最常用的损失函数是平方误差函数。
当样本
i
i
i的预测值为
y
^
(
i
)
\hat{y}^{(i)}
y^(i),其相应的真实标签为
y
(
i
)
y^{(i)}
y(i)时,
平方误差可以定义为以下公式:
l ( i ) ( w , b ) = 1 2 ( y ^ ( i ) − y ( i ) ) 2 . l^{(i)}(\mathbf{w}, b) = \frac{1}{2} \left(\hat{y}^{(i)} - y^{(i)}\right)^2. l(i)(w,b)=21(y^(i)−y(i))2.
常数
1
2
\frac{1}{2}
21不会带来本质的差别,但这样在形式上稍微简单一些
(因为当我们对损失函数求导后常数系数为1)。
由于训练数据集并不受我们控制,所以经验误差只是关于模型参数的函数。
为了进一步说明,来看下面的例子。
我们为一维情况下的回归问题绘制图像,如图所示。

由于平方误差函数中的二次方项,估计值
y
^
(
i
)
\hat{y}^{(i)}
y^(i)和观测值
y
(
i
)
y^{(i)}
y(i)之间较大的差异将导致更大的损失。
为了度量模型在整个数据集上的质量,我们需计算在训练集
n
n
n个样本上的损失均值(也等价于求和)。
L ( w , b ) = 1 n ∑ i = 1 n l ( i ) ( w , b ) = 1 n ∑ i = 1 n 1 2 ( w ⊤ x ( i ) + b − y ( i ) ) 2 . L(\mathbf{w}, b) =\frac{1}{n}\sum_{i=1}^n l^{(i)}(\mathbf{w}, b) =\frac{1}{n} \sum_{i=1}^n \frac{1}{2}\left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right)^2. L(w,b)=n1i=1∑nl(i)(w,b)=n1i=1∑n21(w⊤x(i)+b−y(i))2.
在训练模型时,我们希望寻找一组参数( w ∗ , b ∗ \mathbf{w}^*, b^* w∗,b∗),这组参数能最小化在所有训练样本上的总损失。如下式:
w ∗ , b ∗ = * a r g m i n w , b L ( w , b ) . \mathbf{w}^*, b^* = \operatorname*{argmin}_{\mathbf{w}, b}\ L(\mathbf{w}, b). w∗,b∗=*argminw,b L(w,b).
1.1.3 解析解
线性回归刚好是一个很简单的优化问题。
与我们将在本书中所讲到的其他大部分模型不同,线性回归的解可以用一个公式简单地表达出来,这类解叫作解析解(analytical solution)。
首先,我们将偏置
b
b
b合并到参数
w
\mathbf{w}
w中,合并方法是在包含所有参数的矩阵中附加一列。
我们的预测问题是最小化
∥
y
−
X
w
∥
2
\|\mathbf{y} - \mathbf{X}\mathbf{w}\|^2
∥y−Xw∥2。
这在损失平面上只有一个临界点,这个临界点对应于整个区域的损失极小点。
将损失关于
w
\mathbf{w}
w的导数设为0,得到解析解:
w ∗ = ( X ⊤ X ) − 1 X ⊤ y . \mathbf{w}^* = (\mathbf X^\top \mathbf X)^{-1}\mathbf X^\top \mathbf{y}. w∗=(X⊤X)−1X⊤y.
像线性回归这样的简单问题存在解析解,但并不是所有的问题都存在解析解。
解析解可以进行很好的数学分析,但解析解对问题的限制很严格,导致它无法广泛应用在深度学习里。
1.1.4 随机梯度下降
即使在我们无法得到解析解的情况下,我们仍然可以有效地训练模型。
在许多任务上,那些难以优化的模型效果要更好。
因此,弄清楚如何训练这些难以优化的模型是非常重要的。
这里我们用到一种名为梯度下降(gradient descent)的方法,
这种方法几乎可以优化所有深度学习模型。
它通过不断地在损失函数递减的方向上更新参数来降低误差。
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。
但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。
因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
在每次迭代中,我们首先随机抽样一个小批量
B
\mathcal{B}
B,它是由固定数量的训练样本组成的。
然后,我们计算小批量的平均损失关于模型参数的导数(也可以称为梯度)。
最后,我们将梯度乘以一个预先确定的正数
η
\eta
η,并从当前参数的值中减掉。
我们用下面的数学公式来表示这一更新过程( ∂ \partial ∂表示偏导数):
( w , b ) ← ( w , b ) − η ∣ B ∣ ∑ i ∈ B ∂ ( w , b ) l ( i ) ( w , b ) . (\mathbf{w},b) \leftarrow (\mathbf{w},b) - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{(\mathbf{w},b)} l^{(i)}(\mathbf{w},b). (w,b)←(w,b)−∣B∣ηi∈B∑∂(w,b)l(i)(w,b).
总结一下,算法的步骤如下:
(1)初始化模型参数的值,如随机初始化;
(2)从数据集中随机抽取小批量样本且在负梯度的方向上更新参数,并不断迭代这一步骤。
对于平方损失和仿射变换,我们可以明确地写成如下形式:
w
←
w
−
η
∣
B
∣
∑
i
∈
B
∂
w
l
(
i
)
(
w
,
b
)
=
w
−
η
∣
B
∣
∑
i
∈
B
x
(
i
)
(
w
⊤
x
(
i
)
+
b
−
y
(
i
)
)
,
b
←
b
−
η
∣
B
∣
∑
i
∈
B
∂
b
l
(
i
)
(
w
,
b
)
=
b
−
η
∣
B
∣
∑
i
∈
B
(
w
⊤
x
(
i
)
+
b
−
y
(
i
)
)
.
\begin{aligned} \mathbf{w} &\leftarrow \mathbf{w} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_{\mathbf{w}} l^{(i)}(\mathbf{w}, b) = \mathbf{w} - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \mathbf{x}^{(i)} \left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right),\\ b &\leftarrow b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \partial_b l^{(i)}(\mathbf{w}, b) = b - \frac{\eta}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} \left(\mathbf{w}^\top \mathbf{x}^{(i)} + b - y^{(i)}\right). \end{aligned}
wb←w−∣B∣ηi∈B∑∂wl(i)(w,b)=w−∣B∣ηi∈B∑x(i)(w⊤x(i)+b−y(i)),←b−∣B∣ηi∈B∑∂bl(i)(w,b)=b−∣B∣ηi∈B∑(w⊤x(i)+b−y(i)).
公式中的变量都是向量。
在这里,更优雅的向量表示法比系数表示法(如
w
1
,
w
2
,
…
,
w
d
w_1, w_2, \ldots, w_d
w1,w2,…,wd)更具可读性。
- ∣ B ∣ |\mathcal{B}| ∣B∣表示每个小批量中的样本数,这也称为批量大小(batch size)
- η \eta η表示学习率(learning rate)
批量大小和学习率的值通常是手动预先指定,而不是通过模型训练得到的。
这些可以调整但不在训练过程中更新的参数称为超参数(hyperparameter)。
调参(hyperparameter tuning)是选择超参数的过程。
超参数通常是我们根据训练迭代结果来调整的,而训练迭代结果是在独立的验证数据集(validation dataset)上评估得到的。
在训练了预先确定的若干迭代次数后(或者直到满足某些其他停止条件后),我们记录下模型参数的估计值,表示为
w
^
,
b
^
\hat{\mathbf{w}}, \hat{b}
w^,b^。
但是,即使我们的函数确实是线性的且无噪声,这些估计值也不会使损失函数真正地达到最小值。
因为算法会使得损失向最小值缓慢收敛,但却不能在有限的步数内非常精确地达到最小值。
线性回归恰好是一个在整个域中只有一个最小值的学习问题。
但是对于像深度神经网络这样复杂的模型来说,损失平面上通常包含多个最小值。
深度学习实践者很少会去花费大力气寻找这样一组参数,使得在训练集上的损失达到最小。
事实上,更难做到的是找到一组参数,这组参数能够在我们从未见过的数据上实现较低的损失,这一挑战被称为泛化(generalization)。
1.1.5 用模型进行预测
给定“已学习”的线性回归模型
w
^
⊤
x
+
b
^
\hat{\mathbf{w}}^\top \mathbf{x} + \hat{b}
w^⊤x+b^,现在我们可以通过房屋面积
x
1
x_1
x1和房龄
x
2
x_2
x2来估计一个(未包含在训练数据中的)新房屋价格。
给定特征估计目标的过程通常称为预测(prediction)或推断(inference)。
在统计学中,推断更多地表示基于数据集估计参数。
1.2 矢量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。
为了实现这一点,需要(我们对计算进行矢量化,从而利用线性代数库,而不是在Python中编写开销高昂的for循环)。
%matplotlib inline
import math
import time
import numpy as np
import torch
import d2l
为了说明矢量化为什么如此重要,我们考虑(对向量相加的两种方法)。我们实例化两个全为1的10000维向量。
- 在一种方法中,我们将使用Python的for循环遍历向量
- 在另一种方法中,我们将依赖对
+的调用
【自定义计时器】
class Timer: #@save
"""记录多次运行时间。"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器。"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中。"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间。"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和。"""
return sum(self.times)
def cumsum(self):
"""返回累计时间。"""
return np.array(self.times).cumsum().tolist()
[我们使用for循环,每次执行一位的加法]
c = torch.zeros(n)
timer = Timer()
for i in range(n):
c[i] = a[i] + b[i]
f'{timer.stop():.5f} sec'
'0.07785 sec'
(或者,我们使用重载的+运算符来计算按元素的和)
timer.start()
d = a + b
f'{timer.stop():.5f} sec'
'0.00000 sec'
结果很明显,第二种方法比第一种方法快得多。
矢量化代码通常会带来数量级的加速。
另外,我们将更多的数学运算放到库中,而无须自己编写那么多的计算,从而减少了出错的可能性。
1.3 正态分布与平方损失
接下来,我们通过对噪声分布的假设来解读平方损失目标函数。
正态分布和线性回归之间的关系很密切。
正态分布(normal distribution),也称为高斯分布(Gaussian distribution),最早由德国数学家高斯(Gauss)应用于天文学研究。
简单的说,若随机变量
x
x
x具有均值
μ
\mu
μ和方差
σ
2
\sigma^2
σ2(标准差
σ
\sigma
σ),其正态分布概率密度函数如下:
p ( x ) = 1 2 π σ 2 exp ( − 1 2 σ 2 ( x − μ ) 2 ) . p(x) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2 \sigma^2} (x - \mu)^2\right). p(x)=2πσ21exp(−2σ21(x−μ)2).
下面[我们定义一个Python函数来计算正态分布]。
def normal(x, mu, sigma):
p = 1 / math.sqrt(2 * math.pi * sigma**2)
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)
[可视化概率分布函数]
# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01)
# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',
ylabel='p(x)', figsize=(4.5, 2.5),
legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])

就像我们所看到的,改变均值会产生沿
x
x
x轴的偏移,增加方差将会分散分布、降低其峰值。
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:
我们假设了观测中包含噪声,其中噪声服从正态分布。
噪声正态分布如下式:
y = w ⊤ x + b + ϵ , y = \mathbf{w}^\top \mathbf{x} + b + \epsilon, y=w⊤x+b+ϵ,
其中, ϵ ∼ N ( 0 , σ 2 ) \epsilon \sim \mathcal{N}(0, \sigma^2) ϵ∼N(0,σ2)。
因此,我们现在可以写出通过给定的 x \mathbf{x} x观测到特定 y y y的似然(likelihood):
P ( y ∣ x ) = 1 2 π σ 2 exp ( − 1 2 σ 2 ( y − w ⊤ x − b ) 2 ) . P(y \mid \mathbf{x}) = \frac{1}{\sqrt{2 \pi \sigma^2}} \exp\left(-\frac{1}{2 \sigma^2} (y - \mathbf{w}^\top \mathbf{x} - b)^2\right). P(y∣x)=2πσ21exp(−2σ21(y−w⊤x−b)2).
现在,根据极大似然估计法,参数 w \mathbf{w} w和 b b b的最优值是使整个数据集的似然最大的值:
P ( y ∣ X ) = ∏ i = 1 n p ( y ( i ) ∣ x ( i ) ) . P(\mathbf y \mid \mathbf X) = \prod_{i=1}^{n} p(y^{(i)}|\mathbf{x}^{(i)}). P(y∣X)=i=1∏np(y(i)∣x(i)).
根据极大似然估计法选择的估计量称为极大似然估计量。
虽然使许多指数函数的乘积最大化看起来很困难,但是我们可以在不改变目标的前提下,通过最大化似然对数来简化。
由于历史原因,优化通常是说最小化而不是最大化。
我们可以改为最小化负对数似然
−
log
P
(
y
∣
X
)
-\log P(\mathbf y \mid \mathbf X)
−logP(y∣X)。
由此可以得到的数学公式是:
− log P ( y ∣ X ) = ∑ i = 1 n 1 2 log ( 2 π σ 2 ) + 1 2 σ 2 ( y ( i ) − w ⊤ x ( i ) − b ) 2 . -\log P(\mathbf y \mid \mathbf X) = \sum_{i=1}^n \frac{1}{2} \log(2 \pi \sigma^2) + \frac{1}{2 \sigma^2} \left(y^{(i)} - \mathbf{w}^\top \mathbf{x}^{(i)} - b\right)^2. −logP(y∣X)=i=1∑n21log(2πσ2)+2σ21(y(i)−w⊤x(i)−b)2.
现在我们只需要假设
σ
\sigma
σ是某个固定常数就可以忽略第一项,因为第一项不依赖于
w
\mathbf{w}
w和
b
b
b。
现在第二项除了常数
1
σ
2
\frac{1}{\sigma^2}
σ21外,其余部分和前面介绍的均方误差是一样的。
幸运的是,上面式子的解并不依赖于
σ
\sigma
σ。
因此,在高斯噪声的假设下,最小化均方误差等价于对线性模型的极大似然估计。
1.4 从线性回归到深度网络
到目前为止,我们只谈论了线性模型。
尽管神经网络涵盖了更多更为丰富的模型,我们依然可以用描述神经网络的方式来描述线性模型,从而把线性模型看作一个神经网络。
首先,我们用“层”符号来重写这个模型。
1.4.1 神经网络图
深度学习从业者喜欢绘制图表来可视化模型中正在发生的事情。
在下图中,我们将线性回归模型描述为一个神经网络。
需要注意的是,该图只显示连接模式,即只显示每个输入如何连接到输出,隐去了权重和偏置的值。
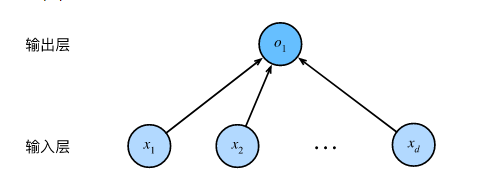
所示的神经网络中,输入为
x
1
,
…
,
x
d
x_1, \ldots, x_d
x1,…,xd,因此输入层中的输入数(或称为特征维度,feature dimensionality)为
d
d
d。网络的输出为
o
1
o_1
o1,因此输出层中的输出数是1。
需要注意的是,输入值都是已经给定的,并且只有一个计算神经元。
由于模型重点在发生计算的地方,所以通常我们在计算层数时不考虑输入层。
也就是说,图中神经网络的层数为1。
我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连,
我们将这种变换(图中的输出层)称为全连接层(fully-connected layer)或称为稠密层(dense layer)。
1.4.2 生物学
线性回归发明的时间(1795年)早于计算神经科学,所以将线性回归描述为神经网络似乎不合适。
当控制学家、神经生物学家沃伦·麦库洛奇和沃尔特·皮茨开始开发人工神经元模型时,
他们为什么将线性模型作为一个起点呢?
我们来看一张图片:
这是一张由树突(dendrites,输入终端)、细胞核(nucleu,CPU)组成的生物神经元图片。
轴突(axon,输出线)和轴突端子(axon terminal,输出端子)通过突触(synapse)与其他神经元连接。

树突中接收到来自其他神经元(或视网膜等环境传感器)的信息
x
i
x_i
xi。
该信息通过突触权重
w
i
w_i
wi来加权,以确定输入的影响(即,通过
x
i
w
i
x_i w_i
xiwi相乘来激活或抑制)。
来自多个源的加权输入以加权和
y
=
∑
i
x
i
w
i
+
b
y = \sum_i x_i w_i + b
y=∑ixiwi+b的形式汇聚在细胞核中,
然后将这些信息发送到轴突
y
y
y中进一步处理,通常会通过
σ
(
y
)
\sigma(y)
σ(y)进行一些非线性处理。
之后,它要么到达目的地(例如肌肉),要么通过树突进入另一个神经元。
当然,许多这样的单元可以通过正确连接和正确的学习算法拼凑在一起,
从而产生的行为会比单独一个神经元所产生的行为更有趣、更复杂,
这种想法归功于我们对真实生物神经系统的研究。
当今大多数深度学习的研究几乎没有直接从神经科学中获得灵感。
我们援引斯图尔特·罗素和彼得·诺维格谁,在他们的经典人工智能教科书
Artificial Intelligence:A Modern Approach 中所说:虽然飞机可能受到鸟类的启发,但几个世纪以来,鸟类学并不是航空创新的主要驱动力。
同样地,如今在深度学习中的灵感同样或更多地来自数学、统计学和计算机科学。
1.5 小结
- 机器学习模型中的关键要素是训练数据、损失函数、优化算法,还有模型本身。
- 矢量化使数学表达上更简洁,同时运行的更快。
- 最小化目标函数和执行极大似然估计等价。
- 线性回归模型也是一个简单的神经网络。
1.6 思考题及其解答
练习
- 假设我们有一些数据
x
1
,
…
,
x
n
∈
R
x_1, \ldots, x_n \in \mathbb{R}
x1,…,xn∈R。我们的目标是找到一个常数
b
b
b,使得最小化
∑
i
(
x
i
−
b
)
2
\sum_i (x_i - b)^2
∑i(xi−b)2。
- 找到最优值 b b b的解析解。
- 这个问题及其解与正态分布有什么关系?
- 推导出使用平方误差的线性回归优化问题的解析解。为了简化问题,可以忽略偏置
b
b
b(我们可以通过向
X
\mathbf X
X添加所有值为1的一列来做到这一点)。
- 用矩阵和向量表示法写出优化问题(将所有数据视为单个矩阵,将所有目标值视为单个向量)。
- 计算损失对 w w w的梯度。
- 通过将梯度设为0、求解矩阵方程来找到解析解。
- 什么时候可能比使用随机梯度下降更好?这种方法何时会失效?
- 假定控制附加噪声
ϵ
\epsilon
ϵ的噪声模型是指数分布。也就是说,
p
(
ϵ
)
=
1
2
exp
(
−
∣
ϵ
∣
)
p(\epsilon) = \frac{1}{2} \exp(-|\epsilon|)
p(ϵ)=21exp(−∣ϵ∣)
- 写出模型 − log P ( y ∣ X ) -\log P(\mathbf y \mid \mathbf X) −logP(y∣X)下数据的负对数似然。
- 你能写出解析解吗?
- 提出一种随机梯度下降算法来解决这个问题。哪里可能出错?(提示:当我们不断更新参数时,在驻点附近会发生什么情况)你能解决这个问题吗?

2. 基础优化方法
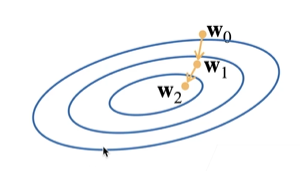
2.1 梯度下降
-
挑选一个初始值 w 0 w_0 w0
-
重复迭代参数t=1,2,3
w t w_t wt= w t − 1 − η w_{t-1}-\eta wt−1−η ∂ l ∂ w t − 1 \frac{\partial l}{\partial w_{t-1}} ∂wt−1∂l
-
沿梯度方向将增加损失函数值
-
学习率 η \eta η:步长的超参数
2.2 选择学习率

2.3 小批量随机梯度下降


2.4 总结

3. 线性回归从零开始实现
3.1 生成数据集
[根据带有噪声的线性模型构造一个人造数据集。]
生成一个包含1000个样本的数据集,
每个样本包含从标准正态分布中采样的2个特征。合成数据集是一个矩阵
X
∈
R
1000
×
2
\mathbf{X}\in \mathbb{R}^{1000 \times 2}
X∈R1000×2。
(**我们使用线性模型参数
w
=
[
2
,
−
3.4
]
⊤
\mathbf{w} = [2, -3.4]^\top
w=[2,−3.4]⊤、
b
=
4.2
b = 4.2
b=4.2和噪声项
ϵ
\epsilon
ϵ生成数据集及其标签:
y
=
X
w
+
b
+
ϵ
.
\mathbf{y}= \mathbf{X} \mathbf{w} + b + \mathbf\epsilon.
y=Xw+b+ϵ.
**)
将 ϵ \epsilon ϵ视为模型预测和标签时的潜在观测误差。在这里我们认为标准假设成立,即 ϵ \epsilon ϵ服从均值为0的正态分布。为了简化问题,我们将标准差设为0.01。
%matplotlib inline
import random
import torch
import d2l
def synthetic_data(w, b, num_examples):
"""生成 y = Xw + b + 噪声。"""
X = torch.normal(0, 1, (num_examples, len(w)))#生成一个均值为0,方差为1的正态随机数矩阵,矩阵的维度为样本数×特征个数
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)#加入一个随机噪音
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
print('features:', features[0],'\nlabel:', labels[0])
#features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)
features: tensor([-1.3686, 1.0361])
label: tensor([-2.0784])
feature中每个变量和label的关系均为线性
d2l.set_figsize()
d2l.plt.scatter(features[:, (0)].detach().numpy(), labels.detach().numpy(), s=1);#在pytorch的某些版本中需要将变量从计算图中detach出来才能转换成numpy
d2l.plt.scatter(features[:, (1)].detach().numpy(), labels.detach().numpy(), s=1);

3.2 读取数据集
[定义一个data_iter函数,该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量,每个小批量包含一组特征和标签]。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(indices[i: min(i + batch_size,num_examples)])
yield features[batch_indices], labels[batch_indices]
3.3 初始化模型参数
[在我们开始用小批量随机梯度下降优化我们的模型参数之前],
(我们需要先有一些参数)。
在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重,
并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)
3.4 定义模型
[定义模型,将模型的输入和参数同模型的输出关联起来。]
def linreg(X, w, b):
"""线性回归模型。"""
return torch.matmul(X, w) + b
3.4.1 定义损失函数
因为需要计算损失函数的梯度,所以我们应该先定义损失函数,这里我们使用平方损失函数。
def squared_loss(y_hat, y):
"""均方损失。"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
3.4.2 定义优化算法(小批量随机梯度下降)
在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。
接下来,朝着减少损失的方向更新我们的参数。
该函数接受模型参数集合、学习速率和批量大小作为输入。每一步更新的大小由学习速率lr决定。
因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size)来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
def sgd(params, lr, batch_size):
"""小批量随机梯度下降。"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()#每次迭代都要将梯度清零
3.5 训练
[训练过程]
在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。
计算完损失后,我们开始反向传播,存储每个参数的梯度。
最后,我们调用优化算法sgd来更新模型参数。
概括一下,我们将执行以下循环:
- 初始化参数
- 重复以下训练,直到完成
- 计算梯度 g ← ∂ ( w , b ) 1 ∣ B ∣ ∑ i ∈ B l ( x ( i ) , y ( i ) , w , b ) \mathbf{g} \leftarrow \partial_{(\mathbf{w},b)} \frac{1}{|\mathcal{B}|} \sum_{i \in \mathcal{B}} l(\mathbf{x}^{(i)}, y^{(i)}, \mathbf{w}, b) g←∂(w,b)∣B∣1∑i∈Bl(x(i),y(i),w,b)
- 更新参数 ( w , b ) ← ( w , b ) − η g (\mathbf{w}, b) \leftarrow (\mathbf{w}, b) - \eta \mathbf{g} (w,b)←(w,b)−ηg
在每个迭代周期(epoch)中,我们使用data_iter函数遍历整个数据集,并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。
这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设为3和0.03。
设置超参数很棘手,需要通过反复试验进行调整。
lr = 0.03#学习率
num_epochs = 3#迭代次数
net = linreg#使用线性回归模型
loss = squared_loss#采用均方误差
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # `X`和`y`的小批量损失
# 因为`l`形状是(`batch_size`, 1),而不是一个标量。`l`中的所有元素被加到一起,
# 并以此计算关于[`w`, `b`]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')
epoch 1, loss 0.046312
epoch 2, loss 0.000188
epoch 3, loss 0.000051
因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。
因此,我们可以通过[比较真实参数和通过训练学到的参数来评估训练的成功程度]。
事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')
w的估计误差: tensor([0.0002, 0.0001], grad_fn=<SubBackward0>)
b的估计误差: tensor([-0.0002], grad_fn=<RsubBackward1>)
在机器学习中,我们通常不太关心恢复真正的参数,而更关心如何高度准确预测参数。
幸运的是,即使是在复杂的优化问题上,随机梯度下降通常也能找到非常好的解。
其中一个原因是,在深度网络中存在许多参数组合能够实现高度精确的预测。
3.6 小结
- 我们学习了深度网络是如何实现和优化的。在这一过程中只使用张量和自动微分,不需要定义层或复杂的优化器。
- 这一节只触及到了表面知识。在下面的部分中,我们将基于刚刚介绍的概念描述其他模型,并学习如何更简洁地实现其他模型。
3.7 思考题及解答
- 如果我们将权重初始化为零,会发生什么。算法仍然有效吗?
答:无隐藏层时权重可以初始化为0 ,但是后续如果有隐藏层权重初始化为0会导致训练过程中所有隐藏层权重都是相等的。详细内容见:谈谈神经网络权重为什么不能初始化为0
- 假设你是乔治·西蒙·欧姆,试图为电压和电流的关系建立一个模型。你能使用自动微分来学习模型的参数吗?
import random
import torch
#生成数据
def synthetic_data_Ohm(true_R, num):
"""U=IR + 噪声。"""
I = torch.rand(num,1)#生成电流值,物理意义均为正,在此用(0,1)均匀分布
U = torch.matmul(I, true_R)#U=IR,广播机制
U += torch.normal(0, 0.1, U.shape)
return I,U
#读取数据
def data_iter(batch_size, I, U):# 载入数据集,分成batch
num = len(I)
indices = list(range(num))# 创建整个数据集的索引
random.shuffle(indices) # 打乱索引,便于随机抽取batch
for i in range(0, num, batch_size):
batch_indices = torch.tensor(indices[i: min(i + batch_size, num)])
yield I[batch_indices], U[batch_indices]#用yield不用return便于训练时的迭代
#定义模型
def model_for_Ohm(I,R): # 欧姆定律模型
return torch.matmul(I, R)
#定义损失函数
# def loss_for_Ohm(predicted_U, U): # 采用的是交叉熵
# return 0.5/len(U)*(predicted_U - U).norm()
def loss_for_Ohm(y_hat, y):
"""均方损失。"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2
#定义优化算法
def sgd(params, lr,batch_size): #小批量随机梯度下降。
with torch.no_grad():#优化算法更新参数不能算在计算图中,所以先声明一下
for param in params:
param -= lr * param.grad /batch_size
param.grad.zero_()#每次迭代都要将梯度清零
if __name__ == "__main__":
#生成数据
true_R = torch.tensor([3.5])
I, U = synthetic_data_Ohm(true_R, 1000)
#初始化模型参数
R = torch.normal(0, 0.01, size = true_R.shape, requires_grad = True)
#开始训练
batch_size = 30
lr = 0.1
num_epochs = 10
net = model_for_Ohm
loss = loss_for_Ohm
for epoch in range(num_epochs):
for i, u in data_iter(batch_size, I, U):
l = loss(net(i, R), u)
l.sum().backward()#反向传播计算梯度
sgd([R], lr, batch_size) #梯度下降优化
with torch.no_grad():#计算epochloss时,只是检验一下,不需要算在计算图里
train_l = loss(net(I, R), U)
print(f'train loss for epoch {epoch} is {train_l.mean()} \n')
print('实际的电阻值 = ', true_R, '\n', '训练学习到的电阻值 = ', R)
train loss for epoch 0 is 0.22325269877910614
train loss for epoch 1 is 0.02835436537861824
train loss for epoch 2 is 0.007398840971291065
train loss for epoch 3 is 0.005151285789906979
train loss for epoch 4 is 0.00489839306101203
train loss for epoch 5 is 0.004865396302193403
train loss for epoch 6 is 0.004861971363425255
train loss for epoch 7 is 0.004862657748162746
train loss for epoch 8 is 0.004861508961766958
train loss for epoch 9 is 0.004861524328589439
实际的电阻值 = tensor([3.5000])
训练学习到的电阻值 = tensor([3.4986], requires_grad=True)
-
如果你想计算二阶导数可能会遇到什么问题?你会如何解决这些问题?
计算量特别大,我会用近似算法来计算二阶导数,例如使用拟牛顿方法替代牛顿法。 -
为什么在
squared_loss函数中需要使用reshape函数?
答:y_hat的形状是(n,1)是二维的tensor,而yy的形状是(n,)是一维的tensor。如果不使用reshape函数,二者相减y_hat - y会引发tensor的广播机制,得到形状是(n,n)的结果,不符合我们的需求。我们想要的损失形状是(n,1),所以必须要使用reshape函数(y.reshape(y_hat.shape))把y从一维(n,)变为二维(n,1)。
- 如果样本个数不能被批量大小整除,
data_iter函数的行为会有什么变化?
答:如果样本个数不能被整除,在epoch中的最后一个Batch的样本个数不到batchsize
4.线性回归的简洁实现
在过去的几年里,出于对深度学习强烈的兴趣,许多公司、学者和业余爱好者开发了各种成熟的开源框架。这些框架可以自动化基于梯度的学习算法中重复性的工作。
在 上一部分中,我们只运用了:
(1)通过张量来进行数据存储和线性代数;
(2)通过自动微分来计算梯度。
(通过使用深度学习框架来简洁地实现线性回归模型)
4.1 生成数据集
import numpy as np
import torch
from torch.utils import data#引入处理数据的模块
import d2l
#人工生成数据
def synthetic_data(w, b, num_examples):
"""生成 y = Xw + b + 噪声。"""
X = torch.normal(0, 1, (num_examples, len(w)))#
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)#加入一个随机噪音
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)
4.2 读取数据集
我们可以[调用框架中现有的API来读取数据]。
我们将features和labels作为API的参数传递,并通过数据迭代器指定batch_size。
此外,布尔值is_train表示是否希望数据迭代器对象在每个迭代周期内打乱数据。
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器。"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
4.3 定义模型
当我们在上节中实现线性回归时,我们明确定义了模型参数变量,并编写了计算的代码,这样通过基本的线性代数运算得到输出。
但是,如果模型变得更加复杂,且当你几乎每天都需要实现模型时,你会想简化这个过程。
这种情况类似于为自己的博客从零开始编写网页。
做一两次是有益的,但如果每个新博客你就花一个月的时间重新开始编写网页,那并不高效。
对于标准深度学习模型,我们可以[使用框架的预定义好的层]。这使我们只需关注使用哪些层来构造模型,而不必关注层的实现细节。
我们首先定义一个模型变量net,它是一个Sequential类的实例。Sequential类将多个层串联在一起。当给定输入数据时,Sequential实例将数据传入到第一层,然后将第一层的输出作为第二层的输入,以此类推。
在下面的例子中,我们的模型只包含一个层,因此实际上不需要Sequential。
但是由于以后几乎所有的模型都是多层的,在这里使用Sequential会让你熟悉“标准的流水线”。
回顾 1.4.1中的单层网络架构,这一单层被称为全连接层(fully-connected layer),因为它的每一个输入都通过矩阵-向量乘法得到它的每个输出。
在PyTorch中,全连接层在Linear类中定义。
值得注意的是,我们将两个参数传递到nn.Linear中。
第一个指定输入特征形状,即2,第二个指定输出特征形状,输出特征形状为单个标量,因此为1。
from torch import nn# `nn` 是神经网络的缩写
net = nn.Sequential(nn.Linear(2, 1))#输入维度为2,输出维度为1,放在Sequential容器里面
#Sequential是一个有序的容器,神经网络模块将按照传入构造器的顺序依次被添加到计算图中执行
#同时以神经网络模块为元素的有序字典也可以作为传入参数。
4.3.1 初始化模型参数
在使用net之前,我们需要初始化模型参数。
如在线性回归模型中的权重和偏置。
深度学习框架通常有预定义的方法来初始化参数。
在这里,我们指定每个权重参数应该从均值为0、标准差为0.01的正态分布中随机采样,偏置参数将初始化为零。
正如我们在构造nn.Linear时指定输入和输出尺寸一样,现在我们能直接访问参数以设定它们的初始值。
我们通过net[0]选择网络中的第一个图层,然后使用weight.data和bias.data方法访问参数。
我们还可以使用替换方法normal_和fill_来重写参数值。
net[0].weight.data.normal_(0, 0.01)#使用正态分布替换data的值
net[0].bias.data.fill_(0)#将偏差设置为0
tensor([0.])
4.3.2 定义损失函数
[计算均方误差使用的是MSELoss类,也称为平方
L
2
L_2
L2范数]。
默认情况下,它返回所有样本损失的平均值。
loss = nn.MSELoss()
4.3.3 定义优化算法
小批量随机梯度下降算法是一种优化神经网络的标准工具,
PyTorch在optim模块中实现了该算法的许多变种。
当我们(实例化一个SGD实例)时,我们要指定优化的参数(可通过net.parameters()从我们的模型中获得)以及优化算法所需的超参数字典。
小批量随机梯度下降只需要设置lr值,这里设置为0.03。
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
4.4 训练
通过深度学习框架的高级API来实现我们的模型只需要相对较少的代码。
我们不必单独分配参数、不必定义我们的损失函数,也不必手动实现小批量随机梯度下降。
当我们需要更复杂的模型时,高级API的优势将大大增加。
当我们有了所有的基本组件,[训练过程代码与我们从零开始实现时所做的非常相似]。
回顾一下:在每个迭代周期里,我们将完整遍历一次数据集(train_data),
不停地从中获取一个小批量的输入和相应的标签。
对于每一个小批量,我们会进行以下步骤:
- 通过调用
net(X)生成预测并计算损失l(前向传播)。 - 通过进行反向传播来计算梯度。
- 通过调用优化器来更新模型参数。
为了更好的衡量训练效果,我们计算每个迭代周期后的损失,并打印它来监控训练过程。
num_epochs = 3 #设置迭代次数
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)#预测值和真实值
trainer.zero_grad()#将梯度清零
l.backward()#通过进行反向传播来计算梯度
trainer.step()#进行模型的更新
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
epoch 1, loss 0.000322
epoch 2, loss 0.000095
epoch 3, loss 0.000097
下面我们[比较生成数据集的真实参数和通过有限数据训练获得的模型参数]。
要访问参数,我们首先从net访问所需的层,然后读取该层的权重和偏置。
正如在从零开始实现中一样,我们估计得到的参数与生成数据的真实参数非常接近。
w = net[0].weight.data
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print('b的估计误差:', true_b - b)
w的估计误差: tensor([-1.3533e-03, -2.1935e-05])
b的估计误差: tensor([-0.0015])
4.5 小结
- 我们可以使用PyTorch的高级API更简洁地实现模型。
- 在PyTorch中,
data模块提供了数据处理工具,nn模块定义了大量的神经网络层和常见损失函数。 - 我们可以通过
_结尾的方法将参数替换,从而初始化参数。
答:应该把学习率除以batch_size,因为默认参数是’mean’,换成’sum’需要除以批量数,一般会采用默认,因为这样学习率可以跟batch_size
4.6 思考题及其解答
- 如果我们用
nn.MSELoss(reduction='sum')替换nn.MSELoss(),为了使代码的行为相同,需要怎么更改学习速率?为什么?
答:应该把学习率除以batch_size,因为默认参数是’mean’,换成’sum’需要除以批量数,一般会采用默认,因为这样学习率可以跟batch_size解耦
- 查看PyTorch文档,了解其提供了哪些损失函数和初始化方法。用Huber损失代替原损失。
| 损失函数 | 名称 | 适用场景 |
|---|---|---|
| torch.nn.L1Loss() | 平均绝对值误差损失 | 回归/简单的模型 |
| torch.nn.MSELoss() | 均方误差损失 | 回归/数值特征不大/问题维度不高 |
| torch.nn.SmoothL1Loss() | 平滑的L1损失 | 回归/当特征中有较大的数值/适合大多数问题 |
| torch.nn.CrossEntropyLoss() | 交叉熵损失 | 多分类 |
| torch.nn.NLLLoss() | 负对数似然函数损失 | 多分类 |
| torch.nn.BCELoss() | 二分类交叉熵损失 | 二分类 |
| torch.nn.NLLLoss2d() | 图片负对数似然函数损失 | 图像分割 |
| torch.nn.KLDivLoss() | KL散度损失 | 回归 |
| torch.nn.MarginRankingLoss() | 评价相似度的损失 | 计算两个向量之间的相似度 |
| torch.nn.MultiLabelMarginLoss() | 多标签分类的损失 | 多标签分类 |
| torch.nn.SoftMarginLoss() | 多标签二分类问题的损失 | 多标签二分类 |
- 你如何访问
net[0].weight的梯度?
print(net[0].weight.grad)
















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











