






香港科技大学提出 MTMamba,超越 Transformer 与 CNN,在语义分割等任务上的卓越表现
代码:https://github.com/EnVision-Research/MTMamba
 https://arxiv.org/abs/2407.02228
https://arxiv.org/abs/2407.02228摘要
多任务密集场景理解是一个在计算机视觉中具有广泛应用的重要问题,例如自动驾驶、医疗保健和机器人技术。这项任务的目标是训练一个模型同时处理多个密集预测任务,如语义分割、单目深度估计和表面法线估计。本文提出了MTMamba,一种新颖的基于Mamba的多任务场景理解架构。MTMamba包含两种核心模块:自任务Mamba(STM)模块和跨任务Mamba(CTM)模块。STM通过利用Mamba处理长距离依赖性,而CTM则显式地建模任务间的交互以促进跨任务的信息交换。在NYUDv2和PASCAL-Context数据集上的实验表明,MTMamba的性能优于基于Transformer和基于CNN的方法。
拟解决的问题
- 多任务密集场景理解中的关键挑战包括建模长距离依赖性和增强跨任务交互。
- 现有的多任务架构通常采用编码器-解码器框架,但这种框架在处理长距离空间关系和任务间关联方面存在局限性。
- SSMs适合于序列任务,将其应用于 2D 图像是有挑战的
主要贡献
- 提出了 MTMamba,这是一种用于多任务场景理解的新型多任务架构。它包含一种新颖的基于 Mamba 的解码器,它有效地对远程空间关系进行建模并实现跨任务相关性;
- 设计了一种新的 CTM 块来增强多任务密集预测中的跨任务交互;
- 在两个基准数据集上的实验表明,MTMamba在多任务密集预测方面优于以往基于cnn和transformer的方法;定性评价表明,MTMamba捕获了判别特征并生成了精确的预测。
方法论
MTMamba由三个主要部分组成:预训练的编码器(encoder)、基于Mamba的解码器(decoder),以及特定于任务的头(task-specific heads)。
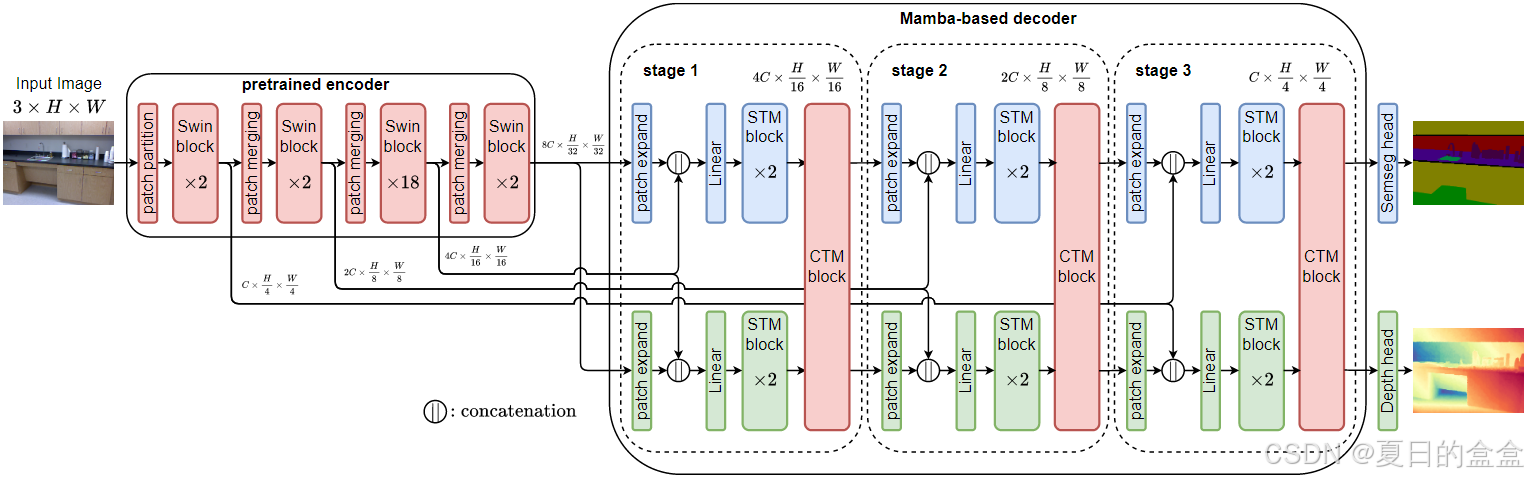
1. 编码器 (Encoder)
- 编码器用于从输入图像中提取多尺度通用视觉表示。
- 论文中使用的是Swin Transformer作为编码器,它通过分块(patch-partition)模块将输入图像分割成不重叠的小块(patches),每个小块视为一个token。
- 编码器输出经过多个Swin Transformer块和合并层(patch merging layers)处理的特征表示。
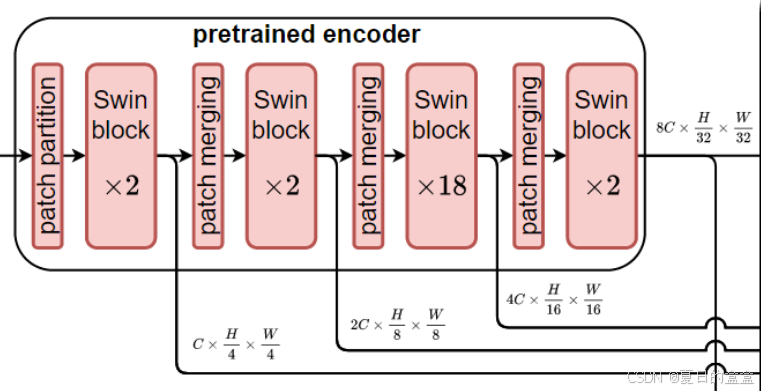
2. 解码器(Decoder)
解码器由三个阶段组成,每个阶段包括:
- 补丁扩展层(Patch Expand Layer):用于上采样特征分辨率并降低特征维度。
- 自任务Mamba(Self-Task Mamba, STM)块:负责学习特定于任务的特征表示。
- 跨任务Mamba(Cross-Task Mamba, CTM)块:通过跨任务的知识交换来增强每个任务的特征。
补丁扩展层:用于对特征分辨率进行2×上采样,降低特征维数。对于每个任务,其特征将被补丁扩展层扩展,然后通过跳过连接与来自编码器的多尺度特征融合,以补充下采样引起的空间信息损失。
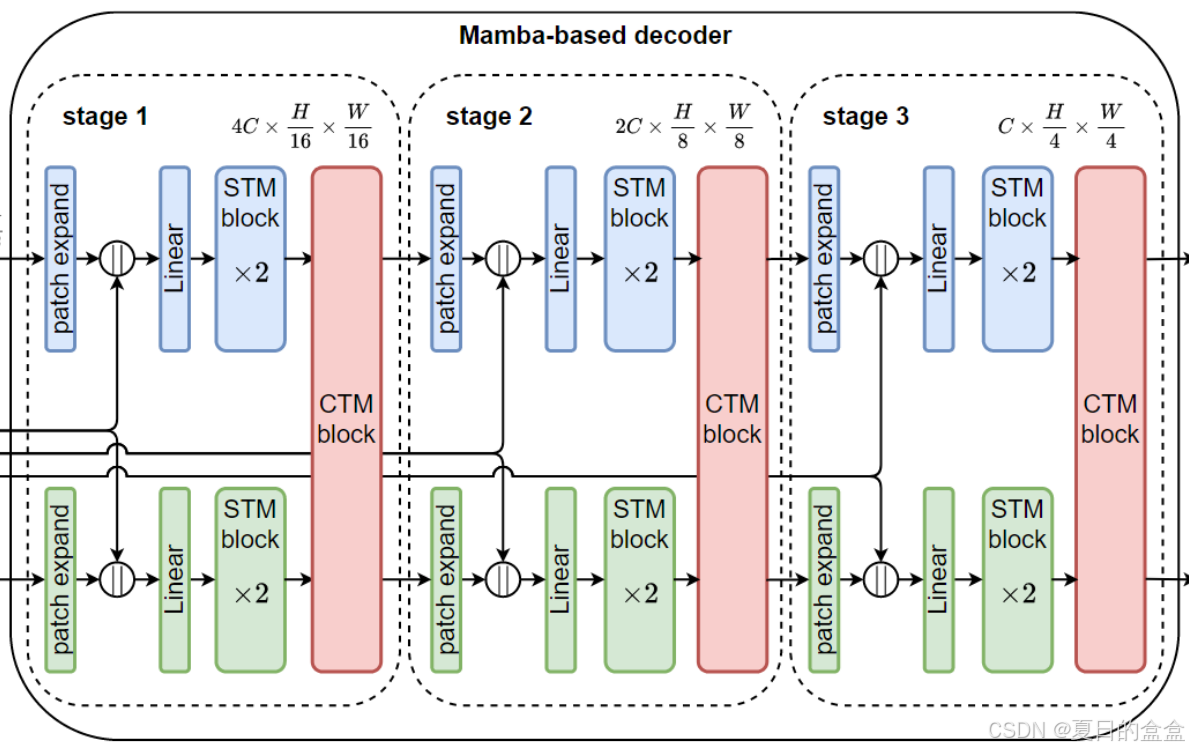
自任务Mamba(STM)块:
- SS2D(SSM扩展到2D图像):SSM 不能直接应用于 2D 图像,结合2D选择性扫描(SS2D)操作来解决这个问题。该方法涉及沿四个方向扩展图像块,生成四个独特的特征序列。然后,每个特征序列被馈送到 SSM(例如 S6)。最后,将处理后的特征组合起来构建综合的二维特征图。
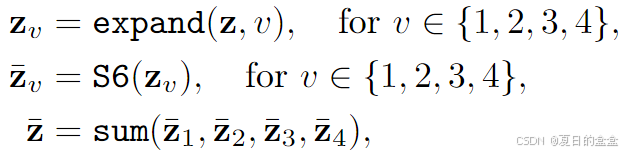
- 基于 Mamba 的特征提取器 (MFE):MFE 由一个线性层组成,用于通过可控膨胀因子 α 扩展特征维度,一个激活函数用于提取局部特征的卷积层,一个用于建模远程依赖的 SS2D 操作,以及一个层归一化来对学习到的特征进行归一化。
![]()
Self-Task Mamba (STM)块:使用依赖于输入的门来自适应地选择从 MFE 中学习到的有用表示。之后,使用线性层来减少 MFE 中扩展的特征维度。
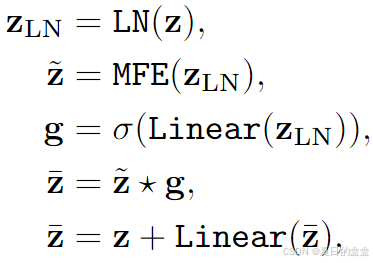
跨任务Mamba (CTM)块:修改 STM 块以实现跨不同任务的知识交换,设计了一种新颖的跨任务 Mamba 块。首先将所有任务特征连接起来,然后通过 MFE 来学习全局表示。每个任务还通过自己的 MFE 学习其对应的特征
。然后,我们使用依赖于输入的门来聚合特定于任务的表示
和全局表示
。因此,每个任务自适应地融合全局表示及其特征。
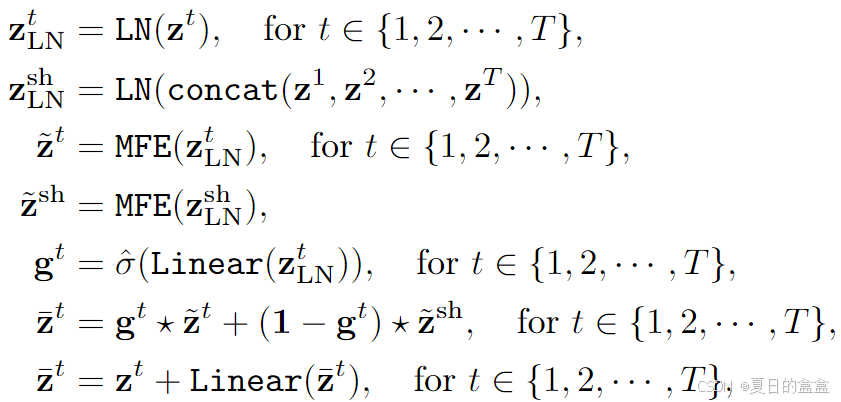
3. Output Head
每个输出头包含一个补丁扩展层和一个线性层,这是轻量级的。具体来说,给定解码器大小为 C × H/4 × W/4 的第 t 个任务特征,补丁扩展层执行 4 倍上采样以将特征图的分辨率恢复到输入分辨率 H × W ,然后使用线性层输出最终的像素级预测。
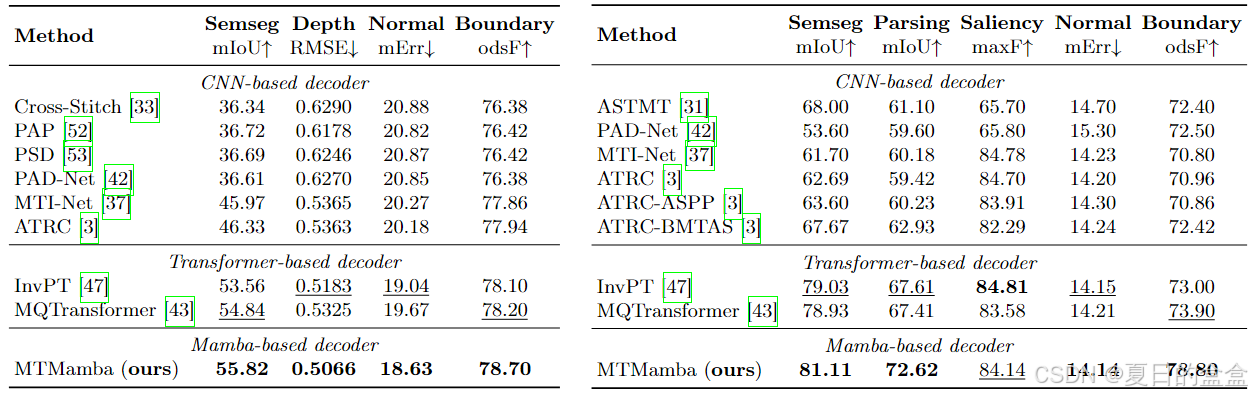
实验结果
结论
MTMamba在多任务密集场景理解方面取得了显著的性能提升,超越了先前的CNN-based和Transformer-based方法。在PASCAL-Context数据集上,MTMamba在语义分割、人体解析和对象边界检测任务中分别实现了+2.08、+5.01和+4.90的改进。定性研究也表明MTMamba生成了更准确的细节和更好的视觉效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









