






一、通过yolov5s的源码生成onnx
(1)在生成onnx的过程中遇到的几个问题
已解决TypeError: Descriptors cannot not be created directly.
If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0.
If you cannot immediately regenerate your protos, some other possible workarounds are:
1.Downgrade the protobuf package to 3.20.x or lower.
2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).的正确解决方法
pip install protobuf==3.19.0
(2)ONNX export failure: No module named ‘onnx‘
pip install onnx==1.7.0(3)生成指令
python export.py --weights ./yolov5s.pt --include onnx --imgsz 640 --device 0
(4)查看模型的网络结构
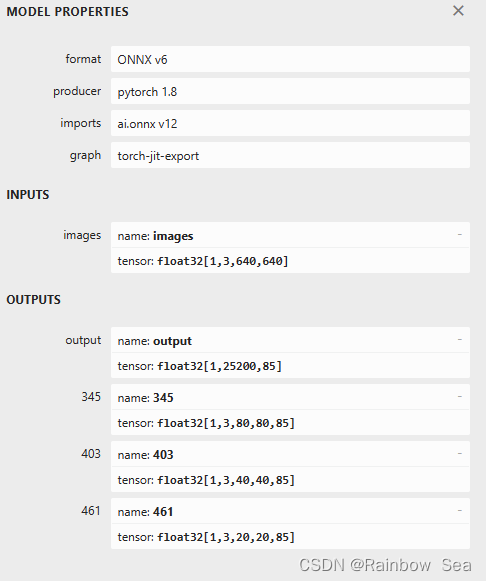
(5)对于输出四个维度的输出,为了便于以后部署,可以修改moudles下的yolo.py,具体修改如下,修改之后再次使用

yolov5s.onnx (netron.app)查看网络结构,可以看到只有一个输出了
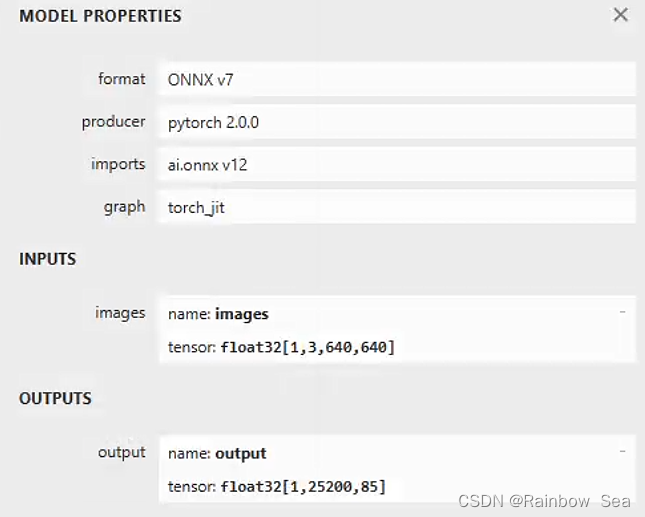
(5)进行测试
python detect.py --weights yolov5s.onnx --imgsz 640 --device 0
二、通过yolov5s生成engine
(1)安装tensorrt,在python的虚拟环境下
找到Tensorrt的解压目录,pip install 目录:/tensorrt-8.2.3.0-cp38-none-win_amd64.whl
(2)在通过命令导出engine
python3 export.py --weights ./yolov5s.pt --include engine --imgsz 640 --device 0
的时候遇到了这样一个问题, 卡在这里不动了,去源码中查找问题,将
卡在这里不动了,去源码中查找问题,将

这一行注释掉(前提已经存在onnx模型),也可以改为12,这里不太明白为什么
(3)导出半精度FP16的engine文件,试试证明使用半精度的engine文件大小约为FP32的一半左右,但是准确行几乎不受影响

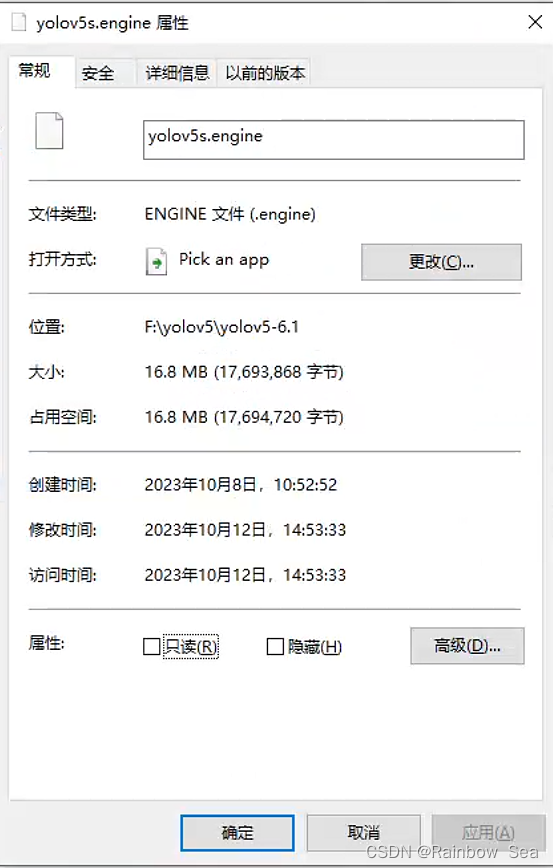
python export.py --weights ./yolov5s.pt --include engine --half --device 0
三、测试onnx和engine模型的推理情况
(1)普通的pt模型的情况
python detect.py --weights yolov5s.pt --imgsz 640 --device 0
运行结果:

(2)onnx模型的情况
python detect.py --weights yolov5s.onnx --imgsz 640 --device 0
运行结果:

(3)FP32 engine模型的情况
python detect.py --weights yolov5s.engine --imgsz 640 --device 0
运行结果:

(4)FP16 engine模型的情况

四、在C++中进行推理部署
源代码(如果是单输出的话更改相应代码即可):
#include <iostream>
#include <fstream>
#include <sstream>
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "NvinferRuntime.h"
#include<string>
#include <opencv2/opencv.hpp>
#include<windows.h>
#include <opencv2/imgproc.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/core/utils/logger.hpp>
#include<opencv2/dnn/dnn.hpp>
using namespace nvinfer1;
using namespace nvonnxparser;
using namespace cv;
Mat resize_image(Mat srcimg, int* newh, int* neww, int* top, int* left)
{
int srch = srcimg.rows, srcw = srcimg.cols;
int inpHeight = 640;
int inpWidth = 640;
*newh = inpHeight;
*neww = inpWidth;
bool keep_ratio = true;
Mat dstimg;
if (keep_ratio && srch != srcw) {
float hw_scale = (float)srch / srcw;
if (hw_scale > 1) {
*newh = inpHeight;
*neww = int(inpWidth / hw_scale);
resize(srcimg, dstimg, Size(*neww, *newh), INTER_AREA);
*left = int((inpWidth - *neww) * 0.5);
copyMakeBorder(dstimg, dstimg, 0, 0, *left, inpWidth - *neww - *left, BORDER_CONSTANT, 0);
}
else {
*newh = (int)inpHeight * hw_scale;
*neww = inpWidth;
resize(srcimg, dstimg, Size(*neww, *newh), INTER_AREA);
*top = (int)(inpHeight - *newh) * 0.5;
copyMakeBorder(dstimg, dstimg, *top, inpHeight - *newh - *top, 0, 0, BORDER_CONSTANT, 0);
}
}
else {
resize(srcimg, dstimg, Size(*neww, *newh), INTER_AREA);
}
return dstimg;
}
class Logger : public ILogger
{
virtual void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity != Severity::kINFO)
std::cout << msg << std::endl;
}
} gLogger;
int main()
{
cudaSetDevice(0);
const char* model_path_onnx = "yolov5s.onnx";
const char* model_path_engine = "yolov5s.engine";
const char* image_path = "zidane.jpg";
std::string lable_path = "coco.txt";
const char* input_node_name = "images";
const char* output_node_name = "output";
std::vector<std::string> class_names;
std::string classesFile = "coco.txt";//加载label
std::ifstream ifs(classesFile.c_str());//用了classesFile.c_str()函数将字符串classesFile转换为C风格的字符串(即以null结尾的字符数组),并将其作为参数传递给std::ifstream类的构造函数。
std::string line;
while (getline(ifs, line)) class_names.push_back(line);
//五个索引
int num_ionode = 5;
std::ifstream file_ptr(model_path_engine, std::ios::binary);
if (!file_ptr.good()) {
std::cerr << "文件无法打开,请确定文件是否可用!" << std::endl;
}
size_t size = 0;
file_ptr.seekg(0, file_ptr.end); // 将读指针从文件末尾开始移动0个字节
size = file_ptr.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file_ptr.seekg(0, file_ptr.beg); // 将读指针从文件开头开始移动0个字节
char* model_stream = new char[size];
file_ptr.read(model_stream, size);
file_ptr.close();
Logger logger;
// 反序列化引擎
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 推理引擎
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(model_stream, size);
// 上下文
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
void** data_buffer = new void* [num_ionode];
// 创建GPU显存输入缓冲区
int input_node_index = engine->getBindingIndex(input_node_name);
//auto it = engine->getNbBindings();
//std::cout << "input_node_index" << input_node_index <<it<< std::endl;
nvinfer1::Dims input_node_dim = engine->getBindingDimensions(input_node_index);
//断点检测
std::cout << "input_node_dim.d[0]" << input_node_dim.d[0]
<< "input_node_dim.d[1]" << input_node_dim.d[1] <<
"input_node_dim.d[2]" << input_node_dim.d[2] <<
"input_node_dim.d[3]" << input_node_dim.d[3] << std::endl;
size_t input_data_length = input_node_dim.d[1] * input_node_dim.d[2] * input_node_dim.d[3];
std::cout << "input_data_length" << input_data_length << std::endl;
cudaError_t err1 = cudaMalloc(&(data_buffer[input_node_index]), input_data_length * sizeof(float));
if (err1 != cudaSuccess) {
std::cout << "Failed to allocate memory for input data: " << cudaGetErrorString(err1) << std::endl;
return -1;
}
// 创建GPU显存输出缓冲区
int output_node_index = engine->getBindingIndex(output_node_name);
std::cout << "output_node_index" << " " << output_node_index << std::endl;
nvinfer1::Dims output_node_dim = engine->getBindingDimensions(output_node_index);
size_t output_data_length = output_node_dim.d[1] * output_node_dim.d[2];
//std::cout << "output_node_dim.d[0]:" << output_node_dim.d[0] <<
// "output_node_dim.d[1]:" << output_node_dim.d[1] <<
// "output_node_dim.d[2]" << output_node_dim.d[2] <<
// "output_node_dim.d[3]"<< output_node_dim.d[3]<<
// "output_node_dim.d[4]" << output_node_dim.d[4]<<std::endl;
std::cout << "output_data_length" << output_data_length<<std::endl;
cudaMalloc(&(data_buffer[output_node_index]), output_data_length * sizeof(float));
//创建另外三个维度的输出缓存区
nvinfer1::Dims output_node_dim1 = engine->getBindingDimensions(output_node_index-1);
size_t output_data_length1 = output_node_dim1.d[1] * output_node_dim1.d[2]* output_node_dim1.d[3]* output_node_dim1.d[4];
std::cout << "output_data_length1" << output_data_length1 << std::endl;
cudaMalloc(&(data_buffer[output_node_index-1]), output_data_length1 * sizeof(float));
nvinfer1::Dims output_node_dim2 = engine->getBindingDimensions(output_node_index - 2);
size_t output_data_length2 = output_node_dim2.d[1] * output_node_dim2.d[2] * output_node_dim2.d[3] * output_node_dim2.d[4];
std::cout << "output_data_length2" << output_data_length2 << std::endl;
cudaMalloc(&(data_buffer[output_node_index - 2]), output_data_length2 * sizeof(float));
nvinfer1::Dims output_node_dim3 = engine->getBindingDimensions(output_node_index - 3);
size_t output_data_length3 = output_node_dim3.d[1] * output_node_dim3.d[2] * output_node_dim3.d[3] * output_node_dim3.d[4];
std::cout << "output_data_length3" << output_data_length3 << std::endl;
cudaMalloc(&(data_buffer[output_node_index - 3]), output_data_length3 * sizeof(float));
// 图象预处理 - 格式化操作2
cv::Mat image = cv::imread(image_path);
//int max_side_length = std::max(image.cols, image.rows);
//std::cout << "max_side_length0" << max_side_length << std::endl;
//cv::Mat max_image = cv::Mat::zeros(cv::Size(max_side_length, max_side_length), CV_8UC3);
//cv::Rect roi(0, 0, image.cols, image.rows);
//image.copyTo(max_image(roi));
// 将图像归一化,并放缩到指定大小
//cv::Size input_node_shape(input_node_dim.d[2], input_node_dim.d[3]);
//cv::Mat BN_image = cv::dnn::blobFromImage(image, 1 / 255.0, input_node_shape, cv::Scalar(0, 0, 0), true, false);
int newh = 0, neww = 0, padh = 0, padw = 0;
//将图像的大小调整为指定的尺寸并在调整过程中保持图像的完整性和比例
Mat dstimg = resize_image(image, &newh, &neww, &padh, &padw);//Padded resize
// 创建输入cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
std::vector<float> input_data(input_data_length);
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < 640; i++)
{
for (int j = 0; j < 640; j++)
{
float pix = dstimg.ptr<uchar>(i)[j * 3 + 2 - c];//转换通道,输入onnx模型的图片通道顺序是RGB,但是opencv存储默认是BGR
input_data[c * 640 * 640 + i * 640 + size_t(j)] = pix / 255.0;//归一化
}
}
}
//memcpy(input_data.data(), BN_image.ptr<float>(), input_data_length * sizeof(float));
// 输入数据由内存到GPU显存
float* result_array = new float[output_data_length];
for (int i = 0; i < 10; i++)
{
clock_t start_time = clock();
cudaError_t err3 = cudaMemcpyAsync(data_buffer[input_node_index], input_data.data(), input_data_length * sizeof(float), cudaMemcpyHostToDevice, stream);
if (err3 != cudaSuccess) {
std::cout << "Failed to transfer input data to GPU1: " << cudaGetErrorString(err3) << std::endl;
return -1;
}
context->enqueueV2(data_buffer, stream, nullptr);
//处理推理结果
//float* result_array = new float[output_data_length];
cudaError_t err4 = cudaMemcpyAsync(result_array, data_buffer[output_node_index], output_data_length * sizeof(float), cudaMemcpyDeviceToHost, stream);
if (err4 != cudaSuccess) {
std::cout << "Failed to transfer input data to HOST: " << cudaGetErrorString(err4) << std::endl;
return -1;
}
clock_t end_time = clock();
double exec_time = static_cast<double>(end_time - start_time) / CLOCKS_PER_SEC;
// 输出执行时间
std::cout << "Execution time: " << exec_time << " seconds" << std::endl;
}
//推理完成
//std::cout << result_array[2] << std::endl;
//解析结果
std::vector<float> output(result_array, result_array + output_data_length);
std::vector<cv::Rect> boxes;
std::vector<float> confs;
std::vector<int> classIds;
int numClasses = (int)output_node_dim.d[2] - 5;
float confThreshold = 0.5;//设定阈值
for (auto it = output.begin(); it != output.begin() + output_data_length; it += output_node_dim.d[2])
{
float clsConf = *(it + 4);//object scores
if (clsConf > confThreshold)
{
int centerX = (int)(*it);
int centerY = (int)(*(it + 1));
int width = (int)(*(it + 2));
int height = (int)(*(it + 3));
int x1 = centerX - width / 2;
int y1 = centerY - height / 2;
boxes.emplace_back(cv::Rect(x1, y1, width, height));
// first 5 element are x y w h and obj confidence
int bestClassId = -1;
float bestConf = 0.0;
for (int i = 5; i < numClasses + 5; i++)
{
if ((*(it + i)) > bestConf)
{
bestConf = it[i];
bestClassId = i - 5;
}
}
//confs.emplace_back(bestConf * clsConf);
confs.emplace_back(clsConf);
classIds.emplace_back(bestClassId);
}
}
float iouThreshold = 0.5;
std::vector<int> indices;
// Perform non maximum suppression to eliminate redundant overlapping boxes with
// lower confidences极大值抑制
cv::dnn::NMSBoxes(boxes, confs, confThreshold, iouThreshold, indices);
//随机数种子
RNG rng((unsigned)time(NULL));
for (size_t i = 0; i < indices.size(); ++i)
{
int index = indices[i];
int colorR = rng.uniform(0, 255);
int colorG = rng.uniform(0, 255);
int colorB = rng.uniform(0, 255);
//保留两位小数
float scores = round(confs[index] * 100) / 100;
std::ostringstream oss;
oss << scores;
rectangle(dstimg, Point(boxes[index].tl().x, boxes[index].tl().y), Point(boxes[index].br().x, boxes[index].br().y), Scalar(colorR, colorG, colorB), 1.5);
putText(dstimg, class_names[classIds[index]] + " " + oss.str(), Point(boxes[index].tl().x, boxes[index].tl().y - 5), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(colorR, colorG, colorB), 2);
}
imshow("检测结果", dstimg);
cv::waitKey();
return 0;
}














 347
347











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









