








abstract
在多目标粒子群优化(MOPSO)中,单个粒子的个人最佳解决方案(pBest)和整个群体的全局最佳解决方案(gBest)的选择策略是平衡粒子群收敛性和多样性的两个关键挑战。迭代过程中的算法。现有文献中的许多选择策略都强调单独粒子的个体特征,而不是整个群体的集体特征。本文提出了一种基于新定义的虚拟代距离指标的新颖 gBest 选择策略,该策略是根据给定精英档案的几何形状制造的虚拟帕累托前沿计算出来的,用于选择最合适的帕累托最优解作为gBest 在全面收敛和多样性贡献方面提高了 MOPSO 的搜索效果和效率。此外,还设计了一种基于不同迭代中进化状态的自适应pBest选择策略,用于从每个粒子的个人档案中识别出更合适的pBest,以自适应地增强开发或探索能力。实验结果表明,采用新的 gBest 和 pBest 选择策略的 MOPSO 在 DTLZ、F、WFG 和 ZDT 系列基准问题上优于十种最先进的竞争算法。此外,还以移动地震监测站选址为例,说明了该算法在实际应用中的有效性。
1. Introduction
多目标优化问题(MOP)广泛存在于许多现实应用中,例如犯罪预测[1]、特征选择[2]、绿色煤炭生产[3]等。在 MOP 中,目标可能同时相互冲突。因此,通常使用一组解而不是单个解作为 MOP 的最佳解,称为 Pareto 最优解。在过去的二十年中,人们提出了许多多目标优化进化算法(MOEA)来成功解决 MOP,因为进化算法(EA)的本质是基于群体的搜索技术,并行生成多个解决方案。现有的 MOEA 根据其解决问题的策略可以大致分为三类。第一类是基于Pareto支配关系或其松弛变体的Pareto-based MOEA,例如基于Pareto支配关系的NSGA-II [4]和基于相对非支配矩阵的MaOEA-RNM [5]。第二类是基于分解的 MOEA,通过分而治之的策略,它将多目标优化问题分解为一组要解决的单目标优化问题(SOP),例如 MOEA/D [6]、DMaOEA-eC [7] 和 NSGA-III [8]。最后一类是基于指标的 MOEA,它通过收敛性和多样性方面的综合指标来指导搜索过程,例如基于超体积(HV)[10]指标的 HypE [9] 和 MaOEA-IGD [11] ] 基于倒代距离(IGD)[12]指标。
粒子群优化(PSO)是一种重要且流行的基于群体的随机搜索进化算法范式,由Eberhart和Kennedy于1995年根据社会心理学模拟动物行为而提出[13]。由于PSO概念简单、收敛速度快、易于实现等优点,在求解SOP方面非常流行,但由于缺乏一些机制来维护一组Pareto解和选择全局最佳解,因此不能直接用于优化MOP。整个群体的(gBest)和来自难以区分的帕累托个体的单个粒子的个人最佳解决方案(pBest)[14]。在扩展 PSO 来解决 SOP 中的 MOP 时,需要解决两个关键挑战。第一个挑战是如何选择和存储非支配解以维持一组收敛且多样化的帕累托最优解。在多目标PSO(MOPSO)中,gBest通常是从外部精英档案中选择的,因此MOPSO的收敛性和多样性在很大程度上取决于档案的收敛性和多样性。对于MOPSO来说,如果迭代过程中收敛过快,可能会出现早熟现象,导致陷入局部最优。在这种情况下,算法得到的非支配解集的多样性会很差,因为个体会聚集到一些局部区域。然而,如果 MOPSO 的收敛速度太慢,则可能会失去在迭代结束时找到近似帕累托前沿 (PF) 的能力。因此,与 MOEA 一样,平衡 MOPSO 中档案的收敛性和多样性非常重要。第二个挑战是如何为单个粒子选择合适的 pBest 以及为整个群体选择合适的 gBest。 MOPSO 中 pBest 和 gBest 的作用是协同确定每个粒子的适当搜索方向。因此,应该仔细设计选择pBest和gBest的策略,以引导群体有效且高效地找到一组收敛且多样化的Pareto前沿。
Coello Coello 和 Lechuga [15] 是第一个推动 PSO 从 SOP 中解决 MOP 的人。从那时起,随着 MOEA 的进步,越来越多的 MOPSO 版本被提出来提高基于 MOPSO 的算法的性能。作为MOEA的一个分支,根据上述MOEA中的分类标准,MOPSO也可以分为基于Pareto、基于分解和基于指标的MOPSO三类,这三类的例子可以相应地取为基于松弛支配关系的 OMOPSO [16],基于分解策略的 MPSO/D [17] 和 dMOPSO [18],基于指标的 R2HMOPSO [19] 和 MOPSOhv [20]。尽管这些 MOPSO 部署了各种策略来从不同角度提高其性能,但仍然存在一些问题,限制了它们在解决 MOP 方面的搜索潜力。首先,pBest选择策略在大多数MOPSO中没有得到足够的重视。几乎所有的MOPSO都简单地根据其新解与历史pBest之间的支配关系来确定每个粒子的pBest,例如MOEA/D-COPSO[21]、NMPSO[22]和AMOPSO/ESE[23]。这些策略没有考虑群体的进化状态,这导致在为粒子选择合适的 pBest 时忽略进化信息。其次,在基于指标的MOPSO中,所选指标在指导群体进化过程方面存在一定的局限性。例如,MOPSOhv中的HV指标同时考虑了非支配解集的收敛性和多样性,但其计算成本太昂贵而难以承受。虽然R2HMOPSO中的R2指标[24]可以以合理的计算成本估计非支配解集,但它需要提前一组合理分布内的凸权重来控制存档的均匀性。由于维数灾难,设置这组凸权重的难度会随着目标数量的增加而急剧上升[25]。
生成距离(GD)[26]和IGD作为简单有效的指标,可以以较低的计算复杂度评估Pareto解集。然而,当这两个指标应用于基于指标的 MOPSO 时,需要 MOP 的真实帕累托前沿 (tPF) 作为参考集。在大多数实际应用中,tPF 是预先未知的。为了发挥IGD或基于GD的指标的优点并克服提前准备tPF的不足,可以根据MOPSO的档案动态构造MOP的虚拟Pareto前沿(vPF)来近似替换tPF,从而构建一个类似 IGD 或 GD 的 MOPSO [11 25]。然而,如果引用的粒子在档案中分布不均匀,则可能会构建 MOP 的不准确 vPF。
为了解决上述问题,本文提出了一种基于vPF的自适应MOPSO,以更好地平衡群体的多样性和收敛性。在 gBest 选择方面,提出了一种新方法来构造 vPF 作为 MOP 的 tPF 的替代方案。 vPF构建完成后,可以利用GD指标对存档中的解进行排序,并从排序靠前的解中选择gBest。在pBest选择方面,根据粒子的当前位置和历史信息提出了自适应pBest选择策略。此外,采用一组参考向量来保持档案的多样性。利用新的自适应方法有望构造出更合理的vPF,并利用新的pBest选择策略来选择更合适的pBest来指导粒子的搜索过程。
本文的其余部分安排如下。在第 2 节中,现有 MOPSO 的一些关键策略将作为相关工作进行简要回顾。所提出的算法(MOPSO/vPF)的细节将在第3节中详细描述。在第4节中,通过与其他MOEA的比较和分析,对MOPSO/vPF的性能进行了实验验证。此外,第4节还展示了移动地震监测站选址的案例研究,以验证所提出的算法在实际应用中的优异性能。本文的最终结论在第 5 节中做出。
2. Related works
本节将介绍一些关于 MOP 的预备知识以及 MOPSO 的相关工作作为背景。首先,2.1 小节将给出 MOP 的一些基本定义。然后,关于如何选择适当的 pBest 和 gBest 以及如何维护收敛和多样化的档案的两个挑战将分别在第 2.2 和 2.3 节中进行研究。最后,作为近年来流行的一种MOPSO,基于指标的MOPSO将在2.4小节中进行额外回顾。
2.1. Basic definitions
许多实际的优化问题常常涉及多个相互冲突的目标同时进行优化,这些目标被称为MOP。一般来说,涉及 m 个相互冲突的目标的 MOP 可以表述为

其中 x = ( X 1 , X 2 , ⋯ , X n ) T {\boldsymbol{x}}=\left(X_{1},X_{2},\cdots,X_{n}\right)^{\mathrm{T}} x=(X1,X2,⋯,Xn)T 是决策空间 s ⊆ R n \mathbf{s}\subseteq\mathbb{R}^n s⊆Rn 中的决策向量, F ( x ) ∈ R m \mathbf{F}(\mathbf{x})\in\mathbb{R}^m F(x)∈Rm 表示目标向量。
由于MOP的复杂性,传统的数学方法很难获得解析解。 MOEA 有助于迭代逼近 Pareto 最优前沿。一般来说,给定任意两个向量 x , y ∈ S x, y \in S x,y∈S 及其对应的目标向量 F ( x ) , F ( y ) ∈ R m F(x),F(y)\in\mathbb{R}^{\mathfrak{m}} F(x),F(y)∈Rm,对于最小化问题, x x x Pareto 支配 y y y(表示为 x ≻ y ) i f f ∀ i , f i ( x ) ≤ f i ( y ) a n d ∃ j ∈ { 1 , 2 , ⋯ , m } , f j ( x ) < f j ( y ) x\succ y)\mathrm{~iff~}\forall i,f_i(\boldsymbol{x})\leq f_i(\boldsymbol{y})\mathrm{~and~}\exists j\in\{1,2,\cdots,\boldsymbol{m}\},f_j(\boldsymbol{x})<f_j(\boldsymbol{y}) x≻y) iff ∀i,fi(x)≤fi(y) and ∃j∈{1,2,⋯,m},fj(x)<fj(y)。如果不存在 y ≻ x y\succ x y≻x 的 y ∈ S y \in S y∈S,则决策向量 x ∈ S x \in S x∈S 是帕累托最优。决策空间中所有Pareto最优解的集合称为Pareto集,其在目标空间中的图像称为Pareto前沿。
2.2. Selection strategy of pBest and gBest
在 MOPSO 中,粒子的运动方向由该粒子的 pBest 和整个群体的 gBest 共同决定。 pBest可以增强粒子的探索能力,而gBest可以增强群体的开发能力。因此,选择合适的pBest和gBest可以有效提高MOPSO的性能。本小节将简要回顾一下近年来流行的MOPSO中pBest和gBest的选择策略。
在现有的MOPSO中,pBest的选择策略仅仅依赖于Pareto支配关系。也就是说,如果新找到的解决方案主导了当前的 pBest,则该新解决方案将成为其新的 pBest。如果新解和使用的 pBest 是非支配的,则算法将保持使用的 pBest 不变或从这两个解中随机选择一个作为即将到来的 pBest。一般来说,近年来提出的MOPSO如MOEA/D-COPSO[21]、NMPSO[22]和AMOPSO/ESE[23]几乎都采用这种策略来选择它们的pBest。该pBest选择策略仅考虑两个候选pBest之间的支配关系,而忽略了粒子的位置信息和群体的进化状态。两个非支配 pBest 可能位于不同区域,因此从两个候选 pBest 中选择的随机 pBest 可能会导致粒子陷入振荡搜索过程。
在基于松弛支配关系的MOPSO中,最简单、最直观的gBest选择策略是将所有非支配解作为群体的候选gBest,这会导致gBest过多而降低选择压力。这个问题在高维空间中会特别明显,因为由于高维目标空间中的不可区分性,大多数解都是非支配的[27]。为了解决这个问题,引入了一个新的指标来维护大小有限的存档。例如,OMOPSO [16] 中引入了拥挤距离(CD)[4],以维护具有预定义大小的多样化存档。优先考虑那些CD贡献值较高的非支配解,从而选择出更好的gBest。
在基于分解的MOPSO中,选择gBest的方式与SOPSO中的相同,因为一个MOP被划分为多个SOP。选择具有最佳适应度值的解作为整个群体的gBest,例如dMOPSO [18]和SDMOPSO [28]。
在基于指标的MOPSO中,根据所选指标计算档案中每个非支配解的贡献值,贡献值最高的解将被选择为群体的gBest。例如,存档中 R2 贡献值最高的解决方案被选为 R2HMOPSO 中的 gBest [19]。同样,存档中 HV 贡献值最高的解决方案被选为 MOPSOhv 中的 gBest [20]。
综上所述,MOPSO 中的 gBest 选择策略得到了足够的重视,以提高算法的性能。然而,大多数MOPSO通常忽略pBest选择策略,导致群体的探索能力下降。针对这一问题,本文提出了一种基于群体进化状态以及每个粒子当前位置和历史信息的新pBest选择策略,以选择更合适的粒子pBest。
2.3. Maintenance strategy of archive
在 MOPSO 中,非支配解被存储在档案中以保留精英解。一般来说,档案的大小是有限的,因为非支配解的数量会随着群体迭代的进行而迅速增加。如果所有这些非支配解都存储在档案中,计算成本将太高而难以承受。因此,需要一个维护策略来确定当没有更多空间来存储新发现的非支配解时,哪些解将保留在存档中。为了获得高质量的档案,维护策略应同时考虑档案的收敛性和多样性。本小节将简要总结近年来提出的 MOPSO 档案维护策略。
基于指标的策略是 MOPSO 中维护档案的常见做法。归档中的所有非支配解按照其对指标的贡献值进行排序,贡献值较高的解将优先保留在归档中。 MaOPSO-CA[29]和MOPSOhv[20]都采用这种方法来维护他们的档案。然而,这种方法的有效性很大程度上依赖于所选择的指标,如果评估指标本身存在缺陷,可能会显着降低算法的性能。
维护档案的另一种常见做法是自适应网格方法。该方法将可行区域划分为若干个相邻且大小相等的网格。如果多个解决方案位于同一网格中,则其中一些解决方案将被删除以保持存档的多样性。 PccsAMOPSO[14]和AGA-MOPSO[30]是管理其档案的代表。然而,当目标数量增加时,这种方法的计算复杂度会迅速增加[31]。
参考向量法是近年来为了维护档案而发展起来的。使用一组预定义且分布良好的向量作为参考来维护多样化且统一的档案。该方法广泛应用于 MaOPSO/vPF [25] 和 IDMOPSO [32]。这种方法的缺点是维护有效性很大程度上取决于待解决的 MOP PF 的几何形状[33]。
在趋同性和多样性方面维护精致的档案是 MOPSO 的一个重要方面。参考向量法因其优异的性能而备受关注。与自适应网格方法相比,它具有较低的计算复杂度。与基于指标的策略相比,它的应用不会因为忽略附加指标的选择而受到限制。此外,参考向量法有利于多样性保持。基于以上分析,本文选择自适应参考向量法来改进档案维护策略。
2.4. Indicator-based MOPSOs
在基于指标的MOPSO中,采用指标来评估档案中的解决方案,评估结果将用于选择gBest或维护档案。本小节将简要回顾近年来提出的基于指标的 MOPSO。
李等人。提出了一种新的基于指标的MOPSO(R2HMOPSO)[19],采用R2指标来保持档案的多样性。在R2HMOPSO中,计算档案中每个解对R2指标(也称为CR2)的贡献值来对Pareto解进行排序,CR2较差的解将被丢弃在档案之外。虽然这种方法增加了档案的多样性,但随着变量和目标数量的增加,设置一组合理的凸权重变得越来越困难[25]。
Garcia 等人将 HV 指标引入 MOPSOhv [20] 中的 MOPSO。 MOPSOhv 根据对 HV 的贡献值确定将哪些解决方案保存在存档中。此外,MOPSOhv还根据存档中解决方案的贡献值选择了合适的pBest和gBest。 HV作为同时评价档案多样性和收敛性的指标,可以有效指导群体的搜索过程。但HV的计算复杂度会随着目标数量的增加而急剧增加[34]。即使蒙特卡罗采样方法可以作为HV计算的简化策略,其计算复杂度仍然很高,影响迭代效率,这是MOPSOhv的主要缺点。
吴等人。提出了一种基于虚拟帕累托前沿(MaOPSO/vPF)的MOPSO[25],它借助根据存档自适应构建的vPF来引导群体。在MaOPSO/vPF中,构建了位于所有保留解的“前面”的超平面,用于对一组参考点进行采样以组成vPF。这些采样参考点用于计算每个解决方案对虚拟 IGD 的贡献值。选择贡献最大的非支配解作为群体的 gBest。同时,利用这组参考点和理想点进行归档维护。在MaOPSO/vPF中构建vPF的方法取得了一定的效果。然而,该方法只能构造均匀超平面。对于一些具有复杂PF的优化问题,例如非均匀或不连续的PF,该方法会导致较大的估计误差。
在这些基于指标的 MOPSO 中,指标值可用于维护档案或/和选择适当的 pBest 和 gBest。但正如上面分析的那样,这些算法都或多或少存在着局限性,比如参数设置困难、计算复杂度高以及指标本身的缺陷等。为了解决这些问题,提出了一种新的方法来构造更准确的vPF。构建好的vPF将用于计算档案的虚拟GD值(vGD),从而维护档案并选择gBest。这里使用 GD 而不是 IGD,因为 IGD基于绩效的评估在很大程度上取决于参考点的规模[35]. 然而,构建太多的参考点会增加算法的计算复杂度。
3. Proposed MOPSO/vPF
如第2节所述,基于指标的MOPSO在实际应用中经常遇到高计算复杂度和参数设置的困难。此外,在大多数 MOPSO 的设计中,pBest 的精心选择策略被不合理地忽略。这里,将根据当前档案制作一个vPF,找出虚拟指标vGD,从而选择gBest并维护更好的档案。提出了一种基于 vPF 的自适应 MOPSO(缩写为 MOPSO/vPF)来应对这些挑战。 MOPSO/vPF 的框架如图 1 所示。在每次迭代中,vPF 都是根据档案的几何结构自适应构建的。此后可以根据构建的 vPF 和当前档案计算 vGD 指标。然后根据 vGD 在存档和 vPF 之间对存档进行排序,以选择 gBest。同时,根据每个粒子的当前位置和历史信息选择pBest。接下来,每个粒子的速度和位置在新的pBest和gBest的指导下更新。最后,档案被更新,群进入下一次迭代。 MOPSO/vPF 的关键组件将在以下小节中详细描述。

3.1. Archive geometry judgement and vPF construction
在提出的MOPSO/vPF中,构建vPF的第一步是判断档案的几何形状。翔等人。文献[36]提出了一种判断档案几何形状的方法,按照以下步骤进行。首先,计算原点到归一化超平面 ∑ i = 1 M f i = 1 \sum_{i=1}^{M}f_{i}=1 ∑i=1Mfi=1 的距离,并将其表示为 d ^ \hat{d} d^。那么从档案到向量 N = ( 1 , 1 , ⋯ , 1 ) T \mathbf{N}=\left(1,1,\cdots,\mathbf{1}\right)^{\mathrm{T}} N=(1,1,⋯,1)T 的 M 个最近点选择来计算这 M M M个点到原点的平均距离 d ˉ \bar{d} dˉ 点,其中 M 代表 MOP 中的目标数量。最后,档案的几何形状可以通过 d ^ \hat{d} d^和 d ˉ \bar{d} dˉ的比率来确定。当存档中的解均匀分布时,可以通过该方法估计精确的几何形状。但当大部分解聚集在档案边界时,该方法的判断结果将不足以准确地构造出良好的vPF。因为当解全部集中在边界处时, d ˉ \bar{d} dˉ的值将趋近于1,而 d ^ \hat{d} d^将小于或等于1。在这种情况下,该方法的判断结果总是会优先于凹形。这种情况的一个具体例子如图2所示,其中子图2(a)和(b)分别显示了当SMPSO[38]在ZDT2和ZDT4上进入第75代时档案中粒子的分布。子图 2 © 是这两种情况的简化。

为了弥补几何判断不准确的缺点,提出了一种利用平均值 d ˉ ⊥ \bar{d}_{\perp} dˉ⊥的改进方法。从这 M 个点到向量 N 的投影,以替换为平均距离 d ˉ \bar{d} dˉ 。改进方法的具体步骤如算法1所示。首先,第1-3行进行准备工作,如对解进行归一化、构造向量N和设置原点Z。然后是距离 d ^ \hat{d} d^和平均投影长度 d ˉ ⊥ \bar{d}_{\perp} dˉ⊥分别在第 4-9 行计算。最后,第 10 行计算比率 q,用于档案的几何判断(第 11-17 行)。根据文献[36],第11行 q 1 q_1 q1和第13行 q 2 q_2 q2的值分别设置为0.9和1.1。为了更直观地解释比率 q 与档案几何形状之间的关系,双目标情况下确定档案几何形状的图如图 3 所示,其中子图 3(a)、(b )和(c)分别显示了对凹存档、线性存档和凸存档的响应情况。与文献[27]和[36]等其他判断档案几何形状的方法相比,新提出的方法使用档案中解到向量N(表示为 d ˉ ⊥ ) \bar{d}_{\perp}) dˉ⊥) 来代替到存档中的原点(表示为 d ˉ \bar{d} dˉ)的解平均距离. 通过这一改进,无论 MOP 的 PF 是凸还是凹,判断结果将不再受解位置的影响。


判断出档案的几何形状后,可以根据判断结果构造vPF。需要注意的是,构建vPF的过程是在归一化空间中进行的。不失一般性,每个目标 f i ( i = 1 , 2 , ⋯ , M ) f_{i}(i=1,2,\cdots,M) fi(i=1,2,⋯,M) 就是找到它的最小值。
档案的几何形状可以分为线性和非线性两种情况。非线性情况可以进一步区分为凸情况和凹情况。当档案几何形状为线性时,构造平面 ∑ i = 1 M f i = 1 \sum_{i=1}^Mf_i=1 ∑i=1Mfi=1,然后沿矢量 N = ( 1 , 1 , ⋯ , 1 ) T {\boldsymbol{N}}=\left(1,1,\cdots,1\right)^{\mathrm{T}} N=(1,1,⋯,1)T的相反方向移动, 直到存档中没有解位于原点和平面之间。之后,可以通过Das和Dennis的方法[39]在移动平面上均匀地采样一组点,称为vPF,这是对均匀分布参考点进行采样的最流行的方法。 M 个客观问题中的参考点 H 的数量由 H = C M + a − 1 M − 1 H=C_{M+a-1}^{M-1} H=CM+a−1M−1 给出,其中 a 代表采样密度。在MOPSO/vPF中,根据文献[6]将a设置为25。
当档案几何结构为非线性时,采用二次曲面作为vPF的几何形式,以降低计算复杂度。在这种情况下,需要档案的两个几何信息“深度”和“宽度”来计算二次曲面的解析表达式。首先,找到距离向量N最近和最远的M个点,记为
p
1
n
,
p
2
n
,
⋯
,
p
M
n
p_{1}^{n},p_{2}^{n},\cdots,p_{M}^{n}
p1n,p2n,⋯,pMn 和
p
1
f
,
p
2
f
,
⋯
,
p
M
f
p_{1}^{f},p_{2}^{f},\cdots,p_{M}^{f}
p1f,p2f,⋯,pMf 。然后计算这两组点到向量N的投影长度,记为
d
1
n
,
d
2
n
,
⋯
,
d
M
n
d_{1}^{n},d_{2}^{n},\cdots,d_{M}^{n}
d1n,d2n,⋯,dMn 和
d
1
f
,
d
2
f
,
⋯
,
d
M
f
d_{1}^{f},d_{2}^{f},\cdots,d_{M}^{f}
d1f,d2f,⋯,dMf 分别。因此,档案的深度和宽度可以表示为

图4示出了双目标情况下计算档案深度和宽度的示例。深度和宽度分别由紫色和绿色实线表示。

获得档案的深度和宽度后,需要确定基准面的位置。当档案几何形状为凸形时,基准面位置的确定方法与线性情况相同。即首先构造超平面 ∑ i = 1 M f i = 1 \sum_{i=1}^{M}f_{i}=1 ∑i=1Mfi=1,然后沿着向量N的相反方向移动,直到原点与平面之间没有档案中的解为止。此时平面的解析公式应为 ∑ i = 1 M f i = a ( 0 < a < 1 ) \sum_{i=1}^Mf_i=a(0<a<1) ∑i=1Mfi=a(0<a<1)。如果基于该平面构造二次曲面,则曲面的宽度可以表示为

需要注意的是,当档案的几何形状是凸的时,没有解可以位于理想点处(如果是这样,则该解将支配档案中的所有其他解)。在这种情况下,存档的深度必须小于其宽度。因此,根据这个深度对基准平面上的点进行拉伸变换时,必须有深度vPF < 宽度vPF。这样就可以保证拉伸后所有的点都在第一个象限内。
当档案的几何形状为凹形时,构造步骤与凸形情况下的构造步骤类似,但有两点不同。第一种是平面沿着矢量 N = ( 1 , 1 , ⋯ , 1 ) T {\boldsymbol{N}}=\left(1,1,\cdots,1\right)^{\mathrm{T}} N=(1,1,⋯,1)T 的反方向移动。第二个是该平面的解析公式应为 ∑ i = 1 M f i = 1 − d e p t h A r c h i v e × M . \sum_{i=1}^Mf_i=1-depth_{Archive}\times\sqrt{M}. ∑i=1Mfi=1−depthArchive×M. 。请注意,当存档的几何形状为凹时,不会有任何解位于最低点(如果是这样,则该解将受到存档中所有其他解的支配)。因此,移动的平面也必须位于第一个正交平面内。同时,由于 w i d t h v P F width_{vPF} widthvPF明显小于 w i d t h A r c h i v e , d e p t h v P F width_{Archive},depth_{vPF} widthArchive,depthvPF 也必须小于深度存档 d e p t h A r c h i v e depth_{Archive} depthArchive, 保证了基准平面上的点在挤压变换后不会与平面 ∑ i = 1 M f i = 1 \sum_{i=1}^Mf_i=1 ∑i=1Mfi=1 相交。

基准平面的位置确定后,可以从基准平面上均匀采样一组点,记为Q。构造vPF的步骤如算法2所示。首先,第1行计算Q的几何中心c。然后,根据档案的几何形状确定Q中点 p i p_i pi的移动方向,以及 p i p_i pi的移动长度根据 p i p_i pi 与几何中心 c 之间的欧氏距离确定。当 Qare 中的所有点都移出后,vPF 就构建成功了。在双目标情况下构造vPF的例子如图5所示,其中子图5(a)、(b)和©分别对应于线性、凹和凸的情况。在双目标情况下,当档案是线性的时,vPF 是垂直于向量 N 的直线。相应地,当档案为凹或凸时,vPF为抛物线,其准线为向量N,其几何形状与档案相同。

3.2. Selection strategy for gBest and pBest
MOPSO/vPF的另一个重要方面是gBest和pBest的选择策略。更合适的gBest和pBest可以更好地平衡群体的探索和利用能力。算法3提出了基于vGD指标的gBest选择策略。构建的vPF将用于根据存档中每个解决方案对vPF的贡献来计算vGD(第1行)。存档中贡献值最高的前 10% Pareto 解决方案将进入群体下一代 gBest 的候选集,以增加群体的多样性(第 2-3 行)[37]。更新粒子速度时,将从候选集中随机选择一个解作为 gBest。 vGD的计算方法可表示为

其中X是通过算法获得的档案中的近似Pareto前沿,Y是精心设计的vPF,|X|代表集合X和中的元素数量, dist (x,Y) 是 Y 中与其最近点之间的距离,表示对 vGD 指标的贡献。

在迭代过程的早期阶段,应鼓励粒子探索那些未访问过的区域,相反,应在迭代后期通过执行精细搜索过程来引导粒子利用当前的最优值。如果将粒子与gBest之间的区域视为群体的探索区域,则应在迭代早期鼓励粒子尽可能远离该区域,反之,则应期望粒子到达该区域在迭代后期阶段尽可能快。最合理的策略是在粒子的速度和群体的 gBest 确定后,为不同迭代阶段的粒子选择不同的 pBest,以平衡开发和探索。
有两个因素影响 pBest 选择策略。第一个是粒子与其 pBest 之间的距离。 pBest 和粒子之间的距离决定了粒子在下一次迭代中移动的距离。距离粒子较远的 pBest 将引导粒子在下一次迭代中移开更远的距离。第二个因素是 gBest、粒子和 pBest 依次形成的角度。该角度决定了粒子在下一次迭代中移动的方向。角度越小,粒子向 gBest 移动所需的距离越短。如果将pBest的这两个因素一起考虑,则可选的pBest可以分为三类。第一类pBest的特点是距离更长、角度更大。这类pBest会引导粒子远离gBest,因此擅长探索。第二种pBest的特点是距离更长、角度更小。这种类型的pBest会引导粒子直接向gBest移动,因此可以很好地利用。第三种pBest可以说是距离较短。该候选 pBest 距离粒子太近,这限制了其对距粒子较短距离的探索和利用的影响。将该分类方法与 Pareto 支配相结合,算法 4 中可以设计一种新的 pBest 选择策略。当粒子找到新的候选 pBest(记为 p B e s t n e w \mathsf{pBest}_{\mathsf{new}} pBestnew)时,算法将首先判断 p B e s t n e w \mathsf{pBest}_{\mathsf{new}} pBestnew 与现有的 pBest 之间是否存在主导关系。 pBest(表示为 pBestold)。如果两个候选 pBest( p B e s t n e w \mathsf{pBest}_{\mathsf{new}} pBestnew 和 p B e s t o l d pBest_{old} pBestold)之间存在支配关系,则算法将根据支配关系确定谁将成为工作 pBest(第 1-4 行)。如果两个候选 pBest 之间不存在支配关系,算法首先计算两个 pBest 与粒子之间的距离(第 5-8 行)。然后,算法计算两个候选 pBest 以及粒子和 gBest 之间的角度(第 9-14 行)。随后,可以根据迭代的角度、距离和当前阶段为每个 pBest 赋予选择权重(第 15-30 行)。最后,采用轮盘赌选择算法从两个候选 pBest 中选择一个更好的一个作为下一次迭代中粒子的工作 pBest(第 31 行)。
在本小节中,MOPSO/vPF的gBest和pBest选择策略分别根据vGD指标和迭代状态设计。对于群体的每次迭代,存档中对 vGD 指标贡献值排名前 10% 的 Pareto 解被选为候选 gBest。每个粒子的pBest由粒子的相对位置、gBest和当前迭代状态决定。这种 gBest 和 pBest 选择策略有利于保持档案更好的收敛性和多样性,以平衡群体的探索和利用。
3.3. Maintenance strategy of archive
在提出的 MOPSO/vPF 中,帕累托支配关系和参考向量用于维护组织良好的档案。根据帕累托支配关系,将档案中的所有受支配解从档案中删除。如果现在档案的大小仍然大于算法预定义的最大大小,则将应用参考向量来修剪过满的档案,以最大化多样性。在MOPSO/vPF中,这组参考向量是根据3.1小节中构建的vPF自适应生成的。具体步骤如下。首先,存档中的所有非支配解都被归一化到 [ 0 , 1 ] M [0,1]^M [0,1]M 空间中。然后是一组分布均匀的构建参考向量来计算每个解与不同参考向量之间的距离。接下来,每个解与其最近的参考向量相关联。请注意,每个参考向量可能与多个解决方案相关联。所有关联解决方案中最近的一个将被添加到存档中。如果没有解与参考向量相关联,则将跳过该参考向量。将重复最后一步,直到存档已满。
3.4. Integration of MOPSO/vPF
MOPSO/vPF 的整个过程总结在算法 5 中。

初始群和存档是在第 1-3 行的初始化阶段生成的。重复以下步骤,直到迭代次数达到预定义的最大迭代次数。新群首先在第 5 行中通过其目标函数进行评估。然后在第 6 行使用维护策略生成新的存档。之后,在第 7 行根据新更新的存档构建 vPF,用于计算指标 vGD。适当的 gBest 和 pBest 在第 8 行中通过建议的选择策略进行更新,以动态平衡群体的收敛性和多样性。接下来,在第 9 行中更新每个粒子的速度和位置。最后,在第 10 行中应用多项式变异算子 [40] 来增加群体的多样性。需要注意的是,速度裁剪策略与在 SMPSO [38] 中。具体来说,MOPSO/vPF 中粒子的速度计算如下

其中w是惯性权重,r1和r2是[0, 1]范围内的两个均匀分布的随机数,c1和c2分别是控制全局和个人影响因素影响的具体参数。速度限幅因子
x
\text{x}
x 的计算公式为

其中
v
j
m
a
x
v_j^{\mathrm{max}}
vjmax 和
v
j
m
i
n
v_j^{min}
vjmin 分别是每个变量
j
j
j 的速度的上限和下限。此外,在评估每个粒子的适应度之前,MOPSO/vPF 采用多项式变异算子来增加群体的多样性。该运算符的表达式表示为

其中 r i r_i ri是0到1之间的随机数, η m \eta_{m} ηm 是突变分布指数。在MOPSO/vPF中, η m \eta_{m} ηm 的值设置为20,以保持与大多数带有多项式变异算子的MOEA的一致性。
到目前为止,基于 vGD 指标的 MOPSO/vPF 的所有组成部分都已分别讨论。在MOPSO/vPF中,提出了一种根据档案的几何形状构造更合理的vPF的新方法。新的vGD指标根据构造良好的vPF计算,以选择更合适的gBest。此外,还提出了一种新的pBest选择策略,根据群体当前的迭代状态自适应地为每个粒子选择更合适的pBest。
判断档案的几何形状时,需要根据算法1计算档案中每个解到向量N的距离,导致算法1的计算复杂度为O SðÞ,其中S为档案的大小。在MOPSO/vPF中,归档文件的大小与swarm的大小相同,即O SðÞ ¼ O NðÞ,其中N是swarm的大小。需要注意的是,MOPSO/vPF 中的 Das 和 Dennis 方法只需要调用一次。因此,其计算复杂度为O 1ðÞ。算法 2 的计算复杂度为 O HðÞ,其中 H 是 vPF 的大小,根据 [6],为 H = C M + 24 M − 1 H=\mathbb{C}_{M+24}^{M-1} H=CM+24M−1,其中 M 是目标数量。即,当目标数为2和3时,H值分别为26和351。 vGD的计算复杂度为 O ( S H ) O(SH) O(SH),因为需要根据算法3计算从档案中的所有点到vPF中对应点的距离以对解进行排序。如果目标数量不超过三个,则 H 可以被视为相对于 M 的常数。因此,算法3的计算复杂度可以认为是 O ( N ) O(N) O(N)。需要根据算法4计算pBest到粒子的距离以及gBest、粒子和pBest依次形成的角度,以比较pBest选择策略中旧的现有pBest和新的非支配解,因此总计算量算法 4 的复杂度为 O ( N ) O(N) O(N)。在每次迭代期间,算法1-4将轮流运行一次,因此MOPSO/vPF的计算复杂度为 O ( N × G × M ) O(N×G×M) O(N×G×M),其中G是最大生成数。

4. Experimental studies
在本节中,所提出的 MOPSO/vPF 将与四种最先进的 MOPSO(MPSO/D [17]、NMPSO [22]、SMPSO [38] 和 dMOPSO [18])进行比较,四种已知的 MOEA(MOEA/D [6]、AMOCSO [45]、NSGA-II [4] 和 NSGA-III [8]),以及两个基于 vPF 的 MOEA,称为 MaOEA-IGD [11] 和 MAOPSO/vPF [25] 。为了保证实验的有效性,一些广泛使用且具有挑战性的基准问题,即DTLZ1-7 [41]、F1-10 [42]、WFG1-9 [43]和ZDT1-4、6 [44],选择来比较所选算法的性能。 ZDT5 不包含在测试问题中,因为它是离散基准问题。表1列出了这些基准问题的一些重要信息,例如变量数量、目标数量、PF的几何形状和PF的样本大小。

本文采用广泛采用的指标IGD[12]和HV[10]来评价算法的性能,因为这两个指标可以综合评价算法获得的近似PF的收敛性和多样性。对于 HV 指标,所有目标值均通过 Pareto 的理想点和最低点进行归一化HV计算前的最优前沿,然后以参考点 (1.1, 1.1, …, 1.1) 计算 Pareto 解集的归一化 HV 值。为了公平起见,所有对比算法涉及的参数均按照原论文中的推荐值设置。具体参数值如表2所示,其中pc和pm分别是交叉概率和变异概率,gc和gm分别是模拟二元交叉(SBX)和多项式变异(PM)的分布指数。对于MOPSO,控制参数c1、c2(NMPSO中的c3)是1.5到2.5之间的随机数,MOPSO/vPF中它们的惯性权重x是0.5到0.9之间的随机数,以增加本文中群体的多样性,或者根据其原始论文,其他 MOPSO 中的值介于 0.1 和 0.5 之间。根据这些基于分解的算法,双目标问题中的群体大小设置为 100,三目标问题中的群体大小设置为 105。对于使用存档来保持近似 Pareto 最优解的算法 NMPSO、AMOCSO、MAOPSO/vPF 和 MOPSO/vPF,存档大小 S 设置为与群体大小 N 相同。所有问题的最大评估次数为设置为100000。每个算法对每个问题独立运行30次,以获得统计意义结果。所有实验结果均在具有 2.6 GHz CPU 和 16 GB 内存的 PC 上获得。所有算法和问题均采用 PlatEMO [45] 中提供的版本。

4.1. Competitive experiments with MOPSOs
DTLZ1-7、F1-10、WFG1-9和ZDT1-4、6上MOPSO/vPF和其他5种MOPSO的IGD和HV值的平均值和标准差分别如表3和表4所示。如果一个算法在 HV 指标上得分为零,则意味着该算法在迭代结束时无法收敛。需要说明的是,本文所有实验结果均采用Wilcoxon秩和检验,显着性水平为0.05[46]。表最后一行中的“+”、“””和““”分别表示结果明显优于、差于 MOPSO/vPF 和统计上与 MOPSO/vPF 相似。每行中每个基准问题的最佳平均值以粗体突出显示。
从表 3 和表 4 可以看出,MOPSO/vPF 在基准问题上的性能总体上比五个比较 MOPSO 的性能要好得多。在62个问题中,MOPSO/vPF获得了24个最佳IGD值和21个最佳HV值,是最优数最多的最佳算法。在DTLZ问题的IGD指标上,MOPSO/vPF的综合性能与MPSO/D、NMPSO和SMPSO相似。对于任何算法,一类问题的任何性能提升都会被另一类问题的性能所抵消[47]。与dMOPSO和MAOPSOvPF相比,MOPSO/vPF取得了明显的性能优势。特别是,与基于 vPF 的 MAOPSOvPF 相比,MOPSO/vPF 在所有 DTLZ 问题上都取得了更好的性能。对于问题F1-10,MOPSO/vPF的综合性能与MPSO/D相似,略优于NMPSO和SMPSO。对于dMOPSO和MAOPSOvPF来说,具有非常明显的优越性能。对于WFG问题,MOPSO/vPF总体上取得了良好的性能。除WFG1和WFG3外,MOPSO/vPF在其余WFG问题上均取得了最佳IGD值。对于 ZDT 问题,MOPSO/vPF 在 ZDT6 上取得了优异的性能,但在 ZDT4 上性能较差,在 ZDT1-3 上排名第二,因为其排名落后于 MPSO/D(在 ZDT1 和 2 上)和 SMPSO(在 ZDT1 和 2 上)和 SMPSO(在ZDT3)。总体而言,根据综合排名,MOPSO/vPF 仍然是 ZDT 问题中最好的 MOPSO。




在HV指标上,情况与IGD不同。对于DTLZ问题,MOPSO/vPF的性能与MPSO/D和SMPSO相似,略弱于NMPSO。然而,与dMOPSO和MAOPSOvPF相比,MOPSO/vPF仍然具有明显的性能优势。对于问题 F1-10,MOPSO/vPF 的性能领先于 NMPSO、SMPSO、dMOPSO 和 MAOPSOvPF。 MOPSO/vPF 在 F1-5 和 F10 上优于 MPSO/D,但在 F6-9 上比 MPSO/D 差。对于WFG问题,MOPSO/vPF与MPSO/D、SMPSO、dMOPSO和MAOPSOvPF相比仍然具有明显的优越性能。然而,MOPSO/vPF的性能弱于NMPSO。对于ZDT问题,MOPSO/vPF在HV上的性能优于IGD上的性能。 MOPSO/vPF在ZDT1、2和6上实现了最佳性能,在ZDT4上性能次优,在ZDT3上比SMPSO性能差。
从IGD和HV的对比实验结果可以得出结论,MOPSO/vPF比其他基于PSO框架的MOEA取得了更好的性能。它表明,3.2小节中提出的基于vPF的新gBest选择策略和自适应pBest选择策略可以为群体选择更有利的gBest和pBest。另外,与基于 vPF 的 MAOPSOvPF 相比,MOPSO/vPF 在几乎所有基准问题上都获得了更好的性能。说明了基于档案几何的新型自适应vPF构建策略的有效性。
为了进一步观察,MOPSO/vPF 和 WFG6 上的 5 个 MOPSO 获得的 30 次运行中的中值近似帕累托前沿如图 6 所示。可以看出,由所提出的 MOPSO/vPF 获得的非支配解集均匀分布在WFG6 的帕累托前沿。 MOPSO/vPF 获得的子图 6(k) 中近似 Pareto 前沿的分布是基于 PSO 的算法(例如 MPSO/D)获得的子图 6(a)-(e) 中最接近真实 Pareto 前沿的分布, NMPSO、SMPSO、dMOPSO 和 MAOPSOvPF。原因是基于档案几何的自适应vPF可以更好地逼近tPF,因此构造良好的vPF可以引导群体搜索尽可能接近tPF的近似PF。

4.2. Competitive experiments with other MOEAs
DTLZ1-7、F1-10、WFG1-9 和 ZDT1-4、6 上 MOPSO/vPF 和其他 5 个 MOEA 的 IGD 和 HV 值的平均值和标准差分别如表 5 和表 6 所示。与4.1小节相同,如果算法在HV指标上得分为零,则意味着它在迭代结束时无法收敛。
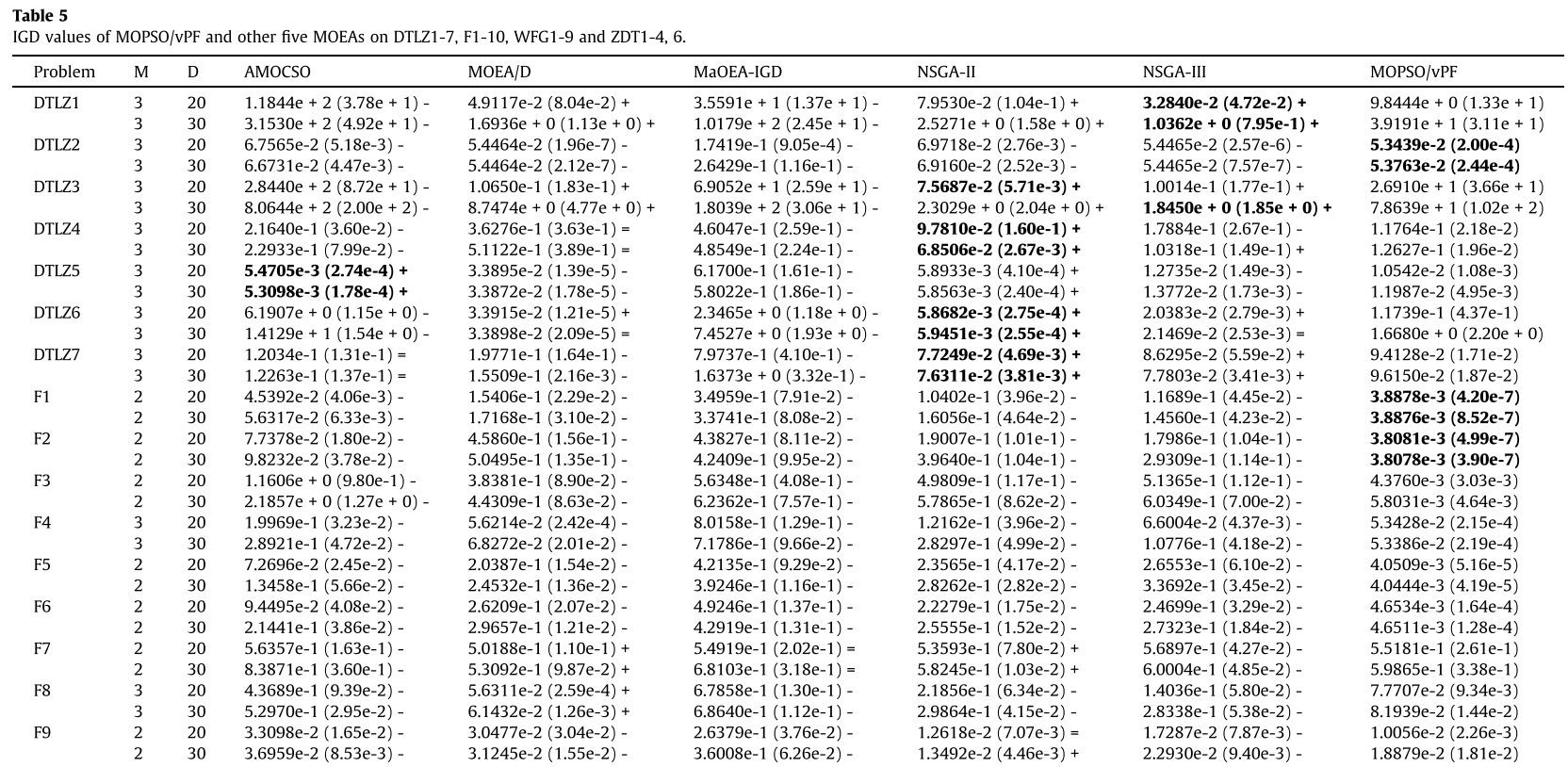



总体而言,MOPSO/vPF 在 IGD(62 个问题上的 27 个最佳性能值)和 HV(62 个问题上的 26 个最佳性能值)上实现了最佳性能值。因此,无论采用IGD还是HV作为评价指标,从综合性能来看,MOPSO/vPF都是最好的算法。与AMOCSO、MOEA/D和MAOEA-IGD相比,无论使用IGD还是HV作为评价指标,MOPSO/vPF在所有基准问题集上都具有明显的性能优势。与NSGA-II和NSGA-III相比,MOPSO/vPF在大多数基准测试套件上的综合性能仍然领先。具体来说,在 DTLZ 问题上,MOPSO/vPF 的 IGD 性能落后于 NSGA-II 和 NSGAIII。 DTLZ1 和 DTLZ3 都是多模态问题,分别具有 115 1 个和 1110 1 个局部前沿[48]。 MOPSO/vPF在DTLZ1和DTLZ3上收敛性较差的原因是基于PSO的算法具有收敛速度快的特点。过快的收敛速度容易使算法在解决多峰问题时陷入局部最优。 DTLZ2 和 DTLZ4 是单峰 MOP,具有与 DTLZ3 类似的 Pareto 前沿 [33]。 MOPSO/vPF 在这两个问题上比 DTLZ3 取得了更好的性能。对于具有退化或断开Pareto前沿的DTLZ5-7,MOPSO/vPF性能不佳的主要原因是vPF的构造方法不适用于那些不规则的PF。对于问题F1-10与NSGA-II和NSGA-III相比,MOPSO/vPF在F9上除NSGA-II外都取得了明显的先验性能,MOPSO/vPF 的性能比 NSGA-II 好很多,类似于 WFG 和 ZDT 套件上的 NSGA-III,HV 得到的结果与 IGD 相似,不再进一步讨论。为了进一步观察,MOPSO/vPF 和 WFG6 上的 5 个 MOEA 获得的 30 次运行中的中值近似 Pareto 前沿如图 6 所示。可以看出,子图 6 (k) 中近似 Pareto 前沿的分布是通过MOPSO/vPF 比 AMOCSO、MOEA/D、MaOEAIGD、NSGA-II 和 NSGA-III 分别获得的子图 6 (f)-(j) 中的结果更加均匀。主要原因是MOPSO/vPF采用的档案维护策略比其他五个MOEA能够更好地保持档案的多样性和一致性。
根据表1中基准问题的Pareto前沿几何和表3-6中的实验结果,所提出的MOPSO/vPF在大多数具有凹PF的MOP上表现良好,但在那些具有非凹或不规则PF的MOP上表现不佳。具体来说,MOPSO/vPF在凹问题、非凹问题和不规则问题上表现最好或不好的数量分别为40/36、10/10和3/25。该结果表明,MOPSO/vPF 在解决非凹 PF 问题时的性能略差于凹 PF 问题。 MOPSO/vPF在解决不规则PF问题时性能明显下降。 MOPSO/vPF 判断的不规则 PF 的几何形状通常与其真实的 PF 有很大差异,这将显着降低算法在不规则 MOP 上的性能。 MOPSO/vPF 在凸问题上的性能通常比在凹问题上的性能差的原因是该算法可以为凹 PF 构建比凸 PF 更“合理”的 vPF。双目标情况下的这种现象如图7所示。子图7(a)是由凹档案构造的vPF(黄点),而子图7(b)是vPF(黄点)由凸档案构造而成。很明显,在计算 vGD 时,子图 7(a) 中的 vPF 比子图 7(b) 中的 vPF 更合理,因为子图 7(a) 中存档中的边际解受到了更多关注。

4.3. Runtime comparison
除了优化效果之外,优化效率也是评价优化算法的重要指标。图 8 显示了所选比较算法在所有 62 个基准问题上的平均运行时间成本。
从图8中可以看出,MOPSO/vPF的平均运行时间在11种算法中按升序排列第五位。此外,所提出的MOPSO/vPF与前四种算法之间存在很小的差距,这表明当主要目标集中在有效性改进时,第3节中所提出的算法的时间消耗仍然是可以接受的。

4.4. Ablation experiment
在 MOPSO/vPF 中,提出了两种关键策略来平衡群体的收敛性和多样性。一是根据几何判断结果构建vPF并选择gBest。另一种是根据迭代过程自适应地选择合适的pBest。本小节将深入探讨这两种策略的有效性。
为了研究这两种策略的有效性,MOPSO/vPF 进一步发展为两个变体:MOPSO/vPF-1 和 MOPSO/vPF-2。去除了MOPSO/vPF-1中构建vPF的自适应过程,使得超平面将被用作vPF。 MOPSO/vPF-2中选择pBest的自适应过程被MOPSO中广泛使用的根据支配关系的pBest选择策略取代。三种定制算法获得的IGD和HV值的平均值和标准差如表7所示。
根据实验结果,MOPSO/vPF在基准问题上的性能总体上比其两个变体要好得多。在62个问题中,MOPSO/vPF取得了34个最佳IGD值和34个最佳HV值,这比MOPSO/vPF-1(10个最佳IGD值和14个最佳HV值)和MOPSO/vPF-2(18个最佳IGD值)要好得多。值和 14 个最佳 HV 值)。因此,MOPSO/vPF的综合性能优于MOPSO/vPF-1和MOPSO/vPF-2。它还表明vPF的自适应构建和pBest的自适应选择对于提高MOPSO的性能非常有帮助。与MOPSO/vPF-1相比,自适应vPF的性能改进主要表现在常规PF的问题F1-6、WFG1-9和ZDT1、4和6上。与MOPSO/vPF-2相比,pBest自适应选择的性能提升对基准问题的Pareto前沿的几何形状不敏感,这表明新的pBest选择策略具有很强的适应性。
为了进一步观察,MOPSO/vPF 及其在 WFG6 上的两个变体获得的 30 次运行中的中值近似帕累托前沿如图 9 所示。可以看出,由所提出的 MOPSO/vPF 获得的非支配解集均匀分布在WFG6的tPF上。对于子图9(a)和(b),近似帕累托前沿的不均匀部分用红色虚线框标记。 MOPSO/vPF 获得的子图 9© 中的近似 Pareto 前沿分布比 MOPSO/vPF-1 和 MOPSO/vPF-2 获得的子图 9(a) 和 (b) 中的近似 Pareto 前沿分布更加均匀。结果表明,基于vPF的gBest选择策略和自适应pBest选择策略都有助于提高群体的多样性。

4.5. Case study
在本小节中,提出了地震观测选址的案例研究,以验证所提出的 MOPSO/vPF 在实际应用中的能力。地震监测站广泛用于监测地震余震。现有地震监测站可分为固定地震监测站和移动地震监测站两类。地震发生后,往往需要在震中附近临时增设移动地震监测站,以提高余震监测能力。如何快速有效地选择合适的地点安装移动地震监测站,成为地震监测工作者面临的首要问题。目前,流动地震监测站选型的主要方法仍然是基于传统的手工计算。在本小节中,拟议的 MOPSO/vPF 将用于搜索移动地震监测站的站点。
根据选址规定[49],移动地震监测站需要布设的区域T应为以基岩在断裂带上的投影点为中心的近似矩形区域。该区域要求覆盖断裂带两侧约10公里的范围,并沿断裂带延伸L=2公里,其中L代表区域T的长度。L的值与地震震级M为

其中 a 和 b 是回归系数。在该地区,放置移动地震监测站的两个目标应仔细考虑。第一个目标是最大化固定和移动地震监测站测量的分布均匀性。第二个目标是尽量减少振动噪声和移动地震监测站不利场地等负面影响。
地震监测站分布的均匀性可以通过固定站和移动站的空间角来衡量。对于震中
O
、
m
O、m
O、m个地震监测站,
S
1
;
S
2
;
;
S
m
S_1; S_2; ; S_m
S1;S2;;Sm,间隙角定义为

其中

这里
X
o
,
X
i
X_o,X_i
Xo,Xi and
X
i
+
1
X_{i+1}
Xi+1 分别是
O
,
S
i
O,S_i
O,Si and
S
i
+
1
S_{i+1}
Si+1 的经度,
Y
o
,
Y
i
Y_o,Y_i
Yo,Yi and
Y
i
+
1
Y_{i+1}
Yi+1 分别是
O
,
S
i
O, S_i
O,Si 和
S
i
+
1
(
i
=
1
,
2
,
⋯
,
m
)
S_{i+1}(i=1,2,\cdots,m)
Si+1(i=1,2,⋯,m) 的纬度;分别。空间角越小,地震监测站分布越均匀。综合上述分析,第一个优化目标可以表示为

为了避免移动地震监测站布设场地不利,根据地理信息系统(GIS)数据,将需要布设移动地震监测站的区域进一步划分为三个区域。第一类是不适宜布设移动地震监测站的区域,如河流、铁路、城市地区等。第二类是优先区域,是最适合布设移动地震监测站的区域,如基岩等。为了简化问题,前两类区域用区域
T
T
T中的不规则多边形来表示。第三类是区域
T
T
T中除第一类和第二类区域之外的区域。为了使地震监测站尽可能布置在第二类区域,对移动站位置所呈现的每个站点
p
i
p_i
pi赋予一个值
z
p
i
z_{p_{i}}
zpi,以评估过程中对其站点的违反约束程度的优化。对于第一、第二和第三类型区域,经验参数
z
p
i
z_{p_{i}}
zpi分别设置为10000、0以及
p
i
p_i
pi到第二类型区域的最近边缘的距离。综合以上分析,第二个优化目标可表示为

由于这个现实世界问题的真实帕累托前沿是事先未知的,因此每个 MOEA 获得的近似帕累托前沿将通过竞争算法获得的所有近似 PF 组合的边界值归一化为 [0, 1]使用 (1.1, 1.1) 的参考点评估可比较的 HV 指标。以2017年发生在中国四川省北部九寨沟县的7.0级地震为例,验证了本案例研究中提出的算法。根据GIS调查,固定地震监测站数量为1个,流动地震监测站数量根据当地资源调度能力设置为7个。为了更直观地描述实验结果,使用图10中的小提琴图来展示多组秩的分布状态和概率密度。该图表结合了箱线图和密度图的特点,展示数据的分布形状。它类似于箱形图,可以更好地显示密度水平。每个算法的排名的平均值、下四分位数和上四分位数分别用白点和两个紫色块绘制在中间。可以看出,所提出的MOPSO/vPF在图10顶部具有更高的密度,这意味着由于新提出的gBest和pBest的良好性能,移动地震监测站的位置选择具有更高的HV等级平衡群体收敛性和多样性的选择策略。另外,图11给出了MOPSO/vPF获得的移动地震监测站布设示意图,表明MOPSO/vPF获得的站布设方案对于余震监测是可行和有效的。


5. Conclusions
本文提出了关于 gBest 和 pBest 选择的两种新策略,以改善群体收敛性和多样性之间的平衡。在新提出的gBest选择策略中,首先通过提出的vPF构建策略来判断档案的几何形状。然后根据几何形状自适应地构建超平面或超曲面作为vPF。最终采用新构造的vPF来选择gBest并维护gBest
,根据 vGD 指标存档粒子群。对于新的pBest选择策略,将根据pBest的位置和迭代信息自适应地选择更合适的pBest。竞争性实验结果表明,两种新策略都能有效提高MOPSO的收敛性和多样性方面的综合性能。此外,第4.5节中还进行了案例研究,以验证AMOPSO/vPF解决现实问题的能力。然而,正如第 4.2 节中所讨论的,MOPSO/vPF 遇到了非凹 PF 或不规则 PF 的基准问题。在这两种情况下,算法构建的vPF可能不够准确。在我们未来的工作中,将进一步研究构建准确 vPF 的更精细策略,以解决具有非凹和不规则 PF 的 MOP。一种可能的想法是将目标空间划分为许多小空间,在不同的空间中生成不同的vPF,从而实现MOP的tPF的更准确的替代。
References
Li Y, Zhang Y, Hu W. Adaptive multi-objective particle swarm optimization based on virtual Pareto front[J]. Information Sciences, 2023, 625: 206-236.
@article{li2023adaptive,
title={Adaptive multi-objective particle swarm optimization based on virtual Pareto front},
author={Li, Yuxuan and Zhang, Yu and Hu, Wang},
journal={Information Sciences},
volume={625},
pages={206--236},
year={2023},
publisher={Elsevier}
}















 3737
3737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









