







学习视频:B站 刘二大人《PyTorch深度学习实践》完结合集
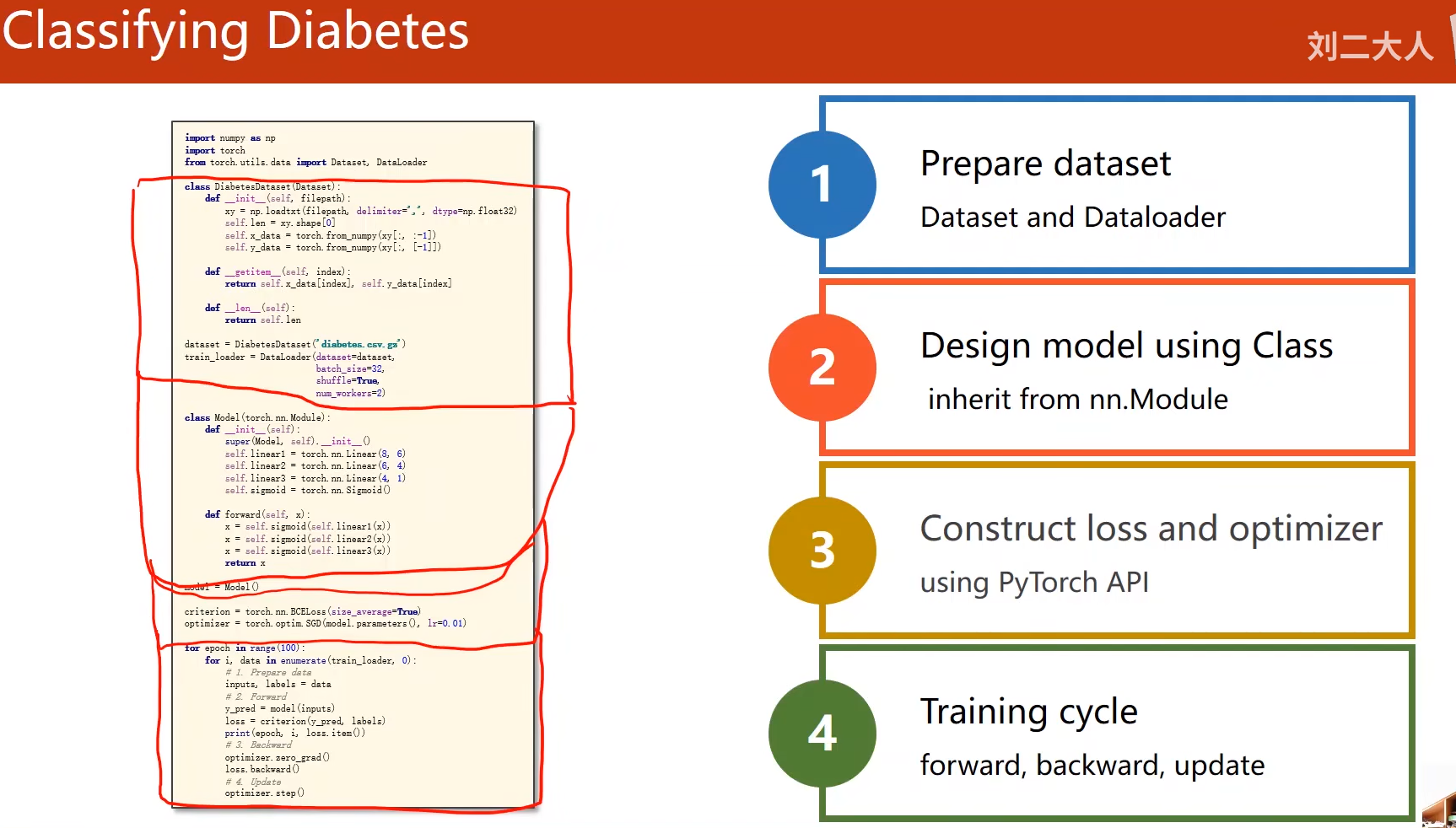
七、加载数据集
Dataset和DataLoader
加载数据的两个工具类
- dataset:构造数据集(数据集应该支持索引,能够用下标操作快速把数据拿出来)
- dataloader :主要目标用来拿出一个mini-batch来供训练时快速使用。
Mini-batch优点
在之前梯度下降时,有两种选择:
- 全部的数据都用(batch)
- 随机梯度下降,只用一个样本
只用一个样本可以得到比较好的随机性,可以帮助我们跨越在优化中遇到的鞍点,而用Batch(所有数据)的优点是可以最大化地利用向量计算的优势提升计算速度。
都用一个样本的随机梯度下降训练出的模型效果可能会比其他模型都更好,但是会导致优化用的时间更长,因为每次一个样本没法使用cpu或gpu的并行能力,训练的时间会很长,而使用Batch计算速度快,但是在求得性能上会遇到一些问题,所以在深度学习中我们使用Mini-Batch来平衡训练时间和训练速度上的要求。
使用Mini-Batch之后训练循环要写成嵌套循环

外层是循环的次数,循环一次是一个epoch;每一次epoch中执行一次内层;内层每循环一次,执行一次Mini-batch。
epoch、batch-size、iteration
epoch:所有的样本都进行了一次前向和反向传播
batch-size:进行一次前馈和反馈所用的样本训练数量
iteration:内层迭代执行了多少次

DataLoader

shuffle:设为true可以随机打乱dataset,这样每一次生成的MiNi-batch数据集数据样本都是随机的。
dataset 需要支持索引,需要知道Dataset长度,这样DataLoader就可以对Dataset进行自动的小批量的数据集的生成。
定义数据集和加载
Dataset是一个抽象类,不能实例化,只能被其他子类所继承,我们需要定义我们自己的类来继承这个类
DataLoader是一个用来帮助我们在pytorch加载数据的类
两种方法构造数据集:
- 第一种在init中把所有的数据都读到内存中,然后每次使用get_item时就把其中第i个样本传出去,适用于样本不大的情况。
- 第二种,如果读取的是较大(10g)图像数据集,在init中把数据都读进来不可能,我们就在init中定义一个列表,每一条数据的文件名放在列表中,标签读到内存中(输出是简单的分类回归数值)或文件名放在列表里,然后get_item读取第i个文件,那x,y的第i个元素去读出来,然后返回,来保证内存的高效使用。(读取文件名,根据文件名加载文件)
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
class DiabetesDataset(Dataset):
def __init__(self):
pass
#将来实例化这个类之后,这个对象能够支持下标操作,可以通过一个索引
#把里面的dataset[index]的第index条数据给拿出来
def __getitem__(self, index):
pass
#返回数据集的条数
def __len__(self):
pass
#用自定义的类把它实例化一个数据对象dataset,
#这个dataset最重要的功能是getitem()和len()
dataset = DiabetesDataset() #实例化类
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
# num_workers:要几个多线程并行读取数据
应用实例:
class DiabetesDataset(Dataset):
def __init__(self,filepath):
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
#定义一个方法支持下标操作,我们称为magic function
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
#返回数据集的条数
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz') #实例化类
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
运行时可能出现的错误
DataLoader是pytorch提供的加载器,初始化要设置:dataset=,bbatch-size=,shufflle=,num—_workers=(超线程,win直接使用会报错,用if main语句包起来即可)

将程序改写一下:

代码实现
import numpy as np
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
class DiabetesDataset(Dataset): #DiabetesDataset继承自抽象类Dataset
def __init__(self,filepath): #filepath数据集路径
xy = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:,:-1])
self.y_data = torch.from_numpy(xy[:,[-1]])
#定义一个方法支持下标操作
def __getitem__(self, index):
return self.x_data[index],self.y_data[index]
#返回数据集的条数
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv.gz') #实例化类
train_loader = DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=0)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1 = torch.nn.Linear(8,6)
self.linear2 = torch.nn.Linear(6,4)
self.linear3 = torch.nn.Linear(4,1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self,x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
#构造损失函数
criterion = torch.nn.BCELoss(size_average=True)
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)
epoch_list=[]
loss_list=[]
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
#1.准备数据
# 在训练之前把x,y从data里面拿出来,inputs=x,labels=y,
# 此时inputs,labels都已经被自动转换为张量(tensor)
inputs,labels = data
#2.forward
y_pred = model(inputs)
loss = criterion(y_pred,labels)
print(epoch,i,loss.item())
#3.backward
optimizer.zero_grad()
loss.backward()
#4.update
optimizer.step()
epoch_list.append(epoch + 1)
loss_list.append(loss.item())
#画图
plt.plot(epoch_list,loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.grid()
plt.show()
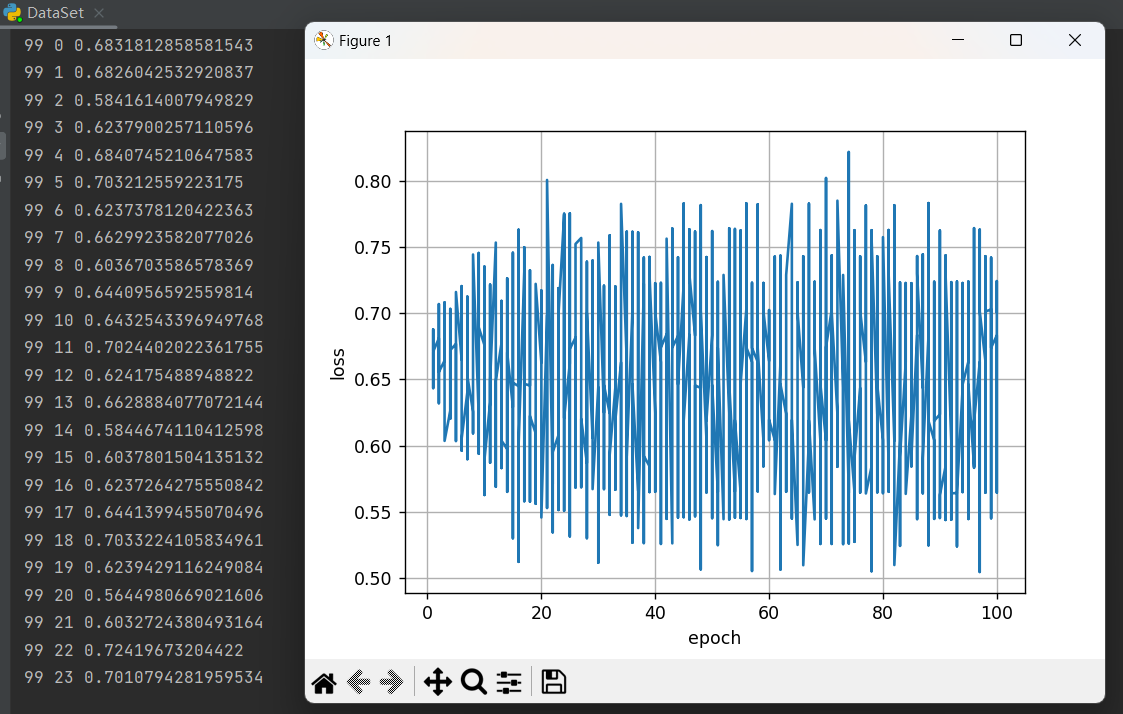
运行结果:
loss在0.65之间震荡,说明模型收敛不够,效果不好
参考资料
https://blog.csdn.net/qq_43800119/article/details/126415690















 2789
2789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









