







第5章 实时技术
在大数据系统中,离线批处理技术可以满足非常多的数据使用场景需求,但在 DT 时代, 每天面对的信息是瞬息万变的,越来越多的应用场景对数据的时效性提出了更高的要求。数据价值是具有时效性的,在一条数据产生的时候,如果不能及时处理并在业务系统中使用,就不能让数据保持最高的“新鲜度”和价值最大化。因此阿里巴巴提出了流式实时处理技术来对离线批处理技术进行补充。
流式数据处理一般具有一下特征:
时效性高
常驻任务
性能要求高
应用局限性
5.1 流式架构
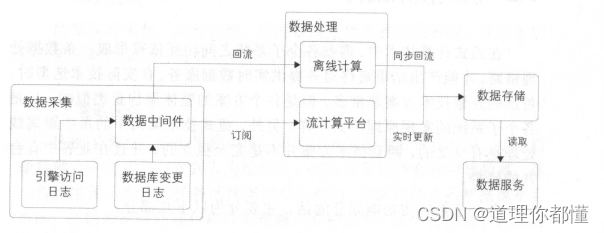
按照功能划分主要包括:
数据采集
数据处理
数据存储
数据服务
- 数据采集
按照数据采集的种类可以划分为:
数据库变更日志:比如MySQL的binlog日志、Hbase的hlog日志、OceanBase的变更日志、Oracle的变更日志等。
引擎访问日志:比如用户访问网站产生的Apache引擎日志,搜索引擎的接口查询日志等
数据采集原则:
数据大小限制:当达到限制条件时,把目前采集到的新数据作为一批(例如512KB一批)。
时间阈值限制:当时间达到一定条件时,也会把目前采集到的新数据作为一批,避免在数据量少的情况下一直不采集(例如30秒写一批)
消息系统与数据中间件
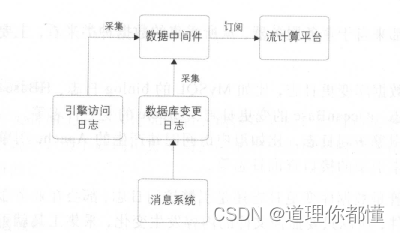
消息系统:
消息系统是数据库变更的上游,所以它的延时数据比数据中间件低很多,但是其支持的吞吐量有限。一般会用作业务数据库变更的消息中转,比如订单下单、支付等消息。
消息中间件:
作为数据交换平台将采集的数据分发给下游,用来处理较大的业务数据(每天几十TB的容量)
| 时效性 | 吞吐量 | |
|---|---|---|
| 消息系统 | 毫秒 | 低 |
| 数据中间件 | 秒 | 高 |
- 数据处理
阿里采用的刘就散引擎系统是阿里元提供的StreamCompute系统:
StreamCompute系统涵盖了从数据采集到数据生产各个环节,力保流计算开发严谨、可靠。其提供的 SQL 语义的流式数据分析能力( StreamSQL ),让流数据分析门槛不再存在。它在Storm 的基础上包装了一层 SQL 语义,方便开发人员通过写 SQL 就可以实现实时计算,不需要关心其中的计算状态细节,大大提高了开发效,降低了流计算的门槛。当然,它也支持传统模式的开发,就像 Hadoop中的 Hive MapReduce 关系一样,根据不同的应用场景选择不同的方式。另外,StreamCompute 还提供了流计算开发平台,在这个平台上就可以完成应用的相关运维工作,不需要登录服务器操作 ,极大地提了运维效率。
业界较广泛使用的流式计算系统:
Twitter 开源的Storm 系统
雅虎开源的 S4 系统
Apache park Streaming
Flink
流数据处理原理,以Storm为例:
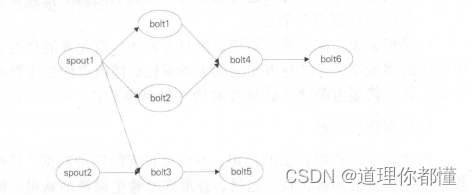
spout :拓扑的输人,从数据中间件中读取数据,并且根据自定义的分发规则发送给下游的 bolt ,可以有多个输人源。
bolt :业务处理单元,可以根据处理逻辑分为多个步骤,其相互之间的数据分发规则也是自定义的。
实时任务典型问题:
(1)去重指标
去重情况分为:
精确去重。在这种情况下,明细数据是必须要保存下来的,当遇到内存问题时,可以通过数据倾斜来进行处理,把一个节点的内存压力分到多个节点上。
模糊去重。在去重的明细数据量非常大,而业务的精度要求不的情况下,可以使用相关的去重算法,把内存的使用 量降到千分之一甚至万分之一 ,以提高内存的利用率
去重方法:
①布隆过滤器
该算法是位数组算法的应用 不保存真实的明细数据,只保存明细数据对应哈希值的标记位。当然,会出现哈希值碰撞的情况,但是误差率可以控制,计算出来的去重值比真实值小。采用这个算法存储1亿条数据只需要 100 MB 空间。
适用场景 统计精度要求不高,统计维度值非常多的情况。比如统计全网各个商家的 UV 数据,结果记录数达到上千万条。因为在各个维度之间,布隆过滤器是可以共用的
②基数估计
该算法也是利用哈希的原理,按照数据的分散程度来估算现有数集的边界,从而得出大概的去重值总和。这里估算的去重值可能比真实值大,也可能比真实值小。采用这个算法存储1亿条数据只需要几 KB内存。
适用场景:统计精度要求不高,统计维度非常粗的情况。比如整个大盘的 UV 数据,每天的结果只有一条记录。基数估计在各个维度值之间不能共用,比如统计全天小时的 UV 数据,就需要有24个基数估计对象,因此不适合细粒度统计的场景。
(2)数据倾斜
解决方法:
①去重指标分桶
通过对去重值进行分桶 Hash,相同的值一定会被放在同一个桶去重,最后再把每个桶里面的值进行加和就得到总值,这里利用了每个桶的CPU 和内存资源。
②非去重指标分桶
数据随机分发到每个桶中,最后再把每个桶的值汇总,主要利用的是各个桶的CPU能力。
(3)事务处理
保证事务的幂等性:
① 超时时间:由于数据处理是按照批次来进行的,当一批数据处理超时时,会从拓扑的spout端重发数据。另外,批次处理的数据量不宜过大,应该增加一个限流的功能(限定一批数据的记录数或者容量等),避免数据处理超时。
② 事务信息:每批数据都会附带 一个事务 ID 的信息,在重发的情况下,让开发者自己根据事务信息去判断数据第一次到达和重发时不同的处理逻辑。
③ 备份机制:开发人员需要保证内存数据可以通过外部存储恢复,因此在计算中用到的中间结果数据需要备份到外部存储中。
- 数据存储
实时任务在运行过程中,会计算很多维度和指标,这些数据需要放在一个存储系统中作为恢复或者关联使用。其中会涉及三种类型的数据:
中间计算结果:在实时应用处理过程中,会有一些状态的保存(比如去重指标的明细数据),用于在发生故障时,使用数据库中的数据恢复内存现场。
最终结果数据:指的是通过 ETL 处理后的实时结果数据,这些数据是实时更新的,写的频率非常高,可以被下游直接使用。
维表数据:在离线计算系统中,通过同步工具导人到在线存储系统中,供实时任务来关联实时流数据。后面章节中会讲到维表的使用方式。
对于海量数据的实时计算,一般会采用非关系型数据库,以应对大量的多并发读写。下面是在数据统计中表名设计的一些时间经验:
(1)表名设计
设计规则:汇总层标识+数据域+主维度+时间维度
例如: dws_trd_slr_dtr ,表示汇总层交易数据,根据卖家( slr )主维度+0点截至当日( dtr )进行统计汇总。
这样做的好处是,所有主维度相同的数据都放在一张物理表中,避免表数量过多,难以维护。另外,可以从表名上直观地看到存储的是什么数据内容,方便排查问题。
(2)rowkey 设计
设计规则: MD5 +主维度+维度标识+子维度1 +时间维度+子维度2
例如:卖家 ID的MD5 前四位+卖家ID+ app+ 一级类目ID+ ddd +二级类目ID
以MD5 前四位作为 rowkey 的第一部分,可以把数据散列,让服务器整体负载是均衡的,避免热点问题。在上面的例子中,卖家 ID于主维度 ,在查数据时是必传的。每个统计维度都会生成一个维度标识以便在 rowkey 上做区分。
- 数据服务
实时数据落地到存储系统中后,使用方就可以通过统一的数据服务获取到实时数据。
5.2 流式数据模型
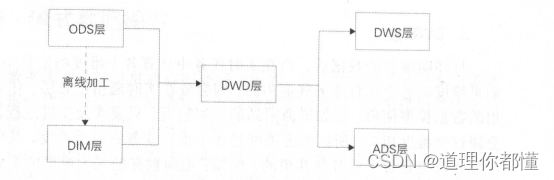
- 数据分层
流数据模型整体上分为五层:
(1)ODS :订单粒度的变更过程, 一笔订单有多条记录。
(2)DWD:订单粒度的支付记录,一笔订单只有一条记录
(3)DWS:卖家的实时成交金额,一个卖家只有一条记录,并且指标在实时刷新。
(4)ADS: 外卖地区的实时成交金额,只有外卖业务使用
(5)DIM :订单商品类目和行业的对应关系维表。
- 数据关联
在流式计算中常常需要把两个实时流进行主键关联,以得到对应的时明细表。下图为订单信息表和支付信息表关联示意图
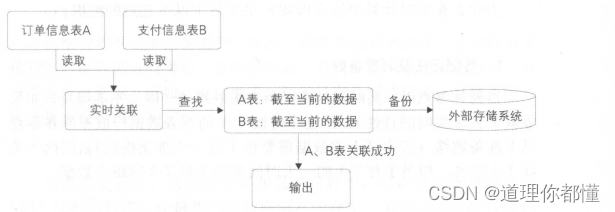
上面的例子中,实时采集两张表的数据,每到来一条新数据时都在内存中的对方表截至当前的全量数据中查找,如果能查找到,则说明关联成功,直接输出 :如果没查找到 ,则把数据放在内存中的自己表数据集合中等待。另外,不管是否关联成功,内存中的数据都需要备份到外部存储系统中,在任务重启时,可以从外部存储系统中恢复内存数据这样才能保证数据不丢失。因为在重启时,任务是续跑的,不会重新跑之前的数据。
另外,订单记录的变更有可能发生多次(比如订单的多个字段多次更新),在这种情况下 需要根据订单 ID 去重,避免A表和B表多次关联成功;否则输出到下游就会有多条记录,这样得到的数据是有重复的。
- 维表使用
(1)为什么使用维表
数据无法及时准备好
无法准确的获取全量的最新数据
数据的无序性
(2)维表的使用形式
全量加载
增量加载
5.3 大促特征和保障
- 大促特征
毫秒级延时
洪峰明显
高保障性
- 大促保障
(1)如何进行实时任务优化
独占资源和共享资源策略
合理选择缓存机制,尽量降低读写库次数
计算单元合并,降低拓扑层级
内存对象共享,避免字符拷贝
在高吞吐量和低延时间取平衡
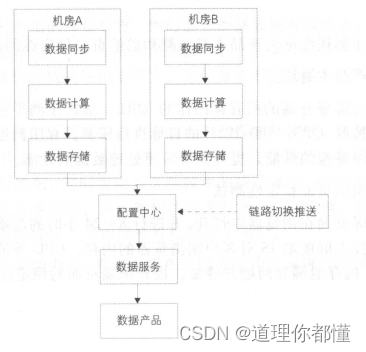
(2)如何进行数据链路保障
进行多机房容灾、异地容灾。下图为多机房容灾示意图
(3)如何进行压测
数据压测:数据压测主要是蓄洪压测,就是把几个小时甚至几天的数据积累下来,并在某个时刻全部放开。
产品压测:
① 产品本身压测
收集大屏服务端的所有读操作的 URL ,通过压测平台进行压测流量回放,按照 QPS: 500次/秒的目标进行压测。在压测过程中不断地迭代优化服务端的性能,提升大屏应用处理数据的性能。
② 前端页面稳定性测试
将大屏页面在浏览器中打开,并进行8到24 小时的前端页面稳定性测试。监控大屏前端 JS 对客户端浏览器的内存、 CPU 等的消耗,检测出前端 JS 内存泄漏等问题并修复,提升前端页面的稳定性。

















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











